 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Cooperative Simulators: Generating Realistic User Personas for Robust Evaluation of LLM Agents
May 13, 2026Large Language Model (LLM) agents are increasingly deployed in settings where they interact with a wide variety of people, including users who are unclear, impatient, or reluctant to share information. However, collecting real interaction data at scale remains expensive. The field has turned to LLM-based user simulators as stand-ins, but these simulators inherit the behavior of their underlying models: cooperative and homogeneous. As a result, agents that appear strong in simulation often fail under the unseen, diverse communication patterns of real users. To narrow this gap, we introduce Persona Policies (PPol), a plug-and-play control layer that induces realistic behavioral variation in user simulators while preserving the original task goals. Rather than hand-crafting personas, we cast persona generation as an LLM-driven evolutionary program search that optimizes a Python generator to discover behaviors and translate them into task-preserving roleplay policies. Candidate generators are guided by a multi-objective fitness score combining human-likeness with broad coverage of human behavioral patterns. Once optimized, the generator produces a diverse population of human-like personas for any task in the domain. Across tau^2-bench retail and airline domains, evolved PPol programs yield 33-62% absolute gains in fitness score over the baseline simulator. In a blinded evaluation, annotators rated PPol-conditioned users as human 80.4% of the time, close to real human traces and nearly twice as frequently as baseline simulators. Agents trained with PPol are more robust to challenging, out-of-distribution behaviors, improving task success by +17% relative to training only on existing simulated interactions. This offers a novel approach to strengthen simulator-based evaluation and training without changing tasks or rewards.
Characterizing Resource Sharing Practices on Underground Internet Forum Synthetic Non-Consensual Intimate Image Content Creation Communities
Apr 14, 2026Many malicious actors responsible for disseminating synthetic non-consensual intimate imagery (SNCII) operate within internet forums to exchange resources, strategies, and generated content across multiple platforms. Technically-sophisticated actors gravitate toward certain communities (e.g., 4chan), while lower-sophistication end-users are more active on others (e.g., Reddit). To characterize key stakeholders in the broader ecosystem, we perform an integrated analysis of multiple communities, analyzing 282,154 4chan comments and 78,308 Reddit submissions spanning 165 days between June and November 2025 to characterize involved actors, actions, and resources. We find: (a) that users with differing levels of technical sophistication employ and share a wide range of primary resources facilitating SNCII content creation as well as numerous secondary resources facilitating dissemination; and (b) that knowledge transfer between experts and newcomers facilitates propagation of these illicit resources. Based on our empirical analysis, we identify gaps in existing SNCII regulatory infrastructure and synthesize several critical intervention points for bolstering deterrence.
Analyzing the AI Nudification Application Ecosystem
Nov 14, 2024



Given a source image of a clothed person (an image subject), AI-based nudification applications can produce nude (undressed) images of that person. Moreover, not only do such applications exist, but there is ample evidence of the use of such applications in the real world and without the consent of an image subject. Still, despite the growing awareness of the existence of such applications and their potential to violate the rights of image subjects and cause downstream harms, there has been no systematic study of the nudification application ecosystem across multiple applications. We conduct such a study here, focusing on 20 popular and easy-to-find nudification websites. We study the positioning of these web applications (e.g., finding that most sites explicitly target the nudification of women, not all people), the features that they advertise (e.g., ranging from undressing-in-place to the rendering of image subjects in sexual positions, as well as differing user-privacy options), and their underlying monetization infrastructure (e.g., credit cards and cryptocurrencies). We believe this work will empower future, data-informed conversations -- within the scientific, technical, and policy communities -- on how to better protect individuals' rights and minimize harm in the face of modern (and future) AI-based nudification applications. Content warning: This paper includes descriptions of web applications that can be used to create synthetic non-consensual explicit AI-created imagery (SNEACI). This paper also includes an artistic rendering of a user interface for such an application.
Breaking News: Case Studies of Generative AI's Use in Journalism
Jun 19, 2024



Journalists are among the many users of large language models (LLMs). To better understand the journalist-AI interactions, we conduct a study of LLM usage by two news agencies through browsing the WildChat dataset, identifying candidate interactions, and verifying them by matching to online published articles. Our analysis uncovers instances where journalists provide sensitive material such as confidential correspondence with sources or articles from other agencies to the LLM as stimuli and prompt it to generate articles, and publish these machine-generated articles with limited intervention (median output-publication ROUGE-L of 0.62). Based on our findings, we call for further research into what constitutes responsible use of AI, and the establishment of clear guidelines and best practices on using LLMs in a journalistic context.
Who's in and who's out? A case study of multimodal CLIP-filtering in DataComp
May 13, 2024



