 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond single receptive field: A receptive field fusion-and-stratification network for airborne laser scanning point cloud classification
Jul 21, 2022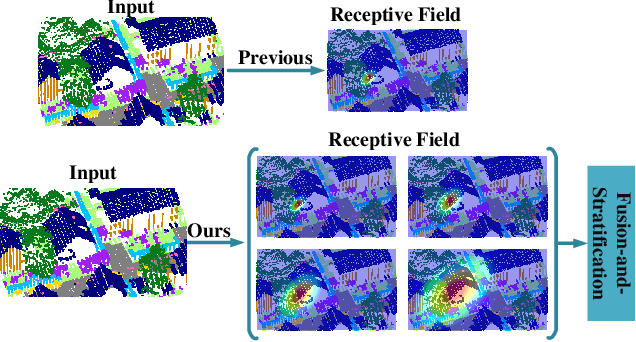
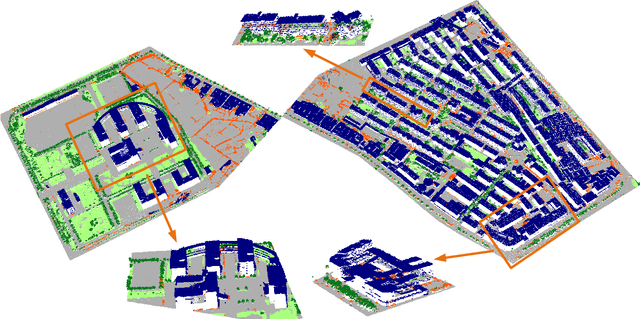

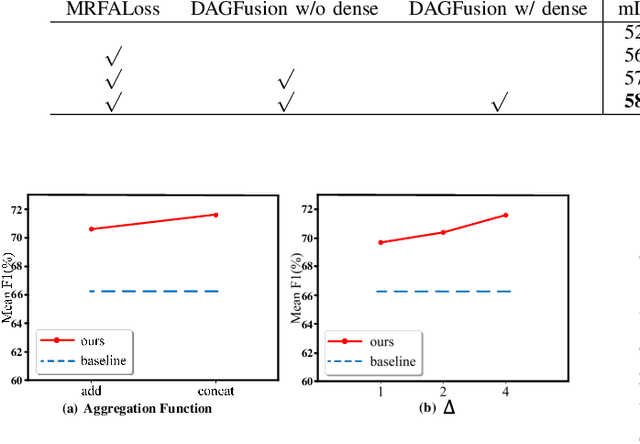
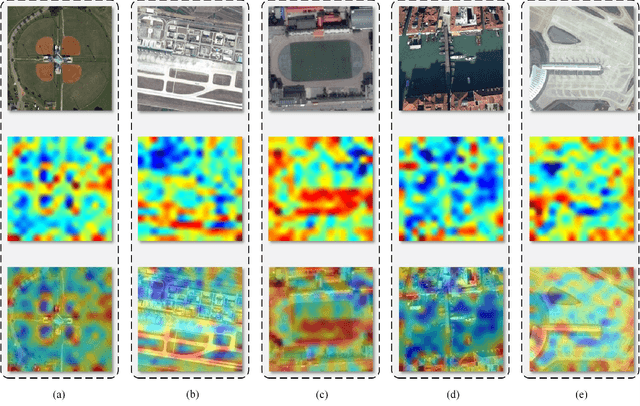
The classification of airborne laser scanning (ALS) point clouds is a critical task of remote sensing and photogrammetry fields. Although recent deep learning-based methods have achieved satisfactory performance, they have ignored the unicity of the receptive field, which makes the ALS point cloud classification remain challenging for the distinguishment of the areas with complex structures and extreme scale variations. In this article, for the objective of configuring multi-receptive field features, we propose a novel receptive field fusion-and-stratification network (RFFS-Net). With a novel dilated graph convolution (DGConv) and its extension annular dilated convolution (ADConv) as basic building blocks, the receptive field fusion process is implemented with the dilated and annular graph fusion (DAGFusion) module, which obtains multi-receptive field feature representation through capturing dilated and annular graphs with various receptive regions. The stratification of the receptive fields with point sets of different resolutions as the calculation bases is performed with Multi-level Decoders nested in RFFS-Net and driven by the multi-level receptive field aggregation loss (MRFALoss) to drive the network to learn in the direction of the supervision labels with different resolutions. With receptive field fusion-and-stratification, RFFS-Net is more adaptable to the classification of regions with complex structures and extreme scale variations in large-scale ALS point clouds. Evaluated on the ISPRS Vaihingen 3D dataset, our RFFS-Net significantly outperforms the baseline approach by 5.3% on mF1 and 5.4% on mIoU, accomplishing an overall accuracy of 82.1%, an mF1 of 71.6%, and an mIoU of 58.2%. Furthermore, experiments on the LASDU dataset and the 2019 IEEE-GRSS Data Fusion Contest dataset show that RFFS-Net achieves a new state-of-the-art classification performance.
