 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Landscape of Games
May 04, 2020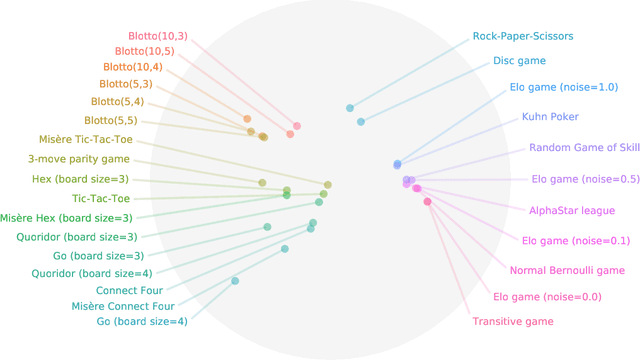
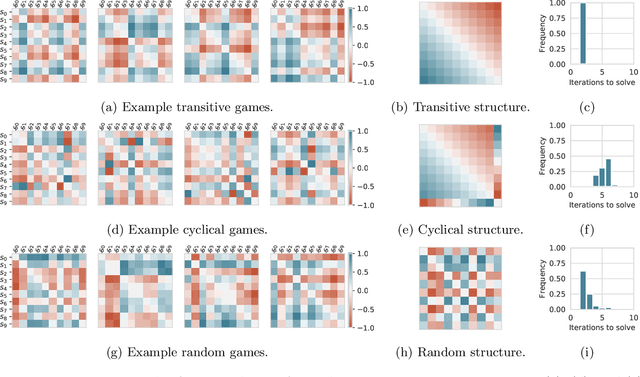
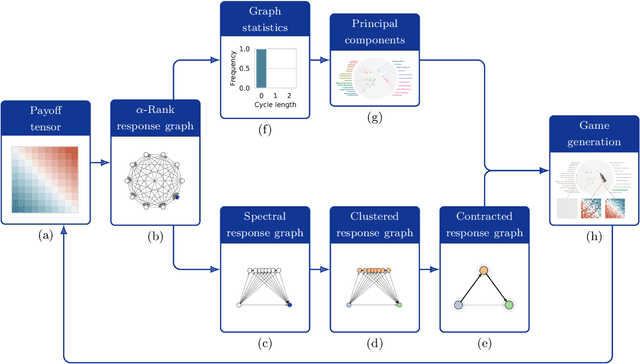

Games are traditionally recognized as one of the key testbeds underlying progress in artificial intelligence (AI), aptly referred to as the "Drosophila of AI". Traditionally, researchers have focused on using games to build strong AI agents that, e.g., achieve human-level performance. This progress, however, also requires a classification of how 'interesting' a game is for an artificial agent. Tackling this latter question not only facilitates an understanding of the characteristics of learnt AI agents in games, but also helps to determine what game an AI should address next as part of its training. Here, we show how network measures applied to so-called response graphs of large-scale games enable the creation of a useful landscape of games, quantifying the relationships between games of widely varying sizes, characteristics, and complexities. We illustrate our findings in various domains, ranging from well-studied canonical games to significantly more complex empirical games capturing the performance of trained AI agents pitted against one another. Our results culminate in a demonstration of how one can leverage this information to automatically generate new and interesting games, including mixtures of empirical games synthesized from real world games.
