 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Interference (RI): Disentangling Models for Improved Model Merging
Mar 13, 2026Model merging has shown that multitask models can be created by directly combining the parameters of different models that are each specialized on tasks of interest. However, models trained independently on distinct tasks often exhibit interference that degrades the merged model's performance. To solve this problem, we formally define the notion of Cross-Task Interference as the drift in the representation of the merged model relative to its constituent models. Reducing cross-task interference is key to improving merging performance. To address this issue, we propose our method, Resolving Interference (RI), a light-weight adaptation framework which disentangles expert models to be functionally orthogonal to the space of other tasks, thereby reducing cross-task interference. RI does this whilst using only unlabeled auxiliary data as input (i.e., no task-data is needed), allowing it to be applied in data-scarce scenarios. RI consistently improves the performance of state-of-the-art merging methods by up to 3.8% and generalization to unseen domains by up to 2.3%. We also find RI to be robust to the source of auxiliary input while being significantly less sensitive to tuning of merging hyperparameters. Our codebase is available at: https://github.com/pramesh39/resolving_interference
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Dec 12, 2025



Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .
Contrastive Flow Matching
Jun 05, 2025



Unconditional flow-matching trains diffusion models to transport samples from a source distribution to a target distribution by enforcing that the flows between sample pairs are unique. However, in conditional settings (e.g., class-conditioned models), this uniqueness is no longer guaranteed--flows from different conditions may overlap, leading to more ambiguous generations. We introduce Contrastive Flow Matching, an extension to the flow matching objective that explicitly enforces uniqueness across all conditional flows, enhancing condition separation. Our approach adds a contrastive objective that maximizes dissimilarities between predicted flows from arbitrary sample pairs. We validate Contrastive Flow Matching by conducting extensive experiments across varying model architectures on both class-conditioned (ImageNet-1k) and text-to-image (CC3M) benchmarks. Notably, we find that training models with Contrastive Flow Matching (1) improves training speed by a factor of up to 9x, (2) requires up to 5x fewer de-noising steps and (3) lowers FID by up to 8.9 compared to training the same models with flow matching. We release our code at: https://github.com/gstoica27/DeltaFM.git.
Model merging with SVD to tie the Knots
Oct 25, 2024



Recent model merging methods demonstrate that the parameters of fully-finetuned models specializing in distinct tasks can be combined into one model capable of solving all tasks without retraining. Yet, this success does not transfer well when merging LoRA finetuned models. We study this phenomenon and observe that the weights of LoRA finetuned models showcase a lower degree of alignment compared to their fully-finetuned counterparts. We hypothesize that improving this alignment is key to obtaining better LoRA model merges, and propose KnOTS to address this problem. KnOTS uses the SVD to jointly transform the weights of different LoRA models into an aligned space, where existing merging methods can be applied. In addition, we introduce a new benchmark that explicitly evaluates whether merged models are general models. Notably, KnOTS consistently improves LoRA merging by up to 4.3% across several vision and language benchmarks, including our new setting. We release our code at: https://github.com/gstoica27/KnOTS.
Analyzing domain shift when using additional data for the MICCAI KiTS23 Challenge
Sep 05, 2023Using additional training data is known to improve the results, especially for medical image 3D segmentation where there is a lack of training material and the model needs to generalize well from few available data. However, the new data could have been acquired using other instruments and preprocessed such its distribution is significantly different from the original training data. Therefore, we study techniques which ameliorate domain shift during training so that the additional data becomes better usable for preprocessing and training together with the original data. Our results show that transforming the additional data using histogram matching has better results than using simple normalization.
