 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Model Driven Neural Rendering for High-fidelity 3D Reconstruction of Human Heads Under Low-View Settings
Mar 24, 2023



We propose a robust method for learning neural implicit functions that can reconstruct 3D human heads with high-fidelity geometry from low-view inputs. We represent 3D human heads as the zero level-set of a composed signed distance field that consists of a smooth template, a non-rigid deformation, and a high-frequency displacement field. The template represents identity-independent and expression-neutral features, which is trained on multiple individuals, along with the deformation network. The displacement field encodes identity-dependent geometric details, trained for each specific individual. We train our network in two stages using a coarse-to-fine strategy without 3D supervision. Our experiments demonstrate that the geometry decomposition and two-stage training make our method robust and our model outperforms existing methods in terms of reconstruction accuracy and novel view synthesis under low-view settings. Additionally, the pre-trained template serves a good initialization for our model to adapt to unseen individuals.
StyleGAN-Human: A Data-Centric Odyssey of Human Generation
Apr 25, 2022

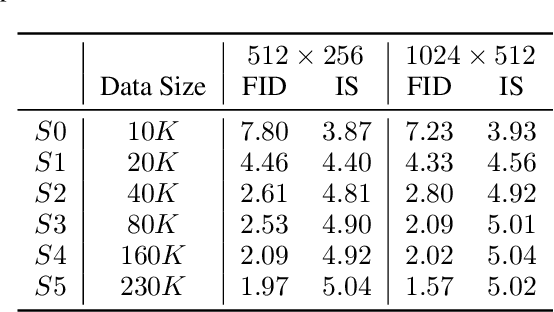
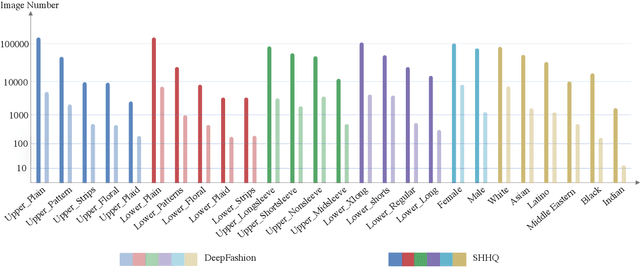
Unconditional human image generation is an important task in vision and graphics, which enables various applications in the creative industry. Existing studies in this field mainly focus on "network engineering" such as designing new components and objective functions. This work takes a data-centric perspective and investigates multiple critical aspects in "data engineering", which we believe would complement the current practice. To facilitate a comprehensive study, we collect and annotate a large-scale human image dataset with over 230K samples capturing diverse poses and textures. Equipped with this large dataset, we rigorously investigate three essential factors in data engineering for StyleGAN-based human generation, namely data size, data distribution, and data alignment. Extensive experiments reveal several valuable observations w.r.t. these aspects: 1) Large-scale data, more than 40K images, are needed to train a high-fidelity unconditional human generation model with vanilla StyleGAN. 2) A balanced training set helps improve the generation quality with rare face poses compared to the long-tailed counterpart, whereas simply balancing the clothing texture distribution does not effectively bring an improvement. 3) Human GAN models with body centers for alignment outperform models trained using face centers or pelvis points as alignment anchors. In addition, a model zoo and human editing applications are demonstrated to facilitate future research in the community.
Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis
Apr 25, 2022
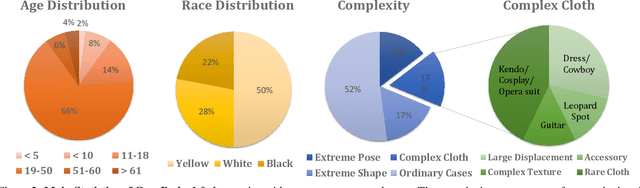
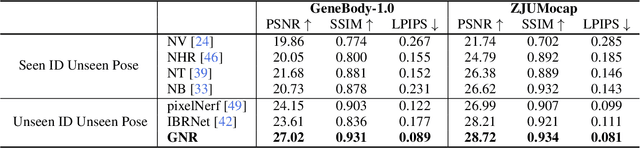
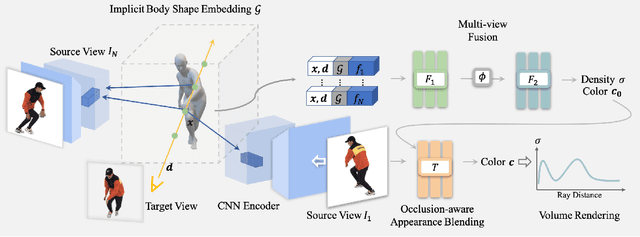
This work targets at using a general deep learning framework to synthesize free-viewpoint images of arbitrary human performers, only requiring a sparse number of camera views as inputs and skirting per-case fine-tuning. The large variation of geometry and appearance, caused by articulated body poses, shapes and clothing types, are the key bottlenecks of this task. To overcome these challenges, we present a simple yet powerful framework, named Generalizable Neural Performer (GNR), that learns a generalizable and robust neural body representation over various geometry and appearance. Specifically, we compress the light fields for novel view human rendering as conditional implicit neural radiance fields from both geometry and appearance aspects. We first introduce an Implicit Geometric Body Embedding strategy to enhance the robustness based on both parametric 3D human body model and multi-view images hints. We further propose a Screen-Space Occlusion-Aware Appearance Blending technique to preserve the high-quality appearance, through interpolating source view appearance to the radiance fields with a relax but approximate geometric guidance. To evaluate our method, we present our ongoing effort of constructing a dataset with remarkable complexity and diversity. The dataset GeneBody-1.0, includes over 360M frames of 370 subjects under multi-view cameras capturing, performing a large variety of pose actions, along with diverse body shapes, clothing, accessories and hairdos. Experiments on GeneBody-1.0 and ZJU-Mocap show better robustness of our methods than recent state-of-the-art generalizable methods among all cross-dataset, unseen subjects and unseen poses settings. We also demonstrate the competitiveness of our model compared with cutting-edge case-specific ones. Dataset, code and model will be made publicly available.
Simulating Fluids in Real-World Still Images
Apr 24, 2022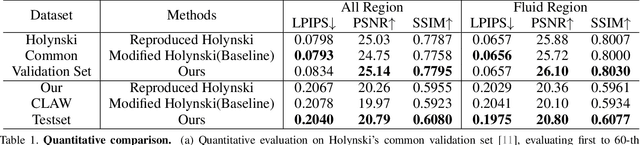
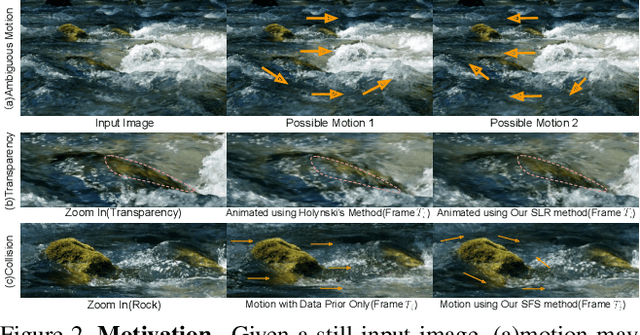
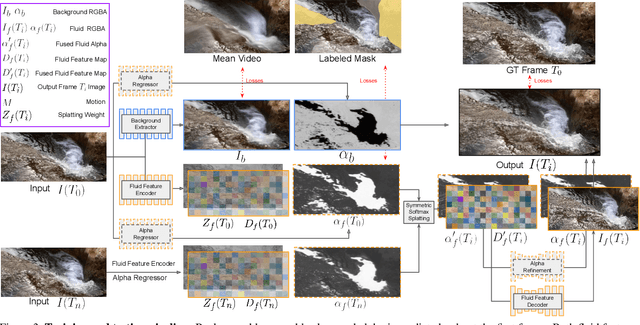
In this work, we tackle the problem of real-world fluid animation from a still image. The key of our system is a surface-based layered representation deriving from video decomposition, where the scene is decoupled into a surface fluid layer and an impervious background layer with corresponding transparencies to characterize the composition of the two layers. The animated video can be produced by