Real World Games Look Like Spinning Tops
Apr 20, 2020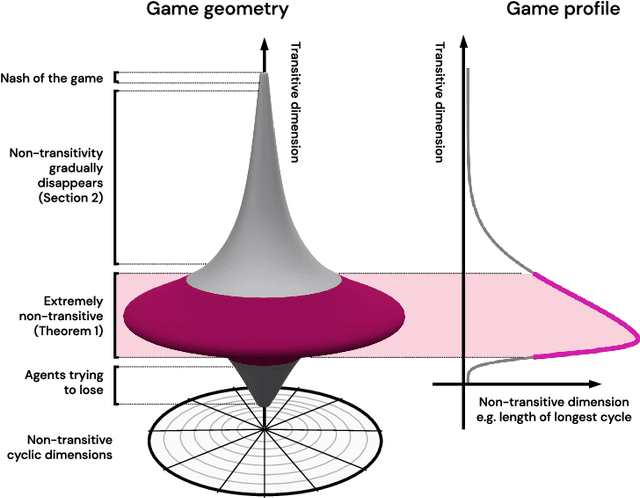
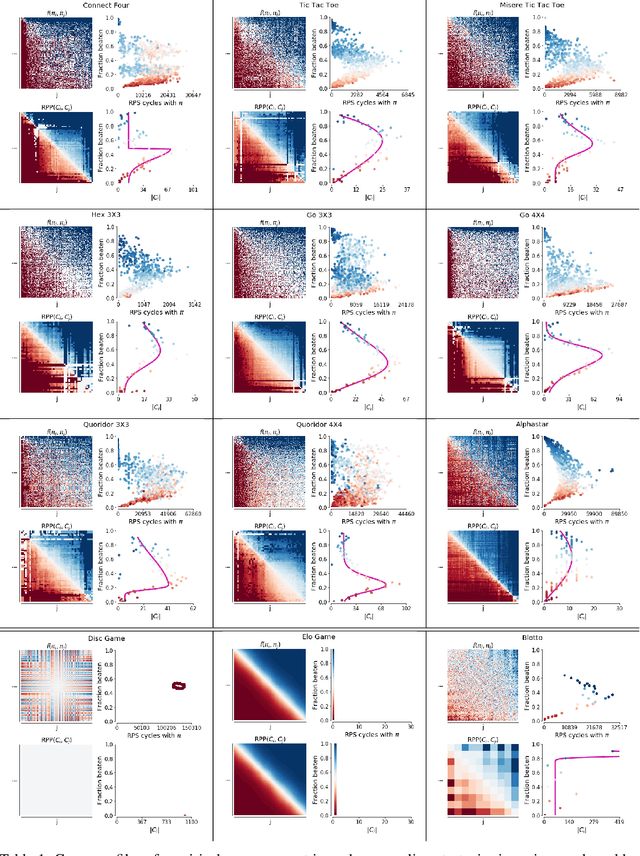
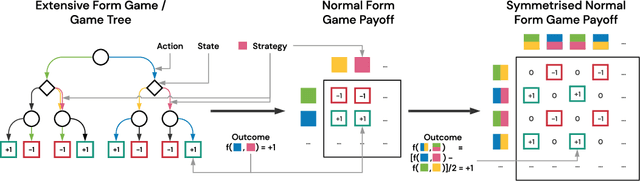
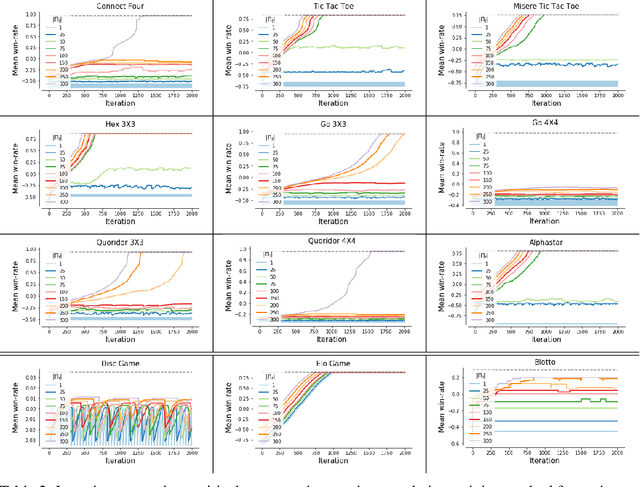
This paper investigates the geometrical properties of real world games (e.g. Tic-Tac-Toe, Go, StarCraft II). We hypothesise that their geometrical structure resemble a spinning top, with the upright axis representing transitive strength, and the radial axis, which corresponds to the number of cycles that exist at a particular transitive strength, representing the non-transitive dimension. We prove the existence of this geometry for a wide class of real world games, exposing their temporal nature. Additionally, we show that this unique structure also has consequences for learning - it clarifies why populations of strategies are necessary for training of agents, and how population size relates to the structure of the game. Finally, we empirically validate these claims by using a selection of nine real world two-player zero-sum symmetric games, showing 1) the spinning top structure is revealed and can be easily re-constructed by using a new method of Nash clustering to measure the interaction between transitive and cyclical strategy behaviour, and 2) the effect that population size has on the convergence in these games.
