 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
Contextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025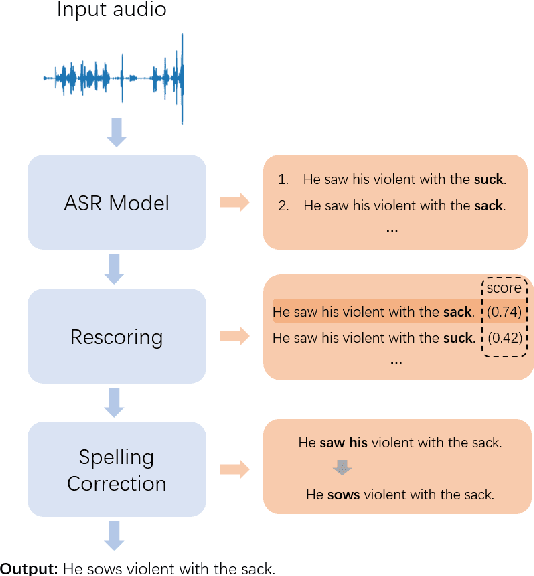



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.
CoderAgent: Simulating Student Behavior for Personalized Programming Learning with Large Language Models
May 27, 2025Personalized programming tutoring, such as exercise recommendation, can enhance learners' efficiency, motivation, and outcomes, which is increasingly important in modern digital education. However, the lack of sufficient and high-quality programming data, combined with the mismatch between offline evaluation and real-world learning, hinders the practical deployment of such systems. To address this challenge, many approaches attempt to simulate learner practice data, yet they often overlook the fine-grained, iterative nature of programming learning, resulting in a lack of interpretability and granularity. To fill this gap, we propose a LLM-based agent, CoderAgent, to simulate students' programming processes in a fine-grained manner without relying on real data. Specifically, we equip each human learner with an intelligent agent, the core of which lies in capturing the cognitive states of the human programming practice process. Inspired by ACT-R, a cognitive architecture framework, we design the structure of CoderAgent to align with human cognitive architecture by focusing on the mastery of programming knowledge and the application of coding ability. Recognizing the inherent patterns in multi-layered cognitive reasoning, we introduce the Programming Tree of Thought (PTOT), which breaks down the process into four steps: why, how, where, and what. This approach enables a detailed analysis of iterative problem-solving strategies. Finally, experimental evaluations on real-world datasets demonstrate that CoderAgent provides interpretable insights into learning trajectories and achieves accurate simulations, paving the way for personalized programming education.
Unveiling the Capabilities of Large Language Models in Detecting Offensive Language with Annotation Disagreement
Feb 10, 2025LLMs are widely used for offensive language detection due to their advanced capability. However, the challenges posed by human annotation disagreement in real-world datasets remain underexplored. These disagreement samples are difficult to detect due to their ambiguous nature. Additionally, the confidence of LLMs in processing disagreement samples can provide valuable insights into their alignment with human annotators. To address this gap, we systematically evaluate the ability of LLMs to detect offensive language with annotation disagreement. We compare the binary accuracy of multiple LLMs across varying annotation agreement levels and analyze the relationship between LLM confidence and annotation agreement. Furthermore, we investigate the impact of disagreement samples on LLM decision-making during few-shot learning and instruction fine-tuning. Our findings highlight the challenges posed by disagreement samples and offer guidance for improving LLM-based offensive language detection.
Commonality and Individuality! Integrating Humor Commonality with Speaker Individuality for Humor Recognition
Feb 07, 2025



Humor recognition aims to identify whether a specific speaker's text is humorous. Current methods for humor recognition mainly suffer from two limitations: (1) they solely focus on one aspect of humor commonalities, ignoring the multifaceted nature of humor; and (2) they typically overlook the critical role of speaker individuality, which is essential for a comprehensive understanding of humor expressions. To bridge these gaps, we introduce the Commonality and Individuality Incorporated Network for Humor Recognition (CIHR), a novel model designed to enhance humor recognition by integrating multifaceted humor commonalities with the distinctive individuality of speakers. The CIHR features a Humor Commonality Analysis module that explores various perspectives of multifaceted humor commonality within user texts, and a Speaker Individuality Extraction module that captures both static and dynamic aspects of a speaker's profile to accurately model their distinctive individuality. Additionally, Static and Dynamic Fusion modules are introduced to effectively incorporate the humor commonality with speaker's individuality in the humor recognition process. Extensive experiments demonstrate the effectiveness of CIHR, underscoring the importance of concurrently addressing both multifaceted humor commonality and distinctive speaker individuality in humor recognition.
STATE ToxiCN: A Benchmark for Span-level Target-Aware Toxicity Extraction in Chinese Hate Speech Detection
Jan 26, 2025



