 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMIX: Improving Importance Weighting for Subpopulation Shift via Uncertainty-Aware Mixup
Oct 10, 2022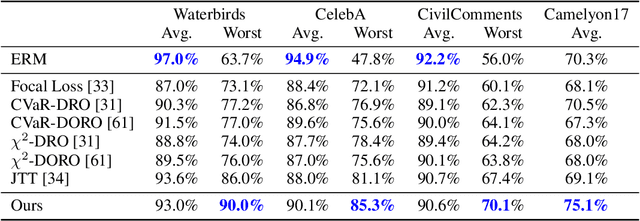
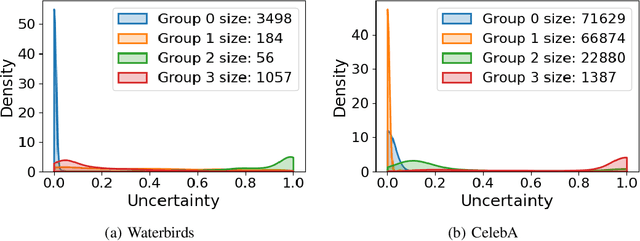
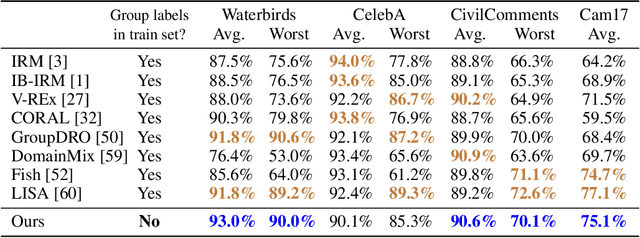
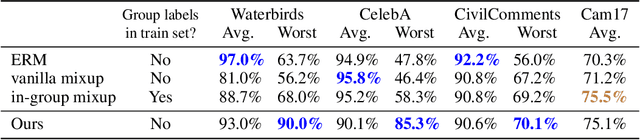
Subpopulation shift widely exists in many real-world machine learning applications, referring to the training and test distributions containing the same subpopulation groups but varying in subpopulation frequencies. Importance reweighting is a normal way to handle the subpopulation shift issue by imposing constant or adaptive sampling weights on each sample in the training dataset. However, some recent studies have recognized that most of these approaches fail to improve the performance over empirical risk minimization especially when applied to over-parameterized neural networks. In this work, we propose a simple yet practical framework, called uncertainty-aware mixup (UMIX), to mitigate the overfitting issue in over-parameterized models by reweighting the ''mixed'' samples according to the sample uncertainty. The training-trajectories-based uncertainty estimation is equipped in the proposed UMIX for each sample to flexibly characterize the subpopulation distribution. We also provide insightful theoretical analysis to verify that UMIX achieves better generalization bounds over prior works. Further, we conduct extensive empirical studies across a wide range of tasks to validate the effectiveness of our method both qualitatively and quantitatively. Code is available at https://github.com/TencentAILabHealthcare/UMIX.
