 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of GlassNet for physics-informed machine learning of glass stability and glass-forming ability
Mar 19, 2024



Glasses form the basis of many modern applications and also hold great potential for future medical and environmental applications. However, their structural complexity and large composition space make design and optimization challenging for certain applications. Of particular importance for glass processing is an estimate of a given composition's glass-forming ability (GFA). However, there remain many open questions regarding the physical mechanisms of glass formation, especially in oxide glasses. It is apparent that a proxy for GFA would be highly useful in glass processing and design, but identifying such a surrogate property has proven itself to be difficult. Here, we explore the application of an open-source pre-trained NN model, GlassNet, that can predict the characteristic temperatures necessary to compute glass stability (GS) and assess the feasibility of using these physics-informed ML (PIML)-predicted GS parameters to estimate GFA. In doing so, we track the uncertainties at each step of the computation - from the original ML prediction errors, to the compounding of errors during GS estimation, and finally to the final estimation of GFA. While GlassNet exhibits reasonable accuracy on all individual properties, we observe a large compounding of error in the combination of these individual predictions for the prediction of GS, finding that random forest models offer similar accuracy to GlassNet. We also breakdown the ML performance on different glass families and find that the error in GS prediction is correlated with the error in crystallization peak temperature prediction. Lastly, we utilize this finding to assess the relationship between top-performing GS parameters and GFA for two ternary glass systems: sodium borosilicate and sodium iron phosphate glasses. We conclude that to obtain true ML predictive capability of GFA, significantly more data needs to be collected.
Viewpoint Integration and Registration with Vision Language Foundation Model for Image Change Understanding
Sep 15, 2023



Recently, the development of pre-trained vision language foundation models (VLFMs) has led to remarkable performance in many tasks. However, these models tend to have strong single-image understanding capability but lack the ability to understand multiple images. Therefore, they cannot be directly applied to cope with image change understanding (ICU), which requires models to capture actual changes between multiple images and describe them in language. In this paper, we discover that existing VLFMs perform poorly when applied directly to ICU because of the following problems: (1) VLFMs generally learn the global representation of a single image, while ICU requires capturing nuances between multiple images. (2) The ICU performance of VLFMs is significantly affected by viewpoint variations, which is caused by the altered relationships between objects when viewpoint changes. To address these problems, we propose a Viewpoint Integration and Registration method. Concretely, we introduce a fused adapter image encoder that fine-tunes pre-trained encoders by inserting designed trainable adapters and fused adapters, to effectively capture nuances between image pairs. Additionally, a viewpoint registration flow and a semantic emphasizing module are designed to reduce the performance degradation caused by viewpoint variations in the visual and semantic space, respectively. Experimental results on CLEVR-Change and Spot-the-Diff demonstrate that our method achieves state-of-the-art performance in all metrics.
RSGPT: A Remote Sensing Vision Language Model and Benchmark
Jul 28, 2023



The emergence of large-scale large language models, with GPT-4 as a prominent example, has significantly propelled the rapid advancement of artificial general intelligence and sparked the revolution of Artificial Intelligence 2.0. In the realm of remote sensing (RS), there is a growing interest in developing large vision language models (VLMs) specifically tailored for data analysis in this domain. However, current research predominantly revolves around visual recognition tasks, lacking comprehensive, large-scale image-text datasets that are aligned and suitable for training large VLMs, which poses significant challenges to effectively training such models for RS applications. In computer vision, recent research has demonstrated that fine-tuning large vision language models on small-scale, high-quality datasets can yield impressive performance in visual and language understanding. These results are comparable to state-of-the-art VLMs trained from scratch on massive amounts of data, such as GPT-4. Inspired by this captivating idea, in this work, we build a high-quality Remote Sensing Image Captioning dataset (RSICap) that facilitates the development of large VLMs in the RS field. Unlike previous RS datasets that either employ model-generated captions or short descriptions, RSICap comprises 2,585 human-annotated captions with rich and high-quality information. This dataset offers detailed descriptions for each image, encompassing scene descriptions (e.g., residential area, airport, or farmland) as well as object information (e.g., color, shape, quantity, absolute position, etc). To facilitate the evaluation of VLMs in the field of RS, we also provide a benchmark evaluation dataset called RSIEval. This dataset consists of human-annotated captions and visual question-answer pairs, allowing for a comprehensive assessment of VLMs in the context of RS.
