 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimism in Model-Based Reinforcement Learning
Jun 21, 2020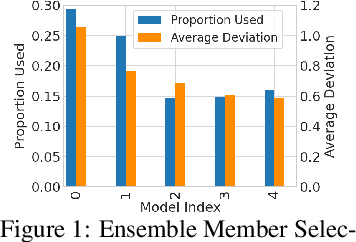
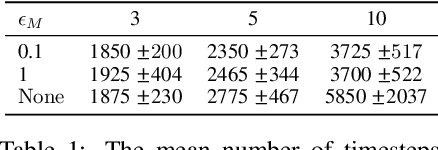
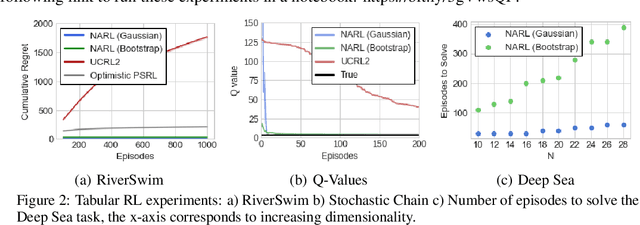
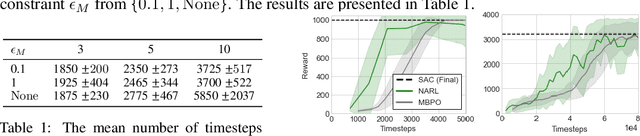
The principle of optimism in the face of uncertainty is prevalent throughout sequential decision making problems such as multi-armed bandits and reinforcement learning (RL), often coming with strong theoretical guarantees. However, it remains a challenge to scale these approaches to the deep RL paradigm, which has achieved a great deal of attention in recent years. In this paper, we introduce a tractable approach to optimism via noise augmented Markov Decision Processes (MDPs), which we show can obtain a competitive regret bound: $\tilde{\mathcal{O}}( |\mathcal{S}|H\sqrt{|\mathcal{S}||\mathcal{A}| T } )$ when augmenting using Gaussian noise, where $T$ is the total number of environment steps. This tractability allows us to apply our approach to the deep RL setting, where we rigorously evaluate the key factors for success of optimistic model-based RL algorithms, bridging the gap between theory and practice.
Online Hyper-parameter Tuning in Off-policy Learning via Evolutionary Strategies
Jun 13, 2020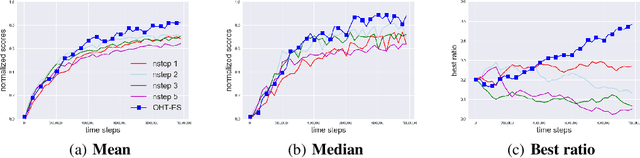
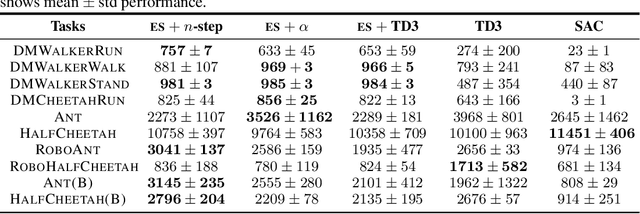

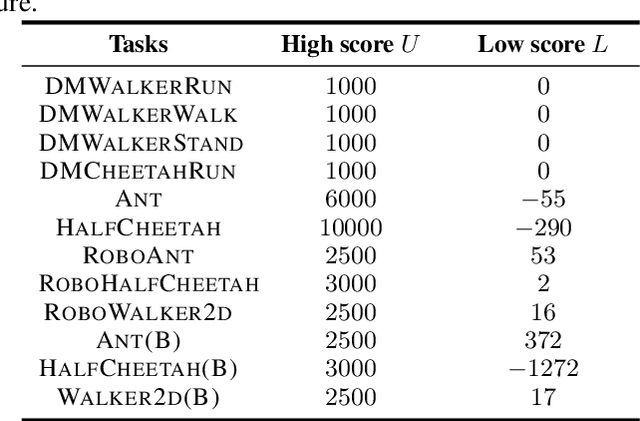
Off-policy learning algorithms have been known to be sensitive to the choice of hyper-parameters. However, unlike near on-policy algorithms for which hyper-parameters could be optimized via e.g. meta-gradients, similar techniques could not be straightforwardly applied to off-policy learning. In this work, we propose a framework which entails the application of Evolutionary Strategies to online hyper-parameter tuning in off-policy learning. Our formulation draws close connections to meta-gradients and leverages the strengths of black-box optimization with relatively low-dimensional search spaces. We show that our method outperforms state-of-the-art off-policy learning baselines with static hyper-parameters and recent prior work over a wide range of continuous control benchmarks.