The Automated Inspection of Opaque Liquid Vaccines
Feb 21, 2020



In the pharmaceutical industry the screening of opaque vaccines containing suspensions is currently a manual task carried out by trained human visual inspectors. We show that deep learning can be used to effectively automate this process. A moving contrast is required to distinguish anomalies from other particles, reflections and dust resting on a vial's surface. We train 3D-ConvNets to predict the likelihood of 20-frame video samples containing anomalies. Our unaugmented dataset consists of hand-labelled samples, recorded using vials provided by the HAL Allergy Group, a pharmaceutical company. We trained ten randomly initialized 3D-ConvNets to provide a benchmark, observing mean AUROC scores of 0.94 and 0.93 for positive samples (containing anomalies) and negative (anomaly-free) samples, respectively. Using Frame-Completion Generative Adversarial Networks we: (i) introduce an algorithm for computing saliency maps, which we use to verify that the 3D-ConvNets are indeed identifying anomalies; (ii) propose a novel self-training approach using the saliency maps to determine if multiple networks agree on the location of anomalies. Our self-training approach allows us to augment our data set by labelling 217,888 additional samples. 3D-ConvNets trained with our augmented dataset improve on the results we get when we train only on the unaugmented dataset.
From Poincaré Recurrence to Convergence in Imperfect Information Games: Finding Equilibrium via Regularization
