 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Copilot: An Autonomous Causal Analysis Agent
Apr 21, 2025Causal analysis plays a foundational role in scientific discovery and reliable decision-making, yet it remains largely inaccessible to domain experts due to its conceptual and algorithmic complexity. This disconnect between causal methodology and practical usability presents a dual challenge: domain experts are unable to leverage recent advances in causal learning, while causal researchers lack broad, real-world deployment to test and refine their methods. To address this, we introduce Causal-Copilot, an autonomous agent that operationalizes expert-level causal analysis within a large language model framework. Causal-Copilot automates the full pipeline of causal analysis for both tabular and time-series data -- including causal discovery, causal inference, algorithm selection, hyperparameter optimization, result interpretation, and generation of actionable insights. It supports interactive refinement through natural language, lowering the barrier for non-specialists while preserving methodological rigor. By integrating over 20 state-of-the-art causal analysis techniques, our system fosters a virtuous cycle -- expanding access to advanced causal methods for domain experts while generating rich, real-world applications that inform and advance causal theory. Empirical evaluations demonstrate that Causal-Copilot achieves superior performance compared to existing baselines, offering a reliable, scalable, and extensible solution that bridges the gap between theoretical sophistication and real-world applicability in causal analysis. A live interactive demo of Causal-Copilot is available at https://causalcopilot.com/.
From Large to Super-Tiny: End-to-End Optimization for Cost-Efficient LLMs
Apr 18, 2025In recent years, Large Language Models (LLMs) have significantly advanced artificial intelligence by optimizing traditional Natural Language Processing (NLP) pipelines, improving performance and generalization. This has spurred their integration into various systems. Many NLP systems, including ours, employ a "one-stage" pipeline directly incorporating LLMs. While effective, this approach incurs substantial costs and latency due to the need for large model parameters to achieve satisfactory outcomes. This paper introduces a three-stage cost-efficient end-to-end LLM deployment pipeline-including prototyping, knowledge transfer, and model compression-to tackle the cost-performance dilemma in LLM-based frameworks. Our approach yields a super tiny model optimized for cost and performance in online systems, simplifying the system architecture. Initially, by transforming complex tasks into a function call-based LLM-driven pipeline, an optimal performance prototype system is constructed to produce high-quality data as a teacher model. The second stage combine techniques like rejection fine-tuning, reinforcement learning and knowledge distillation to transfer knowledge to a smaller 0.5B student model, delivering effective performance at minimal cost. The final stage applies quantization and pruning to extremely compress model to 0.4B, achieving ultra-low latency and cost. The framework's modular design and cross-domain capabilities suggest potential applicability in other NLP areas.
Real-time High-fidelity Gaussian Human Avatars with Position-based Interpolation of Spatially Distributed MLPs
Apr 17, 2025



Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing the ability to learn high-frequency spatial signals. We further use control points to constrain the Gaussians distributed on a surface layer rather than allowing them to be irregularly distributed inside the body, to help the human avatar generalize better when animated under novel poses. Compared to the state-of-the-art method, our method achieves better appearance quality with finer details while the rendering speed is significantly faster under novel views and novel poses.
High-fidelity 3D Object Generation from Single Image with RGBN-Volume Gaussian Reconstruction Model
Apr 02, 2025Recently single-view 3D generation via Gaussian splatting has emerged and developed quickly. They learn 3D Gaussians from 2D RGB images generated from pre-trained multi-view diffusion (MVD) models, and have shown a promising avenue for 3D generation through a single image. Despite the current progress, these methods still suffer from the inconsistency jointly caused by the geometric ambiguity in the 2D images, and the lack of structure of 3D Gaussians, leading to distorted and blurry 3D object generation. In this paper, we propose to fix these issues by GS-RGBN, a new RGBN-volume Gaussian Reconstruction Model designed to generate high-fidelity 3D objects from single-view images. Our key insight is a structured 3D representation can simultaneously mitigate the afore-mentioned two issues. To this end, we propose a novel hybrid Voxel-Gaussian representation, where a 3D voxel representation contains explicit 3D geometric information, eliminating the geometric ambiguity from 2D images. It also structures Gaussians during learning so that the optimization tends to find better local optima. Our 3D voxel representation is obtained by a fusion module that aligns RGB features and surface normal features, both of which can be estimated from 2D images. Extensive experiments demonstrate the superiority of our methods over prior works in terms of high-quality reconstruction results, robust generalization, and good efficiency.
