 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-CAS: Dynamic Neuron Perturbation for Real-Time Hallucination Correction
Dec 21, 2025Large language models (LLMs) often generate hallucinated content that lacks factual or contextual grounding, limiting their reliability in critical applications. Existing approaches such as supervised fine-tuning and reinforcement learning from human feedback are data intensive and computationally expensive, while static parameter editing methods struggle with context dependent errors and catastrophic forgetting. We propose LLM-CAS, a framework that formulates real-time hallucination correction as a hierarchical reinforcement learning problem. LLM-CAS trains an agent to learn a policy that dynamically selects temporary neuron perturbations during inference based on the current context. Unlike prior dynamic approaches that rely on heuristic or predefined adjustments, this policy driven mechanism enables adaptive and fine grained correction without permanent parameter modification. Experiments across multiple language models demonstrate that LLM-CAS consistently improves factual accuracy, achieving gains of 10.98 percentage points on StoryCloze, 2.71 points on TriviaQA, and 2.06 points on the MC1 score of TruthfulQA. These results outperform both static editing methods such as ITI and CAA and the dynamic SADI framework. Overall, LLM-CAS provides an efficient and context aware solution for improving the reliability of LLMs, with promising potential for future multimodal extensions.
PTTA: A Pure Text-to-Animation Framework for High-Quality Creation
Dec 21, 2025Traditional animation production involves complex pipelines and significant manual labor cost. While recent video generation models such as Sora, Kling, and CogVideoX achieve impressive results on natural video synthesis, they exhibit notable limitations when applied to animation generation. Recent efforts, such as AniSora, demonstrate promising performance by fine-tuning image-to-video models for animation styles, yet analogous exploration in the text-to-video setting remains limited. In this work, we present PTTA, a pure text-to-animation framework for high-quality animation creation. We first construct a small-scale but high-quality paired dataset of animation videos and textual descriptions. Building upon the pretrained text-to-video model HunyuanVideo, we perform fine-tuning to adapt it to animation-style generation. Extensive visual evaluations across multiple dimensions show that the proposed approach consistently outperforms comparable baselines in animation video synthesis.
Large Language Models as Discounted Bayesian Filters
Dec 20, 2025Large Language Models (LLMs) demonstrate strong few-shot generalization through in-context learning, yet their reasoning in dynamic and stochastic environments remains opaque. Prior studies mainly focus on static tasks and overlook the online adaptation required when beliefs must be continuously updated, which is a key capability for LLMs acting as world models or agents. We introduce a Bayesian filtering framework to evaluate online inference in LLMs. Our probabilistic probe suite spans both multivariate discrete distributions, such as dice rolls, and continuous distributions, such as Gaussian processes, where ground-truth parameters shift over time. We find that while LLM belief updates resemble Bayesian posteriors, they are more accurately characterized by an exponential forgetting filter with a model-specific discount factor smaller than one. This reveals systematic discounting of older evidence that varies significantly across model architectures. Although inherent priors are often miscalibrated, the updating mechanism itself remains structured and principled. We further validate these findings in a simulated agent task and propose prompting strategies that effectively recalibrate priors with minimal computational cost.
STORM: Search-Guided Generative World Models for Robotic Manipulation
Dec 20, 2025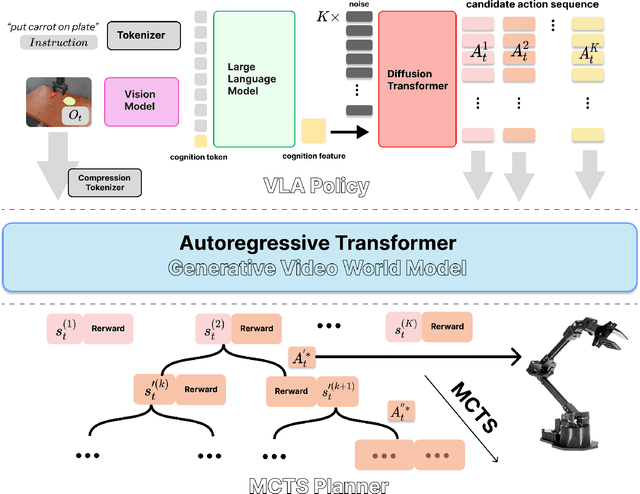
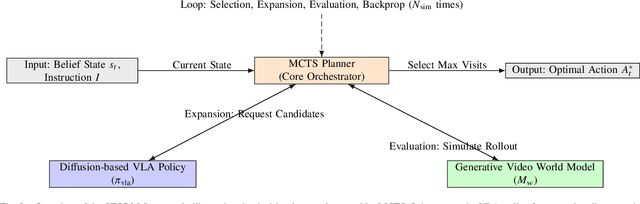


We present STORM (Search-Guided Generative World Models), a novel framework for spatio-temporal reasoning in robotic manipulation that unifies diffusion-based action generation, conditional video prediction, and search-based planning. Unlike prior Vision-Language-Action (VLA) models that rely on abstract latent dynamics or delegate reasoning to language components, STORM grounds planning in explicit visual rollouts, enabling interpretable and foresight-driven decision-making. A diffusion-based VLA policy proposes diverse candidate actions, a generative video world model simulates their visual and reward outcomes, and Monte Carlo Tree Search (MCTS) selectively refines plans through lookahead evaluation. Experiments on the SimplerEnv manipulation benchmark demonstrate that STORM achieves a new state-of-the-art average success rate of 51.0 percent, outperforming strong baselines such as CogACT. Reward-augmented video prediction substantially improves spatio-temporal fidelity and task relevance, reducing Frechet Video Distance by over 75 percent. Moreover, STORM exhibits robust re-planning and failure recovery behavior, highlighting the advantages of search-guided generative world models for long-horizon robotic manipulation.
