 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatten: Video Action Recognition is an Image Classification task
Aug 17, 2024



In recent years, video action recognition, as a fundamental task in the field of video understanding, has been deeply explored by numerous researchers.Most traditional video action recognition methods typically involve converting videos into three-dimensional data that encapsulates both spatial and temporal information, subsequently leveraging prevalent image understanding models to model and analyze these data. However,these methods have significant drawbacks. Firstly, when delving into video action recognition tasks, image understanding models often need to be adapted accordingly in terms of model architecture and preprocessing for these spatiotemporal tasks; Secondly, dealing with high-dimensional data often poses greater challenges and incurs higher time costs compared to its lower-dimensional counterparts.To bridge the gap between image-understanding and video-understanding tasks while simplifying the complexity of video comprehension, we introduce a novel video representation architecture, Flatten, which serves as a plug-and-play module that can be seamlessly integrated into any image-understanding network for efficient and effective 3D temporal data modeling.Specifically, by applying specific flattening operations (e.g., row-major transform), 3D spatiotemporal data is transformed into 2D spatial information, and then ordinary image understanding models are used to capture temporal dynamic and spatial semantic information, which in turn accomplishes effective and efficient video action recognition. Extensive experiments on commonly used datasets (Kinetics-400, Something-Something v2, and HMDB-51) and three classical image classification models (Uniformer, SwinV2, and ResNet), have demonstrated that embedding Flatten provides a significant performance improvements over original model.
SSPA: Split-and-Synthesize Prompting with Gated Alignments for Multi-Label Image Recognition
Jul 30, 2024



Multi-label image recognition is a fundamental task in computer vision. Recently, Vision-Language Models (VLMs) have made notable advancements in this area. However, previous methods fail to effectively leverage the rich knowledge in language models and often incorporate label semantics into visual features unidirectionally. To overcome these problems, we propose a Split-and-Synthesize Prompting with Gated Alignments (SSPA) framework to amplify the potential of VLMs. Specifically, we develop an in-context learning approach to associate the inherent knowledge from LLMs. Then we propose a novel Split-and-Synthesize Prompting (SSP) strategy to first model the generic knowledge and downstream label semantics individually and then aggregate them carefully through the quaternion network. Moreover, we present Gated Dual-Modal Alignments (GDMA) to bidirectionally interact visual and linguistic modalities while eliminating redundant cross-modal information, enabling more efficient region-level alignments. Rather than making the final prediction by a sharp manner in previous works, we propose a soft aggregator to jointly consider results from all image regions. With the help of flexible prompting and gated alignments, SSPA is generalizable to specific domains. Extensive experiments on nine datasets from three domains (i.e., natural, pedestrian attributes and remote sensing) demonstrate the state-of-the-art performance of SSPA. Further analyses verify the effectiveness of SSP and the interpretability of GDMA. The code will be made public.
Garment Animation NeRF with Color Editing
Jul 29, 2024



Generating high-fidelity garment animations through traditional workflows, from modeling to rendering, is both tedious and expensive. These workflows often require repetitive steps in response to updates in character motion, rendering viewpoint changes, or appearance edits. Although recent neural rendering offers an efficient solution for computationally intensive processes, it struggles with rendering complex garment animations containing fine wrinkle details and realistic garment-and-body occlusions, while maintaining structural consistency across frames and dense view rendering. In this paper, we propose a novel approach to directly synthesize garment animations from body motion sequences without the need for an explicit garment proxy. Our approach infers garment dynamic features from body motion, providing a preliminary overview of garment structure. Simultaneously, we capture detailed features from synthesized reference images of the garment's front and back, generated by a pre-trained image model. These features are then used to construct a neural radiance field that renders the garment animation video. Additionally, our technique enables garment recoloring by decomposing its visual elements. We demonstrate the generalizability of our method across unseen body motions and camera views, ensuring detailed structural consistency. Furthermore, we showcase its applicability to color editing on both real and synthetic garment data. Compared to existing neural rendering techniques, our method exhibits qualitative and quantitative improvements in garment dynamics and wrinkle detail modeling. Code is available at \url{https://github.com/wrk226/GarmentAnimationNeRF}.
EarthMarker: Visual Prompt Learning for Region-level and Point-level Remote Sensing Imagery Comprehension
Jul 20, 2024



