 Add to Chrome
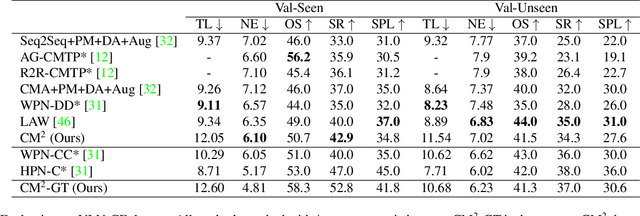
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Tracking, Re-ID, and Social Network Analysis of a Flock of Visually Similar Birds in an Outdoor Aviary
Dec 01, 2022The ability to capture detailed interactions among individuals in a social group is foundational to our study of animal behavior and neuroscience. Recent advances in deep learning and computer vision are driving rapid progress in methods that can record the actions and interactions of multiple individuals simultaneously. Many social species, such as birds, however, live deeply embedded in a three-dimensional world. This world introduces additional perceptual challenges such as occlusions, orientation-dependent appearance, large variation in apparent size, and poor sensor coverage for 3D reconstruction, that are not encountered by applications studying animals that move and interact only on 2D planes. Here we introduce a system for studying the behavioral dynamics of a group of songbirds as they move throughout a 3D aviary. We study the complexities that arise when tracking a group of closely interacting animals in three dimensions and introduce a novel dataset for evaluating multi-view trackers. Finally, we analyze captured ethogram data and demonstrate that social context affects the distribution of sequential interactions between birds in the aviary.
Unified Fourier-based Kernel and Nonlinearity Design for Equivariant Networks on Homogeneous Spaces
Jun 19, 2022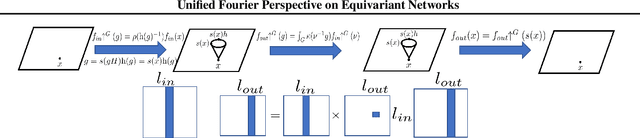
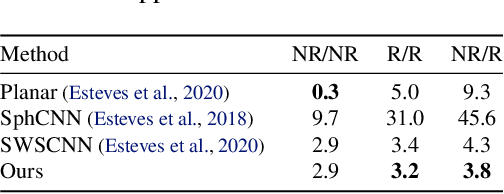

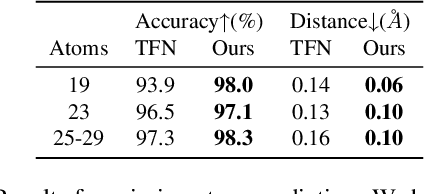
We introduce a unified framework for group equivariant networks on homogeneous spaces derived from a Fourier perspective. We consider tensor-valued feature fields, before and after a convolutional layer. We present a unified derivation of kernels via the Fourier domain by leveraging the sparsity of Fourier coefficients of the lifted feature fields. The sparsity emerges when the stabilizer subgroup of the homogeneous space is a compact Lie group. We further introduce a nonlinear activation, via an elementwise nonlinearity on the regular representation after lifting and projecting back to the field through an equivariant convolution. We show that other methods treating features as the Fourier coefficients in the stabilizer subgroup are special cases of our activation. Experiments on $SO(3)$ and $SE(3)$ show state-of-the-art performance in spherical vector field regression, point cloud classification, and molecular completion.
Semantic keypoint-based pose estimation from single RGB frames
Apr 12, 2022


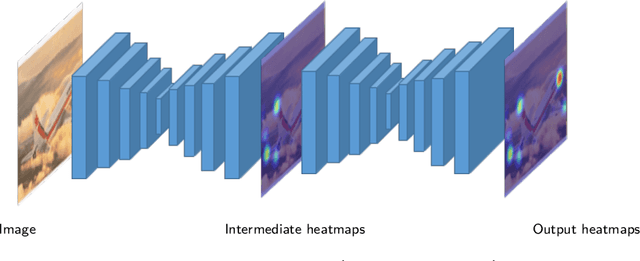
This paper presents an approach to estimating the continuous 6-DoF pose of an object from a single RGB image. The approach combines semantic keypoints predicted by a convolutional network (convnet) with a deformable shape model. Unlike prior investigators, we are agnostic to whether the object is textured or textureless, as the convnet learns the optimal representation from the available training-image data. Furthermore, the approach can be applied to instance- and class-based pose recovery. Additionally, we accompany our main pipeline with a technique for semi-automatic data generation from unlabeled videos. This procedure allows us to train the learnable components of our method with minimal manual intervention in the labeling process. Empirically, we show that our approach can accurately recover the 6-DoF object pose for both instance- and class-based scenarios even against a cluttered background. We apply our approach both to several, existing, large-scale datasets - including PASCAL3D+, LineMOD-Occluded, YCB-Video, and TUD-Light - and, using our labeling pipeline, to a new dataset with novel object classes that we introduce here. Extensive empirical evaluations show that our approach is able to provide pose estimation results comparable to the state of the art.