Exploring a Fine-Grained Multiscale Method for Cross-Modal Remote Sensing Image Retrieval
Apr 21, 2022
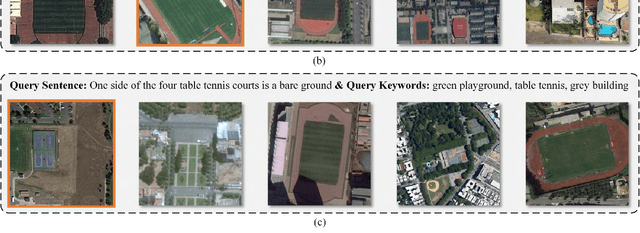
Remote sensing (RS) cross-modal text-image retrieval has attracted extensive attention for its advantages of flexible input and efficient query. However, traditional methods ignore the characteristics of multi-scale and redundant targets in RS image, leading to the degradation of retrieval accuracy. To cope with the problem of multi-scale scarcity and target redundancy in RS multimodal retrieval task, we come up with a novel asymmetric multimodal feature matching network (AMFMN). Our model adapts to multi-scale feature inputs, favors multi-source retrieval methods, and can dynamically filter redundant features. AMFMN employs the multi-scale visual self-attention (MVSA) module to extract the salient features of RS image and utilizes visual features to guide the text representation. Furthermore, to alleviate the positive samples ambiguity caused by the strong intraclass similarity in RS image, we propose a triplet loss function with dynamic variable margin based on prior similarity of sample pairs. Finally, unlike the traditional RS image-text dataset with coarse text and higher intraclass similarity, we construct a fine-grained and more challenging Remote sensing Image-Text Match dataset (RSITMD), which supports RS image retrieval through keywords and sentence separately and jointly. Experiments on four RS text-image datasets demonstrate that the proposed model can achieve state-of-the-art performance in cross-modal RS text-image retrieval task.
Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information
Apr 21, 2022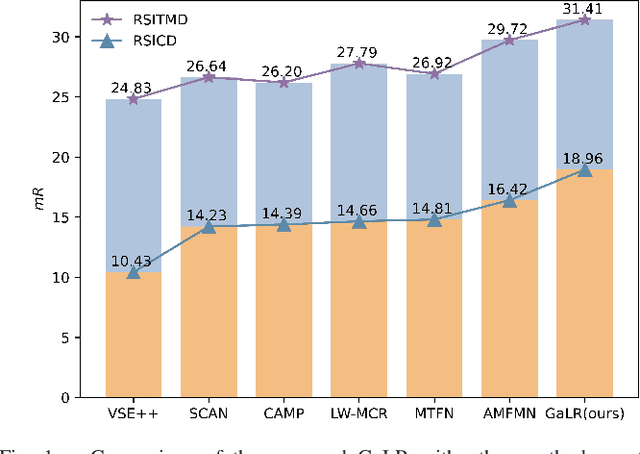
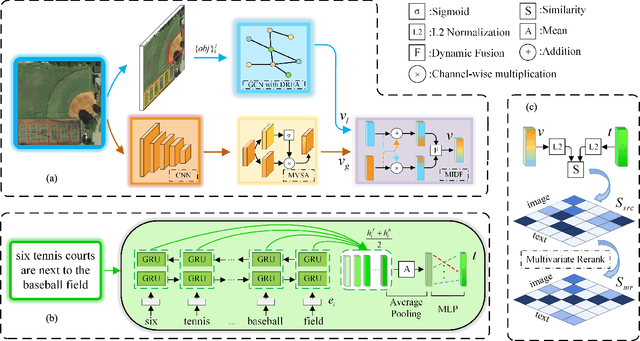
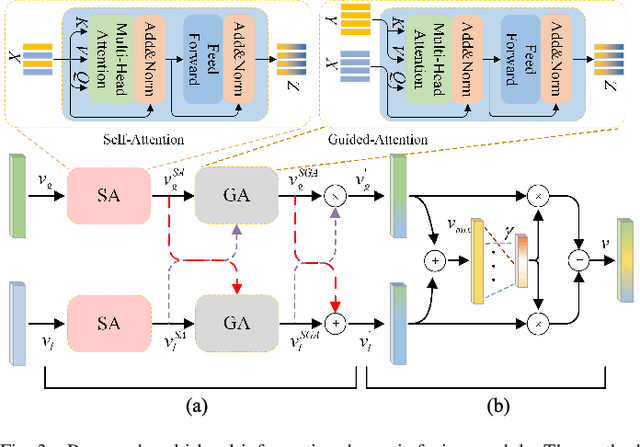
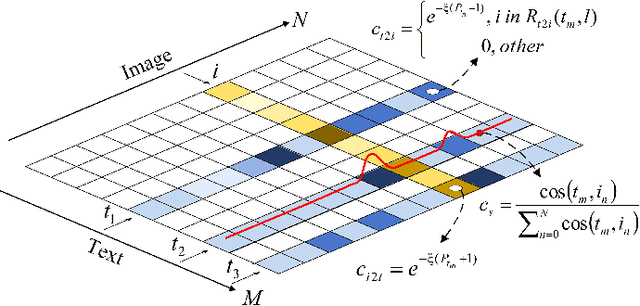
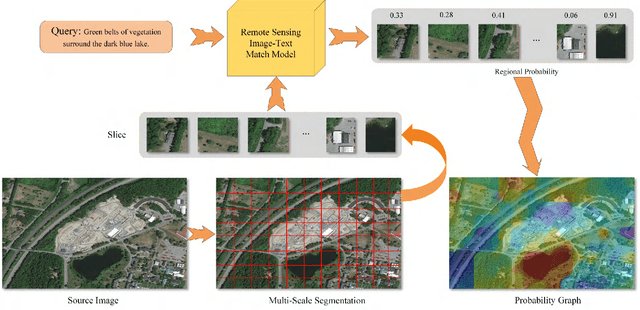