Adaptive-VoCo: Complexity-Aware Visual Token Compression for Vision-Language Models
Dec 20, 2025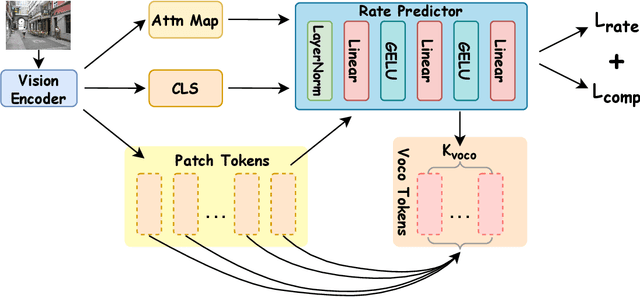
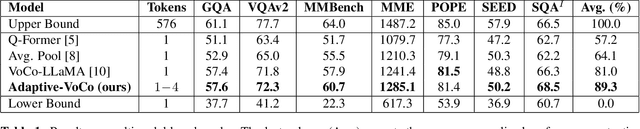
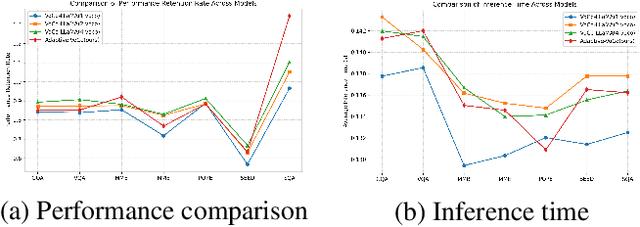
In recent years, large-scale vision-language models (VLMs) have demonstrated remarkable performance on multimodal understanding and reasoning tasks. However, handling high-dimensional visual features often incurs substantial computational and memory costs. VoCo-LLaMA alleviates this issue by compressing visual patch tokens into a few VoCo tokens, reducing computational overhead while preserving strong cross-modal alignment. Nevertheless, such approaches typically adopt a fixed compression rate, limiting their ability to adapt to varying levels of visual complexity. To address this limitation, we propose Adaptive-VoCo, a framework that augments VoCo-LLaMA with a lightweight predictor for adaptive compression. This predictor dynamically selects an optimal compression rate by quantifying an image's visual complexity using statistical cues from the vision encoder, such as patch token entropy and attention map variance. Furthermore, we introduce a joint loss function that integrates rate regularization with complexity alignment. This enables the model to balance inference efficiency with representational capacity, particularly in challenging scenarios. Experimental results show that our method consistently outperforms fixed-rate baselines across multiple multimodal tasks, highlighting the potential of adaptive visual compression for creating more efficient and robust VLMs.