Feb 19, 2020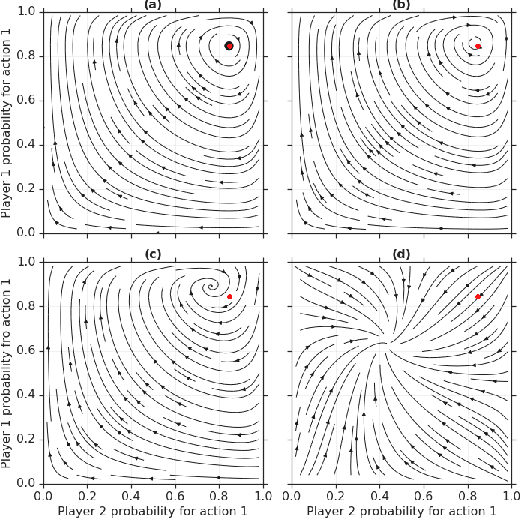
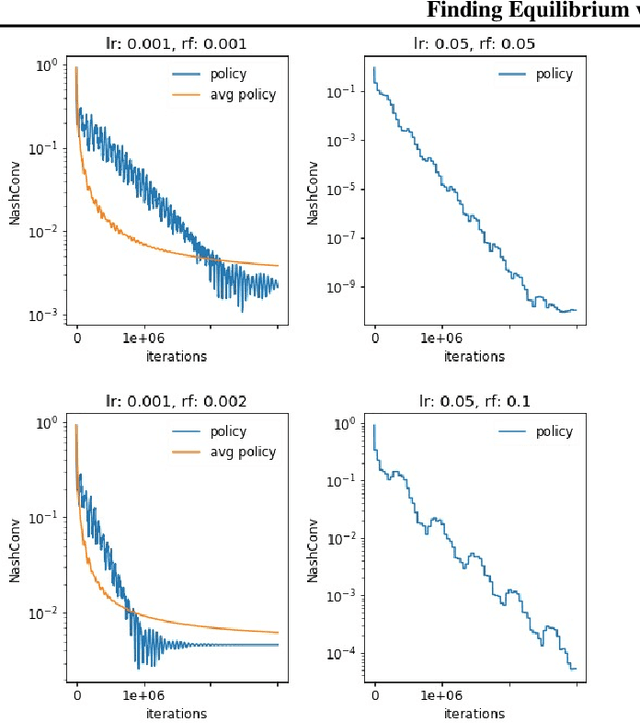
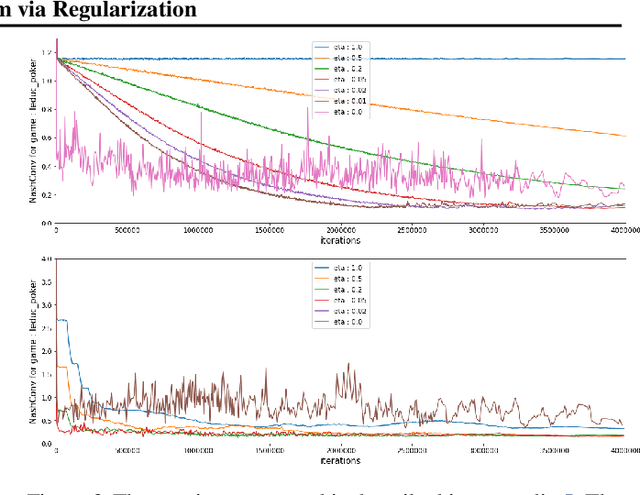

In this paper we investigate the Follow the Regularized Leader dynamics in sequential imperfect information games (IIG). We generalize existing results of Poincar\'e recurrence from normal-form games to zero-sum two-player imperfect information games and other sequential game settings. We then investigate how adapting the reward (by adding a regularization term) of the game can give strong convergence guarantees in monotone games. We continue by showing how this reward adaptation technique can be leveraged to build algorithms that converge exactly to the Nash equilibrium. Finally, we show how these insights can be directly used to build state-of-the-art model-free algorithms for zero-sum two-player Imperfect Information Games (IIG).
Multiagent Evaluation under Incomplete Information
Oct 30, 2019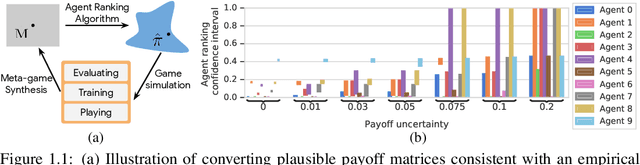
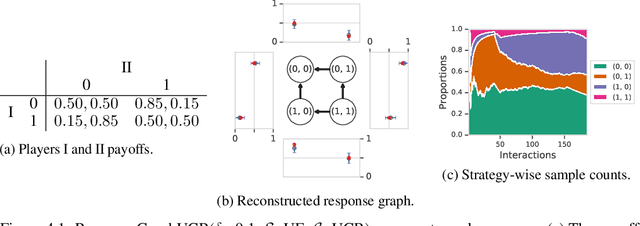
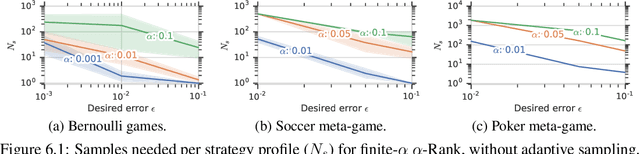
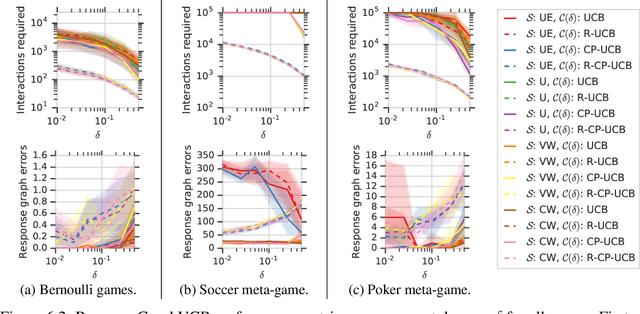
This paper investigates the evaluation of learned multiagent strategies in the incomplete information setting, which plays a critical role in ranking and training of agents. Traditionally, researchers have relied on Elo ratings for this purpose, with recent works also using methods based on Nash equilibria. Unfortunately, Elo is unable to handle intransitive agent interactions, and other techniques are