Breaking Immutable: Information-Coupled Prototype Elaboration for Few-Shot Object Detection
Nov 27, 2022



Few-shot object detection, expecting detectors to detect novel classes with a few instances, has made conspicuous progress. However, the prototypes extracted by existing meta-learning based methods still suffer from insufficient representative information and lack awareness of query images, which cannot be adaptively tailored to different query images. Firstly, only the support images are involved for extracting prototypes, resulting in scarce perceptual information of query images. Secondly, all pixels of all support images are treated equally when aggregating features into prototype vectors, thus the salient objects are overwhelmed by the cluttered background. In this paper, we propose an Information-Coupled Prototype Elaboration (ICPE) method to generate specific and representative prototypes for each query image. Concretely, a conditional information coupling module is introduced to couple information from the query branch to the support branch, strengthening the query-perceptual information in support features. Besides, we design a prototype dynamic aggregation module that dynamically adjusts intra-image and inter-image aggregation weights to highlight the salient information useful for detecting query images. Experimental results on both Pascal VOC and MS COCO demonstrate that our method achieves state-of-the-art performance in almost all settings.
Bidirectional Feature Globalization for Few-shot Semantic Segmentation of 3D Point Cloud Scenes
Aug 17, 2022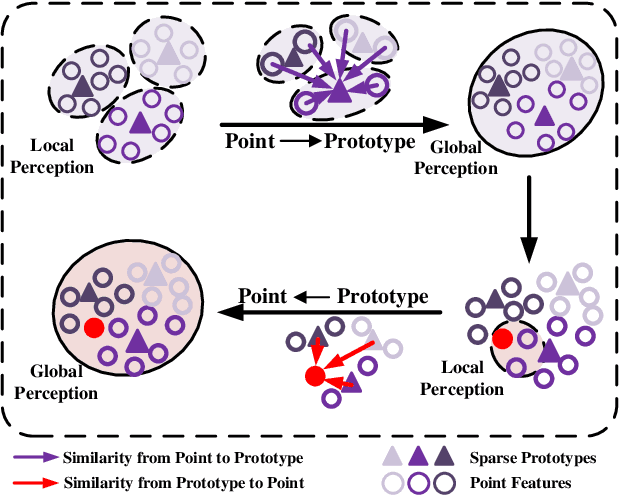
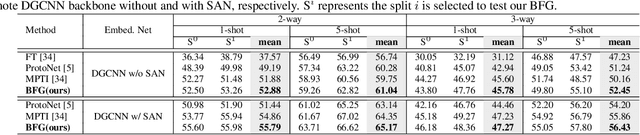
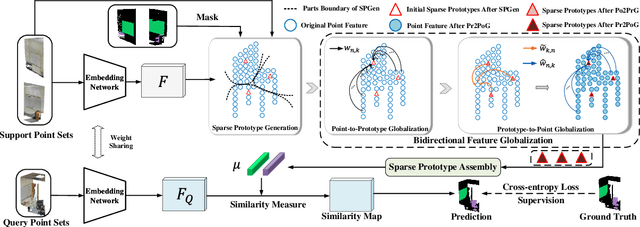
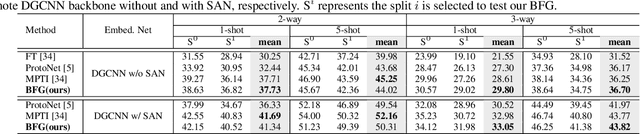
Few-shot segmentation of point cloud remains a challenging task, as there is no effective way to convert local point cloud information to global representation, which hinders the generalization ability of point features. In this study, we propose a bidirectional feature globalization (BFG) approach, which leverages the similarity measurement between point features and prototype vectors to embed global perception to local point features in a bidirectional fashion. With point-to-prototype globalization (Po2PrG), BFG aggregates local point features to prototypes according to similarity weights from dense point features to sparse prototypes. With prototype-to-point globalization (Pr2PoG), the global perception is embedded to local point features based on similarity weights from sparse prototypes to dense point features. The sparse prototypes of each class embedded with global perception are summarized to a single prototype for few-shot 3D segmentation based on the metric learning framework. Extensive experiments on S3DIS and ScanNet demonstrate that BFG significantly outperforms the state-of-the-art methods.