ImDrug: A Benchmark for Deep Imbalanced Learning in AI-aided Drug Discovery
Sep 16, 2022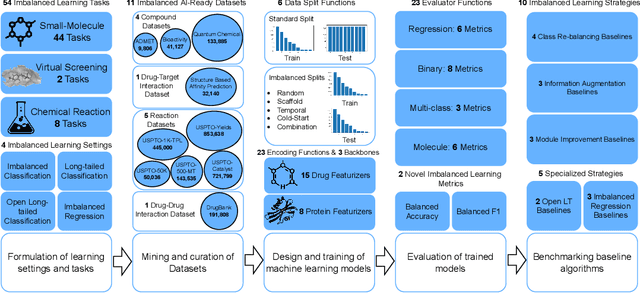

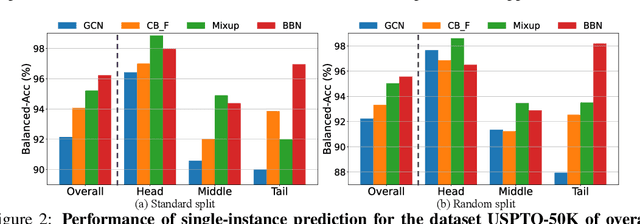
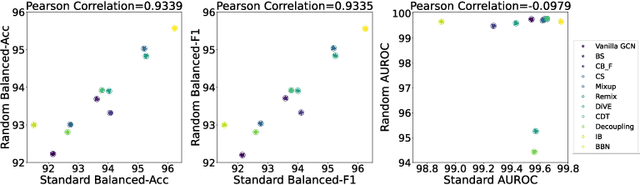
The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
ImGCL: Revisiting Graph Contrastive Learning on Imbalanced Node Classification
May 23, 2022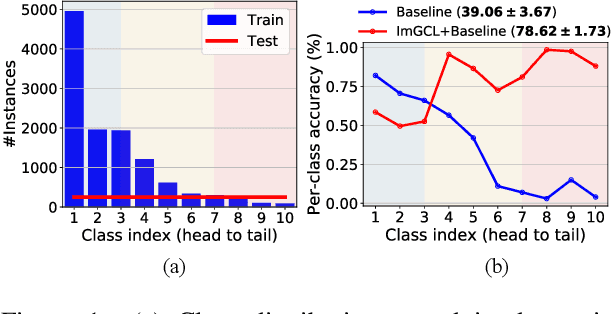
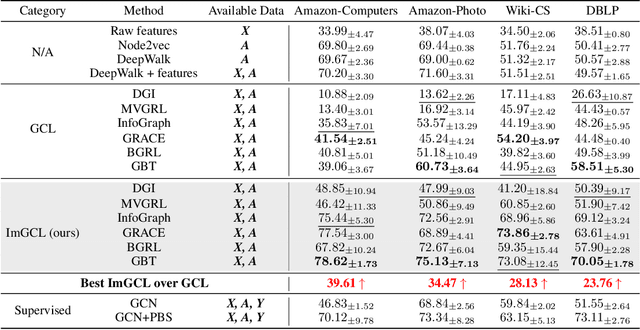
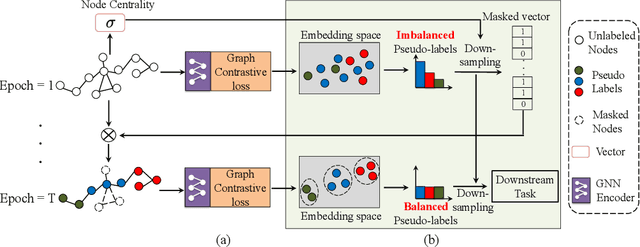
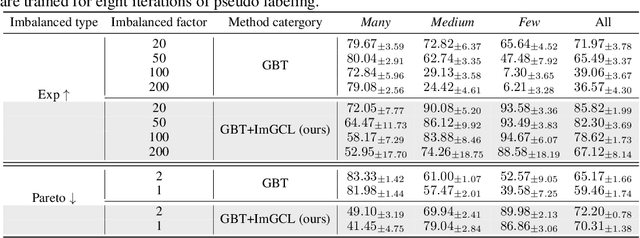
Graph contrastive learning (GCL) has attracted a surge of attention due to its superior performance for learning node/graph representations without labels. However, in practice, unlabeled nodes for the given graph usually follow an implicit imbalanced class distribution, where the majority of nodes belong to a small fraction of classes (a.k.a., head class) and the rest classes occupy only a few samples (a.k.a., tail classes). This highly imbalanced class distribution inevitably deteriorates the quality of learned node representations in GCL. Indeed, we empirically find that most state-of-the-art GCL methods exhibit poor performance on imbalanced node classification. Motivated by this observation, we propose a principled GCL framework on Imbalanced node classification (ImGCL), which automatically and adaptively balances the representation learned from GCL without knowing the labels. Our main inspiration is drawn from the recent progressively balanced sampling (PBS) method in the computer vision domain. We first introduce online clustering based PBS, which balances the training sets based on pseudo-labels obtained from learned representations. We then develop the node centrality based PBS method to better preserve the intrinsic structure of graphs, which highlight the important nodes of the given graph. Besides, we theoretically consolidate our method by proving that the classifier learned by balanced sampling without labels on an imbalanced dataset can converge to the optimal balanced classifier with a linear rate. Extensive experiments on multiple imbalanced graph datasets and imbalance settings verify the effectiveness of our proposed framework, which significantly improves the performance of the recent state-of-the-art GCL methods. Further experimental ablations and analysis show that the ImGCL framework remarkably improves the representations of nodes in tail classes.