RGBAvatar: Reduced Gaussian Blendshapes for Online Modeling of Head Avatars
Mar 17, 2025We present Reduced Gaussian Blendshapes Avatar (RGBAvatar), a method for reconstructing photorealistic, animatable head avatars at speeds sufficient for on-the-fly reconstruction. Unlike prior approaches that utilize linear bases from 3D morphable models (3DMM) to model Gaussian blendshapes, our method maps tracked 3DMM parameters into reduced blendshape weights with an MLP, leading to a compact set of blendshape bases. The learned compact base composition effectively captures essential facial details for specific individuals, and does not rely on the fixed base composition weights of 3DMM, leading to enhanced reconstruction quality and higher efficiency. To further expedite the reconstruction process, we develop a novel color initialization estimation method and a batch-parallel Gaussian rasterization process, achieving state-of-the-art quality with training throughput of about 630 images per second. Moreover, we propose a local-global sampling strategy that enables direct on-the-fly reconstruction, immediately reconstructing the model as video streams in real time while achieving quality comparable to offline settings. Our source code is available at https://github.com/gapszju/RGBAvatar.
Pre-Training Meta-Rule Selection Policy for Visual Generative Abductive Learning
Mar 09, 2025Visual generative abductive learning studies jointly training symbol-grounded neural visual generator and inducing logic rules from data, such that after learning, the visual generation process is guided by the induced logic rules. A major challenge for this task is to reduce the time cost of logic abduction during learning, an essential step when the logic symbol set is large and the logic rule to induce is complicated. To address this challenge, we propose a pre-training method for obtaining meta-rule selection policy for the recently proposed visual generative learning approach AbdGen [Peng et al., 2023], aiming at significantly reducing the candidate meta-rule set and pruning the search space. The selection model is built based on the embedding representation of both symbol grounding of cases and meta-rules, which can be effectively integrated with both neural model and logic reasoning system. The pre-training process is done on pure symbol data, not involving symbol grounding learning of raw visual inputs, making the entire learning process low-cost. An additional interesting observation is that the selection policy can rectify symbol grounding errors unseen during pre-training, which is resulted from the memorization ability of attention mechanism and the relative stability of symbolic patterns. Experimental results show that our method is able to effectively address the meta-rule selection problem for visual abduction, boosting the efficiency of visual generative abductive learning. Code is available at https://github.com/future-item/metarule-select.
Do we Really Need Visual Instructions? Towards Visual Instruction-Free Fine-tuning for Large Vision-Language Models
Feb 17, 2025Visual instruction tuning has become the predominant technology in eliciting the multimodal task-solving capabilities of large vision-language models (LVLMs). Despite the success, as visual instructions require images as the input, it would leave the gap in inheriting the task-solving capabilities from the backbone LLMs, and make it costly to collect a large-scale dataset. To address it, we propose ViFT, a visual instruction-free fine-tuning framework for LVLMs. In ViFT, we only require the text-only instructions and image caption data during training, to separately learn the task-solving and visual perception abilities. During inference, we extract and combine the representations of the text and image inputs, for fusing the two abilities to fulfill multimodal tasks. Experimental results demonstrate that ViFT can achieve state-of-the-art performance on several visual reasoning and visual instruction following benchmarks, with rather less training data. Our code and data will be publicly released.