Beyond single receptive field: A receptive field fusion-and-stratification network for airborne laser scanning point cloud classification
Jul 21, 2022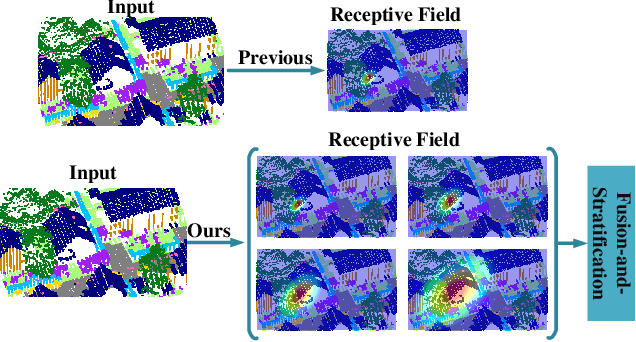
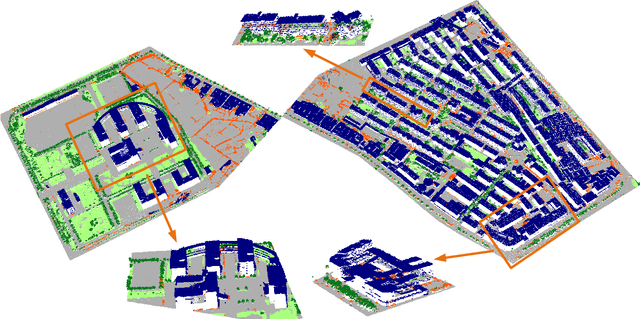

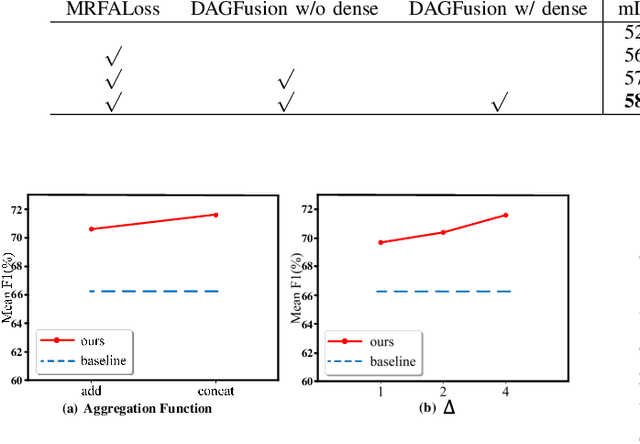
The classification of airborne laser scanning (ALS) point clouds is a critical task of remote sensing and photogrammetry fields. Although recent deep learning-based methods have achieved satisfactory performance, they have ignored the unicity of the receptive field, which makes the ALS point cloud classification remain challenging for the distinguishment of the areas with complex structures and extreme scale variations. In this article, for the objective of configuring multi-receptive field features, we propose a novel receptive field fusion-and-stratification network (RFFS-Net). With a novel dilated graph convolution (DGConv) and its extension annular dilated convolution (ADConv) as basic building blocks, the receptive field fusion process is implemented with the dilated and annular graph fusion (DAGFusion) module, which obtains multi-receptive field feature representation through capturing dilated and annular graphs with various receptive regions. The stratification of the receptive fields with point sets of different resolutions as the calculation bases is performed with Multi-level Decoders nested in RFFS-Net and driven by the multi-level receptive field aggregation loss (MRFALoss) to drive the network to learn in the direction of the supervision labels with different resolutions. With receptive field fusion-and-stratification, RFFS-Net is more adaptable to the classification of regions with complex structures and extreme scale variations in large-scale ALS point clouds. Evaluated on the ISPRS Vaihingen 3D dataset, our RFFS-Net significantly outperforms the baseline approach by 5.3% on mF1 and 5.4% on mIoU, accomplishing an overall accuracy of 82.1%, an mF1 of 71.6%, and an mIoU of 58.2%. Furthermore, experiments on the LASDU dataset and the 2019 IEEE-GRSS Data Fusion Contest dataset show that RFFS-Net achieves a new state-of-the-art classification performance.