Robust Imitation Learning from Corrupted Demonstrations
Jan 29, 2022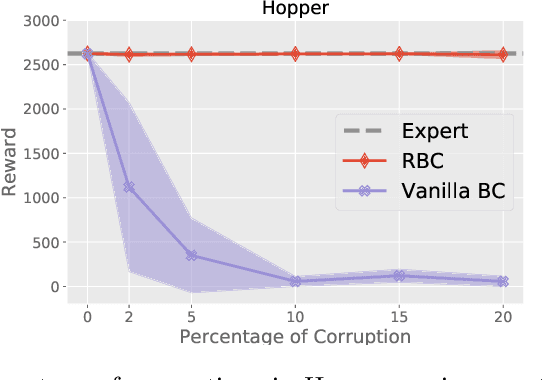
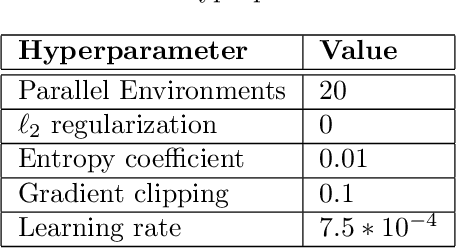
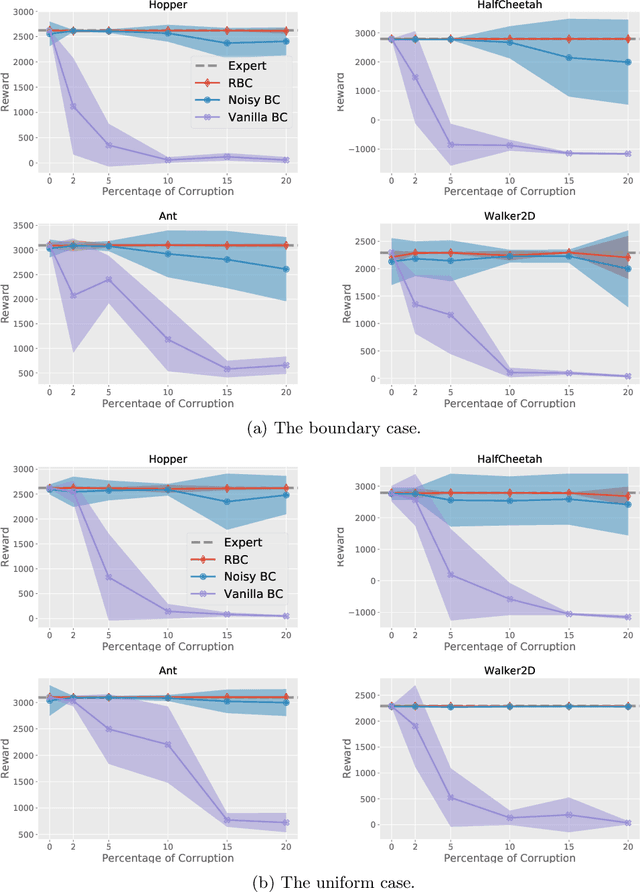
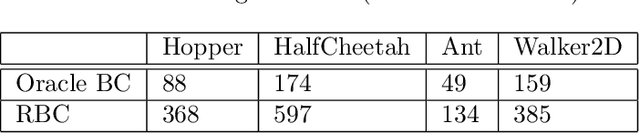
We consider offline Imitation Learning from corrupted demonstrations where a constant fraction of data can be noise or even arbitrary outliers. Classical approaches such as Behavior Cloning assumes that demonstrations are collected by an presumably optimal expert, hence may fail drastically when learning from corrupted demonstrations. We propose a novel robust algorithm by minimizing a Median-of-Means (MOM) objective which guarantees the accurate estimation of policy, even in the presence of constant fraction of outliers. Our theoretical analysis shows that our robust method in the corrupted setting enjoys nearly the same error scaling and sample complexity guarantees as the classical Behavior Cloning in the expert demonstration setting. Our experiments on continuous-control benchmarks validate that our method exhibits the predicted robustness and effectiveness, and achieves competitive results compared to existing imitation learning methods.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022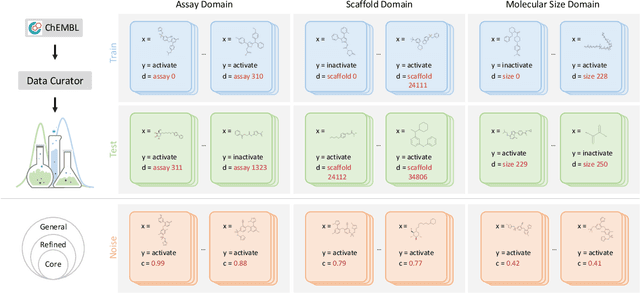

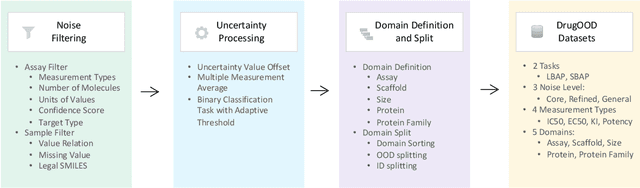
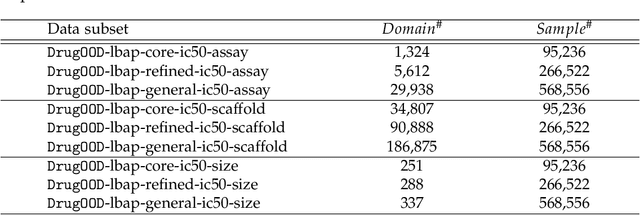
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
Local Augmentation for Graph Neural Networks
Sep 08, 2021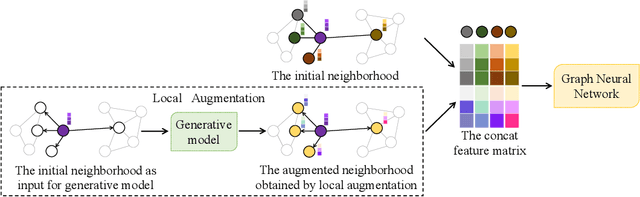
