 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Failure Attribution in Multi-Agent Systems: A Multi-Perspective Benchmark and Evaluation
Mar 26, 2026Failure attribution is essential for diagnosing and improving multi-agent systems (MAS), yet existing benchmarks and methods largely assume a single deterministic root cause for each failure. In practice, MAS failures often admit multiple plausible attributions due to complex inter-agent dependencies and ambiguous execution trajectories. We revisit MAS failure attribution from a multi-perspective standpoint and propose multi-perspective failure attribution, a practical paradigm that explicitly accounts for attribution ambiguity. To support this setting, we introduce MP-Bench, the first benchmark designed for multi-perspective failure attribution in MAS, along with a new evaluation protocol tailored to this paradigm. Through extensive experiments, we find that prior conclusions suggesting LLMs struggle with failure attribution are largely driven by limitations in existing benchmark designs. Our results highlight the necessity of multi-perspective benchmarks and evaluation protocols for realistic and reliable MAS debugging.
GT-SVJ: Generative-Transformer-Based Self-Supervised Video Judge For Efficient Video Reward Modeling
Feb 05, 2026Aligning video generative models with human preferences remains challenging: current approaches rely on Vision-Language Models (VLMs) for reward modeling, but these models struggle to capture subtle temporal dynamics. We propose a fundamentally different approach: repurposing video generative models, which are inherently designed to model temporal structure, as reward models. We present the Generative-Transformer-based Self-Supervised Video Judge (\modelname), a novel evaluation model that transforms state-of-the-art video generation models into powerful temporally-aware reward models. Our key insight is that generative models can be reformulated as energy-based models (EBMs) that assign low energy to high-quality videos and high energy to degraded ones, enabling them to discriminate video quality with remarkable precision when trained via contrastive objectives. To prevent the model from exploiting superficial differences between real and generated videos, we design challenging synthetic negative videos through controlled latent-space perturbations: temporal slicing, feature swapping, and frame shuffling, which simulate realistic but subtle visual degradations. This forces the model to learn meaningful spatiotemporal features rather than trivial artifacts. \modelname achieves state-of-the-art performance on GenAI-Bench and MonteBench using only 30K human-annotations: $6\times$ to $65\times$ fewer than existing VLM-based approaches.
Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt Ensembles
Sep 10, 2025Multimodal large language models (MLLMs) are increasingly used to evaluate text-to-image (TTI) generation systems, providing automated judgments based on visual and textual context. However, these "judge" models often suffer from biases, overconfidence, and inconsistent performance across diverse image domains. While prompt ensembling has shown promise for mitigating these issues in unimodal, text-only settings, our experiments reveal that standard ensembling methods fail to generalize effectively for TTI tasks. To address these limitations, we propose a new multimodal-aware method called Multimodal Mixture-of-Bayesian Prompt Ensembles (MMB). Our method uses a Bayesian prompt ensemble approach augmented by image clustering, allowing the judge to dynamically assign prompt weights based on the visual characteristics of each sample. We show that MMB improves accuracy in pairwise preference judgments and greatly enhances calibration, making it easier to gauge the judge's true uncertainty. In evaluations on two TTI benchmarks, HPSv2 and MJBench, MMB outperforms existing baselines in alignment with human annotations and calibration across varied image content. Our findings highlight the importance of multimodal-specific strategies for judge calibration and suggest a promising path forward for reliable large-scale TTI evaluation.
Is Safety Standard Same for Everyone? User-Specific Safety Evaluation of Large Language Models
Feb 20, 2025As the use of large language model (LLM) agents continues to grow, their safety vulnerabilities have become increasingly evident. Extensive benchmarks evaluate various aspects of LLM safety by defining the safety relying heavily on general standards, overlooking user-specific standards. However, safety standards for LLM may vary based on a user-specific profiles rather than being universally consistent across all users. This raises a critical research question: Do LLM agents act safely when considering user-specific safety standards? Despite its importance for safe LLM use, no benchmark datasets currently exist to evaluate the user-specific safety of LLMs. To address this gap, we introduce U-SAFEBENCH, the first benchmark designed to assess user-specific aspect of LLM safety. Our evaluation of 18 widely used LLMs reveals current LLMs fail to act safely when considering user-specific safety standards, marking a new discovery in this field. To address this vulnerability, we propose a simple remedy based on chain-of-thought, demonstrating its effectiveness in improving user-specific safety. Our benchmark and code are available at https://github.com/yeonjun-in/U-SafeBench.
GUI Agents: A Survey
Dec 18, 2024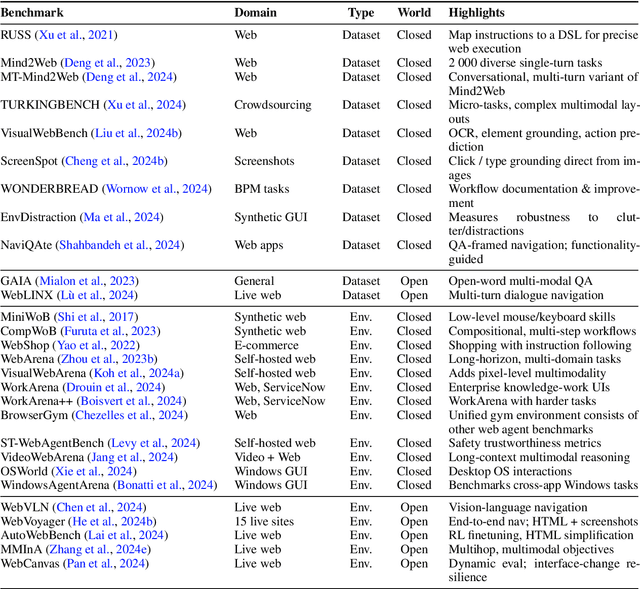
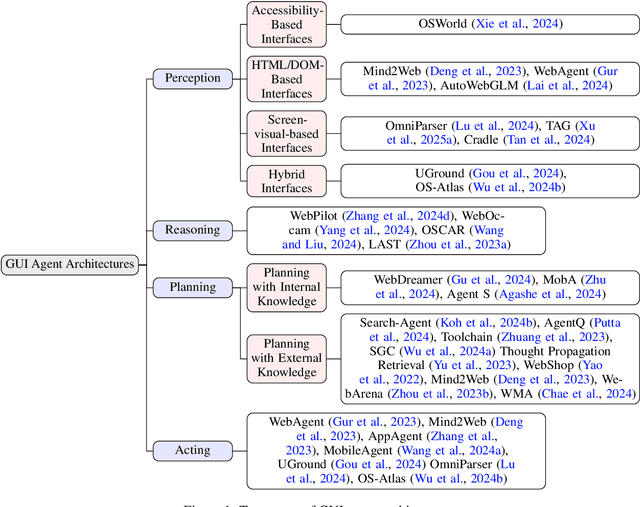

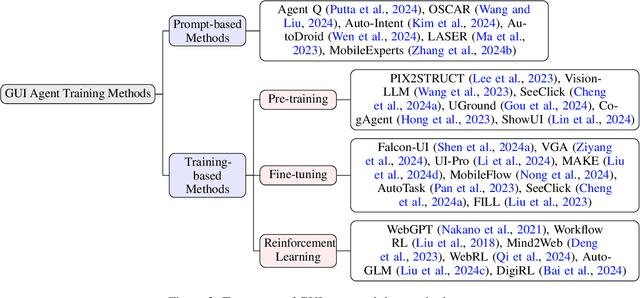
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.