UFO-BLO: Unbiased First-Order Bilevel Optimization
Jun 05, 2020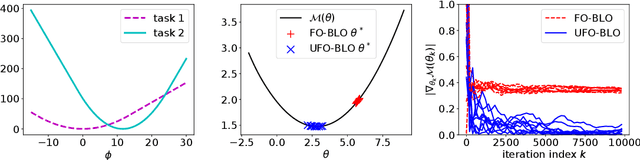



Bilevel optimization (BLO) is a popular approach with many applications including hyperparameter optimization, neural architecture search, adversarial robustness and model-agnostic meta-learning. However, the approach suffers from time and memory complexity proportional to the length $r$ of its inner optimization loop, which has led to several modifications being proposed. One such modification is \textit{first-order} BLO (FO-BLO) which approximates outer-level gradients by zeroing out second derivative terms, yielding significant speed gains and requiring only constant memory as $r$ varies. Despite FO-BLO's popularity, there is a lack of theoretical understanding of its convergence properties. We make progress by demonstrating a rich family of examples where FO-BLO-based stochastic optimization does not converge to a stationary point of the BLO objective. We address this concern by proposing a new FO-BLO-based unbiased estimate of outer-level gradients, enabling us to theoretically guarantee this convergence, with no harm to memory and expected time complexity. Our findings are supported by experimental results on Omniglot and Mini-ImageNet, popular few-shot meta-learning benchmarks.
Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers
Jun 05, 2020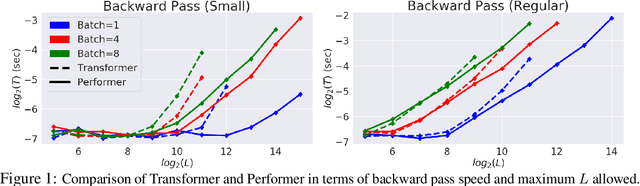
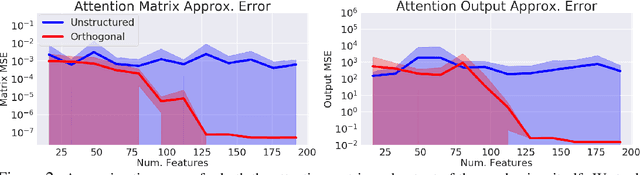
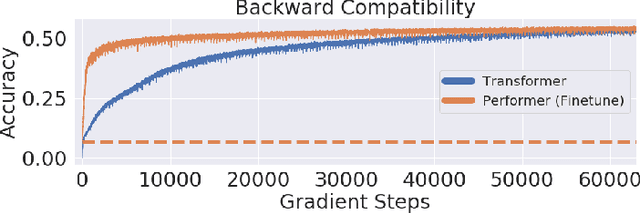
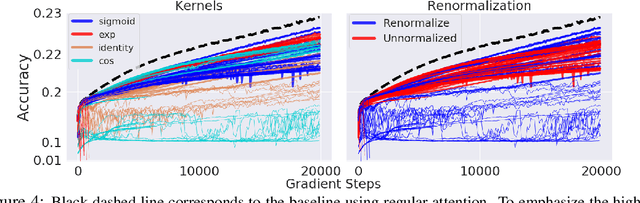
Transformer models have achieved state-of-the-art results across a diverse range of domains. However, concern over the cost of training the attention mechanism to learn complex dependencies between distant inputs continues to grow. In response, solutions that exploit the structure and sparsity of the learned attention matrix have blossomed. However, real-world applications that involve long sequences, such as biological sequence analysis, may fall short of meeting these assumptions, precluding exploration of these models. To address this challenge, we present a new Transformer architecture, Performer, based on Fast Attention Via Orthogonal Random features (FAVOR). Our mechanism scales linearly rather than quadratically in the number of tokens in the sequence, is characterized by sub-quadratic space complexity and does not incorporate any sparsity pattern priors. Furthermore, it provides strong theoretical guarantees: unbiased estimation of the attention matrix and uniform convergence. It is also backwards-compatible with pre-trained regular Transformers. We demonstrate its effectiveness on the challenging task of protein sequence modeling and provide detailed theoretical analysis.
