 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Aware Face Detection
Jun 29, 2017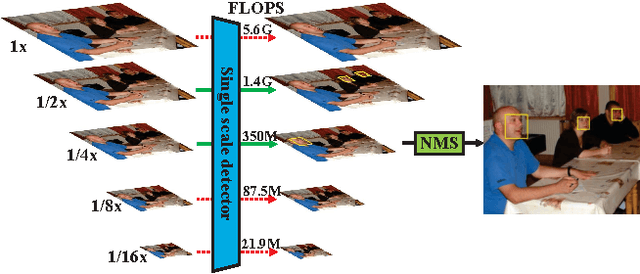
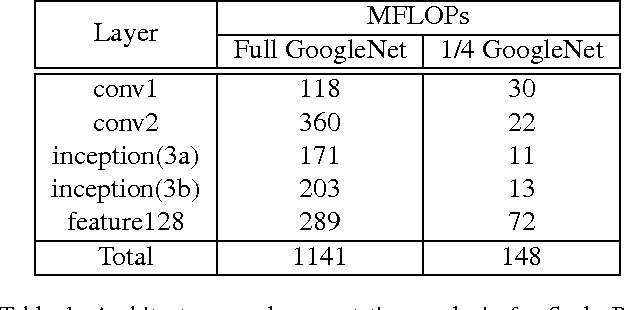
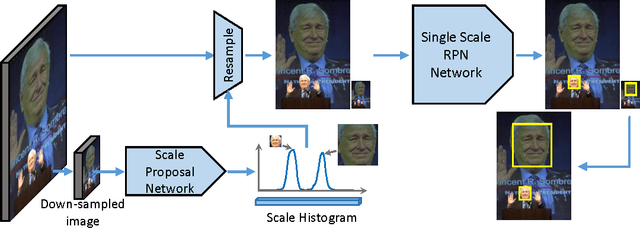

Convolutional neural network (CNN) based face detectors are inefficient in handling faces of diverse scales. They rely on either fitting a large single model to faces across a large scale range or multi-scale testing. Both are computationally expensive. We propose Scale-aware Face Detector (SAFD) to handle scale explicitly using CNN, and achieve better performance with less computation cost. Prior to detection, an efficient CNN predicts the scale distribution histogram of the faces. Then the scale histogram guides the zoom-in and zoom-out of the image. Since the faces will be approximately in uniform scale after zoom, they can be detected accurately even with much smaller CNN. Actually, more than 99% of the faces in AFW can be covered with less than two zooms per image. Extensive experiments on FDDB, MALF and AFW show advantages of SAFD.
Quality Aware Network for Set to Set Recognition
Apr 11, 2017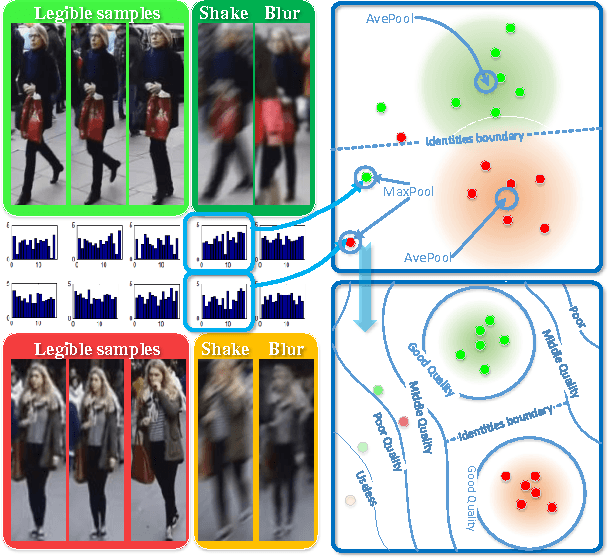
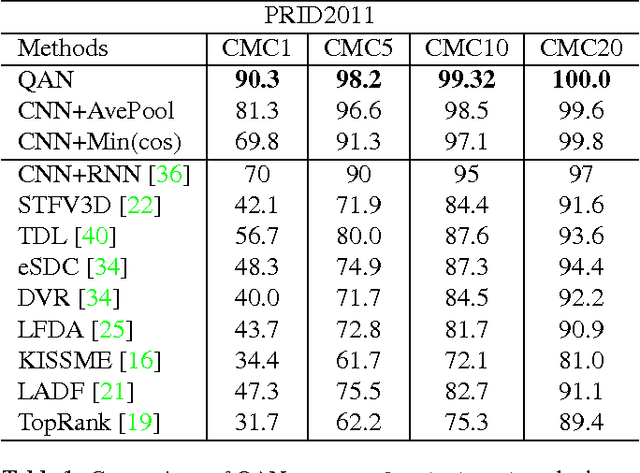

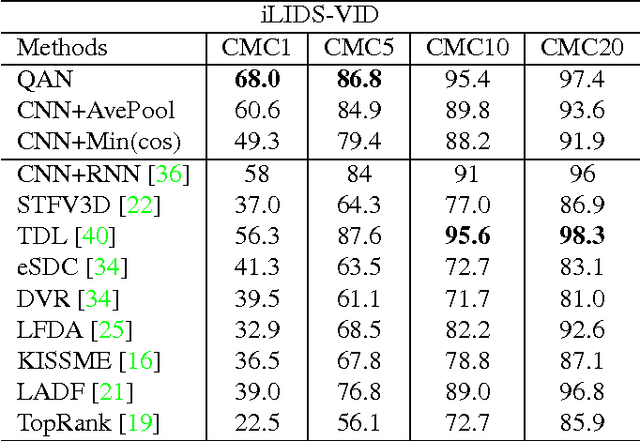
This paper targets on the problem of set to set recognition, which learns the metric between two image sets. Images in each set belong to the same identity. Since images in a set can be complementary, they hopefully lead to higher accuracy in practical applications. However, the quality of each sample cannot be guaranteed, and samples with poor quality will hurt the metric. In this paper, the quality aware network (QAN) is proposed to confront this problem, where the quality of each sample can be automatically learned although such information is not explicitly provided in the training stage. The network has two branches, where the first branch extracts appearance feature embedding for each sample and the other branch predicts