warping only the surface fluid layer according to the estimation of fluid motions and recombining it with the background. In addition, we introduce surface-only fluid simulation, a $2.5D$ fluid calculation version, as a replacement for motion estimation. Specifically, we leverage the triangular mesh based on a monocular depth estimator to represent the fluid surface layer and simulate the motion in the physics-based framework with the inspiration of the classic theory of the hybrid Lagrangian-Eulerian method, along with a learnable network so as to adapt to complex real-world image textures. We demonstrate the effectiveness of the proposed system through comparison with existing methods in both standard objective metrics and subjective ranking scores. Extensive experiments not only indicate our method's competitive performance for common fluid scenes but also better robustness and reasonability under complex transparent fluid scenarios. Moreover, as the proposed surface-based layer representation and surface-only fluid simulation naturally disentangle the scene, interactive editing such as adding objects to the river and texture replacing could be easily achieved with realistic results.
RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose Optimization
Apr 10, 2022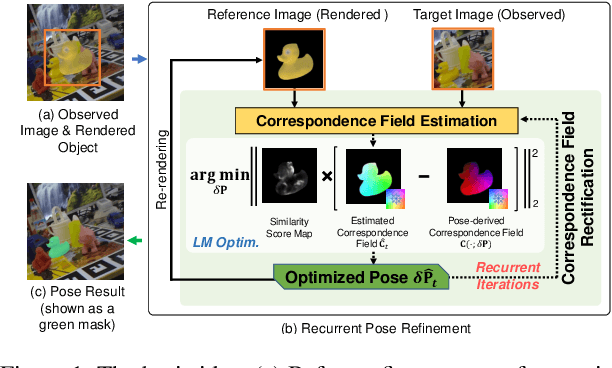
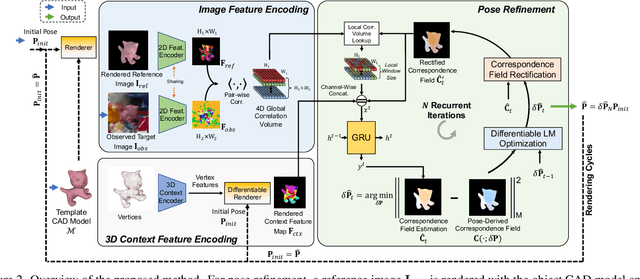
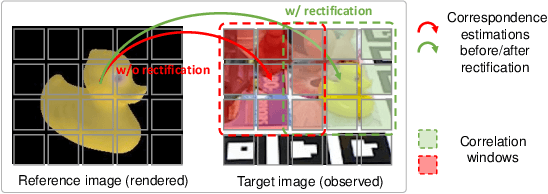
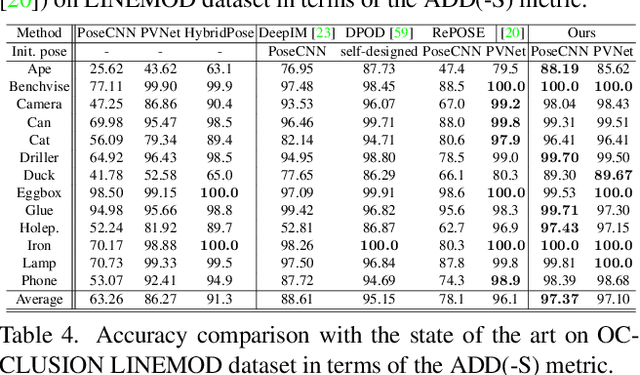
6-DoF object pose estimation from a monocular image is challenging, and a post-refinement procedure is generally needed for high-precision estimation. In this paper, we propose a framework based on a recurrent neural network (RNN) for object pose refinement, which is robust to erroneous initial poses and occlusions. During the recurrent iterations, object pose refinement is formulated as a non-linear least squares problem based on the estimated correspondence field (between a rendered image and the observed image). The problem is then solved by a differentiable Levenberg-Marquardt (LM) algorithm enabling end-to-end training. The correspondence field estimation and pose refinement are conducted alternatively in each iteration to recover the object poses. Furthermore, to improve the robustness to occlusion, we introduce a consistency-check mechanism based on the learned descriptors of the 3D model and observed 2D images, which downweights the unreliable correspondences during pose optimization. Extensive experiments on LINEMOD, Occlusion-LINEMOD, and YCB-Video datasets validate the effectiveness of our method and demonstrate state-of-the-art performance.
