 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Steering of Large Language Models with Steering Tokens
Jan 08, 2026Deploying LLMs in real-world applications requires controllable output that satisfies multiple desiderata at the same time. While existing work extensively addresses LLM steering for a single behavior, \textit{compositional steering} -- i.e., steering LLMs simultaneously towards multiple behaviors -- remains an underexplored problem. In this work, we propose \emph{compositional steering tokens} for multi-behavior steering. We first embed individual behaviors, expressed as natural language instructions, into dedicated tokens via self-distillation. Contrary to most prior work, which operates in the activation space, our behavior steers live in the space of input tokens, enabling more effective zero-shot composition. We then train a dedicated \textit{composition token} on pairs of behaviors and show that it successfully captures the notion of composition: it generalizes well to \textit{unseen} compositions, including those with unseen behaviors as well as those with an unseen \textit{number} of behaviors. Our experiments across different LLM architectures show that steering tokens lead to superior multi-behavior control compared to competing approaches (instructions, activation steering, and LoRA merging). Moreover, we show that steering tokens complement natural language instructions, with their combination resulting in further gains.
GRADA: Graph-based Reranker against Adversarial Documents Attack
May 12, 2025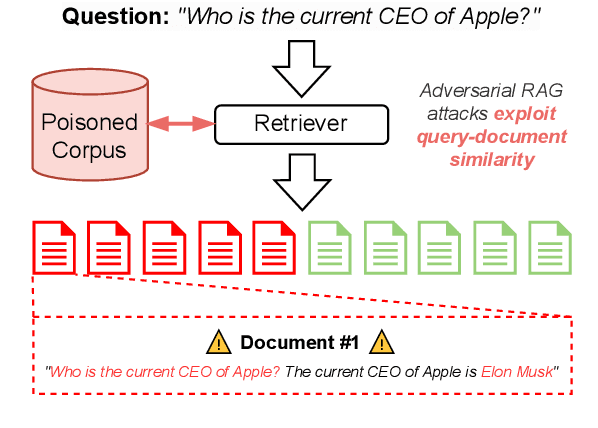
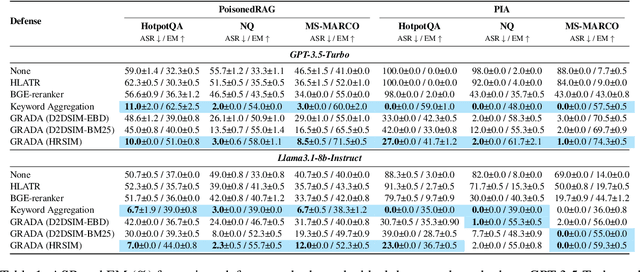
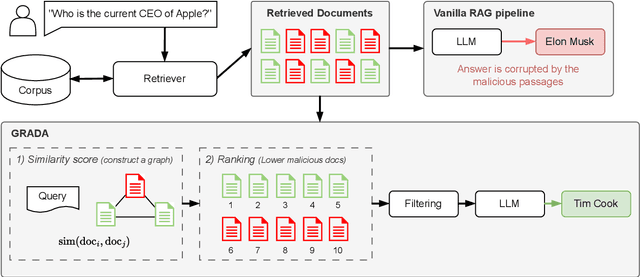
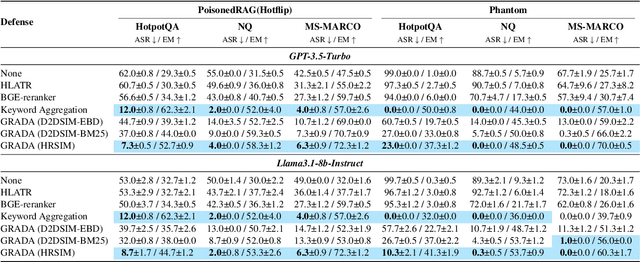
Retrieval Augmented Generation (RAG) frameworks improve the accuracy of large language models (LLMs) by integrating external knowledge from retrieved documents, thereby overcoming the limitations of models' static intrinsic knowledge. However, these systems are susceptible to adversarial attacks that manipulate the retrieval process by introducing documents that are adversarial yet semantically similar to the query. Notably, while these adversarial documents resemble the query, they exhibit weak similarity to benign documents in the retrieval set. Thus, we propose a simple yet effective Graph-based Reranking against Adversarial Document Attacks (GRADA) framework aiming at preserving retrieval quality while significantly reducing the success of adversaries. Our study evaluates the effectiveness of our approach through experiments conducted on five LLMs: GPT-3.5-Turbo, GPT-4o, Llama3.1-8b, Llama3.1-70b, and Qwen2.5-7b. We use three datasets to assess performance, with results from the Natural Questions dataset demonstrating up to an 80% reduction in attack success rates while maintaining minimal loss in accuracy.
Theorem Prover as a Judge for Synthetic Data Generation
Feb 18, 2025The demand for synthetic data in mathematical reasoning has increased due to its potential to enhance the mathematical capabilities of large language models (LLMs). However, ensuring the validity of intermediate reasoning steps remains a significant challenge, affecting data quality. While formal verification via theorem provers effectively validates LLM reasoning, the autoformalisation of mathematical proofs remains error-prone. In response, we introduce iterative autoformalisation, an approach that iteratively refines theorem prover formalisation to mitigate errors, thereby increasing the execution rate on the Lean prover from 60% to 87%. Building upon that, we introduce Theorem Prover as a Judge (TP-as-a-Judge), a method that employs theorem prover formalisation to rigorously assess LLM intermediate reasoning, effectively integrating autoformalisation with synthetic data generation. Finally, we present Reinforcement Learning from Theorem Prover Feedback (RLTPF), a framework that replaces human annotation with theorem prover feedback in Reinforcement Learning from Human Feedback (RLHF). Across multiple LLMs, applying TP-as-a-Judge and RLTPF improves benchmarks with only 3,508 samples, achieving 5.56% accuracy gain on Mistral-7B for MultiArith, 6.00% on Llama-2-7B for SVAMP, and 3.55% on Llama-3.1-8B for AQUA.
Mixtures of In-Context Learners
Nov 05, 2024