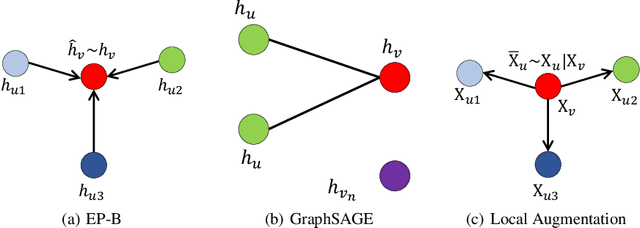

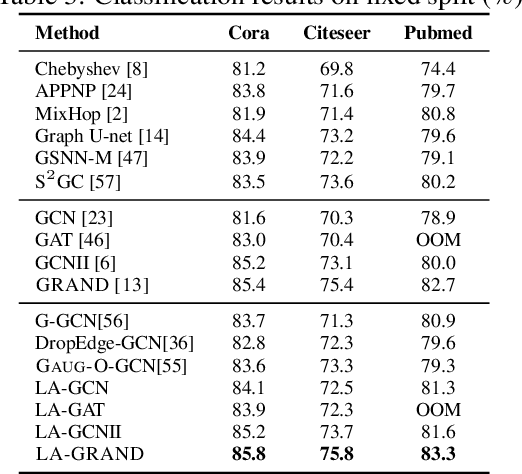
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
IGrow: A Smart Agriculture Solution to Autonomous Greenhouse Control
Jul 06, 2021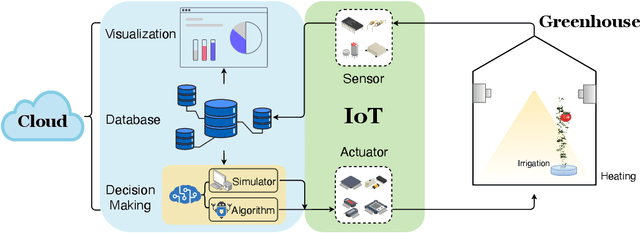
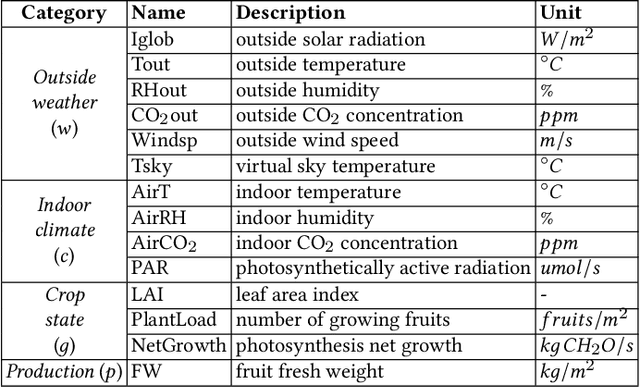
Agriculture is the foundation of human civilization. However, the rapid increase and aging of the global population pose challenges on this cornerstone by demanding more healthy and fresh food. Internet of Things (IoT) technology makes modern autonomous greenhouse a viable and reliable engine of food production. However, the educated and skilled labor capable of overseeing high-tech greenhouses is scarce. Artificial intelligence (AI) and cloud computing technologies are promising solutions for precision control and high-efficiency production in such controlled environments. In this paper, we propose a smart agriculture solution, namely iGrow: (1) we use IoT and cloud computing technologies to measure, collect, and manage growing data, to support iteration of our decision-making AI module, which consists of an incremental model and an optimization algorithm; (2) we propose a three-stage incremental model based on accumulating data, enabling growers/central computers to schedule control strategies conveniently and at low cost; (3) we propose a model-based iterative optimization algorithm, which can dynamically optimize the greenhouse control strategy in real-time