Cross-modal remote sensing text-image retrieval (RSCTIR) has recently become an urgent research hotspot due to its ability of enabling fast and flexible information extraction on remote sensing (RS) images. However, current RSCTIR methods mainly focus on global features of RS images, which leads to the neglect of local features that reflect target relationships and saliency. In this article, we first propose a novel RSCTIR framework based on global and local information (GaLR), and design a multi-level information dynamic fusion (MIDF) module to efficaciously integrate features of different levels. MIDF leverages local information to correct global information, utilizes global information to supplement local information, and uses the dynamic addition of the two to generate prominent visual representation. To alleviate the pressure of the redundant targets on the graph convolution network (GCN) and to improve the model s attention on salient instances during modeling local features, the de-noised representation matrix and the enhanced adjacency matrix (DREA) are devised to assist GCN in producing superior local representations. DREA not only filters out redundant features with high similarity, but also obtains more powerful local features by enhancing the features of prominent objects. Finally, to make full use of the information in the similarity matrix during inference, we come up with a plug-and-play multivariate rerank (MR) algorithm. The algorithm utilizes the k nearest neighbors of the retrieval results to perform a reverse search, and improves the performance by combining multiple components of bidirectional retrieval. Extensive experiments on public datasets strongly demonstrate the state-of-the-art performance of GaLR methods on the RSCTIR task. The code of GaLR method, MR algorithm, and corresponding files have been made available at https://github.com/xiaoyuan1996/GaLR .