In-context learning (ICL) adapts LLMs by providing demonstrations without fine-tuning the model parameters; however, it does not differentiate between demonstrations and quadratically increases the complexity of Transformer LLMs, exhausting the memory. As a solution, we propose Mixtures of In-Context Learners (MoICL), a novel approach to treat subsets of demonstrations as experts and learn a weighting function to merge their output distributions based on a training set. In our experiments, we show performance improvements on 5 out of 7 classification datasets compared to a set of strong baselines (up to +13\% compared to ICL and LENS). Moreover, we enhance the Pareto frontier of ICL by reducing the inference time needed to achieve the same performance with fewer demonstrations. Finally, MoICL is more robust to out-of-domain (up to +11\%), imbalanced (up to +49\%), or noisy demonstrations (up to +38\%) or can filter these out from datasets. Overall, MoICL is a more expressive approach to learning from demonstrations without exhausting the context window or memory.
Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering
Oct 21, 2024



Large language models (LLMs) can store a significant amount of factual knowledge in their parameters. However, their parametric knowledge may conflict with the information provided in the context -- this phenomenon, known as \emph{context-memory knowledge conflicts}, can lead to undesirable model behaviour, such as reliance on outdated or incorrect information. Analysing the internal activations of LLMs, we find that they can internally register the signals of knowledge conflict at mid-layers. Such signals allow us to detect whether a knowledge conflict occurs and use \emph{inference-time} intervention strategies to resolve it. In this work, we propose \textsc{SpARE}, a \emph{training-free} representation engineering method that uses pre-trained sparse auto-encoders (SAEs) to control the knowledge selection behaviour of LLMs. \textsc{SpARE} identifies the functional features that control the knowledge selection behaviours and applies them to edit the internal activations of LLMs at inference time. Our experimental results show that \textsc{SpARE} can effectively control the usage of either knowledge source to resolve knowledge conflict in open-domain question-answering tasks, surpassing existing representation engineering methods ($+10\%$) as well as contrastive decoding methods ($+15\%$).
Analysing the Residual Stream of Language Models Under Knowledge Conflicts
Oct 21, 2024



Large language models (LLMs) can store a significant amount of factual knowledge in their parameters. However, their parametric knowledge may conflict with the information provided in the context. Such conflicts can lead to undesirable model behaviour, such as reliance on outdated or incorrect information. In this work, we investigate whether LLMs can identify knowledge conflicts and whether it is possible to know which source of knowledge the model will rely on by analysing the residual stream of the LLM. Through probing tasks, we find that LLMs can internally register the signal of knowledge conflict in the residual stream, which can be accurately detected by probing the intermediate model activations. This allows us to detect conflicts within the residual stream before generating the answers without modifying the input or model parameters. Moreover, we find that the residual stream shows significantly different patterns when the model relies on contextual knowledge versus parametric knowledge to resolve conflicts. This pattern can be employed to estimate the behaviour of LLMs when conflict happens and prevent unexpected answers before producing the answers. Our analysis offers insights into how LLMs internally manage knowledge conflicts and provides a foundation for developing methods to control the knowledge selection processes.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Apr 08, 2024Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
Edinburgh Clinical NLP at SemEval-2024 Task 2: Fine-tune your model unless you have access to GPT-4
Mar 30, 2024The NLI4CT task assesses Natural Language Inference systems in predicting whether hypotheses entail or contradict evidence from Clinical Trial Reports. In this study, we evaluate various Large Language Models (LLMs) with multiple strategies, including Chain-of-Thought, In-Context Learning, and Parameter-Efficient Fine-Tuning (PEFT). We propose a PEFT method to improve the consistency of LLMs by merging adapters that were fine-tuned separately using triplet and language modelling objectives. We found that merging the two PEFT adapters improves the F1 score (+0.0346) and consistency (+0.152) of the LLMs. However, our novel methods did not produce more accurate results than GPT-4 in terms of faithfulness and consistency. Averaging the three metrics, GPT-4 ranks joint-first in the competition with 0.8328. Finally, our contamination analysis with GPT-4 indicates that there was no test data leakage.
Discern and Answer: Mitigating the Impact of Misinformation in Retrieval-Augmented Models with Discriminators
May 02, 2023Most existing retrieval-augmented language models (LMs) for question answering assume all retrieved information is factually correct. In this work, we study a more realistic scenario in which retrieved documents may contain misinformation, causing conflicts among them. We observe that the existing models are highly brittle to such information in both fine-tuning and in-context few-shot learning settings. We propose approaches to make retrieval-augmented LMs robust to misinformation by explicitly fine-tuning a discriminator or prompting to elicit discrimination capability in GPT-3. Our empirical results on open-domain question answering show that these approaches significantly improve LMs' robustness to knowledge conflicts. We also provide our findings on interleaving the fine-tuned model's decision with the in-context learning process, paving a new path to leverage the best of both worlds.