 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORA: Analyzing and bridging thinking-answer gap in Multimodal RLVR via Consistency-Oriented Reasoning Alignment
Jun 12, 2026Reinforcement learning with verifiable rewards (RLVR) has successfully elicited the reasoning capabilities of large language models, motivating its extension to multimodal scenarios. Existing methods primarily focus on improving the visual coverage of reasoning traces and mitigating visual hallucinations, but underestimate the semantic inconsistency between the reasoning process and the final answer. In this paper, we delve into thinking-answer inconsistency in RLVR for large vision-language models (LVLMs), showing thorough analyses of rollouts collected throughout Group Relative Policy Optimization (GRPO) training process and post-RLVR evaluation outputs that this issue persists during training and remains present during inference. Motivated by the analysis, we propose Consistency-Oriented Reasoning Alignment (CORA), which introduces thinking-answer semantic consistency into RLVR through a lightweight plug-and-play consistency reward model, and further incorporates Hybrid Reward Advantage Splitting (HRAS) to stably coordinate task and consistency optimization. Extensive experiments across representative multimodal reasoning benchmarks and mainstream LVLMs show that CORA improves task performance while effectively mitigating thinking-answer inconsistency, leading to more faithful reasoning traces.
HIPIF: Hierarchical Planning and Information Folding for Long-Horizon LLM Agent Learning
Jun 09, 2026While Large Language Models (LLMs) have demonstrated strong capabilities as autonomous agents across a wide range of tasks, their performance often degrades in multi-turn long-horizon agentic tasks. Existing methods have made progress through fine-grained credit assignment to alleviate long-horizon sparse rewards and hierarchical reinforcement learning to decompose tasks and reduce long-term dependency. However, these methods still do not directly address long-context interference, in which continuously growing histories weaken the agent's ability to track the global task state and impair subsequent reasoning and decision-making. Inspired by the way humans handle complex tasks through subgoal decomposition and completed progress summarization, we propose Hierarchical Planning and Information Folding (HIPIF) for long-horizon LLM agent learning. HIPIF trains the agent end-to-end to organize long-horizon execution around explicit subgoals while folding completed subgoal histories to reduce long-context interference. Furthermore, to stabilize subgoal-based planning and execution, HIPIF combines hierarchical reflection and subgoal-oriented process rewards to guide subgoal generation, transition, and execution, without relying on costly auxiliary models or task-specific expert trajectories. Extensive experiments on three publicly available agentic benchmarks demonstrate the validity of our method.
Faithful-MR1: Faithful Multimodal Reasoning via Anchoring and Reinforcing Visual Attention
May 21, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for advancing complex reasoning in large language models, and recent work extends RLVR to multimodal large language models (MLLMs). This transfer, however, surfaces a faithfulness challenge: faithful perception of task-relevant visual evidence and faithful use of that evidence during reasoning, leading to unsatisfactory gains on multimodal benchmarks. Specifically, existing perception supervision often operates on textual descriptions rather than natively on image regions, and faithful use is largely overlooked, exposing the perception-reasoning disconnect where correctly perceived evidence is dropped or contradicted during reasoning. To close these gaps, we propose Faithful-MR1, a training framework that anchors and reinforces visual attention to address both halves of faithful multimodal reasoning. The Anchoring stage turns perception into an explicit pre-reasoning subtask, supervising a dedicated <Focus> token's attention directly against image regions rather than through textual descriptions. The Reinforcing stage exposes faithful use through counterfactual image intervention, rewarding answer-correct trajectories that concentrate visual attention where vision causally matters. Extensive experiments demonstrate that Faithful-MR1 outperforms recent multimodal reasoning baselines on both Qwen2.5-VL-Instruct 3B and 7B backbones while using substantially less training data.
HISR: Hindsight Information Modulated Segmental Process Rewards For Multi-turn Agentic Reinforcement Learning
Mar 19, 2026While large language models excel in diverse domains, their performance on complex longhorizon agentic decision-making tasks remains limited. Most existing methods concentrate on designing effective reward models (RMs) to advance performance via multi-turn reinforcement learning. However, they suffer from delayed propagation in sparse outcome rewards and unreliable credit assignment with potentially overly fine-grained and unfocused turnlevel process rewards. In this paper, we propose (HISR) exploiting Hindsight Information to modulate Segmental process Rewards, which closely aligns rewards with sub-goals and underscores significant segments to enhance the reliability of credit assignment. Specifically, a segment-level process RM is presented to assign rewards for each sub-goal in the task, avoiding excessively granular allocation to turns. To emphasize significant segments in the trajectory, a hindsight model is devised to reflect the preference of performing a certain action after knowing the trajectory outcome. With this characteristic, we design the ratios of sequence likelihoods between hindsight and policy model to measure action importance. The ratios are subsequently employed to aggregate segment importance scores, which in turn modulate segmental process rewards, enhancing credit assignment reliability. Extensive experimental results on three publicly benchmarks demonstrate the validity of our method.