Learning a Structured Latent Space for Unsupervised Point Cloud Completion
Mar 29, 2022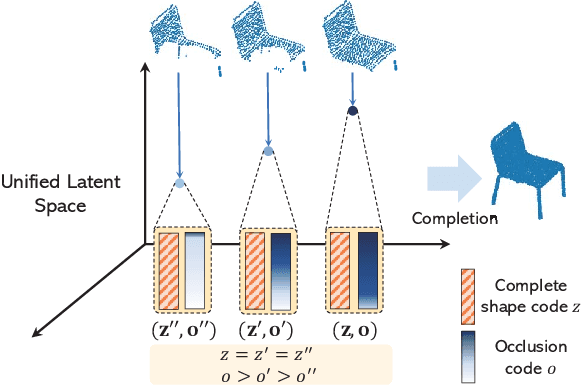
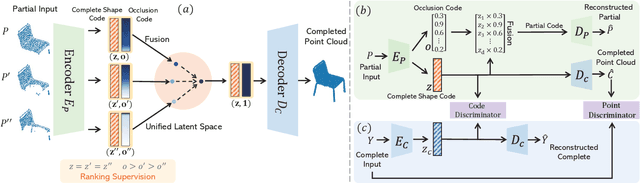
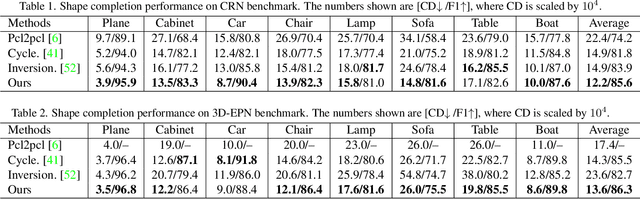
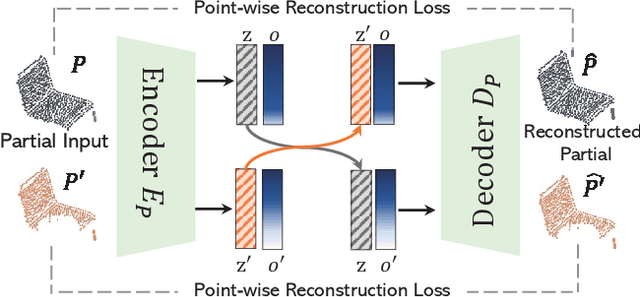
Unsupervised point cloud completion aims at estimating the corresponding complete point cloud of a partial point cloud in an unpaired manner. It is a crucial but challenging problem since there is no paired partial-complete supervision that can be exploited directly. In this work, we propose a novel framework, which learns a unified and structured latent space that encoding both partial and complete point clouds. Specifically, we map a series of related partial point clouds into multiple complete shape and occlusion code pairs and fuse the codes to obtain their representations in the unified latent space. To enforce the learning of such a structured latent space, the proposed method adopts a series of constraints including structured ranking regularization, latent code swapping constraint, and distribution supervision on the related partial point clouds. By establishing such a unified and structured latent space, better partial-complete geometry consistency and shape completion accuracy can be achieved. Extensive experiments show that our proposed method consistently outperforms state-of-the-art unsupervised methods on both synthetic ShapeNet and real-world KITTI, ScanNet, and Matterport3D datasets.