restricted to zero-sum, two-player settings or are limited by the fact that the Nash equilibrium is intractable to compute. Recently, a ranking method called {\alpha}-Rank, relying on a new graph-based game-theoretic solution concept, was shown to tractably apply to general games. However, evaluations based on Elo or {\alpha}-Rank typically assume noise-free game outcomes, despite the data often being collected from noisy simulations, making this assumption unrealistic in practice. This paper investigates multiagent evaluation in the incomplete information regime, involving general-sum many-player games with noisy outcomes. We derive sample complexity guarantees required to confidently rank agents in this setting. We propose adaptive algorithms for accurate ranking, provide correctness and sample complexity guarantees, then introduce a means of connecting uncertainties in noisy match outcomes to uncertainties in rankings. We evaluate the performance of these approaches in several domains, including Bernoulli games, a soccer meta-game, and Kuhn poker.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019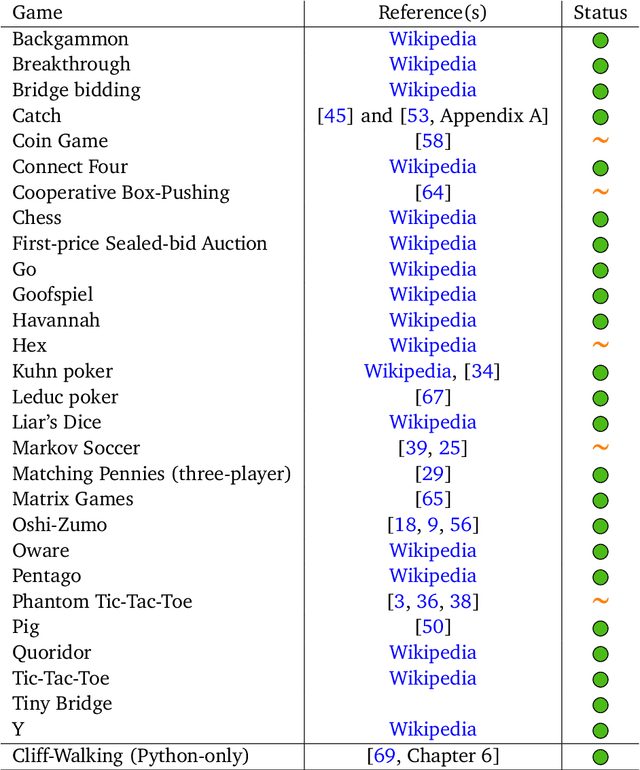
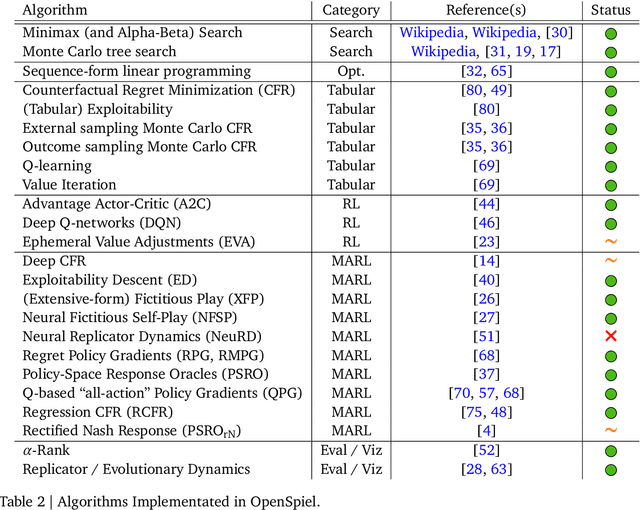
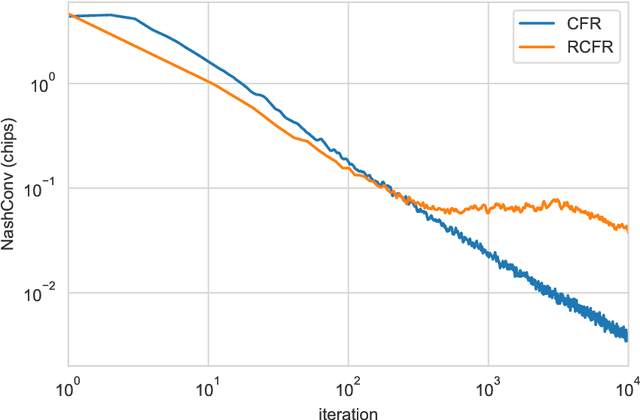
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
A Generalized Training Approach for Multiagent Learning
Sep 27, 2019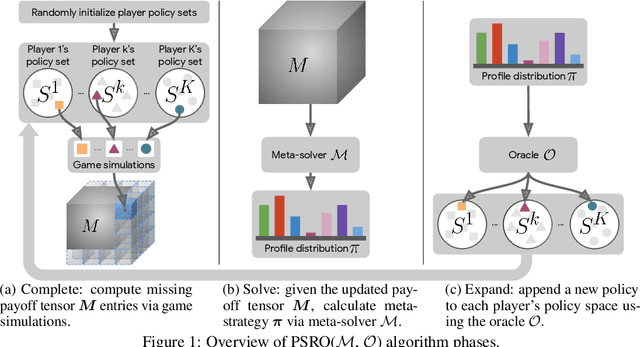
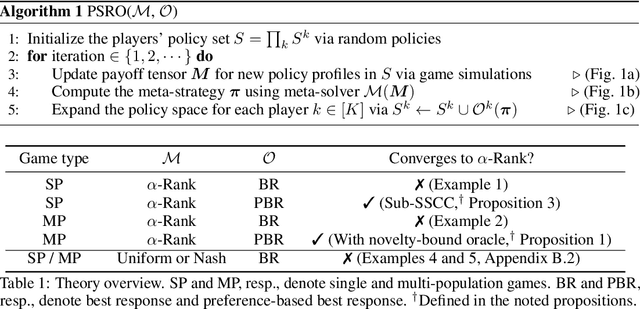
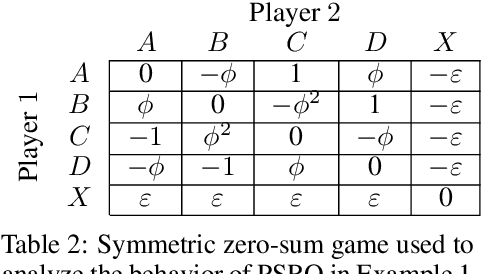
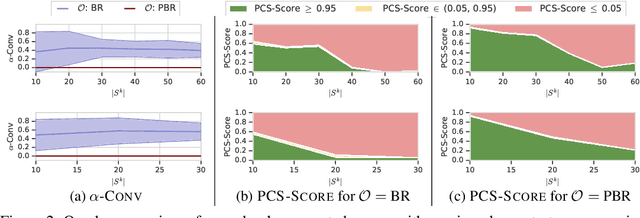