Conditional Latent Diffusion-Based Speech Enhancement Via Dual Context Learning
Jan 17, 2025Recently, the application of diffusion probabilistic models has advanced speech enhancement through generative approaches. However, existing diffusion-based methods have focused on the generation process in high-dimensional waveform or spectral domains, leading to increased generation complexity and slower inference speeds. Additionally, these methods have primarily modelled clean speech distributions, with limited exploration of noise distributions, thereby constraining the discriminative capability of diffusion models for speech enhancement. To address these issues, we propose a novel approach that integrates a conditional latent diffusion model (cLDM) with dual-context learning (DCL). Our method utilizes a variational autoencoder (VAE) to compress mel-spectrograms into a low-dimensional latent space. We then apply cLDM to transform the latent representations of both clean speech and background noise into Gaussian noise by the DCL process, and a parameterized model is trained to reverse this process, conditioned on noisy latent representations and text embeddings. By operating in a lower-dimensional space, the latent representations reduce the complexity of the generation process, while the DCL process enhances the model's ability to handle diverse and unseen noise environments. Our experiments demonstrate the strong performance of the proposed approach compared to existing diffusion-based methods, even with fewer iterative steps, and highlight the superior generalization capability of our models to out-of-domain noise datasets (https://github.com/modelscope/ClearerVoice-Studio).
HiFi-SR: A Unified Generative Transformer-Convolutional Adversarial Network for High-Fidelity Speech Super-Resolution
Jan 17, 2025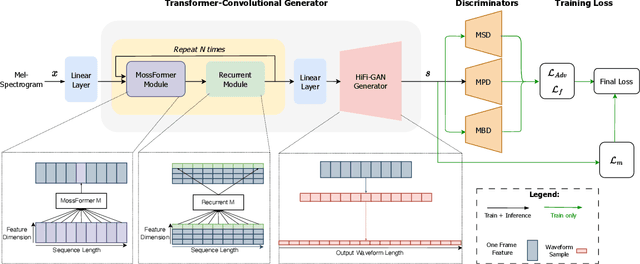
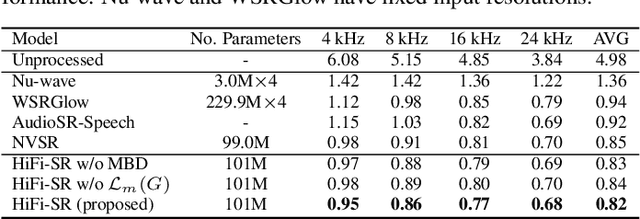

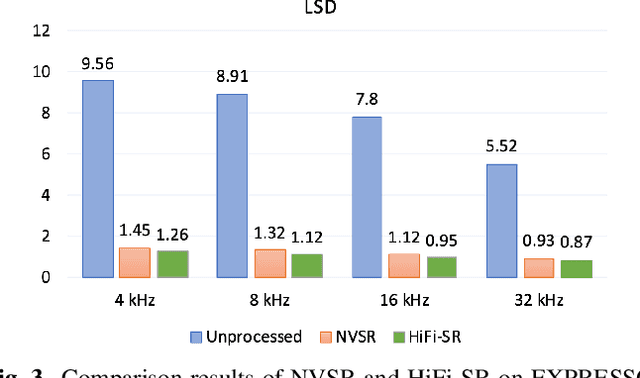
The application of generative adversarial networks (GANs) has recently advanced speech super-resolution (SR) based on intermediate representations like mel-spectrograms. However, existing SR methods that typically rely on independently trained and concatenated networks may lead to inconsistent representations and poor speech quality, especially in out-of-domain scenarios. In this work, we propose HiFi-SR, a unified network that leverages end-to-end adversarial training to achieve high-fidelity speech super-resolution. Our model features a unified transformer-convolutional generator designed to seamlessly handle both the prediction of latent representations and their conversion into time-domain waveforms. The transformer network serves as a powerful encoder, converting low-resolution mel-spectrograms into latent space representations, while the convolutional network upscales these representations into high-resolution waveforms. To enhance high-frequency fidelity, we incorporate a multi-band, multi-scale time-frequency discriminator, along with a multi-scale mel-reconstruction loss in the adversarial training process. HiFi-SR is versatile, capable of upscaling any input speech signal between 4 kHz and 32 kHz to a 48 kHz sampling rate. Experimental results demonstrate that HiFi-SR significantly outperforms existing speech SR methods across both objective metrics and ABX preference tests, for both in-domain and out-of-domain scenarios (https://github.com/modelscope/ClearerVoice-Studio).
YuLan-Mini: An Open Data-efficient Language Model
Dec 24, 2024



Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.