 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the "Video" in Video-Language Understanding
Jun 03, 2022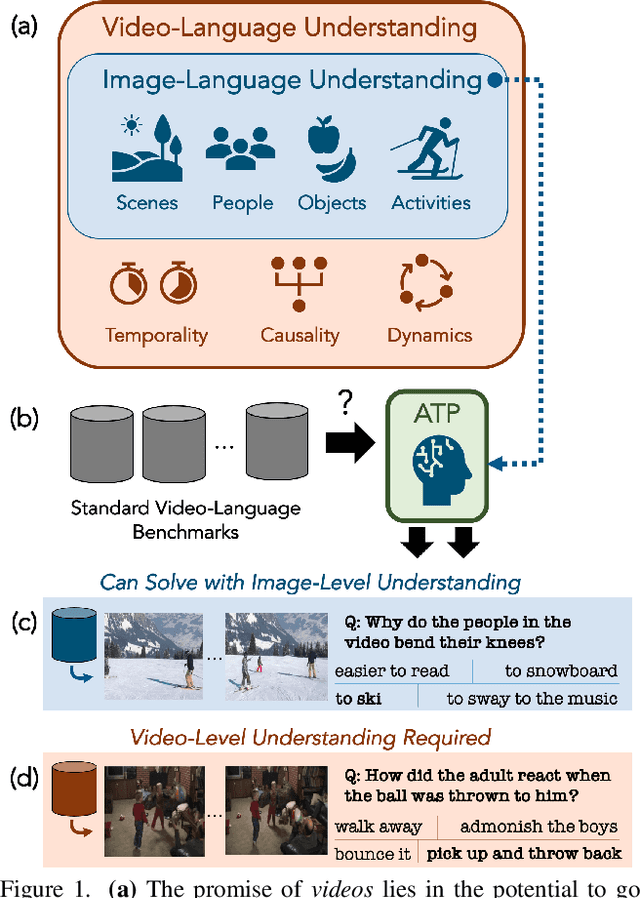


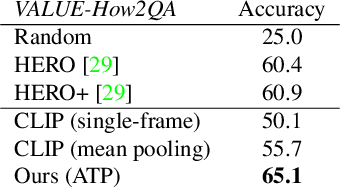
What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
The AI Index 2022 Annual Report
May 02, 2022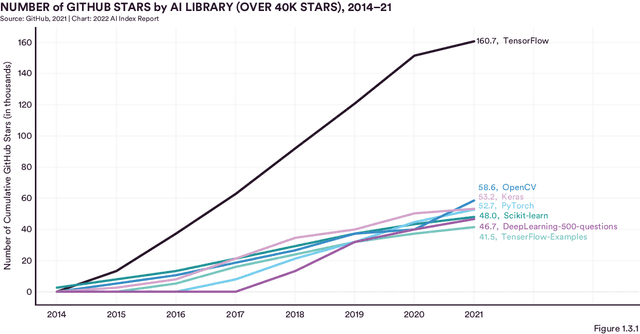
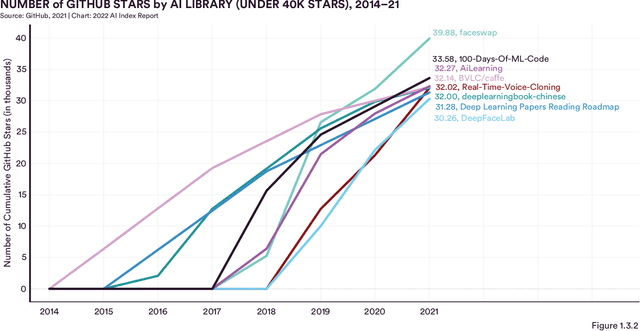
Welcome to the fifth edition of the AI Index Report! The latest edition includes data from a broad set of academic, private, and nonprofit organizations as well as more self-collected data and original analysis than any previous editions, including an expanded technical performance chapter, a new survey of robotics researchers around the world, data on global AI legislation records in 25 countries, and a new chapter with an in-depth analysis of technical AI ethics metrics. The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Its mission is to provide unbiased, rigorously vetted, and globally sourced data for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The report aims to be the world's most credible and authoritative source for data and insights about AI.