* https://sites.google.com/view/rcta-object-keypoints-dataset/home. arXiv admin note: substantial text overlap with arXiv:1703.04670
SE(3)-Equivariant Attention Networks for Shape Reconstruction in Function Space
Apr 05, 2022
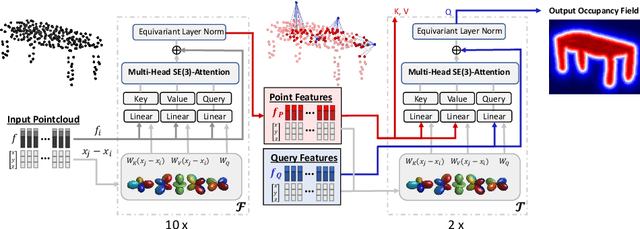
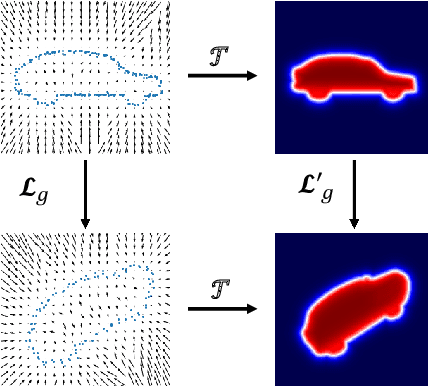
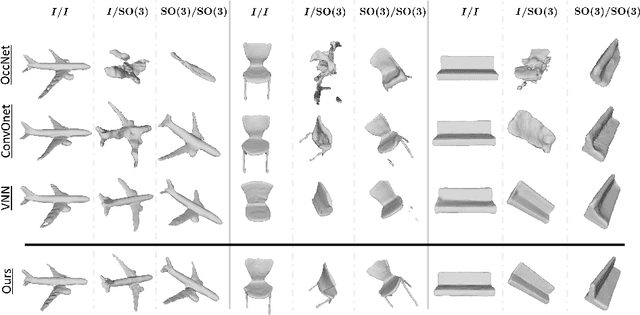
We propose the first SE(3)-equivariant coordinate-based network for learning occupancy fields from point clouds. In contrast to previous shape reconstruction methods that align the input to a regular grid, we operate directly on the irregular, unoriented point cloud. We leverage attention mechanisms in order to preserve the set structure (permutation equivariance and variable length) of the input. At the same time, attention layers enable local shape modelling, a crucial property for scalability to large scenes. In contrast to architectures that create a global signature for the shape, we operate on local tokens. Given an unoriented, sparse, noisy point cloud as input, we produce equivariant features for each point. These serve as keys and values for the subsequent equivariant cross-attention blocks that parametrize the occupancy field. By querying an arbitrary point in space, we predict its occupancy score. We show that our method outperforms previous SO(3)-equivariant methods, as well as non-equivariant methods trained on SO(3)-augmented datasets. More importantly, local modelling together with SE(3)-equivariance create an ideal setting for SE(3) scene reconstruction. We show that by training only on single objects and without any pre-segmentation, we can reconstruct a novel scene with single-object performance.
