 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
Direct Speech-to-speech Translation without Textual Annotation using Bottleneck Features
Dec 12, 2022



Speech-to-speech translation directly translates a speech utterance to another between different languages, and has great potential in tasks such as simultaneous interpretation. State-of-art models usually contains an auxiliary module for phoneme sequences prediction, and this requires textual annotation of the training dataset. We propose a direct speech-to-speech translation model which can be trained without any textual annotation or content information. Instead of introducing an auxiliary phoneme prediction task in the model, we propose to use bottleneck features as intermediate training objectives for our model to ensure the translation performance of the system. Experiments on Mandarin-Cantonese speech translation demonstrate the feasibility of the proposed approach and the performance can match a cascaded system with respect of translation and synthesis qualities.
A Novel Chinese Dialect TTS Frontend with Non-Autoregressive Neural Machine Translation
Jun 15, 2022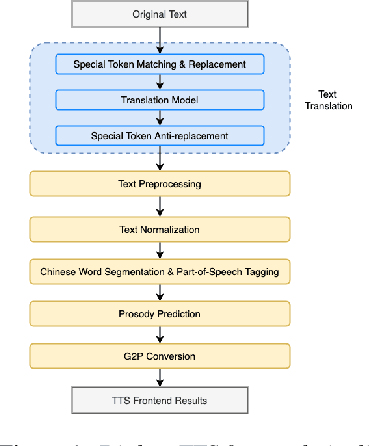
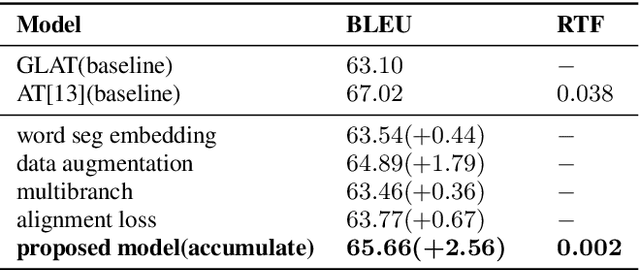
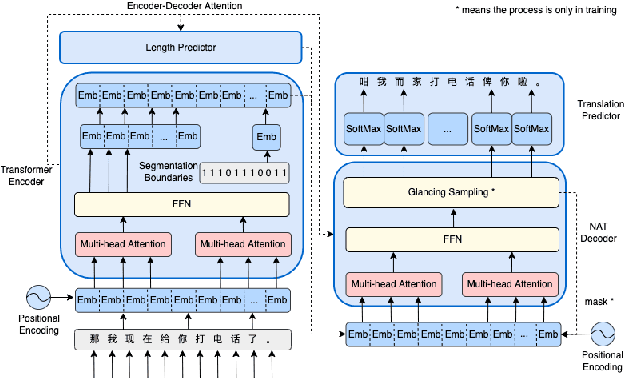

Chinese dialect text-to-speech(TTS) system usually can only be utilized by native linguists, because the written form of Chinese dialects has different characters, idioms, grammar and usage from Mandarin, and even the local speaker cannot input a correct sentence. For Mandarin text inputs, Chinese dialect TTS can only generate partly-meaningful speech with relatively poor prosody and naturalness. To lower the bar of use and make it more practical in commercial, we propose a novel Chinese dialect TTS frontend with a translation module. It helps to convert Mandarin text into idiomatic expressions with correct orthography and grammar, so that the intelligibility and naturalness of the synthesized speech can be improved. A non-autoregressive neural machine translation model with a glancing sampling strategy is proposed for the translation task. It is the first known work to incorporate translation with TTS frontend. Our experiments on Cantonese approve that the proposed frontend can help Cantonese TTS system achieve a 0.27 improvement in MOS with Mandarin inputs.
Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Oct 11, 2021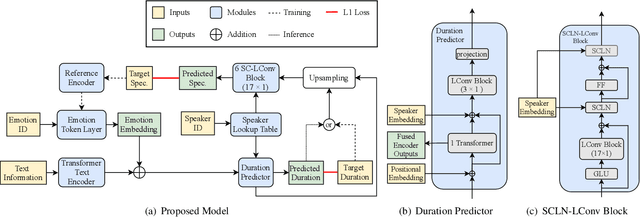
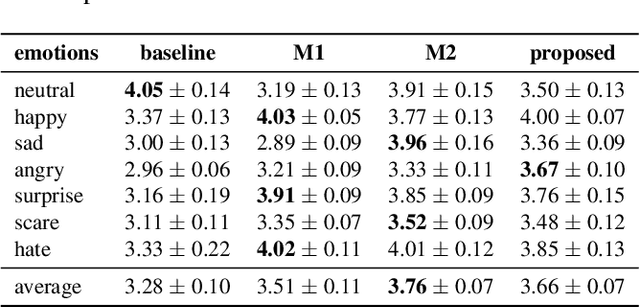
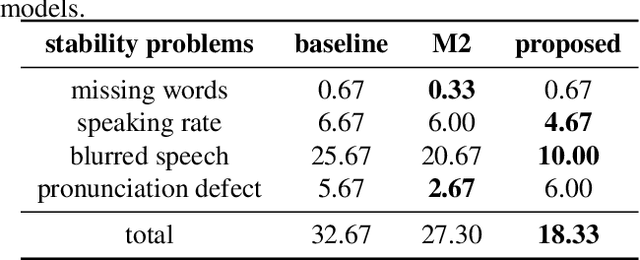
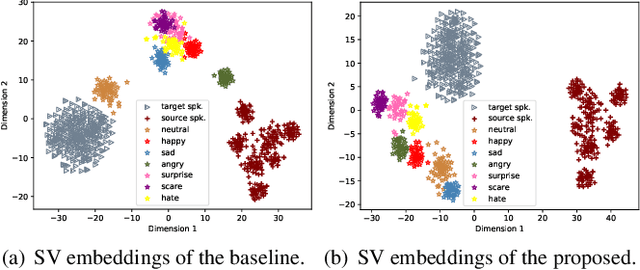
In expressive speech synthesis, there are high requirements for emotion interpretation. However, it is time-consuming to acquire emotional audio corpus for arbitrary speakers due to their deduction ability. In response to this problem, this paper proposes a cross-speaker emotion transfer method that can realize the transfer of emotions from source speaker to target speaker. A set of emotion tokens is firstly defined to represent various categories of emotions. They are trained to be highly correlated with corresponding emotions for controllable synthesis by cross-entropy loss and semi-supervised training strategy. Meanwhile, to eliminate the down-gradation to the timbre similarity from cross-speaker emotion transfer, speaker condition layer normalization is implemented to model speaker characteristics. Experimental results show that the proposed method outperforms the multi-reference based baseline in terms of timbre similarity, stability and emotion perceive evaluations.
A hybrid text normalization system using multi-head self-attention for mandarin
Nov 11, 2019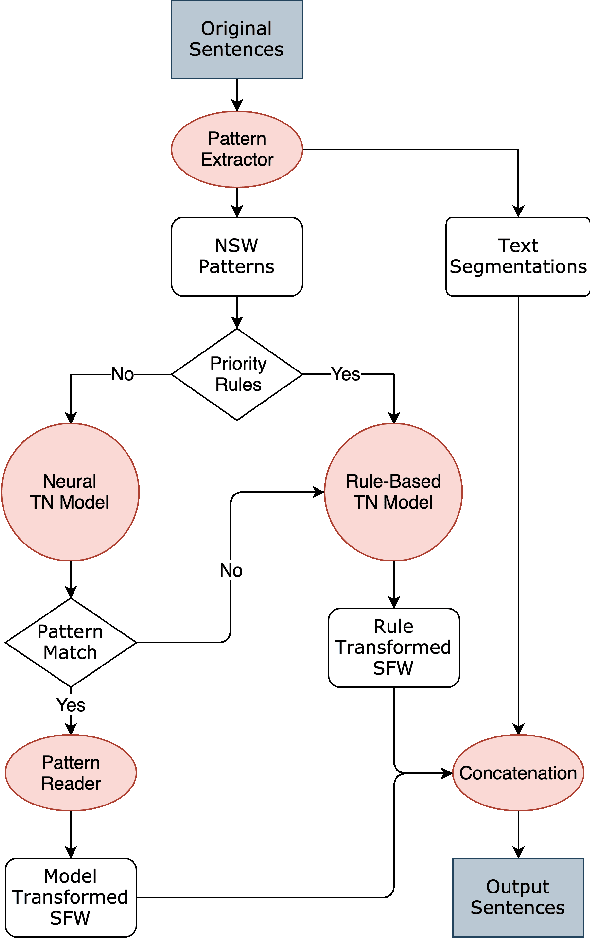
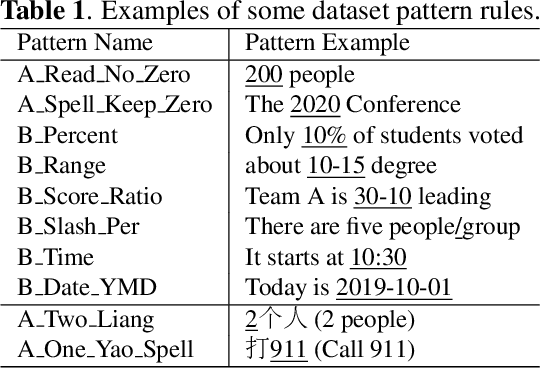
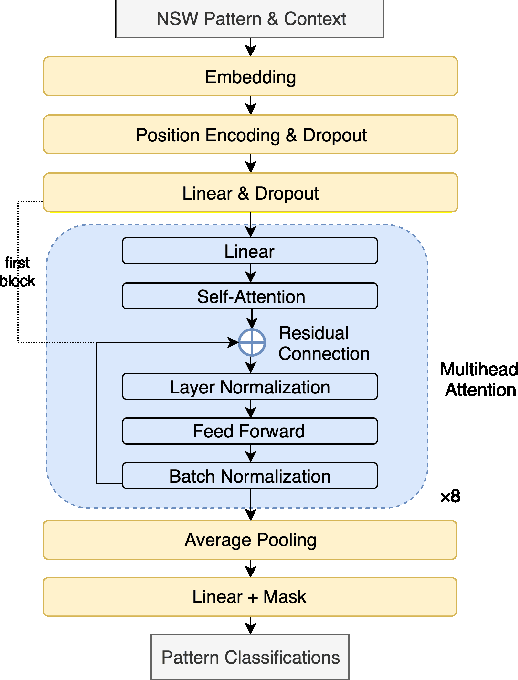
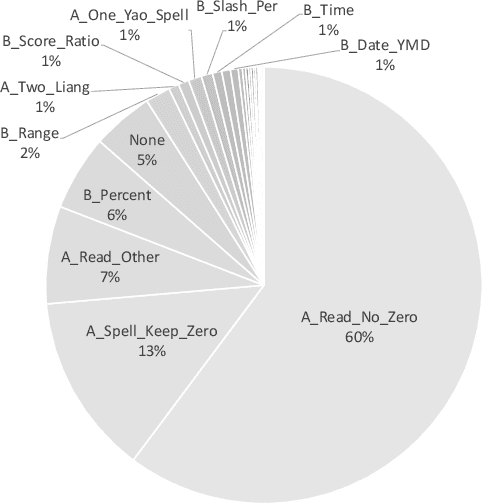