Semantic Segmentation for Point Cloud Scenes via Dilated Graph Feature Aggregation and Pyramid Decoders
Apr 11, 2022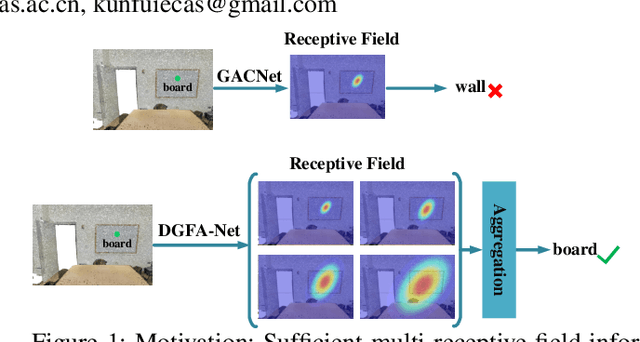
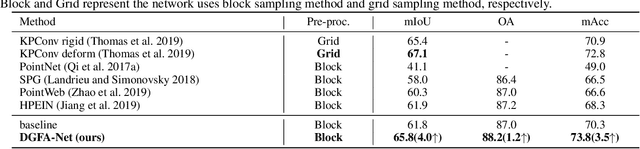
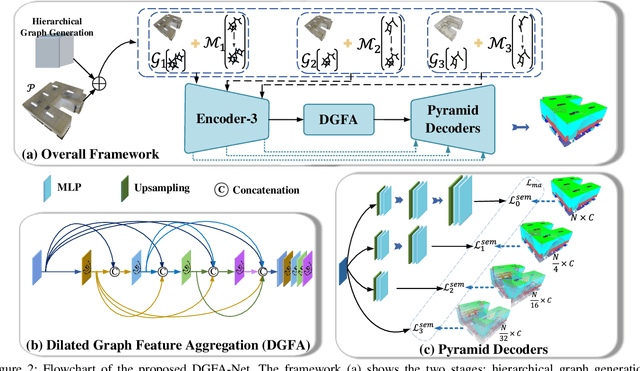

Semantic segmentation of point clouds generates comprehensive understanding of scenes through densely predicting the category for each point. Due to the unicity of receptive field, semantic segmentation of point clouds remains challenging for the expression of multi-receptive field features, which brings about the misclassification of instances with similar spatial structures. In this paper, we propose a graph convolutional network DGFA-Net rooted in dilated graph feature aggregation (DGFA), guided by multi-basis aggregation loss (MALoss) calculated through Pyramid Decoders. To configure multi-receptive field features, DGFA which takes the proposed dilated graph convolution (DGConv) as its basic building block, is designed to aggregate multi-scale feature representation by capturing dilated graphs with various receptive regions. By simultaneously considering penalizing the receptive field information with point sets of different resolutions as calculation bases, we introduce Pyramid Decoders driven by MALoss for the diversity of receptive field bases. Combining these two aspects, DGFA-Net significantly improves the segmentation performance of instances with similar spatial structures. Experiments on S3DIS, ShapeNetPart and Toronto-3D show that DGFA-Net outperforms the baseline approach, achieving a new state-of-the-art segmentation performance.