This paper investigates a population-based training regime based on game-theoretic principles called Policy-Spaced Response Oracles (PSRO). PSRO is general in the sense that it (1) encompasses well-known algorithms such as fictitious play and double oracle as special cases, and (2) in principle applies to general-sum, many-player games. Despite this, prior studies of PSRO have been focused on two-player zero-sum games, a regime wherein Nash equilibria are tractably computable. In moving from two-player zero-sum games to more general settings, computation of Nash equilibria quickly becomes infeasible. Here, we extend the theoretical underpinnings of PSRO by considering an alternative solution concept, {\alpha}-Rank, which is unique (thus faces no equilibrium selection issues, unlike Nash) and tractable to compute in general-sum, many-player settings. We establish convergence guarantees in several games classes, and identify links between Nash equilibria and {\alpha}-Rank. We demonstrate the competitive performance of {\alpha}-Rank-based PSRO against an exact Nash solver-based PSRO in 2-player Kuhn and Leduc Poker. We then go beyond the reach of prior PSRO applications by considering 3- to 5-player poker games, yielding instances where {\alpha}-Rank achieves faster convergence than approximate Nash solvers, thus establishing it as a favorable general games solver. We also carry out an initial empirical validation in MuJoCo soccer, illustrating the feasibility of the proposed approach in another complex domain.