Align and Prompt: Video-and-Language Pre-training with Entity Prompts
Dec 23, 2021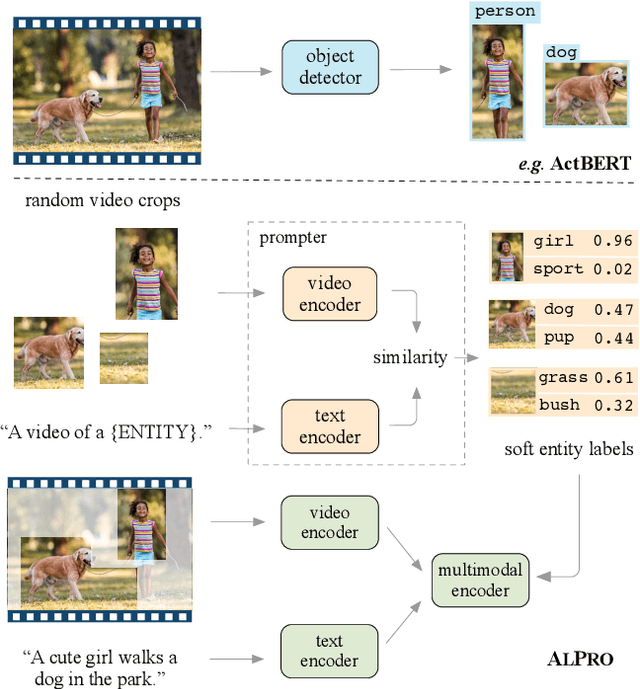
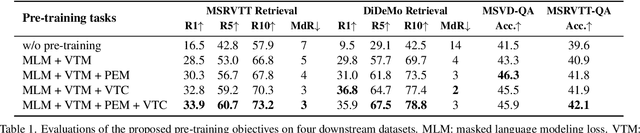
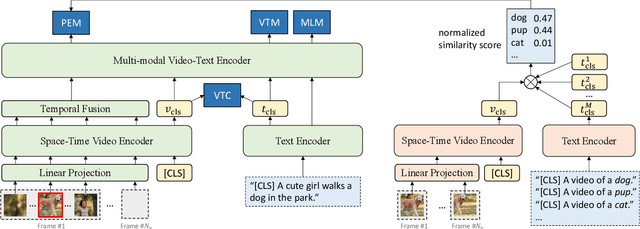
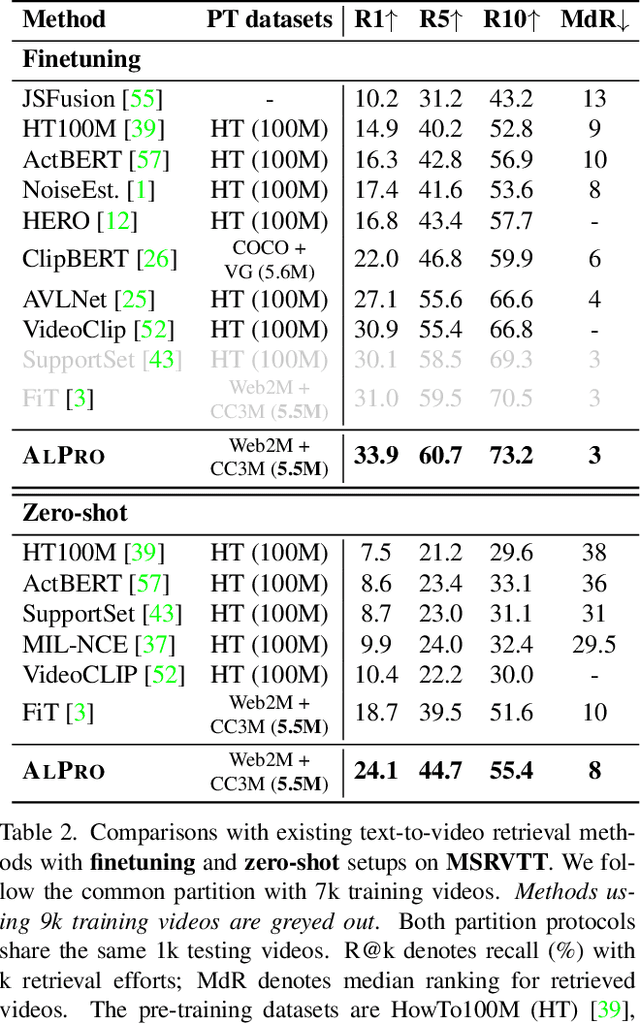
Video-and-language pre-training has shown promising improvements on various downstream tasks. Most previous methods capture cross-modal interactions with a transformer-based multimodal encoder, not fully addressing the misalignment between unimodal video and text features. Besides, learning fine-grained visual-language alignment usually requires off-the-shelf object detectors to provide object information, which is bottlenecked by the detector's limited vocabulary and expensive computation cost. We propose Align and Prompt: an efficient and effective video-and-language pre-training framework with better cross-modal alignment. First, we introduce a video-text contrastive (VTC) loss to align unimodal video-text features at the instance level, which eases the modeling of cross-modal interactions. Then, we propose a new visually-grounded pre-training task, prompting entity modeling (PEM), which aims to learn fine-grained region-entity alignment. To achieve this, we first introduce an entity prompter module, which is trained with VTC to produce the similarity between a video crop and text prompts instantiated with entity names. The PEM task then asks the model to predict the entity pseudo-labels (i.e~normalized similarity scores) for randomly-selected video crops. The resulting pre-trained model achieves state-of-the-art performance on both text-video retrieval and videoQA, outperforming prior work by a substantial margin. Our code and pre-trained models are available at https://github.com/salesforce/ALPRO.