quality score for each sample. Features and quality scores of all samples in a set are then aggregated to generate the final feature embedding. We show that the two branches can be trained in an end-to-end manner given only the set-level identity annotation. Analysis on gradient spread of this mechanism indicates that the quality learned by the network is beneficial to set-to-set recognition and simplifies the distribution that the network needs to fit. Experiments on both face verification and person re-identification show advantages of the proposed QAN. The source code and network structure can be downloaded at https://github.com/sciencefans/Quality-Aware-Network.
Object Detection in Videos with Tubelet Proposal Networks
Apr 10, 2017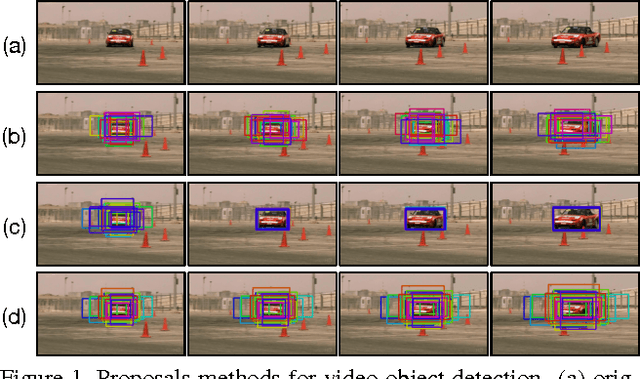
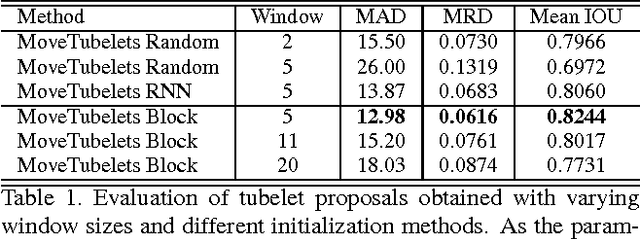
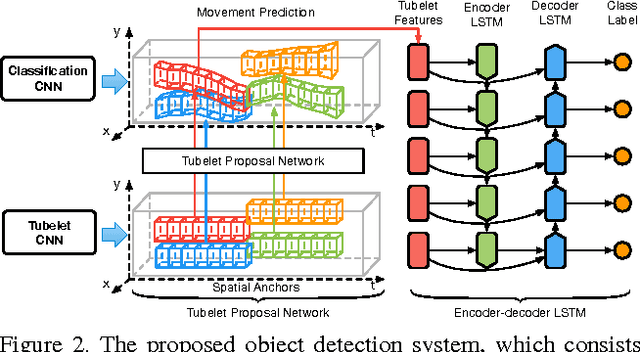
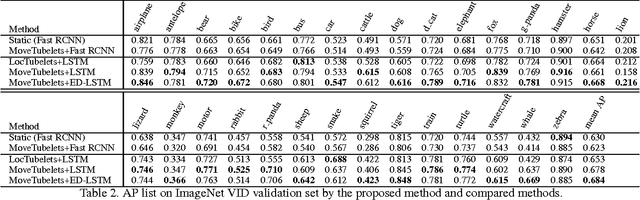
Object detection in videos has drawn increasing attention recently with the introduction of the large-scale ImageNet VID dataset. Different from object detection in static images, temporal information in videos is vital for object detection. To fully utilize temporal information, state-of-the-art methods are based on spatiotemporal tubelets, which are essentially sequences of associated bounding boxes across time. However, the existing methods have major limitations in generating tubelets in terms of quality and efficiency. Motion-based methods are able to obtain dense tubelets efficiently, but the lengths are generally only several frames, which is not optimal for incorporating long-term temporal information. Appearance-based methods, usually involving generic object tracking, could generate long tubelets, but are usually computationally expensive. In this work, we propose a framework for object detection in videos, which consists of a novel tubelet proposal network to efficiently generate spatiotemporal proposals, and a Long Short-term Memory (LSTM) network that incorporates temporal information from tubelet proposals for achieving high object detection accuracy in videos. Experiments on the large-scale ImageNet VID dataset demonstrate the effectiveness of the proposed framework for object detection in videos.