Neural Replicator Dynamics
Jun 01, 2019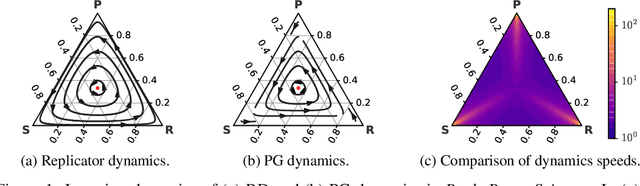

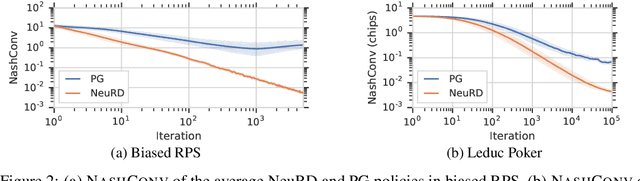
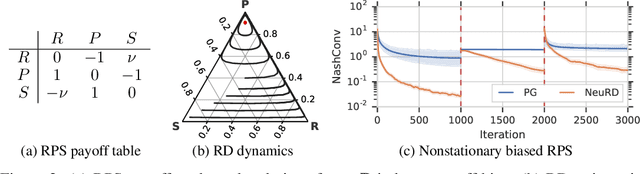
In multiagent learning, agents interact in inherently nonstationary environments due to their concurrent policy updates. It is, therefore, paramount to develop and analyze algorithms that learn effectively despite these nonstationarities. A number of works have successfully conducted this analysis under the lens of evolutionary game theory (EGT), wherein a population of individuals interact and evolve based on biologically-inspired operators. These studies have mainly focused on establishing connections to value-iteration based approaches in stateless or tabular games. We extend this line of inquiry to formally establish links between EGT and policy gradient (PG) methods, which have been extensively applied in single and multiagent learning. We pinpoint weaknesses of the commonly-used softmax PG algorithm in adversarial and nonstationary settings and contrast PG's behavior to that predicted by replicator dynamics (RD), a central model in EGT. We consequently provide theoretical results that establish links between EGT and PG methods, then derive Neural Replicator Dynamics (NeuRD), a parameterized version of RD that constitutes a novel method with several advantages. First, as NeuRD reduces to the well-studied no-regret Hedge algorithm in the tabular setting, it inherits no-regret guarantees that enable convergence to equilibria in games. Second, NeuRD is shown to be more adaptive to nonstationarity, in comparison to PG, when learning in canonical games and imperfect information benchmarks including Poker. Thirdly, modifying any PG-based algorithm to use the NeuRD update rule is straightforward and incurs no added computational costs. Finally, while single-agent learning is not the main focus of the paper, we verify empirically that NeuRD is competitive in these settings with a recent baseline algorithm.
Differentiable Game Mechanics
May 13, 2019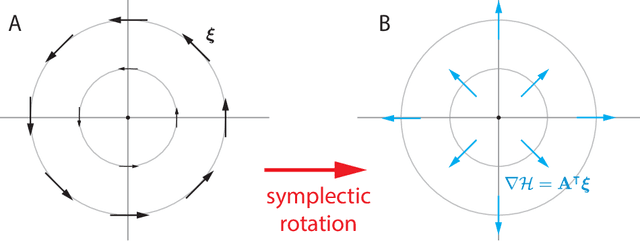
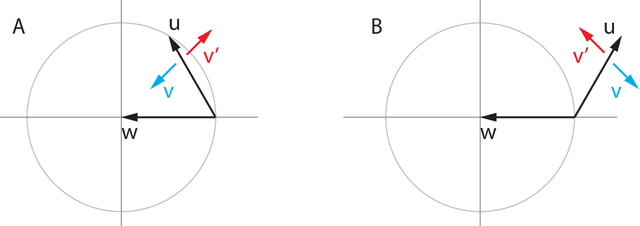
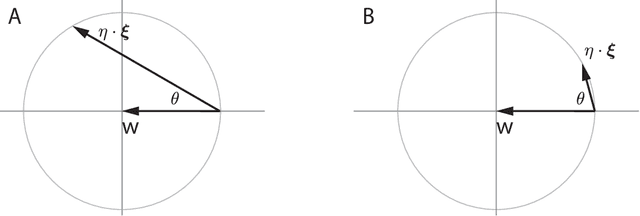
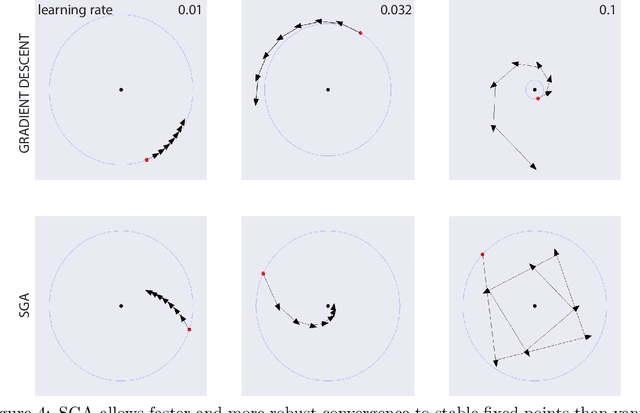
