 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
Sep 25, 2017


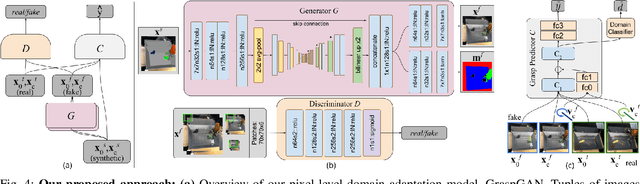
Instrumenting and collecting annotated visual grasping datasets to train modern machine learning algorithms can be extremely time-consuming and expensive. An appealing alternative is to use off-the-shelf simulators to render synthetic data for which ground-truth annotations are generated automatically. Unfortunately, models trained purely on simulated data often fail to generalize to the real world. We study how randomized simulated environments and domain adaptation methods can be extended to train a grasping system to grasp novel objects from raw monocular RGB images. We extensively evaluate our approaches with a total of more than 25,000 physical test grasps, studying a range of simulation conditions and domain adaptation methods, including a novel extension of pixel-level domain adaptation that we term the GraspGAN. We show that, by using synthetic data and domain adaptation, we are able to reduce the number of real-world samples needed to achieve a given level of performance by up to 50 times, using only randomly generated simulated objects. We also show that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with 939,777 labeled real-world samples.
Attention-based Extraction of Structured Information from Street View Imagery
Aug 20, 2017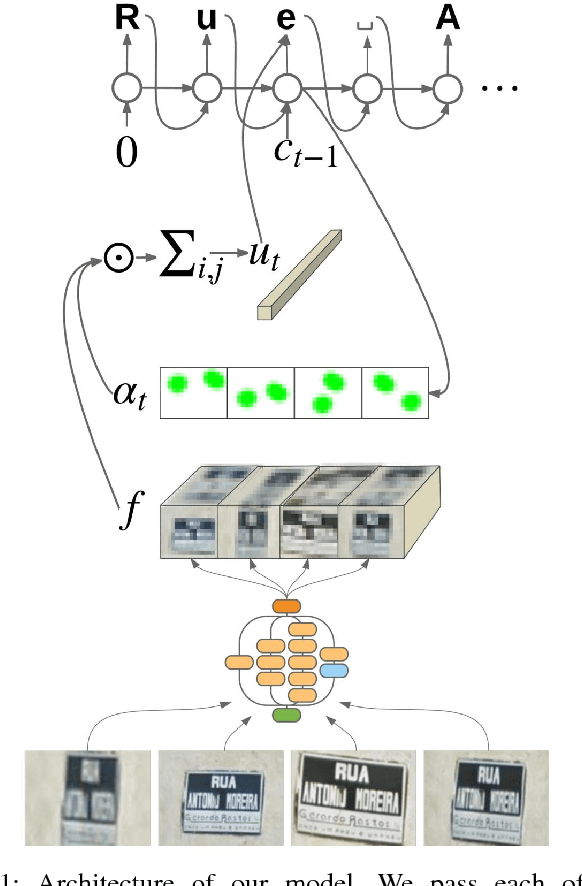
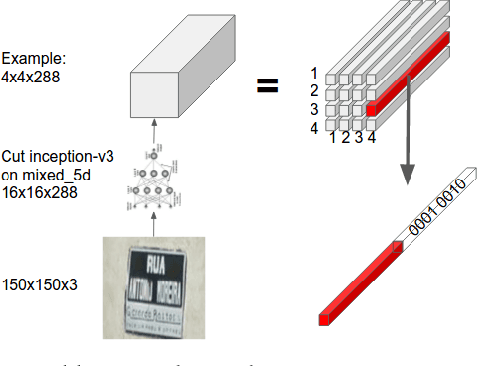


We present a neural network model - based on CNNs, RNNs and a novel attention mechanism - which achieves 84.2% accuracy on the challenging French Street Name Signs (FSNS) dataset, significantly outperforming the previous state of the art (Smith'16), which achieved 72.46%. Furthermore, our new method is much simpler and more general than the previous approach. To demonstrate the generality of our model, we show that it also performs well on an even more challenging dataset derived from Google Street View, in which the goal is to extract business names from store fronts. Finally, we study the speed/accuracy tradeoff that results from using CNN feature extractors of different depths. Surprisingly, we find that deeper is not always better (in terms of accuracy, as well as speed). Our resulting model is simple, accurate and fast, allowing it to be used at scale on a variety of challenging real-world text extraction problems.
End-to-End Interpretation of the French Street Name Signs Dataset
Feb 13, 2017