POI: Multiple Object Tracking with High Performance Detection and Appearance Feature
Oct 19, 2016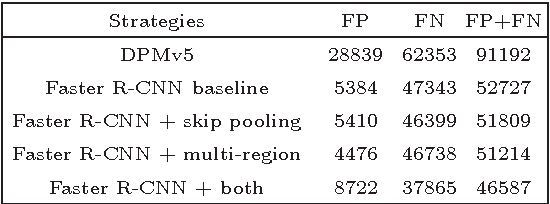


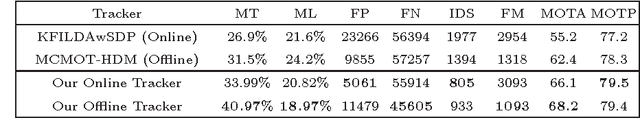
Detection and learning based appearance feature play the central role in data association based multiple object tracking (MOT), but most recent MOT works usually ignore them and only focus on the hand-crafted feature and association algorithms. In this paper, we explore the high-performance detection and deep learning based appearance feature, and show that they lead to significantly better MOT results in both online and offline setting. We make our detection and appearance feature publicly available. In the following part, we first summarize the detection and appearance feature, and then introduce our tracker named Person of Interest (POI), which has both online and offline version.
* ECCV workshop BMTT 2016
Crafting GBD-Net for Object Detection
Oct 08, 2016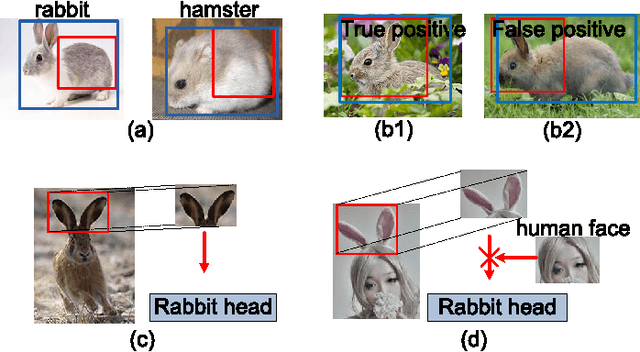
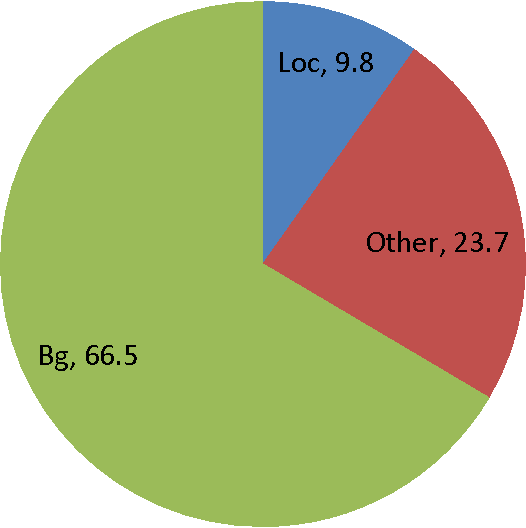
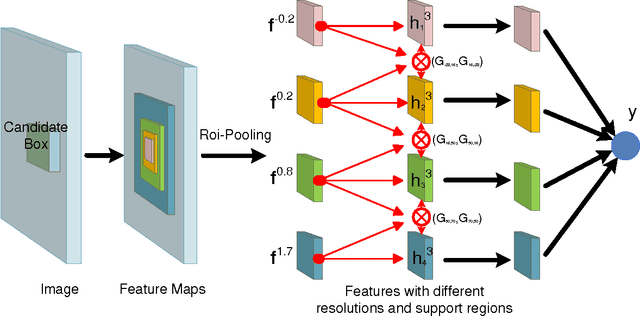
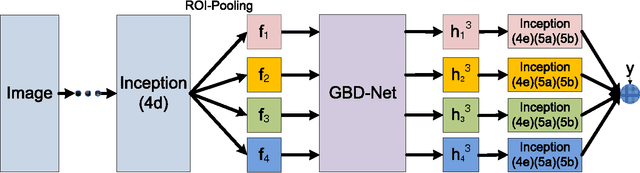
The visual cues from multiple support regions of different sizes and resolutions are complementary in classifying a candidate box in object detection. Effective integration of local and contextual visual cues from these regions has become a fundamental problem in object detection. In this paper, we propose a gated bi-directional CNN (GBD-Net) to pass messages among features from different support regions during both feature learning and feature extraction. Such message passing can be implemented through convolution between neighboring support regions in two directions and can be conducted in various