production. In the simulated experiment, evaluation results show the accuracy of our incremental model is comparable to an advanced tomato simulator, while our optimization algorithms can beat the champion of the 2nd Autonomous Greenhouse Challenge. Compelling results from the A/B test in real greenhouses demonstrate that our solution significantly increases production (commercially sellable fruits) (+ 10.15%) and net profit (+ 87.07%) with statistical significance compared to planting experts.
Bias-reduced multi-step hindsight experience replay
Feb 25, 2021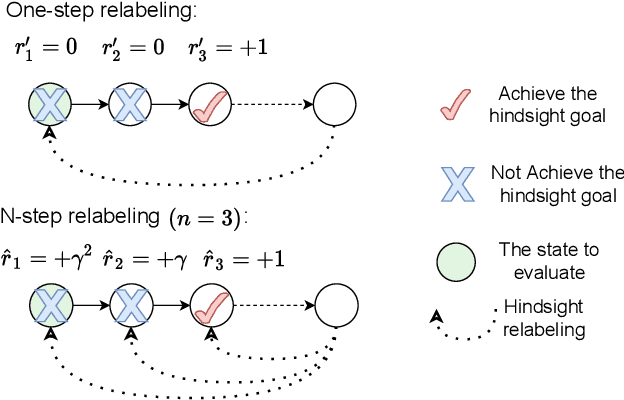
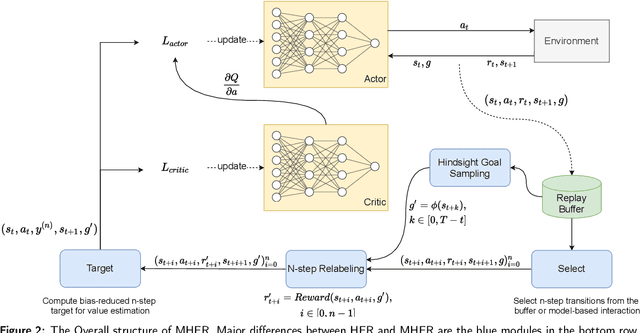
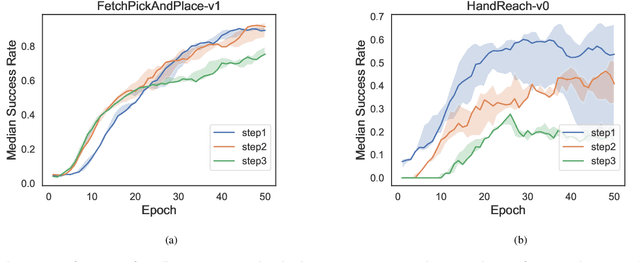
Multi-goal reinforcement learning is widely used in planning and robot manipulation. Two main challenges in multi-goal reinforcement learning are sparse rewards and sample inefficiency. Hindsight Experience Replay (HER) aims to tackle the two challenges with hindsight knowledge. However, HER and its previous variants still need millions of samples and a huge computation. In this paper, we propose \emph{Multi-step Hindsight Experience Replay} (MHER) based on $n$-step relabeling, incorporating multi-step relabeled returns to improve sample efficiency. Despite the advantages of $n$-step relabeling, we theoretically and experimentally prove the off-policy $n$-step bias introduced by $n$-step relabeling may lead to poor performance in many environments. To address the above issue, two bias-reduced MHER