* 8 pages, 5 figures, cvpr2022
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021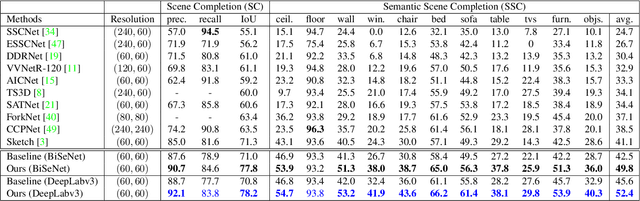

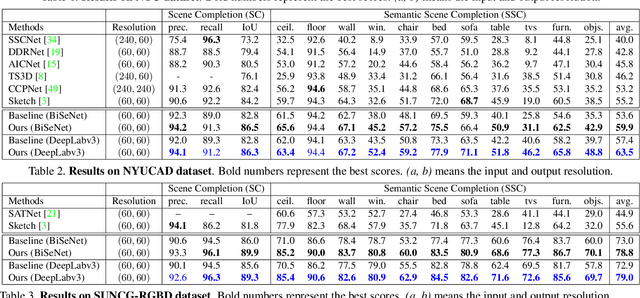
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.
SelfVoxeLO: Self-supervised LiDAR Odometry with Voxel-based Deep Neural Networks
Oct 19, 2020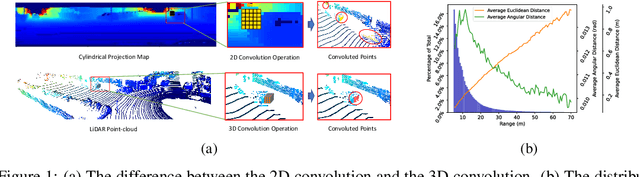
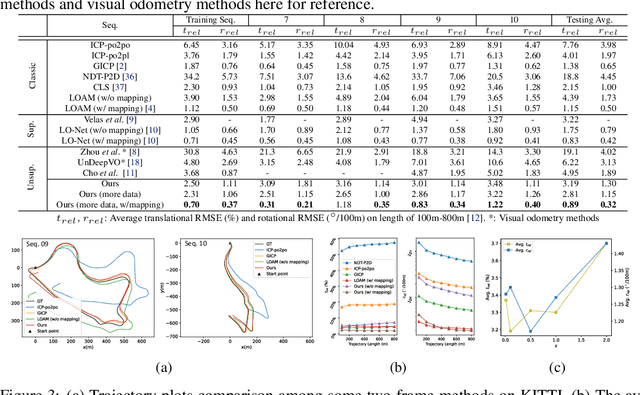
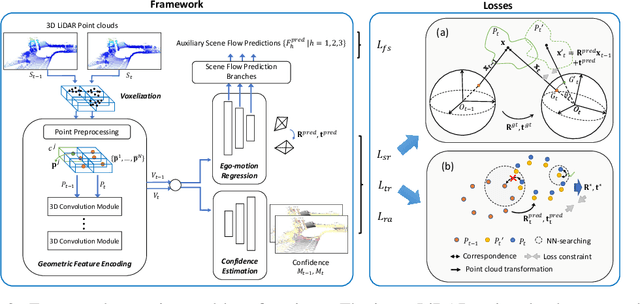
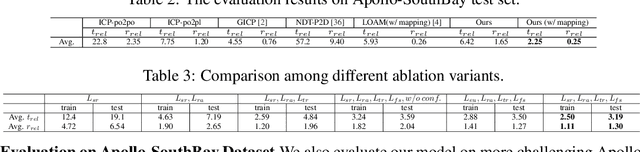
Recent learning-based LiDAR odometry methods have demonstrated their competitiveness. However, most methods still face two substantial challenges: 1) the 2D projection representation of LiDAR data cannot effectively encode 3D structures from the point clouds; 2) the needs for a large amount of labeled data for training limit the application scope of these methods. In this paper, we propose a self-supervised LiDAR odometry method, dubbed SelfVoxeLO, to tackle these two difficulties. Specifically, we propose a 3D convolution network to process the raw LiDAR data directly, which extracts features that better encode the 3D geometric patterns. To suit our network to self-supervised learning, we design several novel loss functions that utilize the inherent properties of LiDAR point clouds. Moreover, an uncertainty-aware mechanism is incorporated in the loss functions to alleviate the interference of moving objects/noises. We evaluate our method's performances on two large-scale datasets, i.e., KITTI and Apollo-SouthBay. Our method outperforms state-of-the-art unsupervised methods by 27%/32% in terms of translational/rotational errors on the KITTI dataset and also performs well on the Apollo-SouthBay dataset. By including more unlabelled training data, our method can further improve performance comparable to the supervised methods.