Recent advances in visual prompting in the natural image area have allowed users to interact with artificial intelligence (AI) tools through various visual marks such as box, point, and free-form shapes. However, due to the significant difference between the natural and remote sensing (RS) images, existing visual prompting models face challenges in RS scenarios. Moreover, RS MLLMs mainly focus on interpreting image-level RS data and only support interaction with language instruction, restricting flexibility applications in the real world. To address those limitations, the first visual prompting model named EarthMarker is proposed, which excels in image-level, region-level, and point-level RS imagery interpretation. Specifically, the visual prompts alongside images and text instruction input into the large language model (LLM), adapt models toward specific predictions and tasks. Subsequently, a sharing visual encoding method is introduced to refine multi-scale image features and visual prompt information uniformly. Furthermore, to endow the EarthMarker with versatile multi-granularity visual perception abilities, the cross-domain phased learning strategy is developed, and the disjoint parameters are optimized in a lightweight manner by leveraging both the natural and RS domain-specific knowledge. In addition, to tackle the lack of RS visual prompting data, a dataset named RSVP featuring multi-modal fine-grained visual prompting instruction is constructed. Extensive experiments are conducted to demonstrate the proposed EarthMarker's competitive performance, representing a significant advance in multi-granularity RS imagery interpretation under the visual prompting learning framework.
Unsupervised Domain Adaptive Lane Detection via Contextual Contrast and Aggregation
Jul 18, 2024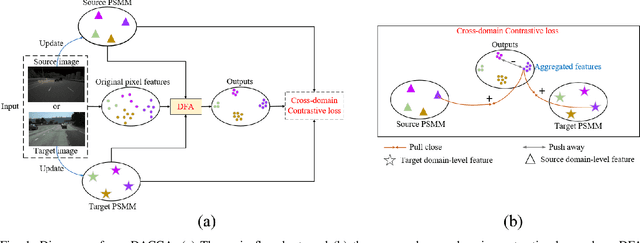
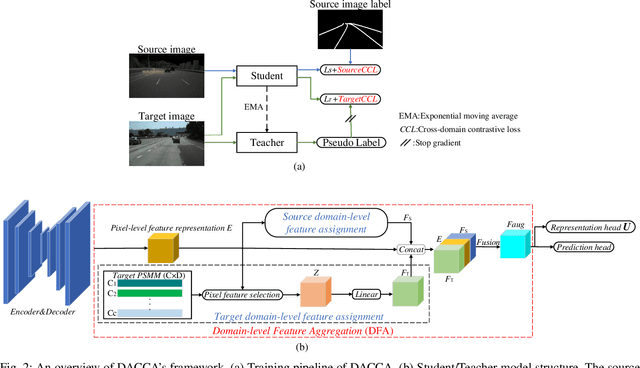

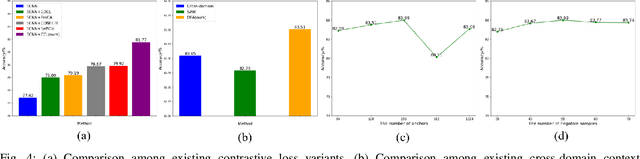
This paper focuses on two crucial issues in domain-adaptive lane detection, i.e., how to effectively learn discriminative features and transfer knowledge across domains. Existing lane detection methods usually exploit a pixel-wise cross-entropy loss to train detection models. However, the loss ignores the difference in feature representation among lanes, which leads to inefficient feature learning. On the other hand, cross-domain context dependency crucial for transferring knowledge across domains remains unexplored in existing lane detection methods. This paper proposes a method of Domain-Adaptive lane detection via Contextual Contrast and Aggregation (DACCA), consisting of two key components, i.e., cross-domain contrastive loss and domain-level feature aggregation, to realize domain-adaptive lane detection. The former can effectively differentiate feature representations among categories by taking domain-level features as positive samples. The latter fuses the domain-level and pixel-level features to strengthen cross-domain context dependency. Extensive experiments show that DACCA significantly improves the detection model's performance and outperforms existing unsupervised domain adaptive lane detection methods on six datasets, especially achieving the best performance when transferring from CULane to Tusimple (92.10% accuracy), Tusimple to CULane (41.9% F1 score), OpenLane to CULane (43.0% F1 score), and CULane to OpenLane (27.6% F1 score).
DFMSD: Dual Feature Masking Stage-wise Knowledge Distillation for Object Detection
Jul 18, 2024In recent years, current mainstream feature masking distillation methods mainly function by reconstructing selectively masked regions of a student network from the feature maps of a teacher network. In these methods, attention mechanisms can help to identify spatially important regions and crucial object-aware channel clues, such that the reconstructed features are encoded with sufficient discriminative and representational power similar to teacher features. However, previous feature-masking distillation methods mainly address homogeneous knowledge distillation without fully taking into account the heterogeneous knowledge distillation scenario. In particular, the huge discrepancy between the teacher and the student frameworks within the heterogeneous distillation paradigm is detrimental to feature masking, leading to deteriorating reconstructed student features. In this study, a novel dual feature-masking heterogeneous distillation framework termed DFMSD is proposed for object detection. More specifically, a stage-wise adaptation learning module is incorporated into the dual feature-masking framework, and thus the student model can be progressively adapted to the teacher models for bridging the gap between heterogeneous networks. Furthermore, a masking enhancement strategy is combined with stage-wise learning such that object-aware masking regions are adaptively strengthened to improve feature-masking reconstruction. In addition, semantic alignment is performed at each Feature Pyramid Network (FPN) layer between the teacher and the student networks for generating consistent feature distributions. Our experiments for the object detection task demonstrate the promise of our approach, suggesting that DFMSD outperforms both the state-of-the-art heterogeneous and homogeneous distillation methods.
Decision Transformer for IRS-Assisted Systems with Diffusion-Driven Generative Channels
Jun 28, 2024