CaDeX: Learning Canonical Deformation Coordinate Space for Dynamic Surface Representation via Neural Homeomorphism
Mar 30, 2022
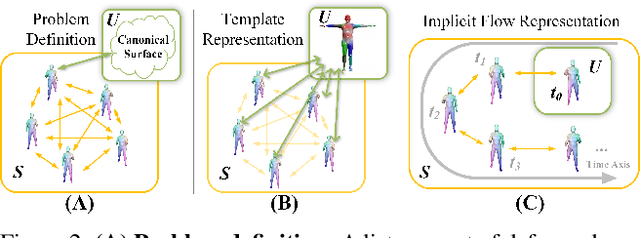
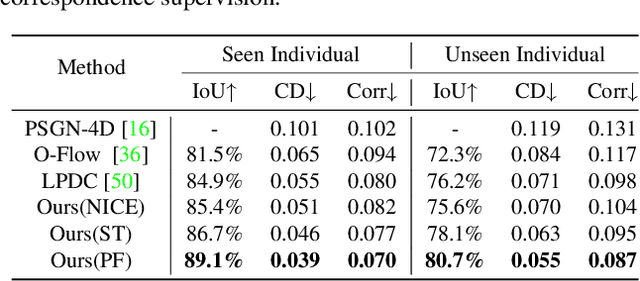
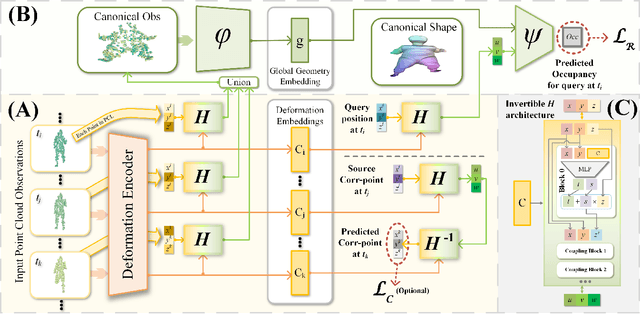
While neural representations for static 3D shapes are widely studied, representations for deformable surfaces are limited to be template-dependent or lack efficiency. We introduce Canonical Deformation Coordinate Space (CaDeX), a unified representation of both shape and nonrigid motion. Our key insight is the factorization of the deformation between frames by continuous bijective canonical maps (homeomorphisms) and their inverses that go through a learned canonical shape. Our novel deformation representation and its implementation are simple, efficient, and guarantee cycle consistency, topology preservation, and, if needed, volume conservation. Our modelling of the learned canonical shapes provides a flexible and stable space for shape prior learning. We demonstrate state-of-the-art performance in modelling a wide range of deformable geometries: human bodies, animal bodies, and articulated objects.
Cross-modal Map Learning for Vision and Language Navigation
Mar 21, 2022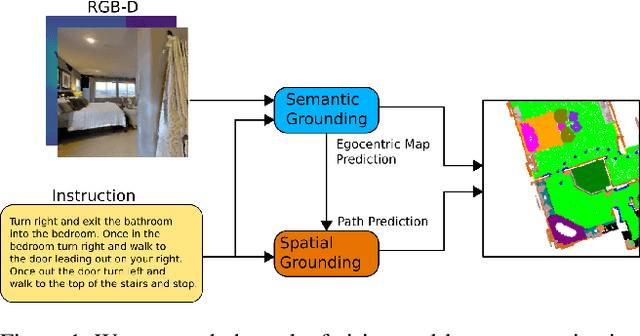
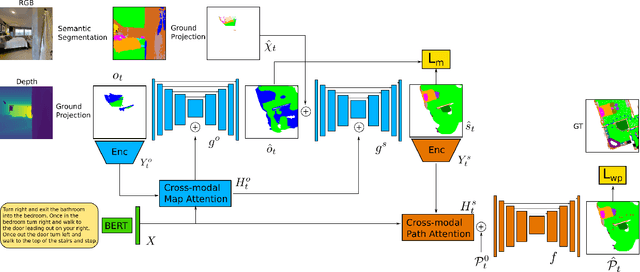
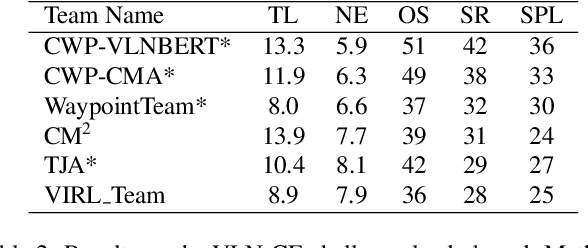
We consider the problem of Vision-and-Language Navigation (VLN). The majority of current methods for VLN are trained end-to-end using either unstructured memory such as LSTM, or using cross-modal attention over the egocentric observations of the agent. In contrast to other works, our key insight is that the association between language and vision is stronger when it occurs in explicit spatial representations. In this work, we propose a cross-modal map learning model for vision-and-language navigation that first learns to predict the top-down semantics on an egocentric map for both observed and unobserved regions, and then predicts a path towards the goal as a set of waypoints. In both cases, the prediction is informed by the language through cross-modal attention mechanisms. We experimentally test the basic hypothesis that language-driven navigation can be solved given a map, and then show competitive results on the full VLN-CE benchmark.