Deep learning is built on the foundational guarantee that gradient descent on an objective function converges to local minima. Unfortunately, this guarantee fails in settings, such as generative adversarial nets, that exhibit multiple interacting losses. The behavior of gradient-based methods in games is not well understood -- and is becoming increasingly important as adversarial and multi-objective architectures proliferate. In this paper, we develop new tools to understand and control the dynamics in n-player differentiable games. The key result is to decompose the game Jacobian into two components. The first, symmetric component, is related to potential games, which reduce to gradient descent on an implicit function. The second, antisymmetric component, relates to Hamiltonian games, a new class of games that obey a conservation law akin to conservation laws in classical mechanical systems. The decomposition motivates Symplectic Gradient Adjustment (SGA), a new algorithm for finding stable fixed points in differentiable games. Basic experiments show SGA is competitive with recently proposed algorithms for finding stable fixed points in GANs -- while at the same time being applicable to, and having guarantees in, much more general cases.
* JMLR 2019, journal version of arXiv:1802.05642
Evolving Indoor Navigational Strategies Using Gated Recurrent Units In NEAT
Apr 12, 2019
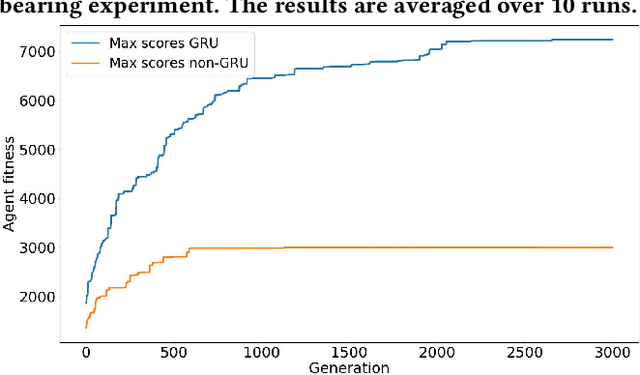
Simultaneous Localisation and Mapping (SLAM) algorithms are expensive to run on smaller robotic platforms such as Micro-Aerial Vehicles. Bug algorithms are an alternative that use relatively little processing power, and avoid high memory consumption by not building an explicit map of the environment. Bug Algorithms achieve relatively good performance in simulated and robotic maze solving domains. However, because they are hand-designed, a natural question is whether they are globally optimal control policies. In this work we explore the performance of Neuroevolution - specifically NEAT - at evolving control policies for simulated differential drive robots carrying out generalised maze navigation. We extend NEAT to include Gated Recurrent Units (GRUs) to help deal with long term dependencies. We show that both NEAT and our NEAT-GRU can repeatably generate controllers that outperform I-Bug (an algorithm particularly well-suited for use in real robots) on a test set of 209 indoor maze like environments. We show that NEAT-GRU is superior to NEAT in this task but also that out of the 2 systems, only NEAT-GRU can continuously evolve successful controllers for a much harder task in which no bearing information about the target is provided to the agent.