ZipIt! Merging Models from Different Tasks without Training
May 04, 2023Typical deep visual recognition models are capable of performing the one task they were trained on. In this paper, we tackle the extremely difficult problem of combining completely distinct models with different initializations, each solving a separate task, into one multi-task model without any additional training. Prior work in model merging permutes one model to the space of the other then adds them together. While this works for models trained on the same task, we find that this fails to account for the differences in models trained on disjoint tasks. Thus, we introduce "ZipIt!", a general method for merging two arbitrary models of the same architecture that incorporates two simple strategies. First, in order to account for features that aren't shared between models, we expand the model merging problem to additionally allow for merging features within each model by defining a general "zip" operation. Second, we add support for partially zipping the models up until a specified layer, naturally creating a multi-head model. We find that these two changes combined account for a staggering 20-60% improvement over prior work, making the merging of models trained on disjoint tasks feasible.
Dynamic Batch Adaptation
Aug 01, 2022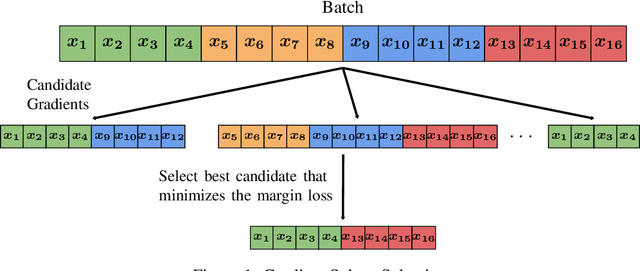
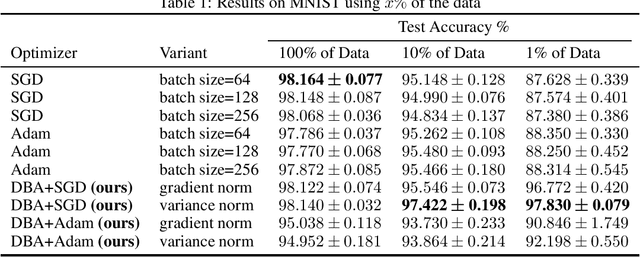
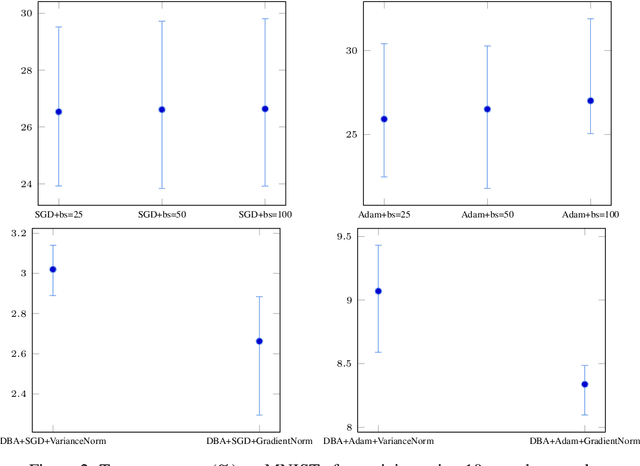
Current deep learning adaptive optimizer methods adjust the step magnitude of parameter updates by altering the effective learning rate used by each parameter. Motivated by the known inverse relation between batch size and learning rate on update step magnitudes, we introduce a novel training procedure that dynamically decides the dimension and the composition of the current update step. Our procedure, Dynamic Batch Adaptation (DBA) analyzes the gradients of every sample and selects the subset that best improves certain metrics such as gradient variance for each layer of the network. We present results showing DBA significantly improves the speed of model convergence. Additionally, we find that DBA produces an increased improvement over standard optimizers when used in data scarce conditions where, in addition to convergence speed, it also significantly improves model generalization, managing to train a network with a single fully connected hidden layer using only 1% of the MNIST dataset to reach 97.79% test accuracy. In an even more extreme scenario, it manages to reach 97.44% test accuracy using only 10 samples per class. These results represent a relative error rate reduction of 81.78% and 88.07% respectively, compared to the standard optimizers, Stochastic Gradient Descent (SGD) and Adam.