The proliferation of hate speech has caused significant harm to society. The intensity and directionality of hate are closely tied to the target and argument it is associated with. However, research on hate speech detection in Chinese has lagged behind, and existing datasets lack span-level fine-grained annotations. Furthermore, the lack of research on Chinese hateful slang poses a significant challenge. In this paper, we provide a solution for fine-grained detection of Chinese hate speech. First, we construct a dataset containing Target-Argument-Hateful-Group quadruples (STATE ToxiCN), which is the first span-level Chinese hate speech dataset. Secondly, we evaluate the span-level hate speech detection performance of existing models using STATE ToxiCN. Finally, we conduct the first study on Chinese hateful slang and evaluate the ability of LLMs to detect such expressions. Our work contributes valuable resources and insights to advance span-level hate speech detection in Chinese
Towards Comprehensive Detection of Chinese Harmful Memes
Oct 03, 2024



This paper has been accepted in the NeurIPS 2024 D & B Track. Harmful memes have proliferated on the Chinese Internet, while research on detecting Chinese harmful memes significantly lags behind due to the absence of reliable datasets and effective detectors. To this end, we focus on the comprehensive detection of Chinese harmful memes. We construct ToxiCN MM, the first Chinese harmful meme dataset, which consists of 12,000 samples with fine-grained annotations for various meme types. Additionally, we propose a baseline detector, Multimodal Knowledge Enhancement (MKE), incorporating contextual information of meme content generated by the LLM to enhance the understanding of Chinese memes. During the evaluation phase, we conduct extensive quantitative experiments and qualitative analyses on multiple baselines, including LLMs and our MKE. The experimental results indicate that detecting Chinese harmful memes is challenging for existing models while demonstrating the effectiveness of MKE. The resources for this paper are available at https://github.com/DUT-lujunyu/ToxiCN_MM.
Towards Patronizing and Condescending Language in Chinese Videos: A Multimodal Dataset and Detector
Sep 10, 2024



Patronizing and Condescending Language (PCL) is a form of discriminatory toxic speech targeting vulnerable groups, threatening both online and offline safety. While toxic speech research has mainly focused on overt toxicity, such as hate speech, microaggressions in the form of PCL remain underexplored. Additionally, dominant groups' discriminatory facial expressions and attitudes toward vulnerable communities can be more impactful than verbal cues, yet these frame features are often overlooked. In this paper, we introduce the PCLMM dataset, the first Chinese multimodal dataset for PCL, consisting of 715 annotated videos from Bilibili, with high-quality PCL facial frame spans. We also propose the MultiPCL detector, featuring a facial expression detection module for PCL recognition, demonstrating the effectiveness of modality complementarity in this challenging task. Our work makes an important contribution to advancing microaggression detection within the domain of toxic speech.
Integrating Multi-view Analysis: Multi-view Mixture-of-Expert for Textual Personality Detection
Aug 16, 2024



Textual personality detection aims to identify personality traits by analyzing user-generated content. To achieve this effectively, it is essential to thoroughly examine user-generated content from various perspectives. However, previous studies have struggled with automatically extracting and effectively integrating information from multiple perspectives, thereby limiting their performance on personality detection. To address these challenges, we propose the Multi-view Mixture-of-Experts Model for Textual Personality Detection (MvP). MvP introduces a Multi-view Mixture-of-Experts (MoE) network to automatically analyze user posts from various perspectives. Additionally, it employs User Consistency Regularization to mitigate conflicts among different perspectives and learn a multi-view generic user representation. The model's training is optimized via a multi-task joint learning strategy that balances supervised personality detection with self-supervised user consistency constraints. Experimental results on two widely-used personality detection datasets demonstrate the effectiveness of the MvP model and the benefits of automatically analyzing user posts from diverse perspectives for textual personality detection.