 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniIF: Unified Molecule Inverse Folding
May 29, 2024



Molecule inverse folding has been a long-standing challenge in chemistry and biology, with the potential to revolutionize drug discovery and material science. Despite specified models have been proposed for different small- or macro-molecules, few have attempted to unify the learning process, resulting in redundant efforts. Complementary to recent advancements in molecular structure prediction, such as RoseTTAFold All-Atom and AlphaFold3, we propose the unified model UniIF for the inverse folding of all molecules. We do such unification in two levels: 1) Data-Level: We propose a unified block graph data form for all molecules, including the local frame building and geometric feature initialization. 2) Model-Level: We introduce a geometric block attention network, comprising a geometric interaction, interactive attention and virtual long-term dependency modules, to capture the 3D interactions of all molecules. Through comprehensive evaluations across various tasks such as protein design, RNA design, and material design, we demonstrate that our proposed method surpasses state-of-the-art methods on all tasks. UniIF offers a versatile and effective solution for general molecule inverse folding.
Invisible Gas Detection: An RGB-Thermal Cross Attention Network and A New Benchmark
Mar 26, 2024



The widespread use of various chemical gases in industrial processes necessitates effective measures to prevent their leakage during transportation and storage, given their high toxicity. Thermal infrared-based computer vision detection techniques provide a straightforward approach to identify gas leakage areas. However, the development of high-quality algorithms has been challenging due to the low texture in thermal images and the lack of open-source datasets. In this paper, we present the RGB-Thermal Cross Attention Network (RT-CAN), which employs an RGB-assisted two-stream network architecture to integrate texture information from RGB images and gas area information from thermal images. Additionally, to facilitate the research of invisible gas detection, we introduce Gas-DB, an extensive open-source gas detection database including about 1.3K well-annotated RGB-thermal images with eight variant collection scenes. Experimental results demonstrate that our method successfully leverages the advantages of both modalities, achieving state-of-the-art (SOTA) performance among RGB-thermal methods, surpassing single-stream SOTA models in terms of accuracy, Intersection of Union (IoU), and F2 metrics by 4.86%, 5.65%, and 4.88%, respectively. The code and data will be made available soon.
Harnessing Deep Learning of Point Clouds for Inverse Control of 3D Shape Morphing
Jan 26, 2024



Shape-morphing devices, a crucial branch in soft robotics, hold significant application value in areas like human-machine interfaces, biomimetic robotics, and tools for interacting with biological systems. To achieve three-dimensional (3D) programmable shape morphing (PSM), the deployment of array-based actuators is essential. However, a critical knowledge gap impeding the development of 3D PSM is the challenge of controlling the complex systems formed by these soft actuator arrays. This study introduces a novel approach, for the first time, representing the configuration of shape morphing devices using point cloud data and employing deep learning to map these configurations to control inputs. We propose Shape Morphing Net (SMNet), a method that realizes the regression from point cloud data to high-dimensional continuous vectors. Applied to previous 2D PSM actuator arrays, SMNet significantly enhances control precision from 82.23% to 97.68%. Further, we extend its application to 3D PSM devices with three different actuator mechanisms, demonstrating the universal applicability of SMNet to the control of 3D shape morphing technologies. In our demonstrations, we confirm the efficacy of inverse control, where 3D PSM devices successfully replicate target shapes. These shapes are obtained either through 3D scanning of physical objects or via 3D modeling software. The results show that within the deformable range of 3D PSM devices, accurate reproduction of the desired shapes is achievable. The findings of this research represent a substantial advancement in soft robotics, particularly for applications demanding intricate 3D shape transformations, and establish a foundational framework for future developments in the field.
MapChange: Enhancing Semantic Change Detection with Temporal-Invariant Historical Maps Based on Deep Triplet Network
Jan 21, 2024