PreViTS: Contrastive Pretraining with Video Tracking Supervision
Dec 01, 2021
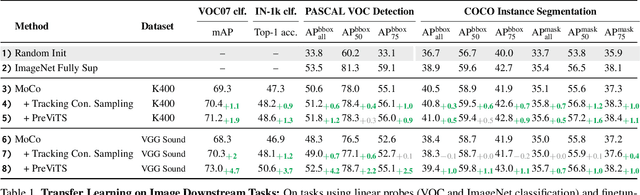
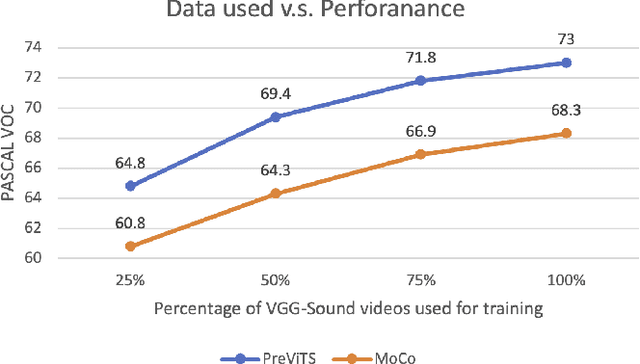
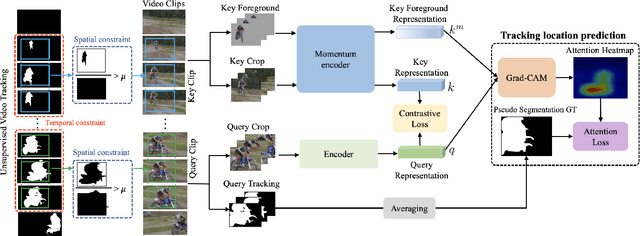
Videos are a rich source for self-supervised learning (SSL) of visual representations due to the presence of natural temporal transformations of objects. However, current methods typically randomly sample video clips for learning, which results in a poor supervisory signal. In this work, we propose PreViTS, an SSL framework that utilizes an unsupervised tracking signal for selecting clips containing the same object, which helps better utilize temporal transformations of objects. PreViTS further uses the tracking signal to spatially constrain the frame regions to learn from and trains the model to locate meaningful objects by providing supervision on Grad-CAM attention maps. To evaluate our approach, we train a momentum contrastive (MoCo) encoder on VGG-Sound and Kinetics-400 datasets with PreViTS. Training with PreViTS outperforms representations learnt by MoCo alone on both image recognition and video classification downstream tasks, obtaining state-of-the-art performance on action classification. PreViTS helps learn feature representations that are more robust to changes in background and context, as seen by experiments on image and video datasets with background changes. Learning from large-scale uncurated videos with PreViTS could lead to more accurate and robust visual feature representations.