Semantic Segmentation for Point Cloud Scenes via Dilated Graph Feature Aggregation and Pyramid Decoders
Apr 11, 2022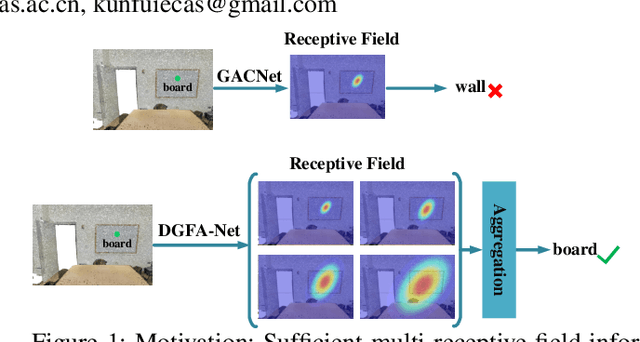
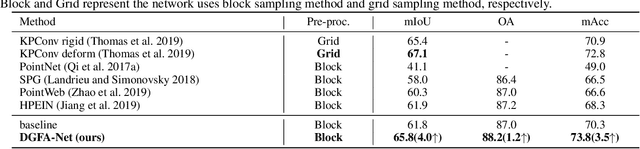
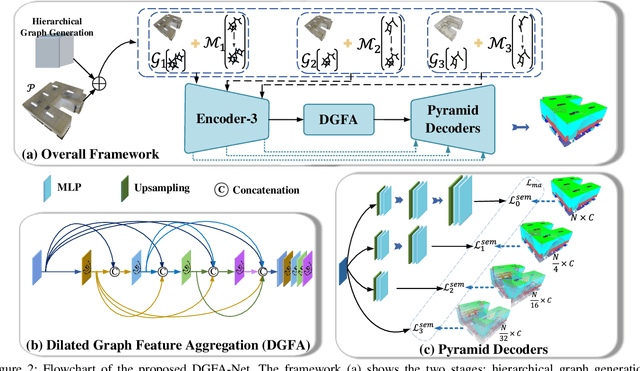

Semantic segmentation of point clouds generates comprehensive understanding of scenes through densely predicting the category for each point. Due to the unicity of receptive field, semantic segmentation of point clouds remains challenging for the expression of multi-receptive field features, which brings about the misclassification of instances with similar spatial structures. In this paper, we propose a graph convolutional network DGFA-Net rooted in dilated graph feature aggregation (DGFA), guided by multi-basis aggregation loss (MALoss) calculated through Pyramid Decoders. To configure multi-receptive field features, DGFA which takes the proposed dilated graph convolution (DGConv) as its basic building block, is designed to aggregate multi-scale feature