 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
Window Attention is Bugged: How not to Interpolate Position Embeddings
Nov 09, 2023



Window attention, position embeddings, and high resolution finetuning are core concepts in the modern transformer era of computer vision. However, we find that naively combining these near ubiquitous components can have a detrimental effect on performance. The issue is simple: interpolating position embeddings while using window attention is wrong. We study two state-of-the-art methods that have these three components, namely Hiera and ViTDet, and find that both do indeed suffer from this bug. To fix it, we introduce a simple absolute window position embedding strategy, which solves the bug outright in Hiera and allows us to increase both speed and performance of the model in ViTDet. We finally combine the two to obtain HieraDet, which achieves 61.7 box mAP on COCO, making it state-of-the-art for models that only use ImageNet-1k pretraining. This all stems from what is essentially a 3 line bug fix, which we name "absolute win".
FACTS: First Amplify Correlations and Then Slice to Discover Bias
Sep 29, 2023



Computer vision datasets frequently contain spurious correlations between task-relevant labels and (easy to learn) latent task-irrelevant attributes (e.g. context). Models trained on such datasets learn "shortcuts" and underperform on bias-conflicting slices of data where the correlation does not hold. In this work, we study the problem of identifying such slices to inform downstream bias mitigation strategies. We propose First Amplify Correlations and Then Slice to Discover Bias (FACTS), wherein we first amplify correlations to fit a simple bias-aligned hypothesis via strongly regularized empirical risk minimization. Next, we perform correlation-aware slicing via mixture modeling in bias-aligned feature space to discover underperforming data slices that capture distinct correlations. Despite its simplicity, our method considerably improves over prior work (by as much as 35% precision@10) in correlation bias identification across a range of diverse evaluation settings. Our code is available at: https://github.com/yvsriram/FACTS.
Memory in Plain Sight: A Survey of the Uncanny Resemblances between Diffusion Models and Associative Memories
Sep 28, 2023


Diffusion Models (DMs) have recently set state-of-the-art on many generation benchmarks. However, there are myriad ways to describe them mathematically, which makes it difficult to develop a simple understanding of how they work. In this survey, we provide a concise overview of DMs from the perspective of dynamical systems and Ordinary Differential Equations (ODEs) which exposes a mathematical connection to the highly related yet often overlooked class of energy-based models, called Associative Memories (AMs). Energy-based AMs are a theoretical framework that behave much like denoising DMs, but they enable us to directly compute a Lyapunov energy function on which we can perform gradient descent to denoise data. We then summarize the 40 year history of energy-based AMs, beginning with the original Hopfield Network, and discuss new research directions for AMs and DMs that are revealed by characterizing the extent of their similarities and differences
ICON$^2$: Reliably Benchmarking Predictive Inequity in Object Detection
Jun 07, 2023



As computer vision systems are being increasingly deployed at scale in high-stakes applications like autonomous driving, concerns about social bias in these systems are rising. Analysis of fairness in real-world vision systems, such as object detection in driving scenes, has been limited to observing predictive inequity across attributes such as pedestrian skin tone, and lacks a consistent methodology to disentangle the role of confounding variables e.g. does my model perform worse for a certain skin tone, or are such scenes in my dataset more challenging due to occlusion and crowds? In this work, we introduce ICON$^2$, a framework for robustly answering this question. ICON$^2$ leverages prior knowledge on the deficiencies of object detection systems to identify performance discrepancies across sub-populations, compute correlations between these potential confounders and a given sensitive attribute, and control for the most likely confounders to obtain a more reliable estimate of model bias. Using our approach, we conduct an in-depth study on the performance of object detection with respect to income from the BDD100K driving dataset, revealing useful insights.
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Jun 01, 2023



Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pretraining with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchical vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebookresearch/hiera.
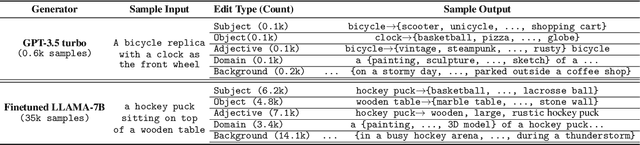
LANCE: Stress-testing Visual Models by Generating Language-guided Counterfactual Images
May 30, 2023
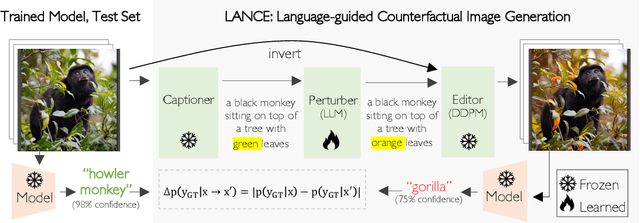

We propose an automated algorithm to stress-test a trained visual model by generating language-guided counterfactual test images (LANCE). Our method leverages recent progress in large language modeling and text-based image editing to augment an IID test set with a suite of diverse, realistic, and challenging test images without altering model weights. We benchmark the performance of a diverse set of pretrained models on our generated data and observe significant and consistent performance drops. We further analyze model sensitivity across different types of edits, and demonstrate its applicability at surfacing previously unknown class-level model biases in ImageNet.
ZipIt! Merging Models from Different Tasks without Training
May 04, 2023Typical deep visual recognition models are capable of performing the one task they were trained on. In this paper, we tackle the extremely difficult problem of combining completely distinct models with different initializations, each solving a separate task, into one multi-task model without any additional training. Prior work in model merging permutes one model to the space of the other then adds them together. While this works for models trained on the same task, we find that this fails to account for the differences in models trained on disjoint tasks. Thus, we introduce "ZipIt!", a general method for merging two arbitrary models of the same architecture that incorporates two simple strategies. First, in order to account for features that aren't shared between models, we expand the model merging problem to additionally allow for merging features within each model by defining a general "zip" operation. Second, we add support for partially zipping the models up until a specified layer, naturally creating a multi-head model. We find that these two changes combined account for a staggering 20-60% improvement over prior work, making the merging of models trained on disjoint tasks feasible.
Benchmarking Low-Shot Robustness to Natural Distribution Shifts
Apr 21, 2023



Robustness to natural distribution shifts has seen remarkable progress thanks to recent pre-training strategies combined with better fine-tuning methods. However, such fine-tuning assumes access to large amounts of labelled data, and the extent to which the observations hold when the amount of training data is not as high remains unknown. We address this gap by performing the first in-depth study of robustness to various natural distribution shifts in different low-shot regimes: spanning datasets, architectures, pre-trained initializations, and state-of-the-art robustness interventions. Most importantly, we find that there is no single model of choice that is often more robust than others, and existing interventions can fail to improve robustness on some datasets even if they do so in the full-shot regime. We hope that our work will motivate the community to focus on this problem of practical importance.