Re-TACRED: Addressing Shortcomings of the TACRED Dataset
Apr 16, 2021
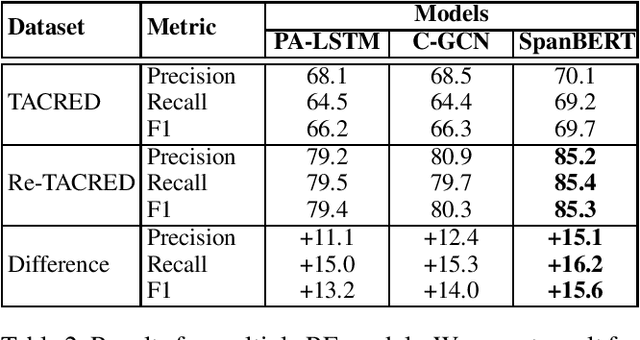
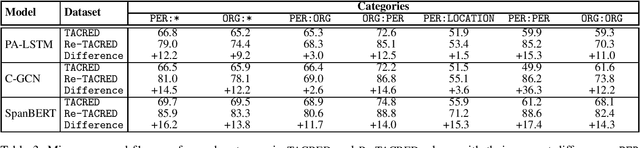
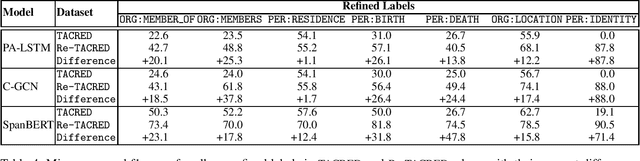
TACRED is one of the largest and most widely used sentence-level relation extraction datasets. Proposed models that are evaluated using this dataset consistently set new state-of-the-art performance. However, they still exhibit large error rates despite leveraging external knowledge and unsupervised pretraining on large text corpora. A recent study suggested that this may be due to poor dataset quality. The study observed that over 50% of the most challenging sentences from the development and test sets are incorrectly labeled and account for an average drop of 8% f1-score in model performance. However, this study was limited to a small biased sample of 5k (out of a total of 106k) sentences, substantially restricting the generalizability and broader implications of its findings. In this paper, we address these shortcomings by: (i) performing a comprehensive study over the whole TACRED dataset, (ii) proposing an improved crowdsourcing strategy and deploying it to re-annotate the whole dataset, and (iii) performing a thorough analysis to understand how correcting the TACRED annotations affects previously published results. After verification, we observed that 23.9% of TACRED labels are incorrect. Moreover, evaluating several models on our revised dataset yields an average f1-score improvement of 14.3% and helps uncover significant relationships between the different models (rather than simply offsetting or scaling their scores by a constant factor). Finally, aside from our analysis we also release Re-TACRED, a new completely re-annotated version of the TACRED dataset that can be used to perform reliable evaluation of relation extraction models.
Improving Relation Extraction by Leveraging Knowledge Graph Link Prediction
Dec 09, 2020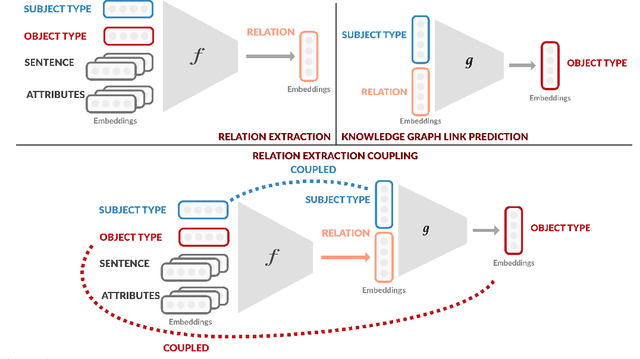



Relation extraction (RE) aims to predict a relation between a subject and an object in a sentence, while knowledge graph link prediction (KGLP) aims to predict a set of objects, O, given a subject and a relation from a knowledge graph. These two problems are closely related as their respective objectives are intertwined: given a sentence containing a subject and an object o, a RE model predicts a relation that can then be used by a KGLP model together with the subject, to predict a set of objects O. Thus, we expect object o to be in set O. In this paper, we leverage this insight by proposing a multi-task learning approach that improves the performance of RE models by jointly training on RE and KGLP tasks. We illustrate the generality of our approach by applying it on several existing RE models and empirically demonstrate how it helps them achieve consistent performance gains.