Rectify Evaluation Preference: Improving LLMs' Critique on Math Reasoning via Perplexity-aware Reinforcement Learning
Nov 13, 2025To improve Multi-step Mathematical Reasoning (MsMR) of Large Language Models (LLMs), it is crucial to obtain scalable supervision from the corpus by automatically critiquing mistakes in the reasoning process of MsMR and rendering a final verdict of the problem-solution. Most existing methods rely on crafting high-quality supervised fine-tuning demonstrations for critiquing capability enhancement and pay little attention to delving into the underlying reason for the poor critiquing performance of LLMs. In this paper, we orthogonally quantify and investigate the potential reason -- imbalanced evaluation preference, and conduct a statistical preference analysis. Motivated by the analysis of the reason, a novel perplexity-aware reinforcement learning algorithm is proposed to rectify the evaluation preference, elevating the critiquing capability. Specifically, to probe into LLMs' critiquing characteristics, a One-to-many Problem-Solution (OPS) benchmark is meticulously constructed to quantify the behavior difference of LLMs when evaluating the problem solutions generated by itself and others. Then, to investigate the behavior difference in depth, we conduct a statistical preference analysis oriented on perplexity and find an intriguing phenomenon -- ``LLMs incline to judge solutions with lower perplexity as correct'', which is dubbed as \textit{imbalanced evaluation preference}. To rectify this preference, we regard perplexity as the baton in the algorithm of Group Relative Policy Optimization, supporting the LLMs to explore trajectories that judge lower perplexity as wrong and higher perplexity as correct. Extensive experimental results on our built OPS and existing available critic benchmarks demonstrate the validity of our method.
Thinking Like an Expert:Multimodal Hypergraph-of-Thought (HoT) Reasoning to boost Foundation Modals
Aug 11, 2023



Reasoning ability is one of the most crucial capabilities of a foundation model, signifying its capacity to address complex reasoning tasks. Chain-of-Thought (CoT) technique is widely regarded as one of the effective methods for enhancing the reasoning ability of foundation models and has garnered significant attention. However, the reasoning process of CoT is linear, step-by-step, similar to personal logical reasoning, suitable for solving general and slightly complicated problems. On the contrary, the thinking pattern of an expert owns two prominent characteristics that cannot be handled appropriately in CoT, i.e., high-order multi-hop reasoning and multimodal comparative judgement. Therefore, the core motivation of this paper is transcending CoT to construct a reasoning paradigm that can think like an expert. The hyperedge of a hypergraph could connect various vertices, making it naturally suitable for modelling high-order relationships. Inspired by this, this paper innovatively proposes a multimodal Hypergraph-of-Thought (HoT) reasoning paradigm, which enables the foundation models to possess the expert-level ability of high-order multi-hop reasoning and multimodal comparative judgement. Specifically, a textual hypergraph-of-thought is constructed utilizing triple as the primary thought to model higher-order relationships, and a hyperedge-of-thought is generated through multi-hop walking paths to achieve multi-hop inference. Furthermore, we devise a visual hypergraph-of-thought to interact with the textual hypergraph-of-thought via Cross-modal Co-Attention Graph Learning for multimodal comparative verification. Experimentations on the ScienceQA benchmark demonstrate the proposed HoT-based T5 outperforms CoT-based GPT3.5 and chatGPT, which is on par with CoT-based GPT4 with a lower model size.
Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information
Apr 21, 2022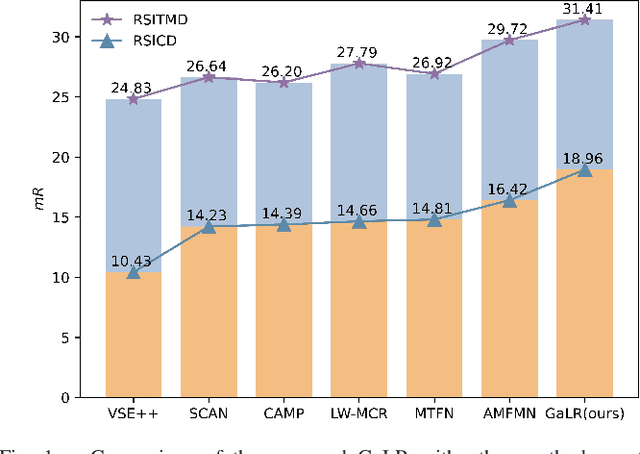
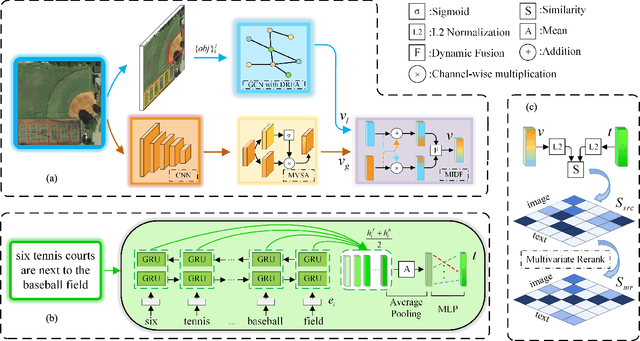
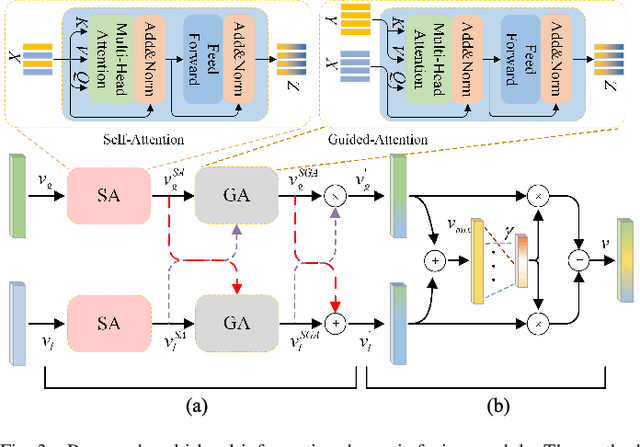
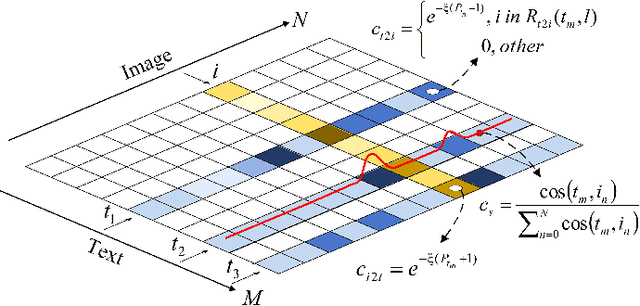
Cross-modal remote sensing text-image retrieval (RSCTIR) has recently become an urgent research hotspot due to its ability of enabling fast and flexible information extraction on remote sensing (RS) images. However, current RSCTIR methods mainly focus on global features of RS images, which leads to the neglect of local features that reflect target relationships and saliency. In this article, we first propose a novel RSCTIR framework based on global and local information (GaLR), and design a multi-level information dynamic fusion (MIDF) module to efficaciously integrate features of different levels. MIDF leverages local information to correct global information, utilizes global information to supplement local information, and uses the dynamic addition of the two to generate prominent visual representation. To alleviate the pressure of the redundant targets on the graph convolution network (GCN) and to improve the model s attention on salient instances during modeling local features, the de-noised representation matrix and the enhanced adjacency matrix (DREA) are devised to assist GCN in producing superior local representations. DREA not only filters out redundant features with high similarity, but also obtains more powerful local features by enhancing the features of prominent objects. Finally, to make full use of the information in the similarity matrix during inference, we come up with a plug-and-play multivariate rerank (MR) algorithm. The algorithm utilizes the k nearest neighbors of the retrieval results to perform a reverse search, and improves the performance by combining multiple components of bidirectional retrieval. Extensive experiments on public datasets strongly demonstrate the state-of-the-art performance of GaLR methods on the RSCTIR task. The code of GaLR method, MR algorithm, and corresponding files have been made available at https://github.com/xiaoyuan1996/GaLR .