As training datasets become increasingly drawn from unstructured, uncontrolled environments such as the web, researchers and industry practitioners have increasingly relied upon data filtering techniques to "filter out the noise" of web-scraped data. While datasets have been widely shown to reflect the biases and values of their creators, in this paper we contribute to an emerging body of research that assesses the filters used to create these datasets. We show that image-text data filtering also has biases and is value-laden, encoding specific notions of what is counted as "high-quality" data. In our work, we audit a standard approach of image-text CLIP-filtering on the academic benchmark DataComp's CommonPool by analyzing discrepancies of filtering through various annotation techniques across multiple modalities of image, text, and website source. We find that data relating to several imputed demographic groups -- such as LGBTQ+ people, older women, and younger men -- are associated with higher rates of exclusion. Moreover, we demonstrate cases of exclusion amplification: not only are certain marginalized groups already underrepresented in the unfiltered data, but CLIP-filtering excludes data from these groups at higher rates. The data-filtering step in the machine learning pipeline can therefore exacerbate representation disparities already present in the data-gathering step, especially when existing filters are designed to optimize a specifically-chosen downstream performance metric like zero-shot image classification accuracy. Finally, we show that the NSFW filter fails to remove sexually-explicit content from CommonPool, and that CLIP-filtering includes several categories of copyrighted content at high rates. Our conclusions point to a need for fundamental changes in dataset creation and filtering practices.
Particip-AI: A Democratic Surveying Framework for Anticipating Future AI Use Cases, Harms and Benefits
Mar 21, 2024



General purpose AI, such as ChatGPT, seems to have lowered the barriers for the public to use AI and harness its power. However, the governance and development of AI still remain in the hands of a few, and the pace of development is accelerating without proper assessment of risks. As a first step towards democratic governance and risk assessment of AI, we introduce Particip-AI, a framework to gather current and future AI use cases and their harms and benefits from non-expert public. Our framework allows us to study more nuanced and detailed public opinions on AI through collecting use cases, surfacing diverse harms through risk assessment under alternate scenarios (i.e., developing and not developing a use case), and illuminating tensions over AI development through making a concluding choice on its development. To showcase the promise of our framework towards guiding democratic AI, we gather responses from 295 demographically diverse participants. We find that participants' responses emphasize applications for personal life and society, contrasting with most current AI development's business focus. This shows the value of surfacing diverse harms that are complementary to expert assessments. Furthermore, we found that perceived impact of not developing use cases predicted participants' judgements of whether AI use cases should be developed, and highlighted lay users' concerns of techno-solutionism. We conclude with a discussion on how frameworks like Particip-AI can further guide democratic AI governance and regulation.
SecGPT: An Execution Isolation Architecture for LLM-Based Systems
Mar 08, 2024



Large language models (LLMs) extended as systems, such as ChatGPT, have begun supporting third-party applications. These LLM apps leverage the de facto natural language-based automated execution paradigm of LLMs: that is, apps and their interactions are defined in natural language, provided access to user data, and allowed to freely interact with each other and the system. These LLM app ecosystems resemble the settings of earlier computing platforms, where there was insufficient isolation between apps and the system. Because third-party apps may not be trustworthy, and exacerbated by the imprecision of the natural language interfaces, the current designs pose security and privacy risks for users. In this paper, we propose SecGPT, an architecture for LLM-based systems that aims to mitigate the security and privacy issues that arise with the execution of third-party apps. SecGPT's key idea is to isolate the execution of apps and more precisely mediate their interactions outside of their isolated environments. We evaluate SecGPT against a number of case study attacks and demonstrate that it protects against many security, privacy, and safety issues that exist in non-isolated LLM-based systems. The performance overhead incurred by SecGPT to improve security is under 0.3x for three-quarters of the tested queries. To foster follow-up research, we release SecGPT's source code at https://github.com/llm-platform-security/SecGPT.
LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI's ChatGPT Plugins
Sep 19, 2023