Uncertainty-driven Planner for Exploration and Navigation
Feb 24, 2022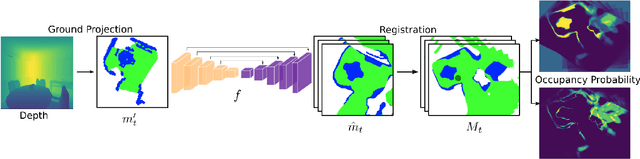
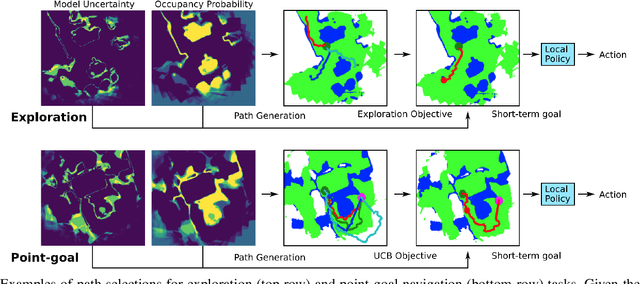

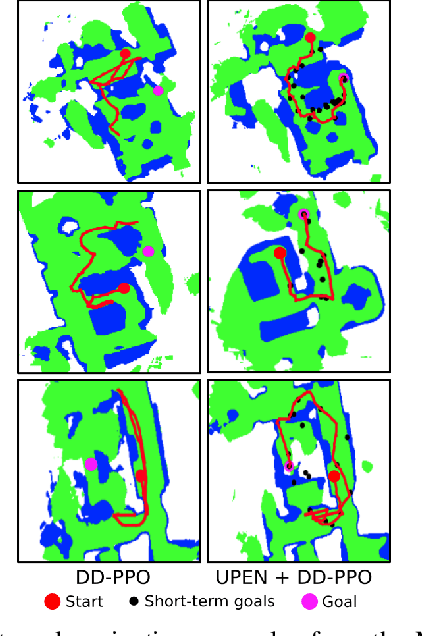
We consider the problems of exploration and point-goal navigation in previously unseen environments, where the spatial complexity of indoor scenes and partial observability constitute these tasks challenging. We argue that learning occupancy priors over indoor maps provides significant advantages towards addressing these problems. To this end, we present a novel planning framework that first learns to generate occupancy maps beyond the field-of-view of the agent, and second leverages the model uncertainty over the generated areas to formulate path selection policies for each task of interest. For point-goal navigation the policy chooses paths with an upper confidence bound policy for efficient and traversable paths, while for exploration the policy maximizes model uncertainty over candidate paths. We perform experiments in the visually realistic environments of Matterport3D using the Habitat simulator and demonstrate: 1) Improved results on exploration and map quality metrics over competitive methods, and 2) The effectiveness of our planning module when paired with the state-of-the-art DD-PPO method for the point-goal navigation task.