representation by capturing dilated graphs with various receptive regions. By simultaneously considering penalizing the receptive field information with point sets of different resolutions as calculation bases, we introduce Pyramid Decoders driven by MALoss for the diversity of receptive field bases. Combining these two aspects, DGFA-Net significantly improves the segmentation performance of instances with similar spatial structures. Experiments on S3DIS, ShapeNetPart and Toronto-3D show that DGFA-Net outperforms the baseline approach, achieving a new state-of-the-art segmentation performance.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 24, 2021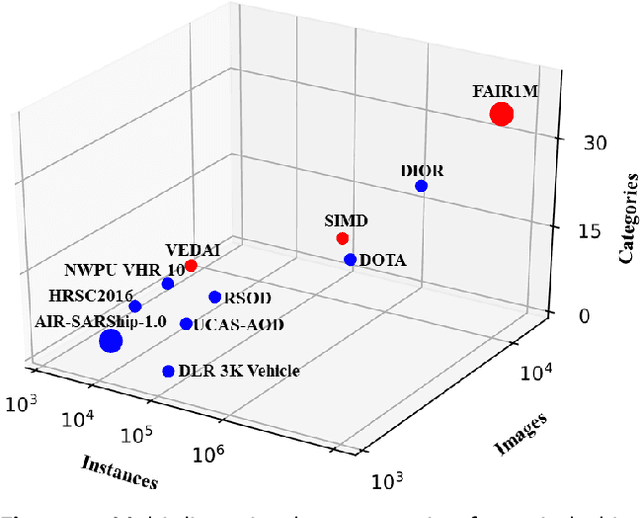
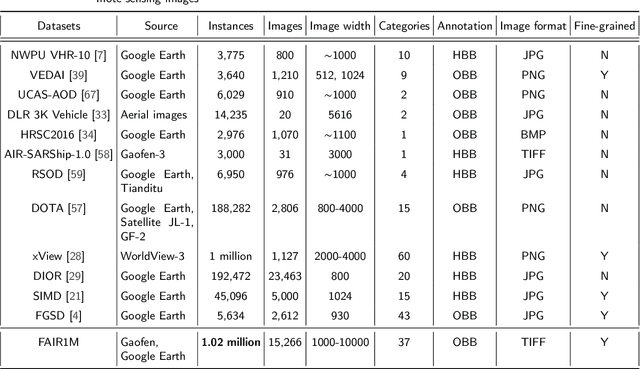
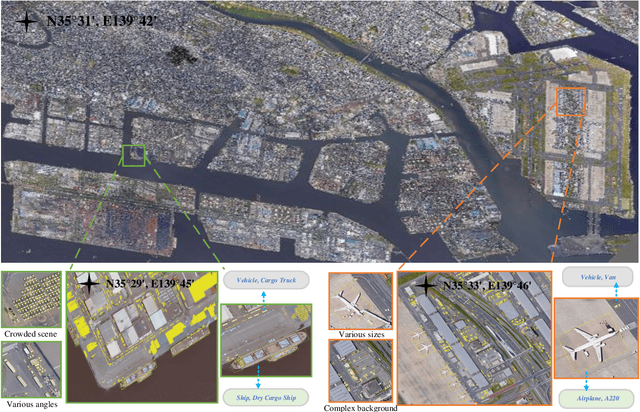
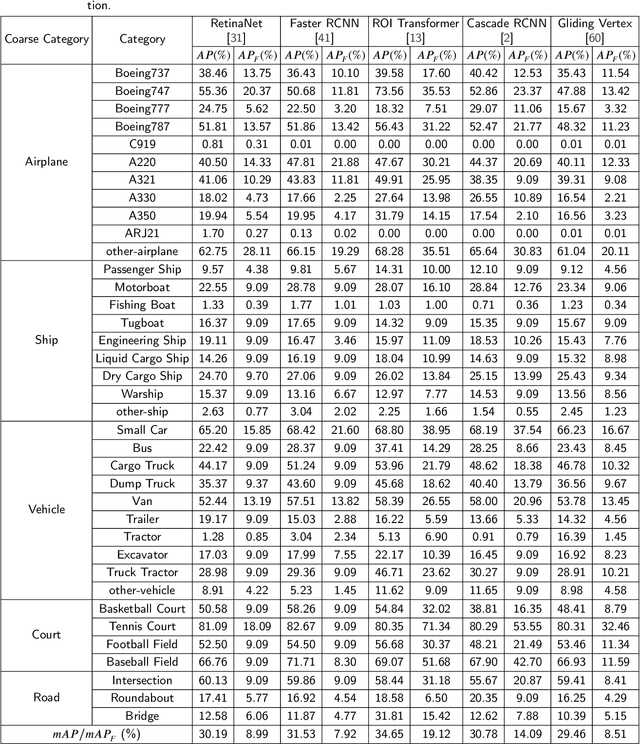
With the rapid development of deep learning, many deep learning-based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning-based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.