Large language model (LLM) platforms, such as ChatGPT, have recently begun offering a plugin ecosystem to interface with third-party services on the internet. While these plugins extend the capabilities of LLM platforms, they are developed by arbitrary third parties and thus cannot be implicitly trusted. Plugins also interface with LLM platforms and users using natural language, which can have imprecise interpretations. In this paper, we propose a framework that lays a foundation for LLM platform designers to analyze and improve the security, privacy, and safety of current and future plugin-integrated LLM platforms. Our framework is a formulation of an attack taxonomy that is developed by iteratively exploring how LLM platform stakeholders could leverage their capabilities and responsibilities to mount attacks against each other. As part of our iterative process, we apply our framework in the context of OpenAI's plugin ecosystem. We uncover plugins that concretely demonstrate the potential for the types of issues that we outline in our attack taxonomy. We conclude by discussing novel challenges and by providing recommendations to improve the security, privacy, and safety of present and future LLM-based computing platforms.
Is the U.S. Legal System Ready for AI's Challenges to Human Values?
Sep 05, 2023Our interdisciplinary study investigates how effectively U.S. laws confront the challenges posed by Generative AI to human values. Through an analysis of diverse hypothetical scenarios crafted during an expert workshop, we have identified notable gaps and uncertainties within the existing legal framework regarding the protection of fundamental values, such as privacy, autonomy, dignity, diversity, equity, and physical/mental well-being. Constitutional and civil rights, it appears, may not provide sufficient protection against AI-generated discriminatory outputs. Furthermore, even if we exclude the liability shield provided by Section 230, proving causation for defamation and product liability claims is a challenging endeavor due to the intricate and opaque nature of AI systems. To address the unique and unforeseeable threats posed by Generative AI, we advocate for legal frameworks that evolve to recognize new threats and provide proactive, auditable guidelines to industry stakeholders. Addressing these issues requires deep interdisciplinary collaborations to identify harms, values, and mitigation strategies.
Re-purposing Perceptual Hashing based Client Side Scanning for Physical Surveillance
Dec 08, 2022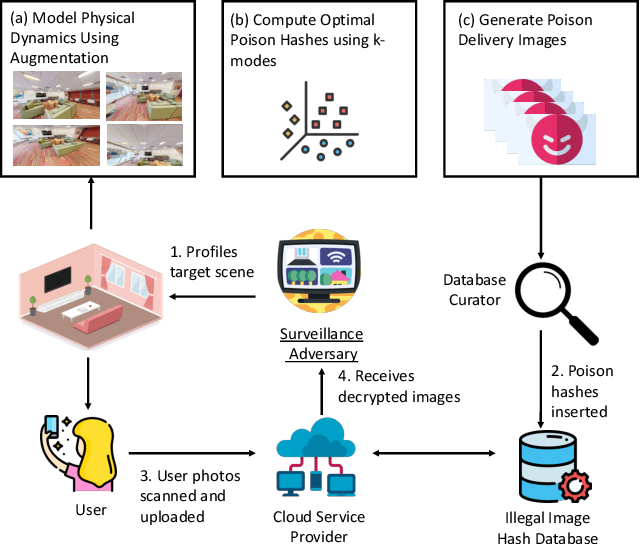
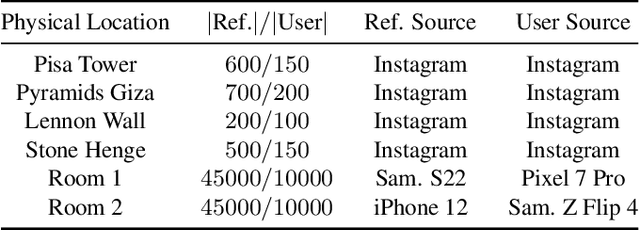
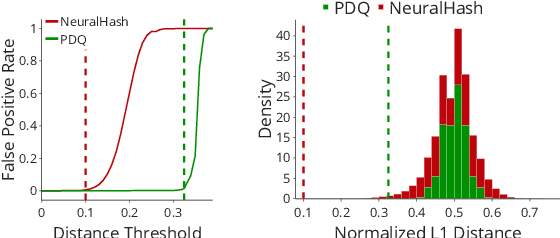

Content scanning systems employ perceptual hashing algorithms to scan user content for illegal material, such as child pornography or terrorist recruitment flyers. Perceptual hashing algorithms help determine whether two images are visually similar while preserving the privacy of the input images. Several efforts from industry and academia propose to conduct content scanning on client devices such as smartphones due to the impending roll out of end-to-end encryption that will make server-side content scanning difficult. However, these proposals have met with strong criticism because of the potential for the technology to be misused and re-purposed. Our work informs this conversation by experimentally characterizing the potential for one type of misuse -- attackers manipulating the content scanning system to perform physical surveillance on target locations. Our contributions are threefold: (1) we offer a definition of physical surveillance in the context of client-side image scanning systems; (2) we experimentally characterize this risk and create a surveillance algorithm that achieves physical surveillance rates of >40% by poisoning 5% of the perceptual hash database; (3) we experimentally study the trade-off between the robustness of client-side image scanning systems and surveillance, showing that more robust detection of illegal material leads to increased potential for physical surveillance.