Bi-directional Cross-Modality Feature Propagation with Separation-and-Aggregation Gate for RGB-D Semantic Segmentation
Jul 17, 2020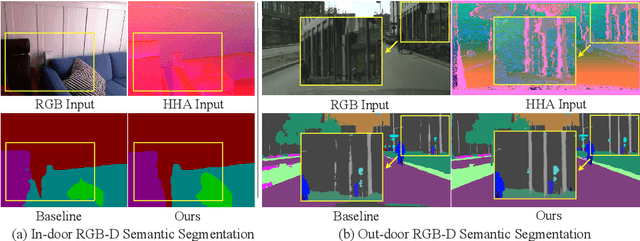

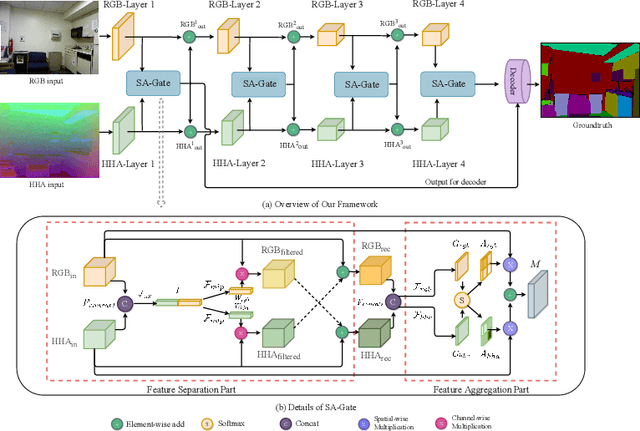

Depth information has proven to be a useful cue in the semantic segmentation of RGB-D images for providing a geometric counterpart to the RGB representation. Most existing works simply assume that depth measurements are accurate and well-aligned with the RGB pixels and models the problem as a cross-modal feature fusion to obtain better feature representations to achieve more accurate segmentation. This, however, may not lead to satisfactory results as actual depth data are generally noisy, which might worsen the accuracy as the networks go deeper. In this paper, we propose a unified and efficient Cross-modality Guided Encoder to not only effectively recalibrate RGB feature responses, but also to distill accurate depth information via multiple stages and aggregate the two recalibrated representations alternatively. The key of the proposed architecture is a novel Separation-and-Aggregation Gating operation that jointly filters and recalibrates both representations before cross-modality aggregation. Meanwhile, a Bi-direction Multi-step Propagation strategy is introduced, on the one hand, to help to propagate and fuse information between the two modalities, and on the other hand, to preserve their specificity along the long-term propagation process. Besides, our proposed encoder can be easily injected into the previous encoder-decoder structures to boost their performance on RGB-D semantic segmentation. Our model outperforms state-of-the-arts consistently on both in-door and out-door challenging datasets. Code of this work is available at https://charlescxk.github.io/
3D Sketch-aware Semantic Scene Completion via Semi-supervised Structure Prior
Mar 31, 2020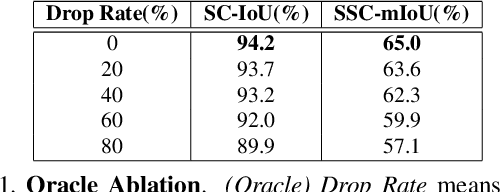