Road Network Metric Learning for Estimated Time of Arrival
Jun 24, 2020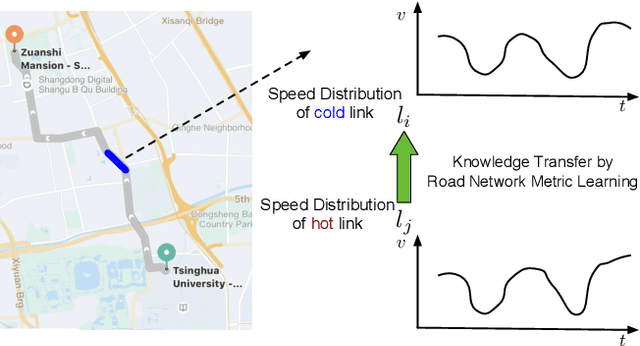
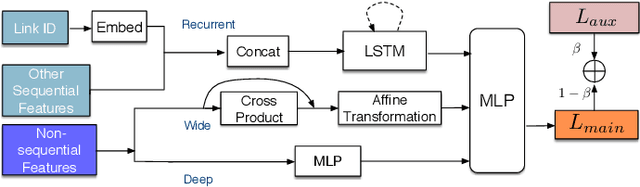
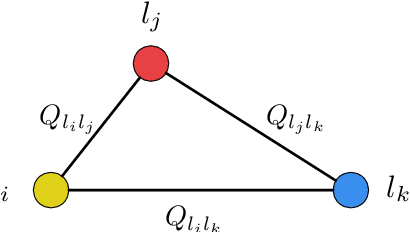
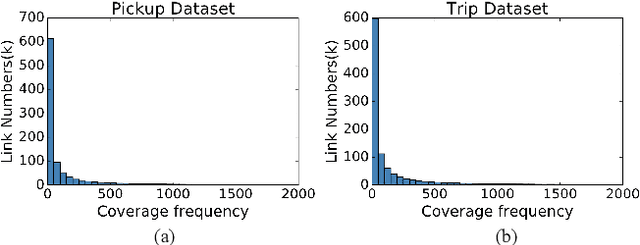
Recently, deep learning have achieved promising results in Estimated Time of Arrival (ETA), which is considered as predicting the travel time from the origin to the destination along a given path. One of the key techniques is to use embedding vectors to represent the elements of road network, such as the links (road segments). However, the embedding suffers from the data sparsity problem that many links in the road network are traversed by too few floating cars even in large ride-hailing platforms like Uber and DiDi. Insufficient data makes the embedding vectors in an under-fitting status, which undermines the accuracy of ETA prediction. To address the data sparsity problem, we propose the Road Network Metric Learning framework for ETA (RNML-ETA). It consists of two components: (1) a main regression task to predict the travel time, and (2) an auxiliary metric learning task to improve the quality of link embedding vectors. We further propose the triangle loss, a novel loss function to improve the efficiency of metric learning. We validated the effectiveness of RNML-ETA on large scale real-world datasets, by showing that our method outperforms the state-of-the-art model and the promotion concentrates on the cold links with few data.
FMA-ETA: Estimating Travel Time Entirely Based on FFN With Attention
Jun 07, 2020
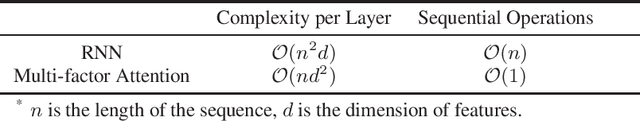
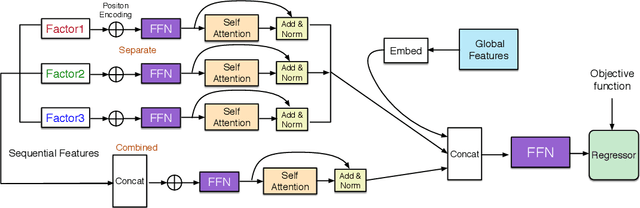
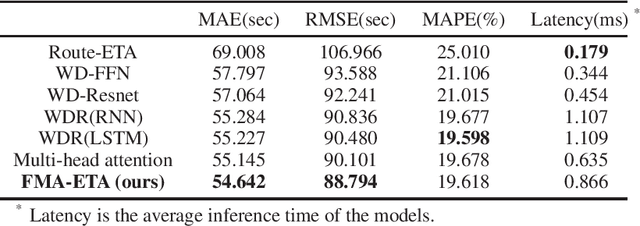
Estimated time of arrival (ETA) is one of the most important services in intelligent transportation systems and becomes a challenging spatial-temporal (ST) data mining task in recent years. Nowadays, deep learning based methods, specifically recurrent neural networks (RNN) based ones are adapted to model the ST patterns from massive data for ETA and become the state-of-the-art. However, RNN is suffering from slow training and inference speed, as its structure is unfriendly to parallel computing. To solve this problem, we propose a novel, brief and effective framework mainly based on feed-forward network (FFN) for ETA, FFN with Multi-factor self-Attention (FMA-ETA). The novel Multi-factor self-attention mechanism is proposed to deal with different category features and aggregate the information purposefully. Extensive experimental results on the real-world vehicle travel dataset show FMA-ETA is competitive with state-of-the-art methods in terms of the prediction accuracy with significantly better inference speed.