Semantic Change Detection (SCD) is recognized as both a crucial and challenging task in the field of image analysis. Traditional methods for SCD have predominantly relied on the comparison of image pairs. However, this approach is significantly hindered by substantial imaging differences, which arise due to variations in shooting times, atmospheric conditions, and angles. Such discrepancies lead to two primary issues: the under-detection of minor yet significant changes, and the generation of false alarms due to temporal variances. These factors often result in unchanged objects appearing markedly different in multi-temporal images. In response to these challenges, the MapChange framework has been developed. This framework introduces a novel paradigm that synergizes temporal-invariant historical map data with contemporary high-resolution images. By employing this combination, the temporal variance inherent in conventional image pair comparisons is effectively mitigated. The efficacy of the MapChange framework has been empirically validated through comprehensive testing on two public datasets. These tests have demonstrated the framework's marked superiority over existing state-of-the-art SCD methods.
Fluid Antenna-Assisted MIMO Transmission Exploiting Statistical CSI
Dec 13, 2023


In conventional multiple-input multiple-output (MIMO) communication systems, the positions of antennas are fixed. To take full advantage of spatial degrees of freedom, a new technology called fluid antenna (FA) is proposed to obtain higher achievable rate and diversity gain. Most existing works on FA exploit instantaneous channel state information (CSI). However, in FA-assisted systems, it is difficult to obtain instantaneous CSI since changes in the antenna position will lead to channel variation. In this letter, we investigate a FA-assisted MIMO system using relatively slow-varying statistical CSI. Specifically, in the criterion of rate maximization, we propose an algorithmic framework for transmit precoding and transmit/receive FAs position designs with statistical CSI. Simulation results show that our proposed algorithm in FA-assisted systems significantly outperforms baselines in terms of rate performance.
Infinite forecast combinations based on Dirichlet process
Nov 24, 2023Forecast combination integrates information from various sources by consolidating multiple forecast results from the target time series. Instead of the need to select a single optimal forecasting model, this paper introduces a deep learning ensemble forecasting model based on the Dirichlet process. Initially, the learning rate is sampled with three basis distributions as hyperparameters to convert the infinite mixture into a finite one. All checkpoints are collected to establish a deep learning sub-model pool, and weight adjustment and diversity strategies are developed during the combination process. The main advantage of this method is its ability to generate the required base learners through a single training process, utilizing the decaying strategy to tackle the challenge posed by the stochastic nature of gradient descent in determining the optimal learning rate. To ensure the method's generalizability and competitiveness, this paper conducts an empirical analysis using the weekly dataset from the M4 competition and explores sensitivity to the number of models to be combined. The results demonstrate that the ensemble model proposed offers substantial improvements in prediction accuracy and stability compared to a single benchmark model.
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
Oct 26, 2023



Large language models (LLMs) with hundreds of billions of parameters have sparked a new wave of exciting AI applications. However, they are computationally expensive at inference time. Sparsity is a natural approach to reduce this cost, but existing methods either require costly retraining, have to forgo LLM's in-context learning ability, or do not yield wall-clock time speedup on modern hardware. We hypothesize that contextual sparsity, which are small, input-dependent sets of attention heads and MLP parameters that yield approximately the same output as the dense model for a given input, can address these issues. We show that contextual sparsity exists, that it can be accurately predicted, and that we can exploit it to speed up LLM inference in wall-clock time without compromising LLM's quality or in-context learning ability. Based on these insights, we propose DejaVu, a system that uses a low-cost algorithm to predict contextual sparsity on the fly given inputs to each layer, along with an asynchronous and hardware-aware implementation that speeds up LLM inference. We validate that DejaVu can reduce the inference latency of OPT-175B by over 2X compared to the state-of-the-art FasterTransformer, and over 6X compared to the widely used Hugging Face implementation, without compromising model quality. The code is available at https://github.com/FMInference/DejaVu.
E4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023



This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.
Minimalist and High-Performance Semantic Segmentation with Plain Vision Transformers
Oct 19, 2023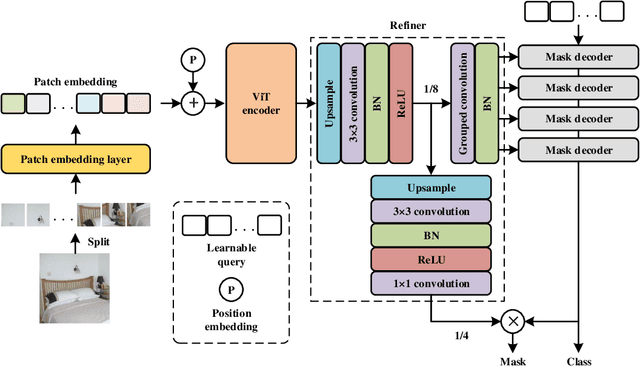