algorithms, MHER($\lambda$) and Model-based MHER (MMHER) are presented. MHER($\lambda$) exploits the $\lambda$ return while MMHER benefits from model-based value expansions. Experimental results on numerous multi-goal robotic tasks show that our solutions can successfully alleviate off-policy $n$-step bias and achieve significantly higher sample efficiency than HER and Curriculum-guided HER with little additional computation beyond HER.
Improved Context-Based Offline Meta-RL with Attention and Contrastive Learning
Feb 22, 2021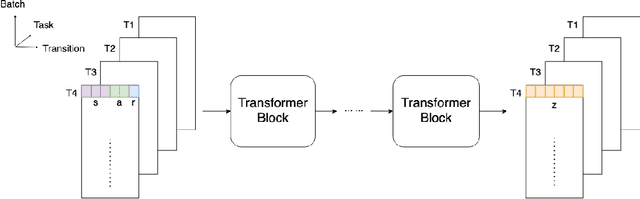
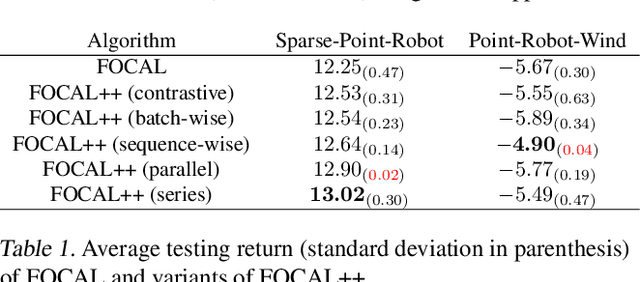
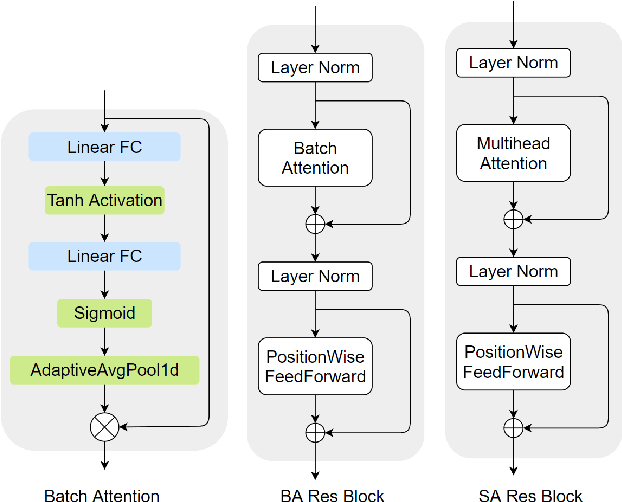
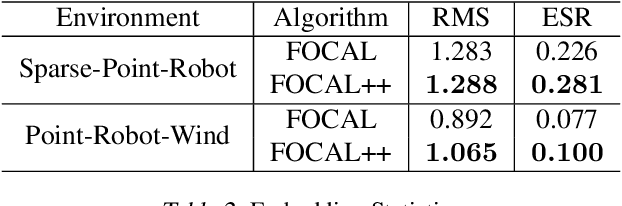
Meta-learning for offline reinforcement learning (OMRL) is an understudied problem with tremendous potential impact by enabling RL algorithms in many real-world applications. A popular solution to the problem is to infer task identity as augmented state using a context-based encoder, for which efficient learning of task representations remains an open challenge. In this work, we improve upon one of the SOTA OMRL algorithms, FOCAL, by incorporating intra-task attention mechanism and inter-task contrastive learning objectives for more effective task inference and learning of control. Theoretical analysis and experiments are presented to demonstrate the superior performance, efficiency and robustness of our end-to-end and model free method compared to prior algorithms across multiple meta-RL benchmarks.