Demystifying Orthogonal Monte Carlo and Beyond
May 27, 2020
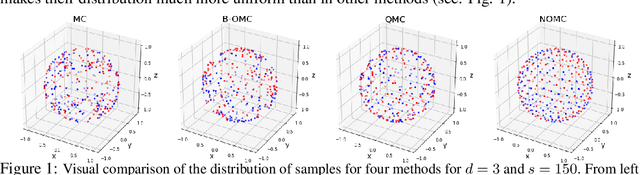
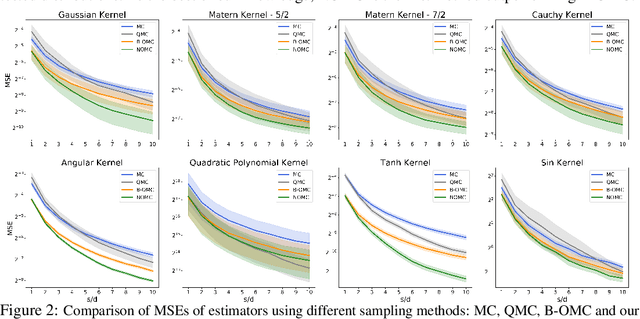
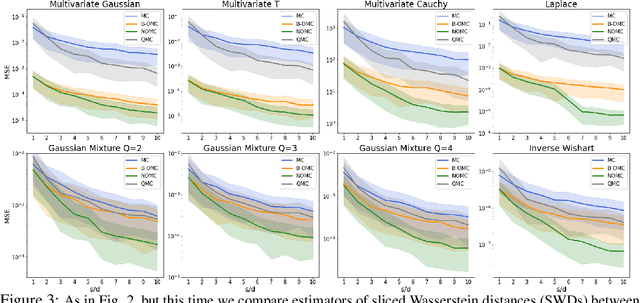
Orthogonal Monte Carlo (OMC) is a very effective sampling algorithm imposing structural geometric conditions (orthogonality) on samples for variance reduction. Due to its simplicity and superior performance as compared to its Quasi Monte Carlo counterparts, OMC is used in a wide spectrum of challenging machine learning applications ranging from scalable kernel methods to predictive recurrent neural networks, generative models and reinforcement learning. However theoretical understanding of the method remains very limited. In this paper we shed new light on the theoretical principles behind OMC, applying theory of negatively dependent random variables to obtain several new concentration results. We also propose a novel extensions of the method leveraging number theory techniques and particle algorithms, called Near-Orthogonal Monte Carlo (NOMC). We show that NOMC is the first algorithm consistently outperforming OMC in applications ranging from kernel methods to approximating distances in probabilistic metric spaces.