Towards Open Vocabulary Object Detection without Human-provided Bounding Boxes
Nov 18, 2021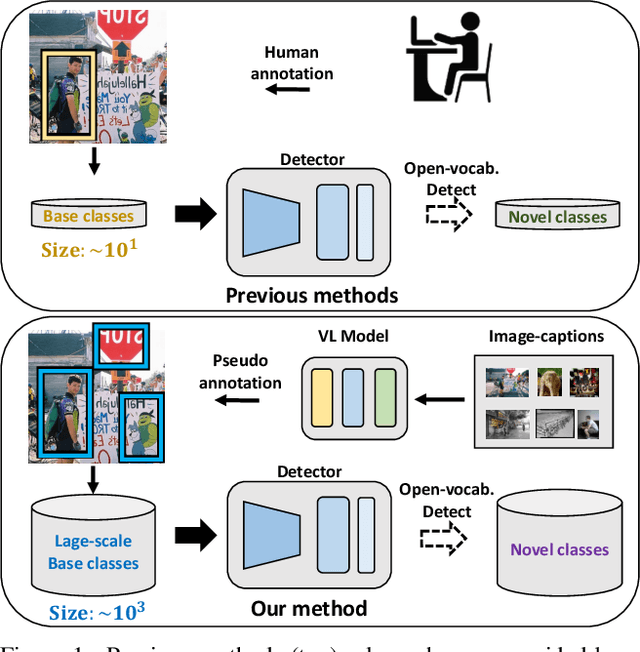
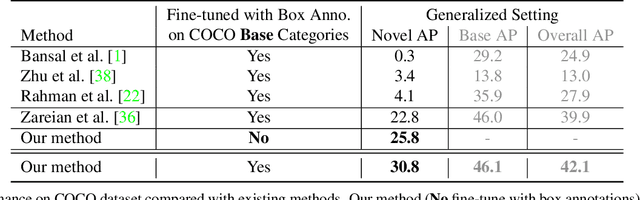
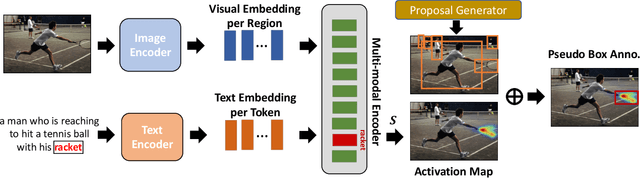
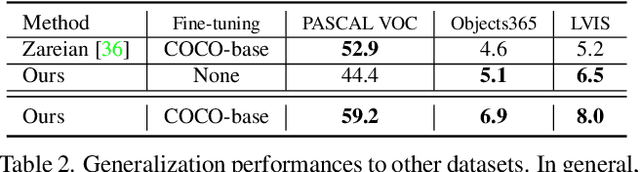
Despite great progress in object detection, most existing methods are limited to a small set of object categories, due to the tremendous human effort needed for instance-level bounding-box annotation. To alleviate the problem, recent open vocabulary and zero-shot detection methods attempt to detect object categories not seen during training. However, these approaches still rely on manually provided bounding-box annotations on a set of base classes. We propose an open vocabulary detection framework that can be trained without manually provided bounding-box annotations. Our method achieves this by leveraging the localization ability of pre-trained vision-language models and generating pseudo bounding-box labels that can be used directly for training object detectors. Experimental results on COCO, PASCAL VOC, Objects365 and LVIS demonstrate the effectiveness of our method. Specifically, our method outperforms the state-of-the-arts (SOTA) that are trained using human annotated bounding-boxes by 3% AP on COCO novel categories even though our training source is not equipped with manual bounding-box labels. When utilizing the manual bounding-box labels as our baselines do, our method surpasses the SOTA largely by 8% AP.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Jun 21, 2021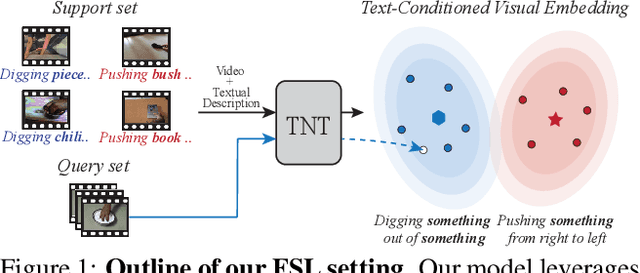
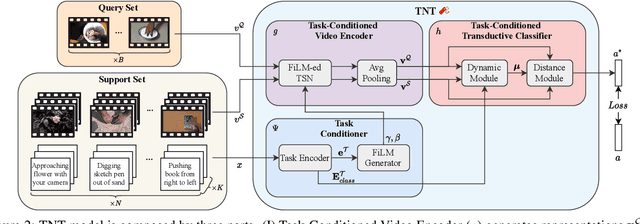
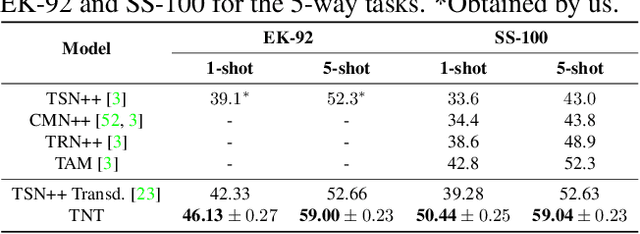
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.