layers. Therefore, local and contextual visual patterns can validate the existence of each other by learning their nonlinear relationships and their close interactions are modeled in a more complex way. It is also shown that message passing is not always helpful but dependent on individual samples. Gated functions are therefore needed to control message transmission, whose on-or-offs are controlled by extra visual evidence from the input sample. The effectiveness of GBD-Net is shown through experiments on three object detection datasets, ImageNet, Pascal VOC2007 and Microsoft COCO. This paper also shows the details of our approach in wining the ImageNet object detection challenge of 2016, with source code provided on \url{https://github.com/craftGBD/craftGBD}.
CRAFT Objects from Images
Apr 12, 2016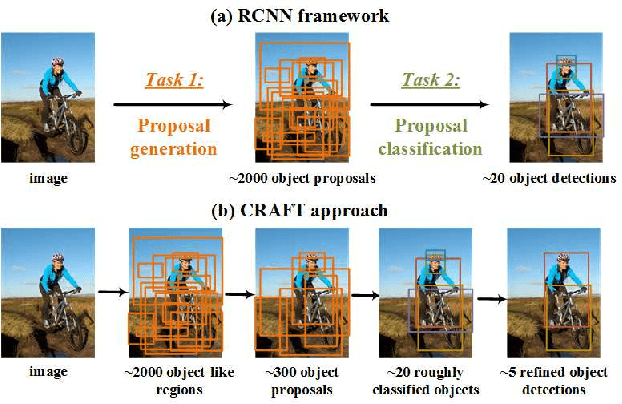


Object detection is a fundamental problem in image understanding. One popular solution is the R-CNN framework and its fast versions. They decompose the object detection problem into two cascaded easier tasks: 1) generating object proposals from images, 2) classifying proposals into various object categories. Despite that we are handling with two relatively easier tasks, they are not solved perfectly and there's still room for improvement. In this paper, we push the "divide and conquer" solution even further by dividing each task into two sub-tasks. We call the proposed method "CRAFT" (Cascade Region-proposal-network And FasT-rcnn), which tackles each task with a carefully designed network cascade. We show that the cascade structure helps in both tasks: in proposal generation, it provides more compact and better localized object proposals; in object classification, it reduces false positives (mainly between ambiguous categories) by capturing both inter- and intra-category variances. CRAFT achieves consistent and considerable improvement over the state-of-the-art on object detection benchmarks like PASCAL VOC 07/12 and ILSVRC.