Efficient Fully-Offline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization
Oct 02, 2020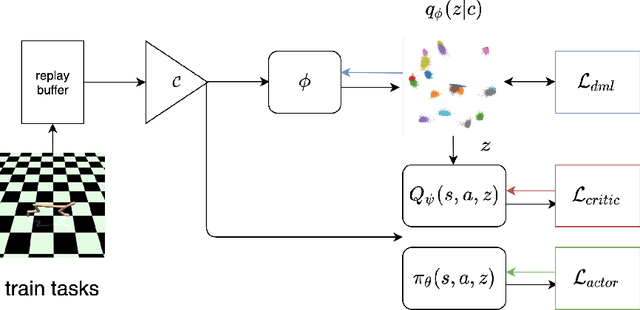
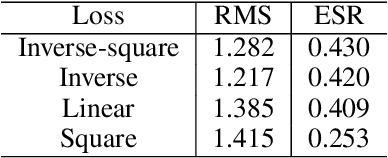
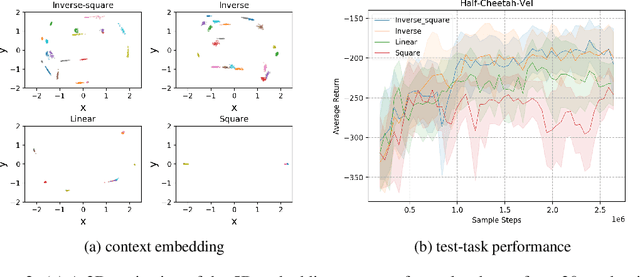
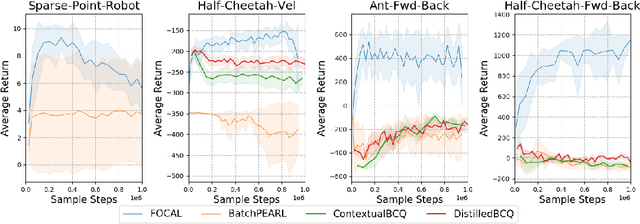
We study the offline meta-reinforcement learning (OMRL) problem, a paradigm which enables reinforcement learning (RL) algorithms to quickly adapt to unseen tasks without any interactions with the environments, making RL truly practical in many real-world applications. This problem is still not fully understood, for which two major challenges need to be addressed. First, offline RL often suffers from bootstrapping errors of out-of-distribution state-actions which leads to divergence of value functions. Second, meta-RL requires efficient and robust task inference learned jointly with control policy. In this work, we enforce behavior regularization on learned policy as a general approach to offline RL, combined with a deterministic context encoder for efficient task inference. We propose a novel negative-power distance metric on bounded context embedding space, whose gradients propagation is detached from that of the Bellman backup. We provide analysis and insight showing that some simple design choices can yield substantial improvements over recent approaches involving meta-RL and distance metric learning. To the best of our knowledge, our method is the first model-free and end-to-end OMRL algorithm, which is computationally efficient and demonstrated to outperform prior algorithms on several meta-RL benchmarks.