Home Action Genome: Cooperative Compositional Action Understanding
May 11, 2021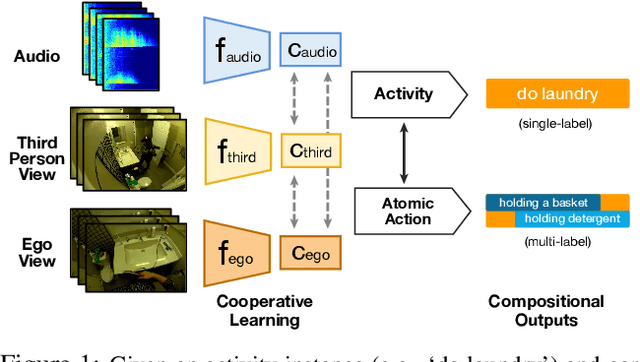
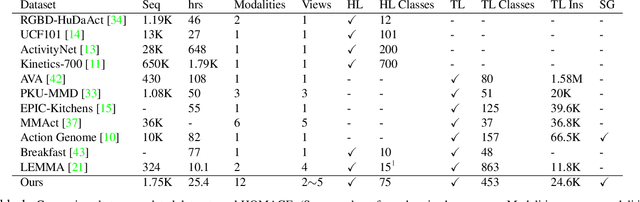

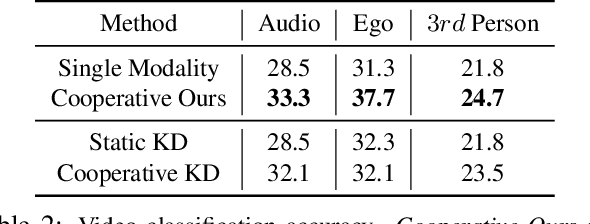
Existing research on action recognition treats activities as monolithic events occurring in videos. Recently, the benefits of formulating actions as a combination of atomic-actions have shown promise in improving action understanding with the emergence of datasets containing such annotations, allowing us to learn representations capturing this information. However, there remains a lack of studies that extend action composition and leverage multiple viewpoints and multiple modalities of data for representation learning. To promote research in this direction, we introduce Home Action Genome (HOMAGE): a multi-view action dataset with multiple modalities and view-points supplemented with hierarchical activity and atomic action labels together with dense scene composition labels. Leveraging rich multi-modal and multi-view settings, we propose Cooperative Compositional Action Understanding (CCAU), a cooperative learning framework for hierarchical action recognition that is aware of compositional action elements. CCAU shows consistent performance improvements across all modalities. Furthermore, we demonstrate the utility of co-learning compositions in few-shot action recognition by achieving 28.6% mAP with just a single sample.