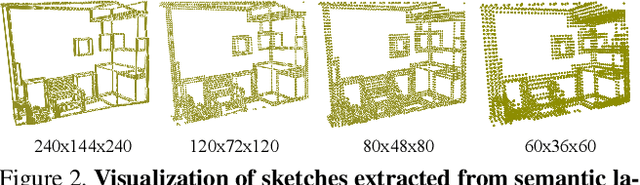
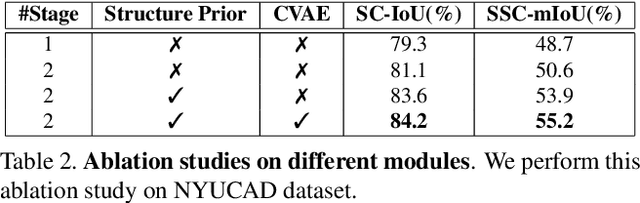
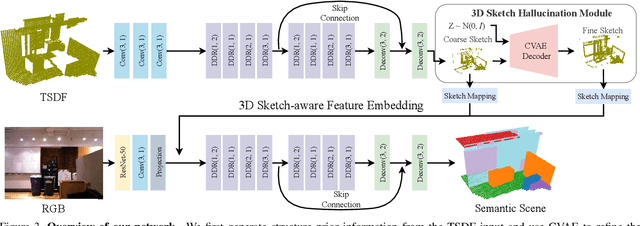
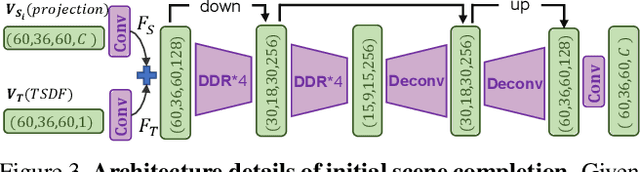
The goal of the Semantic Scene Completion (SSC) task is to simultaneously predict a completed 3D voxel representation of volumetric occupancy and semantic labels of objects in the scene from a single-view observation. Since the computational cost generally increases explosively along with the growth of voxel resolution, most current state-of-the-arts have to tailor their framework into a low-resolution representation with the sacrifice of detail prediction. Thus, voxel resolution becomes one of the crucial difficulties that lead to the performance bottleneck. In this paper, we propose to devise a new geometry-based strategy to embed depth information with low-resolution voxel representation, which could still be able to encode sufficient geometric information, e.g., room layout, object's sizes and shapes, to infer the invisible areas of the scene with well structure-preserving details. To this end, we first propose a novel 3D sketch-aware feature embedding to explicitly encode geometric information effectively and efficiently. With the 3D sketch in hand, we further devise a simple yet effective semantic scene completion framework that incorporates a light-weight 3D Sketch Hallucination module to guide the inference of occupancy and the semantic labels via a semi-supervised structure prior learning strategy. We demonstrate that our proposed geometric embedding works better than the depth feature learning from habitual SSC frameworks. Our final model surpasses state-of-the-arts consistently on three public benchmarks, which only requires 3D volumes of 60 x 36 x 60 resolution for both input and output. The code and the supplementary material will be available at https://charlesCXK.github.io.