GTMA: Dynamic Representation Optimization for OOD Vision-Language Models
Dec 20, 2025Vision-language models (VLMs) struggle in open-world applications, where out-of-distribution (OOD) concepts often trigger cross-modal alignment collapse and severely degrade zero-shot performance. We identify the root cause as modal asymmetry: while the visual encoder can extract discriminative features from unseen images, the text encoder is constrained by a fixed discrete vocabulary and cannot synthesize new semantic anchors. Existing approaches such as CoOp or LoRA provide only partial remedies, as they remain confined to the pre-trained semantic space. To overcome this bottleneck, we propose dynamic representation optimization, realized through the Guided Target-Matching Adaptation (GTMA) framework. At inference time, GTMA constructs a continuous pseudo-word embedding that best aligns with an OOD image's visual anchor, effectively bypassing vocabulary limitations. The optimization is driven by an adaptive gradient-based representation policy optimization algorithm, which incorporates semantic regularization to preserve plausibility and compatibility with the model's prior knowledge. Experiments on ImageNet-R and the VISTA-Beyond benchmark demonstrate that GTMA improves zero-shot and few-shot OOD accuracy by up to 15-20 percent over the base VLM while maintaining performance on in-distribution concepts. Ablation studies further confirm the necessity of pseudo-word optimization.
Massive Editing for Large Language Models Based on Dynamic Weight Generation
Dec 17, 2025Knowledge Editing (KE) is a field that studies how to modify some knowledge in Large Language Models (LLMs) at a low cost (compared to pre-training). Currently, performing large-scale edits on LLMs while ensuring the Reliability, Generality, and Locality metrics of the edits remain a challenge. This paper proposes a Massive editing approach for LLMs based on dynamic weight Generation (MeG). Our MeG involves attaching a dynamic weight neuron to specific layers of the LLMs and using a diffusion model to conditionally generate the weights of this neuron based on the input query required for the knowledge. This allows the use of adding a single dynamic weight neuron to achieve the goal of large-scale knowledge editing. Experiments show that our MeG can significantly improve the performance of large-scale KE in terms of Reliability, Generality, and Locality metrics compared to existing knowledge editing methods, particularly with a high percentage point increase in the absolute value index for the Locality metric, demonstrating the advantages of our proposed method.
Enhancing Visual Programming for Visual Reasoning via Probabilistic Graphs
Dec 16, 2025



Recently, Visual Programming (VP) based on large language models (LLMs) has rapidly developed and demonstrated significant potential in complex Visual Reasoning (VR) tasks. Previous works to enhance VP have primarily focused on improving the quality of LLM-generated visual programs. However, they have neglected to optimize the VP-invoked pre-trained models, which serve as modules for the visual sub-tasks decomposed from the targeted tasks by VP. The difficulty is that there are only final labels of targeted VR tasks rather than labels of sub-tasks. Besides, the non-differentiable nature of VP impedes the direct use of efficient gradient-based optimization methods to leverage final labels for end-to-end learning of the entire VP framework. To overcome these issues, we propose EVPG, a method to Enhance Visual Programming for visual reasoning via Probabilistic Graphs. Specifically, we creatively build a directed probabilistic graph according to the variable dependency relationships during the VP executing process, which reconstructs the non-differentiable VP executing process into a differentiable exact probability inference process on this directed probabilistic graph. As a result, this enables the VP framework to utilize the final labels for efficient, gradient-based optimization in end-to-end supervised learning on targeted VR tasks. Extensive and comprehensive experiments demonstrate the effectiveness and advantages of our EVPG, showing significant performance improvements for VP on three classical complex VR tasks: GQA, NLVRv2, and Open Images.
MM-CoT:A Benchmark for Probing Visual Chain-of-Thought Reasoning in Multimodal Models
Dec 09, 2025



The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating free-form explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.
HybridToken-VLM: Hybrid Token Compression for Vision-Language Models
Dec 09, 2025Vision-language models (VLMs) have transformed multimodal reasoning, but feeding hundreds of visual patch tokens into LLMs incurs quadratic computational costs, straining memory and context windows. Traditional approaches face a trade-off: continuous compression dilutes high-level semantics such as object identities, while discrete quantization loses fine-grained details such as textures. We introduce HTC-VLM, a hybrid framework that disentangles semantics and appearance through dual channels, i.e., a continuous pathway for fine-grained details via ViT patches and a discrete pathway for symbolic anchors using MGVQ quantization projected to four tokens. These are fused into a 580-token hybrid sequence and compressed into a single voco token via a disentanglement attention mask and bottleneck, ensuring efficient and grounded representations. HTC-VLM achieves an average performance retention of 87.2 percent across seven benchmarks (GQA, VQAv2, MMBench, MME, POPE, SEED-Bench, ScienceQA-Image), outperforming the leading continuous baseline at 81.0 percent with a 580-to-1 compression ratio. Attention analyses show that the compressed token prioritizes the discrete anchor, validating its semantic guidance. Our work demonstrates that a minimalist hybrid design can resolve the efficiency-fidelity dilemma and advance scalable VLMs.