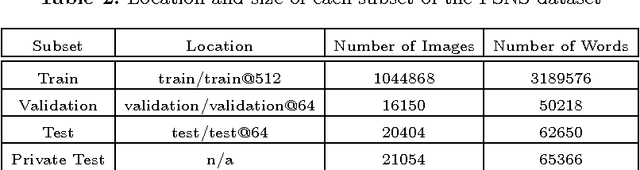
We introduce the French Street Name Signs (FSNS) Dataset consisting of more than a million images of street name signs cropped from Google Street View images of France. Each image contains several views of the same street name sign. Every image has normalized, title case folded ground-truth text as it would appear on a map. We believe that the FSNS dataset is large and complex enough to train a deep network of significant complexity to solve the street name extraction problem "end-to-end" or to explore the design trade-offs between a single complex engineered network and multiple sub-networks designed and trained to solve sub-problems. We present such an "end-to-end" network/graph for Tensor Flow and its results on the FSNS dataset.
* Presented at the IWRR workshop at ECCV 2016
Large Scale Business Discovery from Street Level Imagery
Feb 02, 2016
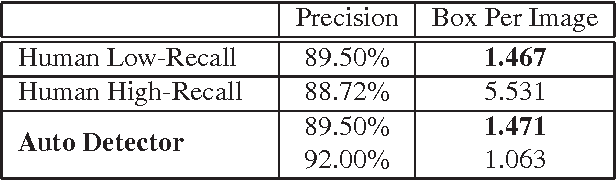

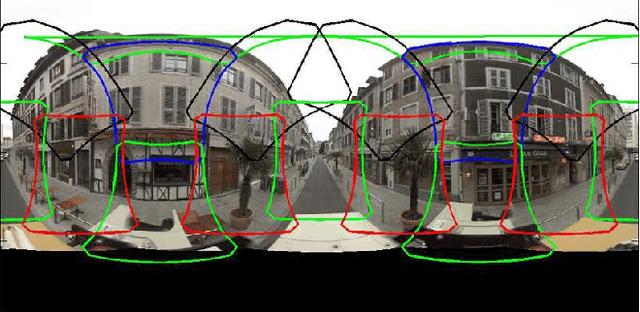
Search with local intent is becoming increasingly useful due to the popularity of the mobile device. The creation and maintenance of accurate listings of local businesses worldwide is time consuming and expensive. In this paper, we propose an approach to automatically discover businesses that are visible on street level imagery. Precise business store front detection enables accurate geo-location of businesses, and further provides input for business categorization, listing generation, etc. The large variety of business categories in different countries makes this a very challenging problem. Moreover, manual annotation is prohibitive due to the scale of this problem. We propose the use of a MultiBox based approach that takes input image pixels and directly outputs store front bounding boxes. This end-to-end learning approach instead preempts the need for hand modeling either the proposal generation phase or the post-processing phase, leveraging large labelled training datasets. We demonstrate our approach outperforms the state of the art detection techniques with a large margin in terms of performance and run-time efficiency. In the evaluation, we show this approach achieves human accuracy in the low-recall settings. We also provide an end-to-end evaluation of business discovery in the real world.
Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
Apr 14, 2014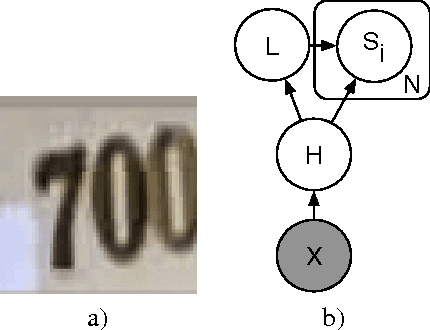


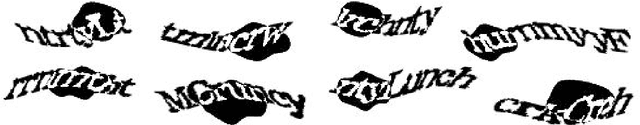
Recognizing arbitrary multi-character text in unconstrained natural photographs is a hard problem. In this paper, we address an equally hard sub-problem in this domain viz. recognizing arbitrary multi-digit numbers from Street View imagery. Traditional approaches to solve this problem typically separate out the localization, segmentation, and recognition steps. In this paper we propose a unified approach that integrates these three steps via the use of a deep convolutional neural network that operates directly on the image pixels. We employ the DistBelief implementation of deep neural networks in order to train large, distributed neural networks on high quality images. We find that the performance of this approach increases with the depth of the convolutional network, with the best performance occurring in the deepest architecture we trained, with eleven hidden layers. We evaluate this approach on the publicly available SVHN dataset and achieve over $96\%$ accuracy in recognizing complete street numbers. We show that on a per-digit recognition task, we improve upon the state-of-the-art, achieving $97.84\%$ accuracy. We also evaluate this approach on an even more challenging dataset generated from Street View imagery containing several tens of millions of street number annotations and achieve over $90\%$ accuracy. To further explore the applicability of the proposed system to broader text recognition tasks, we apply it to synthetic distorted text from reCAPTCHA. reCAPTCHA is one of the most secure reverse turing tests that uses distorted text to distinguish humans from bots. We report a $99.8\%$ accuracy on the hardest category of reCAPTCHA. Our evaluations on both tasks indicate that at specific operating thresholds, the performance of the proposed system is comparable to, and in some cases exceeds, that of human operators.