Convolutional Channel Features
Sep 24, 2015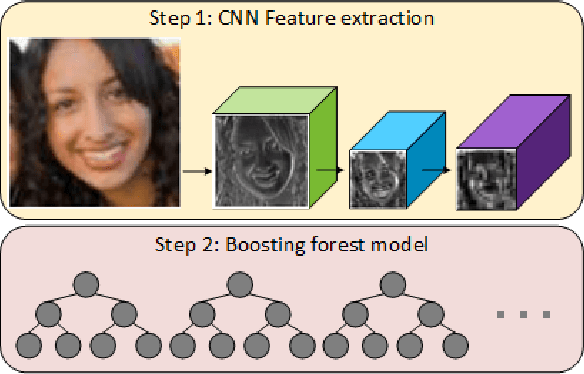
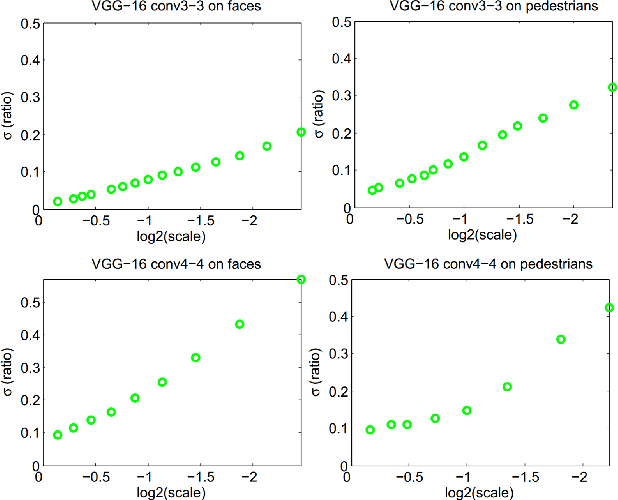
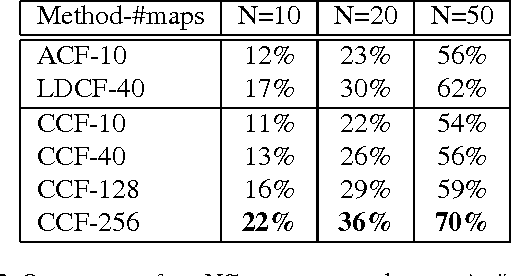
Deep learning methods are powerful tools but often suffer from expensive computation and limited flexibility. An alternative is to combine light-weight models with deep representations. As successful cases exist in several visual problems, a unified framework is absent. In this paper, we revisit two widely used approaches in computer vision, namely filtered channel features and Convolutional Neural Networks (CNN), and absorb merits from both by proposing an integrated method called Convolutional Channel Features (CCF). CCF transfers low-level features from pre-trained CNN models to feed the boosting forest model. With the combination of CNN features and boosting forest, CCF benefits from the richer capacity in feature representation compared with channel features, as well as lower cost in computation and storage compared with end-to-end CNN methods. We show that CCF serves as a good way of tailoring pre-trained CNN models to diverse tasks without fine-tuning the whole network to each task by achieving state-of-the-art performances in pedestrian detection, face detection, edge detection and object proposal generation.
To Make a Robot Secure: An Experimental Analysis of Cyber Security Threats Against Teleoperated Surgical Robots
May 12, 2015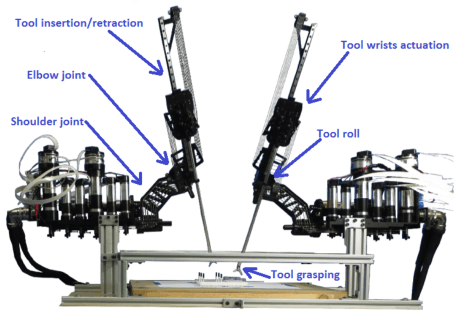

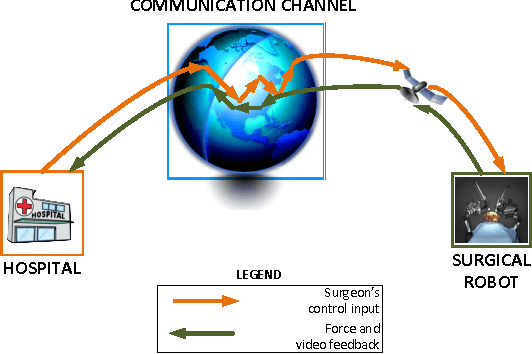
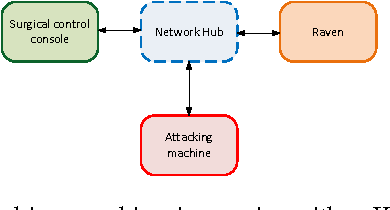
Teleoperated robots are playing an increasingly important role in military actions and medical services. In the future, remotely operated surgical robots will likely be used in more scenarios such as battlefields and emergency response. But rapidly growing applications of teleoperated surgery raise the question; what if the computer systems for these robots are attacked, taken over and even turned into weapons? Our work seeks to answer this question by systematically analyzing possible cyber security attacks against Raven II, an advanced teleoperated robotic surgery system. We identify a slew of possible cyber security threats, and experimentally evaluate their scopes and impacts. We demonstrate the ability to maliciously control a wide range of robots functions, and even to completely ignore or override command inputs from the surgeon. We further find that it is possible to abuse the robot's existing emergency stop (E-stop) mechanism to execute efficient (single packet) attacks. We then consider steps to mitigate these identified attacks, and experimentally evaluate the feasibility of applying the existing security solutions against these threats. The broader goal of our paper, however, is to raise awareness and increase understanding of these emerging threats. We anticipate that the majority of attacks against telerobotic surgery will also be relevant to other teleoperated robotic and co-robotic systems.