Learning Augmentation Distributions using Transformed Risk Minimization
Nov 16, 2021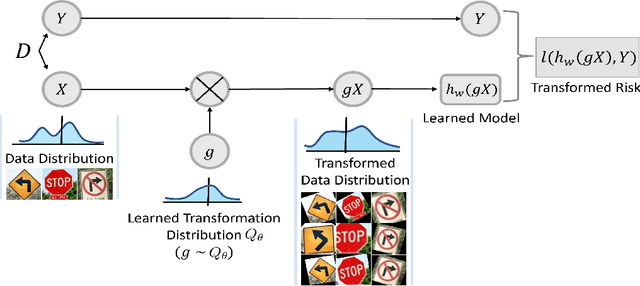

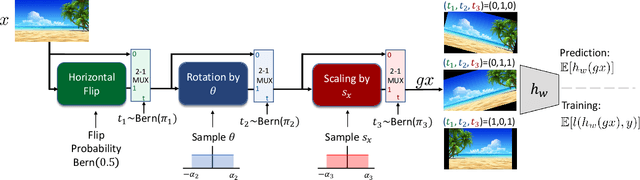

Adapting to the structure of data distributions (such as symmetry and transformation invariances) is an important challenge in machine learning. Invariances can be built into the learning process by architecture design, or by augmenting the dataset. Both require a priori knowledge about the exact nature of the symmetries. Absent this knowledge, practitioners resort to expensive and time-consuming tuning. To address this problem, we propose a new approach to learn distributions of augmentation transforms, in a new \emph{Transformed Risk Minimization} (TRM) framework. In addition to predictive models, we also optimize over transformations chosen from a hypothesis space. As an algorithmic framework, our TRM method is (1) efficient (jointly learns augmentations and models in a \emph{single training loop}), (2) modular (works with \emph{any} training algorithm), and (3) general (handles \emph{both discrete and continuous} augmentations). We theoretically compare TRM with standard risk minimization, and give a PAC-Bayes upper bound on its generalization error. We propose to optimize this bound over a rich augmentation space via a new parametrization over compositions of blocks, leading to the new \emph{Stochastic Compositional Augmentation Learning} (SCALE) algorithm. We compare SCALE experimentally with prior methods (Fast AutoAugment and Augerino) on CIFAR10/100, SVHN . Additionally, we show that SCALE can correctly learn certain symmetries in the data distribution (recovering rotations on rotated MNIST) and can also improve calibration of the learned model.
Discovering and Achieving Goals via World Models
Oct 18, 2021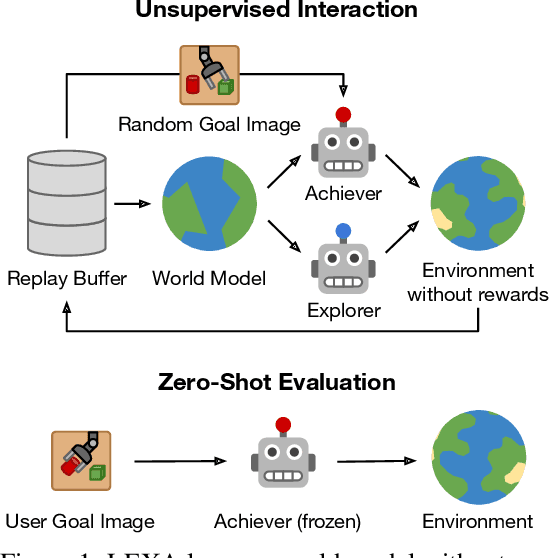
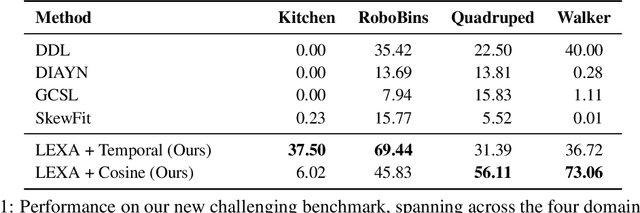
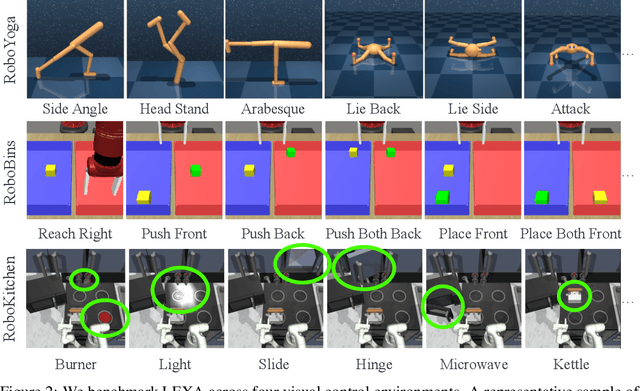
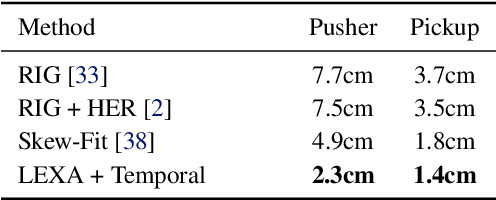
How can artificial agents learn to solve many diverse tasks in complex visual environments in the absence of any supervision? We decompose this question into two problems: discovering new goals and learning to reliably achieve them. We introduce Latent Explorer Achiever (LEXA), a unified solution to these that learns a world model from image inputs and uses it to train an explorer and an achiever policy from imagined rollouts. Unlike prior methods that explore by reaching previously visited states, the explorer plans to discover unseen surprising states through foresight, which