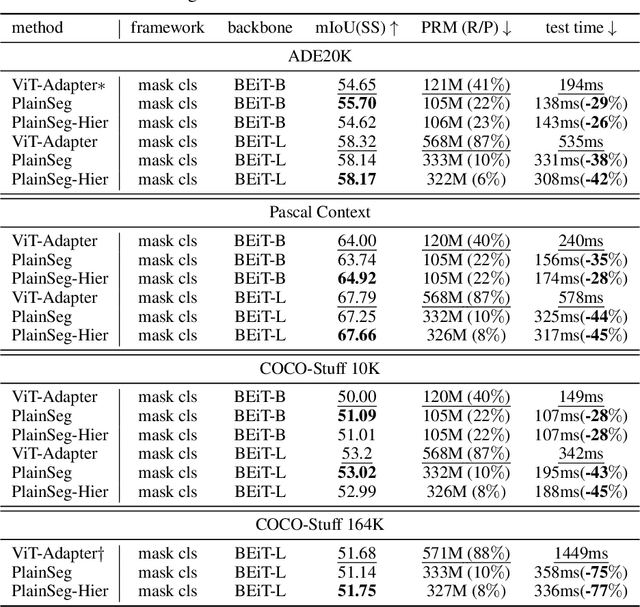
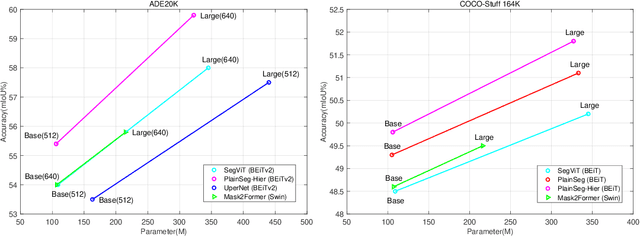
In the wake of Masked Image Modeling (MIM), a diverse range of plain, non-hierarchical Vision Transformer (ViT) models have been pre-trained with extensive datasets, offering new paradigms and significant potential for semantic segmentation. Current state-of-the-art systems incorporate numerous inductive biases and employ cumbersome decoders. Building upon the original motivations of plain ViTs, which are simplicity and generality, we explore high-performance `minimalist' systems to this end. Our primary purpose is to provide simple and efficient baselines for practical semantic segmentation with plain ViTs. Specifically, we first explore the feasibility and methodology for achieving high-performance semantic segmentation using the last feature map. As a result, we introduce the PlainSeg, a model comprising only three 3$\times$3 convolutions in addition to the transformer layers (either encoder or decoder). In this process, we offer insights into two underlying principles: (i) high-resolution features are crucial to high performance in spite of employing simple up-sampling techniques and (ii) the slim transformer decoder requires a much larger learning rate than the wide transformer decoder. On this basis, we further present the PlainSeg-Hier, which allows for the utilization of hierarchical features. Extensive experiments on four popular benchmarks demonstrate the high performance and efficiency of our methods. They can also serve as powerful tools for assessing the transfer ability of base models in semantic segmentation. Code is available at \url{https://github.com/ydhongHIT/PlainSeg}.
Revisiting the Temporal Modeling in Spatio-Temporal Predictive Learning under A Unified View
Oct 09, 2023Spatio-temporal predictive learning plays a crucial role in self-supervised learning, with wide-ranging applications across a diverse range of fields. Previous approaches for temporal modeling fall into two categories: recurrent-based and recurrent-free methods. The former, while meticulously processing frames one by one, neglect short-term spatio-temporal information redundancies, leading to inefficiencies. The latter naively stack frames sequentially, overlooking the inherent temporal dependencies. In this paper, we re-examine the two dominant temporal modeling approaches within the realm of spatio-temporal predictive learning, offering a unified perspective. Building upon this analysis, we introduce USTEP (Unified Spatio-TEmporal Predictive learning), an innovative framework that reconciles the recurrent-based and recurrent-free methods by integrating both micro-temporal and macro-temporal scales. Extensive experiments on a wide range of spatio-temporal predictive learning demonstrate that USTEP achieves significant improvements over existing temporal modeling approaches, thereby establishing it as a robust solution for a wide range of spatio-temporal applications.