Aggregate channel features for multi-view face detection
Sep 03, 2014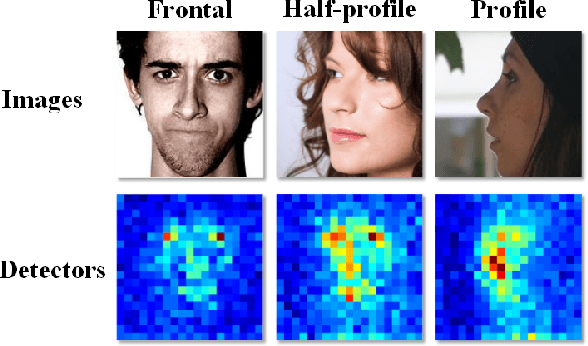
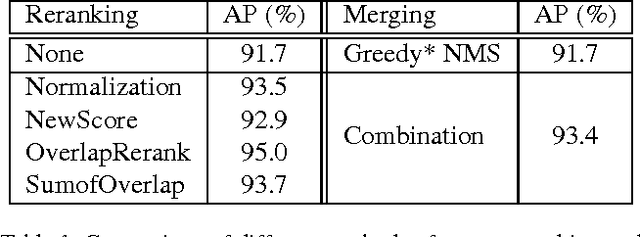
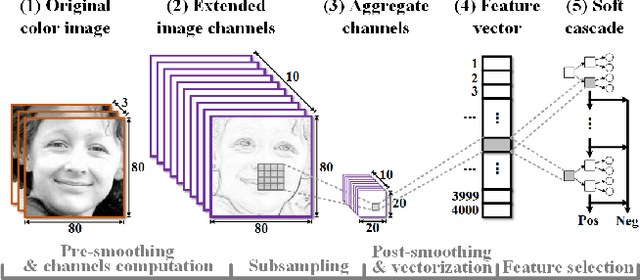
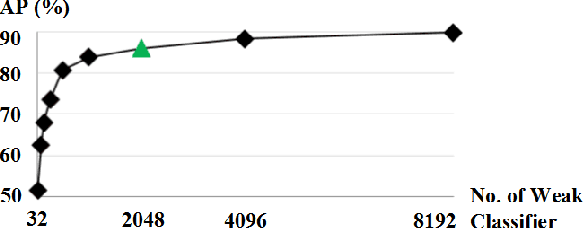
Face detection has drawn much attention in recent decades since the seminal work by Viola and Jones. While many subsequences have improved the work with more powerful learning algorithms, the feature representation used for face detection still can't meet the demand for effectively and efficiently handling faces with large appearance variance in the wild. To solve this bottleneck, we borrow the concept of channel features to the face detection domain, which extends the image channel to diverse types like gradient magnitude and oriented gradient histograms and therefore encodes rich information in a simple form. We adopt a novel variant called aggregate channel features, make a full exploration of feature design, and discover a multi-scale version of features with better performance. To deal with poses of faces in the wild, we propose a multi-view detection approach featuring score re-ranking and detection adjustment. Following the learning pipelines in Viola-Jones framework, the multi-view face detector using aggregate channel features shows competitive performance against state-of-the-art algorithms on AFW and FDDB testsets, while runs at 42 FPS on VGA images.