are then used as diverse targets for the achiever to practice. After the unsupervised phase, LEXA solves tasks specified as goal images zero-shot without any additional learning. LEXA substantially outperforms previous approaches to unsupervised goal-reaching, both on prior benchmarks and on a new challenging benchmark with a total of 40 test tasks spanning across four standard robotic manipulation and locomotion domains. LEXA further achieves goals that require interacting with multiple objects in sequence. Finally, to demonstrate the scalability and generality of LEXA, we train a single general agent across four distinct environments. Code and videos at https://orybkin.github.io/lexa/
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Sep 27, 2021
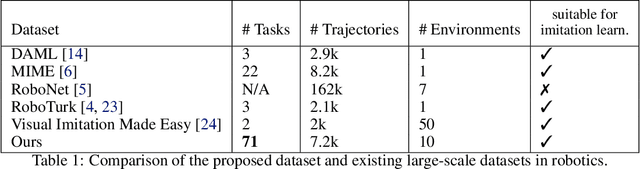

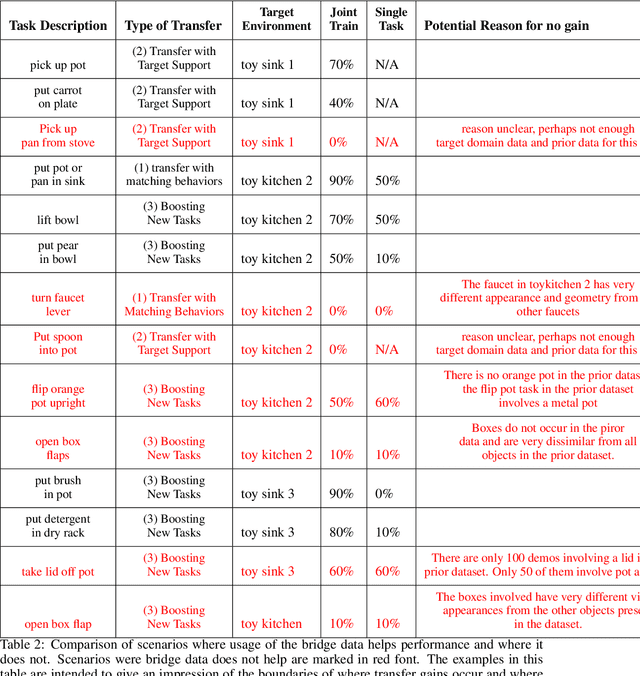
Robot learning holds the promise of learning policies that generalize broadly. However, such generalization requires sufficiently diverse datasets of the task of interest, which can be prohibitively expensive to collect. In other fields, such as computer vision, it is common to utilize shared, reusable datasets, such as ImageNet, to overcome this challenge, but this has proven difficult in robotics. In this paper, we ask: what would it take to enable practical data reuse in robotics for end-to-end skill learning? We hypothesize that the key is to use datasets with multiple tasks and multiple domains, such that a new user that wants to train their robot to perform a new task in a new domain can include this dataset in their training process and benefit from cross-task and cross-domain generalization. To evaluate this hypothesis, we collect a large multi-domain and multi-task dataset, with 7,200 demonstrations constituting 71 tasks across 10 environments, and empirically study how this data can improve the learning of new tasks in new environments. We find that jointly training with the proposed dataset and 50 demonstrations of a never-before-seen task in a new domain on average leads to a 2x improvement in success rate compared to using target domain data alone. We also find that data for only a few tasks in a new domain can bridge the domain gap and make it possible for a robot to perform a variety of prior tasks that were only seen in other domains. These results suggest that reusing diverse multi-task and multi-domain datasets, including our open-source dataset, may pave the way for broader robot generalization, eliminating the need to re-collect data for each new robot learning project.