Fusion Recurrent Neural Network
Jun 07, 2020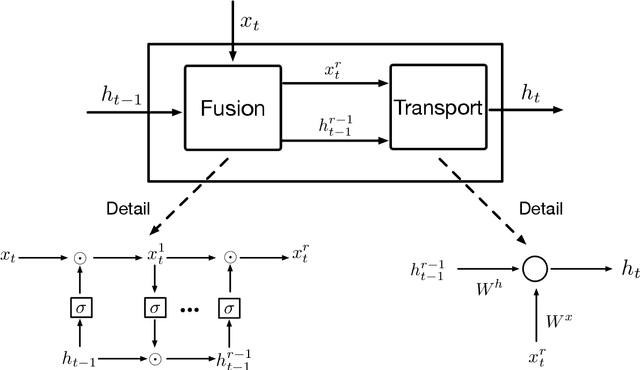


Considering deep sequence learning for practical application, two representative RNNs - LSTM and GRU may come to mind first. Nevertheless, is there no chance for other RNNs? Will there be a better RNN in the future? In this work, we propose a novel, succinct and promising RNN - Fusion Recurrent Neural Network (Fusion RNN). Fusion RNN is composed of Fusion module and Transport module every time step. Fusion module realizes the multi-round fusion of the input and hidden state vector. Transport module which mainly refers to simple recurrent network calculate the hidden state and prepare to pass it to the next time step. Furthermore, in order to evaluate Fusion RNN's sequence feature extraction capability, we choose a representative data mining task for sequence data, estimated time of arrival (ETA) and present a novel model based on Fusion RNN. We contrast our method and other variants of RNN for ETA under massive vehicle travel data from DiDi Chuxing. The results demonstrate that for ETA, Fusion RNN is comparable to state-of-the-art LSTM and GRU which are more complicated than Fusion RNN.
Constructing Geographic and Long-term Temporal Graph for Traffic Forecasting
Apr 23, 2020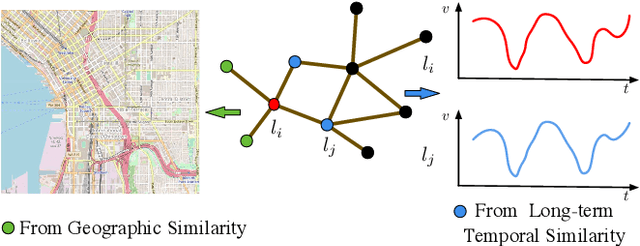
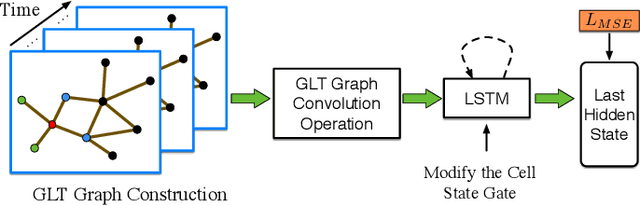
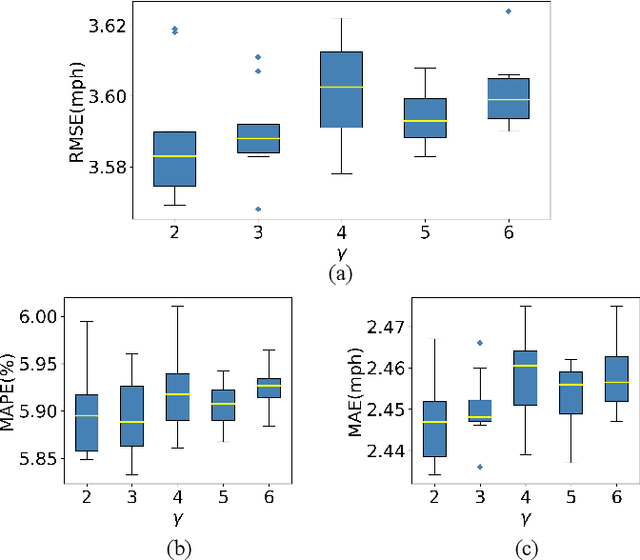
Traffic forecasting influences various intelligent transportation system (ITS) services and is of great significance for user experience as well as urban traffic control. It is challenging due to the fact that the road network contains complex and time-varying spatial-temporal dependencies. Recently, deep learning based methods have achieved promising results by adopting graph convolutional network (GCN) to extract the spatial correlations and recurrent neural network (RNN) to capture the temporal dependencies. However, the existing methods often construct the graph only based on road network connectivity, which limits the interaction between roads. In this work, we propose Geographic and Long term Temporal Graph Convolutional Recurrent Neural Network (GLT-GCRNN), a novel framework for traffic forecasting that learns the rich interactions between roads sharing similar geographic or longterm temporal patterns. Extensive experiments on a real-world traffic state dataset validate the effectiveness of our method by showing that GLT-GCRNN outperforms the state-of-the-art methods in terms of different metrics.