In this paper, we propose a hybrid text normalization system using multi-head self-attention. The system combines the advantages of a rule-based model and a neural model for text preprocessing tasks. Previous studies in Mandarin text normalization usually use a set of hand-written rules, which are hard to improve on general cases. The idea of our proposed system is motivated by the neural models from recent studies and has a better performance on our internal news corpus. This paper also includes different attempts to deal with imbalanced pattern distribution of the dataset. Overall, the performance of the system is improved by over 1.5% on sentence-level and it has a potential to improve further.
A unified sequence-to-sequence front-end model for Mandarin text-to-speech synthesis
Nov 11, 2019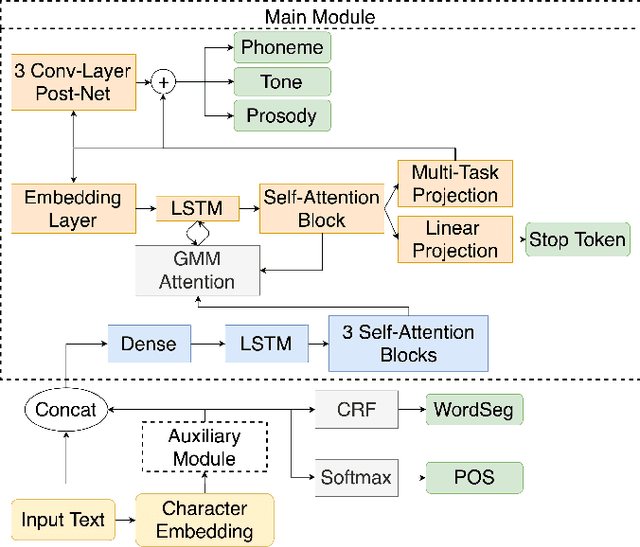

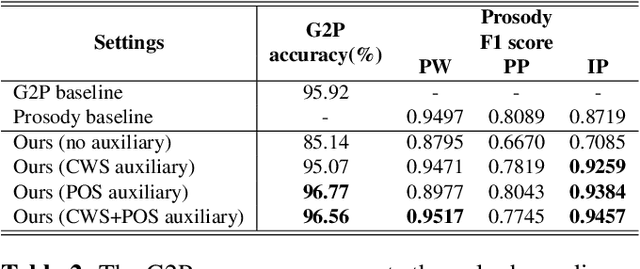
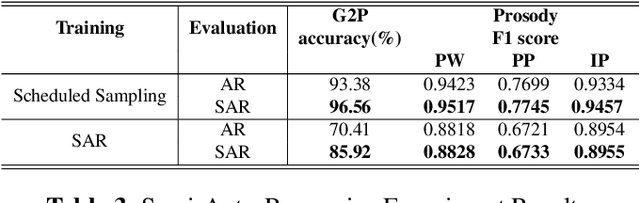
In Mandarin text-to-speech (TTS) system, the front-end text processing module significantly influences the intelligibility and naturalness of synthesized speech. Building a typical pipeline-based front-end which consists of multiple individual components requires extensive efforts. In this paper, we proposed a unified sequence-to-sequence front-end model for Mandarin TTS that converts raw texts to linguistic features directly. Compared to the pipeline-based front-end, our unified front-end can achieve comparable performance in polyphone disambiguation and prosody word prediction, and improve intonation phrase prediction by 0.0738 in F1 score. We also implemented the unified front-end with Tacotron and WaveRNN to build a Mandarin TTS system. The synthesized speech by that got a comparable MOS (4.38) with the pipeline-based front-end (4.37) and close to human recordings (4.49).