Time Dependence in Non-Autonomous Neural ODEs
May 06, 2020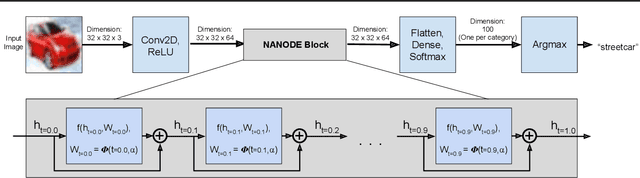
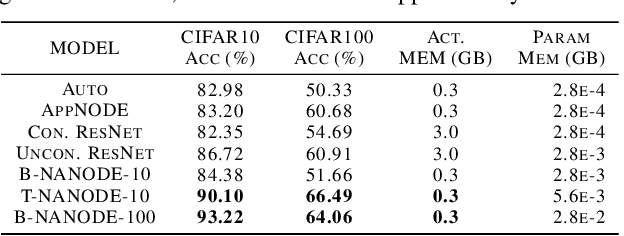
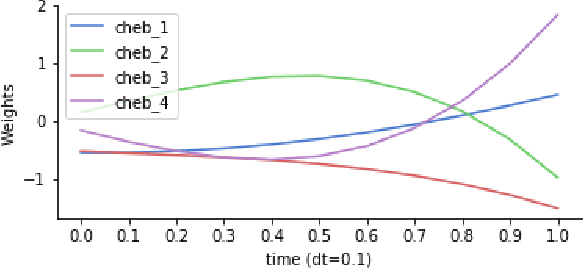
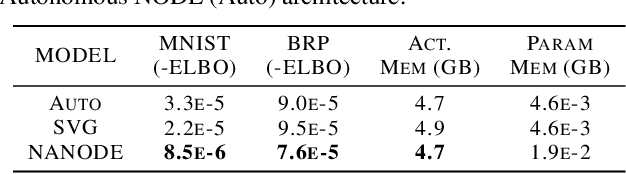
Neural Ordinary Differential Equations (ODEs) are elegant reinterpretations of deep networks where continuous time can replace the discrete notion of depth, ODE solvers perform forward propagation, and the adjoint method enables efficient, constant memory backpropagation. Neural ODEs are universal approximators only when they are non-autonomous, that is, the dynamics depends explicitly on time. We propose a novel family of Neural ODEs with time-varying weights, where time-dependence is non-parametric, and the smoothness of weight trajectories can be explicitly controlled to allow a tradeoff between expressiveness and efficiency. Using this enhanced expressiveness, we outperform previous Neural ODE variants in both speed and representational capacity, ultimately outperforming standard ResNet and CNN models on select image classification and video prediction tasks.
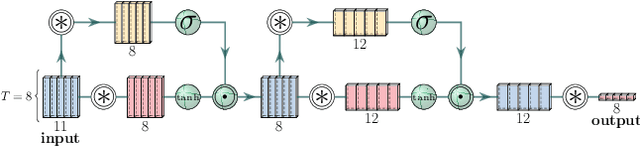
CWY Parametrization for Scalable Learning of Orthogonal and Stiefel Matrices
Apr 18, 2020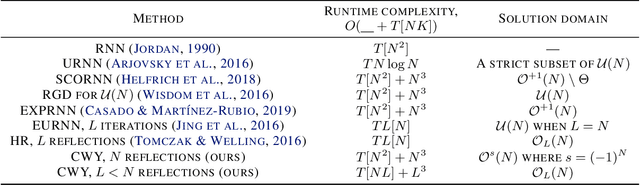
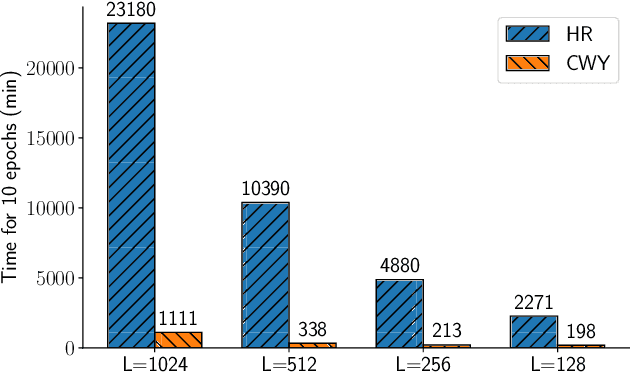

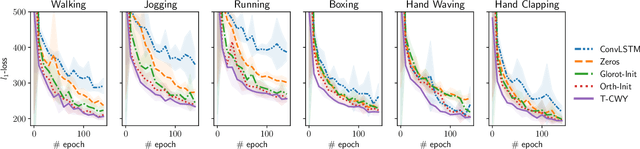
In this paper we propose a new approach for optimization over orthogonal groups. We parametrize an orthogonal matrix as a product of Householder reflections. To overcome low parallelization capabilities of computing Householder reflections sequentially, we employ an accumulation scheme called the compact WY (or CWY) transform---a compact matrix representation for the series of Householder reflections which can be computed efficiently on highly parallelizable computation units such as GPU and TPU. We further introduce the Truncated CWY (or T-CWY)---a novel approach for Stiefel manifold parametrization which has a competitive complexity estimate compared to other methods and, again, has an advantage when computed on GPU and TPU. We apply these proposed parametrizations to train recurrent neural network architectures in the tasks of neural machine translation and video prediction and demonstrate superiority in both computational and learning aspects compared to other methods from the literature.