Comparison Network for One-Shot Conditional Object Detection
Apr 04, 2019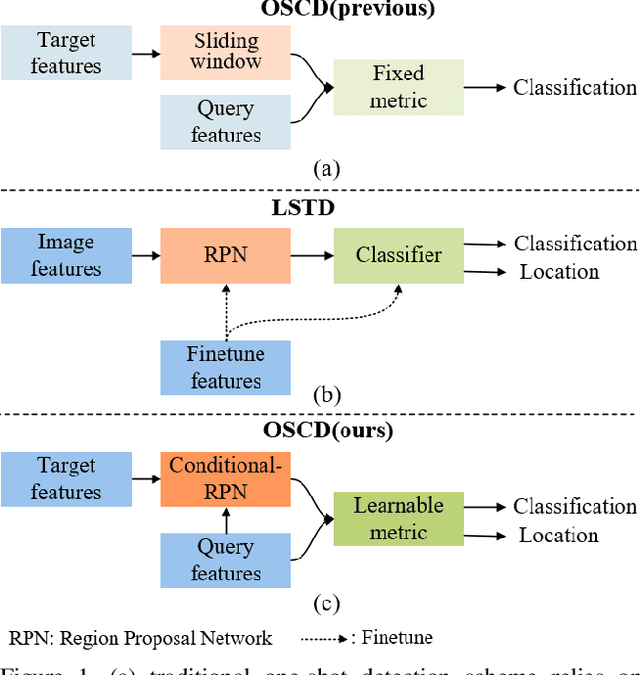
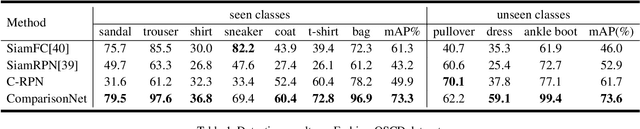

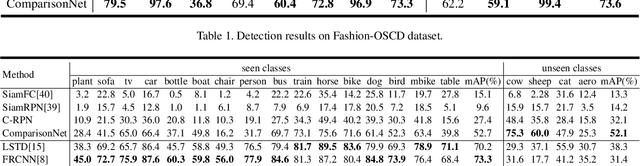
The current advances in object detection depend on large-scale datasets to get good performance. However, there may not always be sufficient samples in many scenarios, which leads to the research on few-shot detection as well as its extreme variation one-shot detection. In this paper, the one-shot detection has been formulated as a conditional probability problem. With this insight, a novel one-shot conditional object detection (OSCD) framework, referred as Comparison Network (ComparisonNet), has been proposed. Specifically, query and target image features are extracted through a Siamese network as mapped metrics of marginal probabilities. A two-stage detector for OSCD is introduced to compare the extracted query and target features with the learnable metric to approach the optimized non-linear conditional probability. Once trained, ComparisonNet can detect objects of both seen and unseen classes without further training, which also has the advantages including class-agnostic, training-free for unseen classes, and without catastrophic forgetting. Experiments show that the proposed approach achieves state-of-the-art performance on the proposed datasets of Fashion-MNIST and PASCAL VOC.