In this paper, we propose a novel diffusion-decision transformer (D2T) architecture to optimize the beamforming strategies for intelligent reflecting surface (IRS)-assisted multiple-input single-output (MISO) communication systems. The first challenge lies in the expensive computation cost to recover the real-time channel state information (CSI) from the received pilot signals, which usually requires prior knowledge of the channel distributions. To reduce the channel estimation complexity, we adopt a diffusion model to automatically learn the mapping between the received pilot signals and channel matrices in a model-free manner. The second challenge is that, the traditional optimization or reinforcement learning (RL) algorithms cannot guarantee the optimality of the beamforming policies once the channel distribution changes, and it is costly to resolve the optimized strategies. To enhance the generality of the decision models over varying channel distributions, we propose an offline pre-training and online fine-tuning decision transformer (DT) framework, wherein we first pre-train the DT offline with the data samples collected by the RL algorithms under diverse channel distributions, and then fine-tune the DT online with few-shot samples under a new channel distribution for a generalization purpose. Simulation results demonstrate that, compared with retraining RL algorithms, the proposed D2T algorithm boosts the convergence speed by 3 times with only a few samples from the new channel distribution while enhancing the average user data rate by 6%.
Deep Imbalanced Regression to Estimate Vascular Age from PPG Data: a Novel Digital Biomarker for Cardiovascular Health
Jun 21, 2024



Photoplethysmography (PPG) is emerging as a crucial tool for monitoring human hemodynamics, with recent studies highlighting its potential in assessing vascular aging through deep learning. However, real-world age distributions are often imbalanced, posing significant challenges for deep learning models. In this paper, we introduce a novel, simple, and effective loss function named the Dist Loss to address deep imbalanced regression tasks. We trained a one-dimensional convolutional neural network (Net1D) incorporating the Dist Loss on the extensive UK Biobank dataset (n=502,389) to estimate vascular age from PPG signals and validate its efficacy in characterizing cardiovascular health. The model's performance was validated on a 40% held-out test set, achieving state-of-the-art results, especially in regions with small sample sizes. Furthermore, we divided the population into three subgroups based on the difference between predicted vascular age and chronological age: less than -10 years, between -10 and 10 years, and greater than 10 years. We analyzed the relationship between predicted vascular age and several cardiovascular events over a follow-up period of up to 10 years, including death, coronary heart disease, and heart failure. Our results indicate that the predicted vascular age has significant potential to reflect an individual's cardiovascular health status. Our code will be available at https://github.com/Ngk03/AI-vascular-age.
Utilizing Navigation Path to Generate Target Point for Enhanced End-to-End Autonomous Driving Planning
Jun 12, 2024In recent years, end-to-end autonomous driving frameworks have been shown to not only enhance perception performance but also improve planning capabilities. However, most previous end-to-end autonomous driving frameworks have primarily focused on enhancing environment perception while neglecting the learning of autonomous vehicle planning intent. Within the end-to-end framework, this paper proposes a method termed NTT, which obtains explicit planning intent through the navigation path. NTT first generates the future target point for the autonomous vehicle based on the navigation path, thereby enhancing planning performance within the end-to-end framework. On one hand, the generation of the target point allows the autonomous vehicle to learn explicit intention from the navigation path, enhancing the practicality of planning. On the other hand, planning trajectory generated based on the target point can adapt more flexibly to environmental changes, thus effectively improving planning safety. We achieved excellent planning performance on the widely used nuScenes dataset and validated the effectiveness of our method through ablation experiments.
Ultrasound Report Generation with Cross-Modality Feature Alignment via Unsupervised Guidance
Jun 02, 2024Automatic report generation has arisen as a significant research area in computer-aided diagnosis, aiming to alleviate the burden on clinicians by generating reports automatically based on medical images. In this work, we propose a novel framework for automatic ultrasound report generation, leveraging a combination of unsupervised and supervised learning methods to aid the report generation process. Our framework incorporates unsupervised learning methods to extract potential knowledge from ultrasound text reports, serving as the prior information to guide the model in aligning visual and textual features, thereby addressing the challenge of feature discrepancy. Additionally, we design a global semantic comparison mechanism to enhance the performance of generating more comprehensive and accurate medical reports. To enable the implementation of ultrasound report generation, we constructed three large-scale ultrasound image-text datasets from different organs for training and validation purposes. Extensive evaluations with other state-of-the-art approaches exhibit its superior performance across all three datasets. Code and dataset are valuable at this link.