Robotic Table Tennis with Model-Free Reinforcement Learning
Mar 31, 2020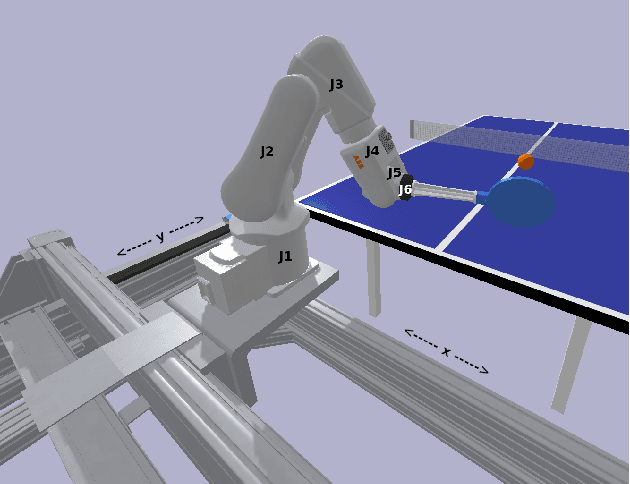
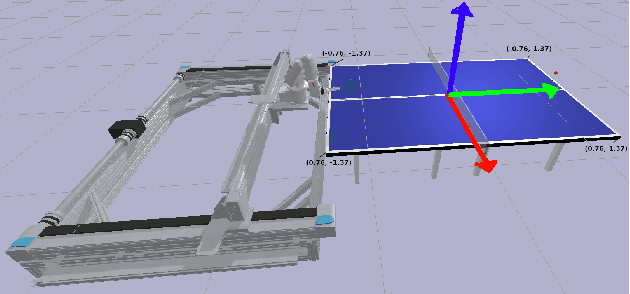

We propose a model-free algorithm for learning efficient policies capable of returning table tennis balls by controlling robot joints at a rate of 100Hz. We demonstrate that evolutionary search (ES) methods acting on CNN-based policy architectures for non-visual inputs and convolving across time learn compact controllers leading to smooth motions. Furthermore, we show that with appropriately tuned curriculum learning on the task and rewards, policies are capable of developing multi-modal styles, specifically forehand and backhand stroke, whilst achieving 80\% return rate on a wide range of ball throws. We observe that multi-modality does not require any architectural priors, such as multi-head architectures or hierarchical policies.