Metadata Normalization
May 05, 2021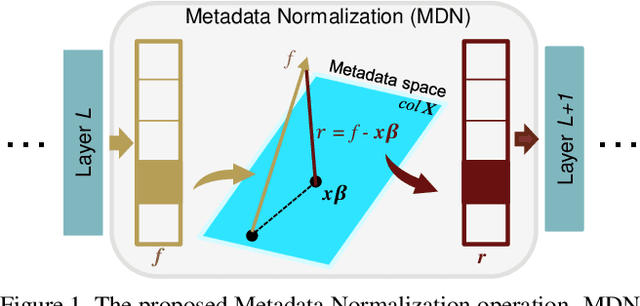
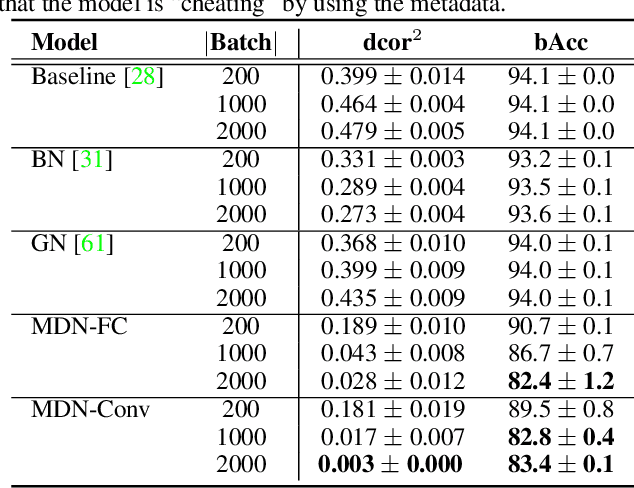

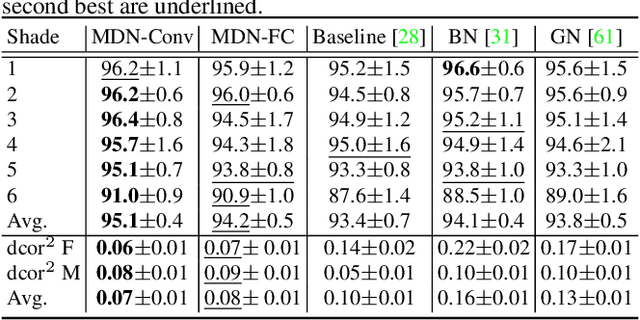
Batch Normalization (BN) and its variants have delivered tremendous success in combating the covariate shift induced by the training step of deep learning methods. While these techniques normalize feature distributions by standardizing with batch statistics, they do not correct the influence on features from extraneous variables or multiple distributions. Such extra variables, referred to as metadata here, may create bias or confounding effects (e.g., race when classifying gender from face images). We introduce the Metadata Normalization (MDN) layer, a new batch-level operation which can be used end-to-end within the training framework, to correct the influence of metadata on feature distributions. MDN adopts a regression analysis technique traditionally used for preprocessing to remove (regress out) the metadata effects on model features during training. We utilize a metric based on distance correlation to quantify the distribution bias from the metadata and demonstrate that our method successfully removes metadata effects on four diverse settings: one synthetic, one 2D image, one video, and one 3D medical image dataset.
CoCon: Cooperative-Contrastive Learning
Apr 30, 2021

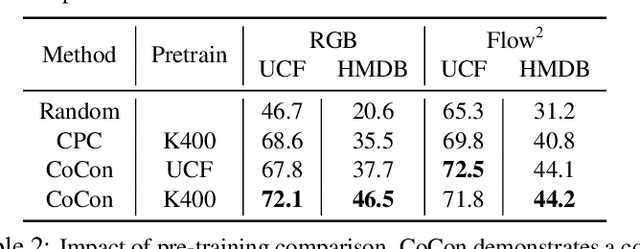
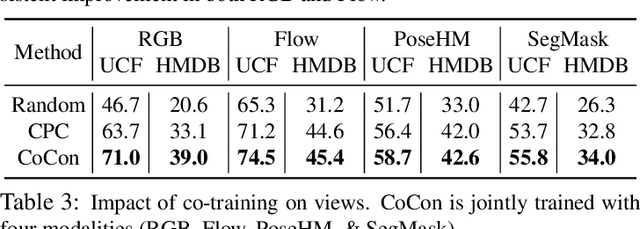
Labeling videos at scale is impractical. Consequently, self-supervised visual representation learning is key for efficient video analysis. Recent success in learning image representations suggests contrastive learning is a promising framework to tackle this challenge. However, when applied to real-world videos, contrastive learning may unknowingly lead to the separation of instances that contain semantically similar events. In our work, we introduce a cooperative variant of contrastive learning to utilize complementary information across views and address this issue. We use data-driven sampling to leverage implicit relationships between multiple input video views, whether observed (e.g. RGB) or inferred (e.g. flow, segmentation masks, poses). We are one of the firsts to explore exploiting inter-instance relationships to drive learning. We experimentally evaluate our representations on the downstream task of action recognition. Our method achieves competitive performance on standard benchmarks (UCF101, HMDB51, Kinetics400). Furthermore, qualitative experiments illustrate that our models can capture higher-order class relationships.