Stochastic Flows and Geometric Optimization on the Orthogonal Group
Mar 30, 2020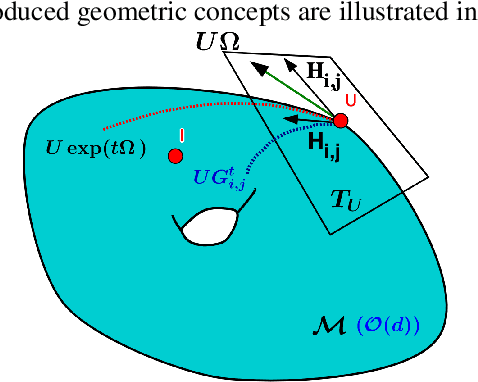
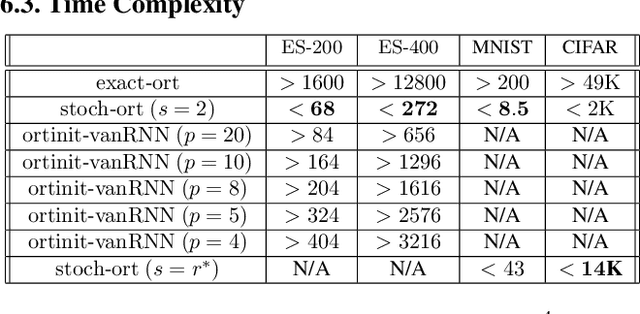


We present a new class of stochastic, geometrically-driven optimization algorithms on the orthogonal group $O(d)$ and naturally reductive homogeneous manifolds obtained from the action of the rotation group $SO(d)$. We theoretically and experimentally demonstrate that our methods can be applied in various fields of machine learning including deep, convolutional and recurrent neural networks, reinforcement learning, normalizing flows and metric learning. We show an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory (e.g. matching problem, partition functions over graphs, graph-coloring). We leverage the theory of Lie groups and provide theoretical results for the designed class of algorithms. We demonstrate broad applicability of our methods by showing strong performance on the seemingly unrelated tasks of learning world models to obtain stable policies for the most difficult $\mathrm{Humanoid}$ agent from $\mathrm{OpenAI}$ $\mathrm{Gym}$ and improving convolutional neural networks.
Rapidly Adaptable Legged Robots via Evolutionary Meta-Learning
Mar 02, 2020

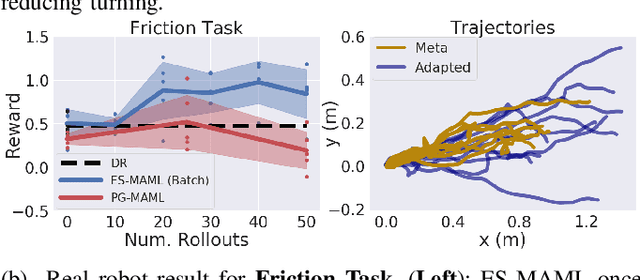
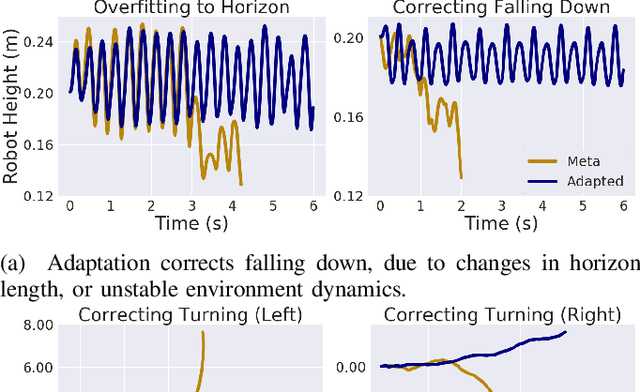
Learning adaptable policies is crucial for robots to operate autonomously in our complex and quickly changing world. In this work, we present a new meta-learning method that allows robots to quickly adapt to changes in dynamics. In contrast to gradient-based meta-learning algorithms that rely on second-order gradient estimation, we introduce a more noise-tolerant Batch Hill-Climbing adaptation operator and combine it with meta-learning based on evolutionary strategies. Our method significantly improves adaptation to changes in dynamics in high noise settings, which are common in robotics applications. We validate our approach on a quadruped robot that learns to walk while subject to changes in dynamics. We observe that our method significantly outperforms prior gradient-based approaches, enabling the robot to adapt its policy to changes based on less than 3 minutes of real data.