 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Reinforcement Learning for Optimal Design of Legged Robots
Oct 06, 2022
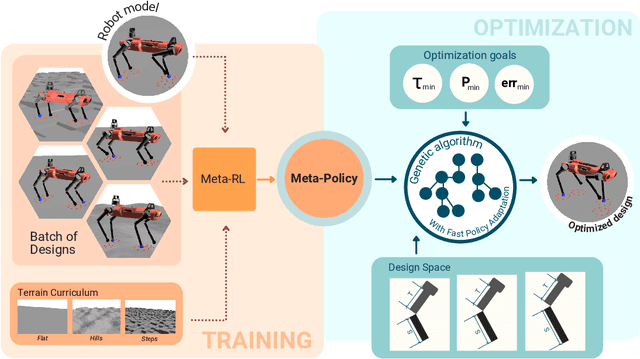
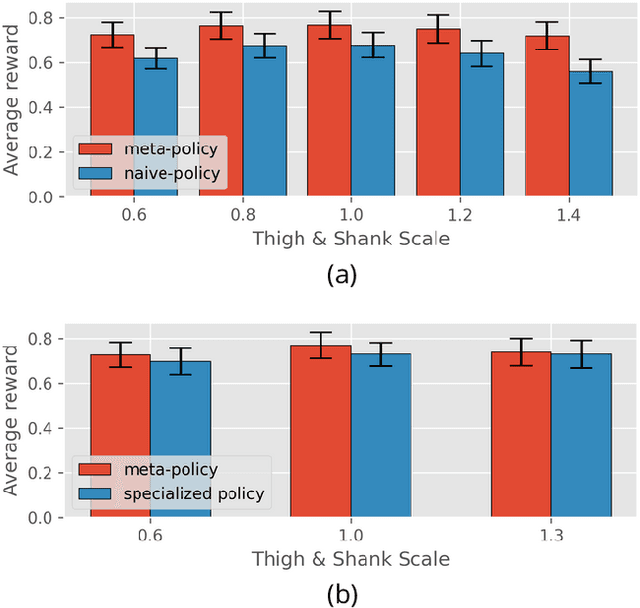

The process of robot design is a complex task and the majority of design decisions are still based on human intuition or tedious manual tuning. A more informed way of facing this task is computational design methods where design parameters are concurrently optimized with corresponding controllers. Existing approaches, however, are strongly influenced by predefined control rules or motion templates and cannot provide end-to-end solutions. In this paper, we present a design optimization framework using model-free meta reinforcement learning, and its application to the optimizing kinematics and actuator parameters of quadrupedal robots. We use meta reinforcement learning to train a locomotion policy that can quickly adapt to different designs. This policy is used to evaluate each design instance during the design optimization. We demonstrate that the policy can control robots of different designs to track random velocity commands over various rough terrains. With controlled experiments, we show that the meta policy achieves close-to-optimal performance for each design instance after adaptation. Lastly, we compare our results against a model-based baseline and show that our approach allows higher performance while not being constrained by predefined motions or gait patterns.
Advanced Skills through Multiple Adversarial Motion Priors in Reinforcement Learning
Mar 23, 2022
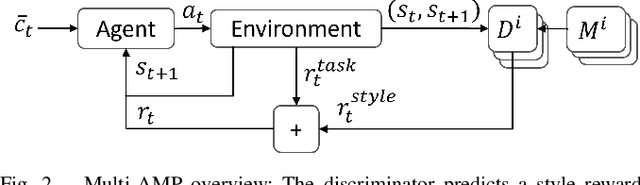


In recent years, reinforcement learning (RL) has shown outstanding performance for locomotion control of highly articulated robotic systems. Such approaches typically involve tedious reward function tuning to achieve the desired motion style. Imitation learning approaches such as adversarial motion priors aim to reduce this problem by encouraging a pre-defined motion style. In this work, we present an approach to augment the concept of adversarial motion prior-based RL to allow for multiple, discretely switchable styles. We show that multiple styles and skills can be learned simultaneously without notable performance differences, even in combination with motion data-free skills. Our approach is validated in several real-world experiments with a wheeled-legged quadruped robot showing skills learned from existing RL controllers and trajectory optimization, such as ducking and walking, and novel skills such as switching between a quadrupedal and humanoid configuration. For the latter skill, the robot is required to stand up, navigate on two wheels, and sit down. Instead of tuning the sit-down motion, we verify that a reverse playback of the stand-up movement helps the robot discover feasible sit-down behaviors and avoids tedious reward function tuning.
Learning robust perceptive locomotion for quadrupedal robots in the wild
Jan 20, 2022Legged robots that can operate autonomously in remote and hazardous environments will greatly increase opportunities for exploration into under-explored areas. Exteroceptive perception is crucial for fast and energy-efficient locomotion: perceiving the terrain before making contact with it enables planning and adaptation of the gait ahead of time to maintain speed and stability. However, utilizing exteroceptive perception robustly for locomotion has remained a grand challenge in robotics. Snow, vegetation, and water visually appear as obstacles on which the robot cannot step~-- or are missing altogether due to high reflectance. Additionally, depth perception can degrade due to difficult lighting, dust, fog, reflective or transparent surfaces, sensor occlusion, and more. For this reason, the most robust and general solutions to legged locomotion to date rely solely on proprioception. This severely limits locomotion speed, because the robot has to physically feel out the terrain before adapting its gait accordingly. Here we present a robust and general solution to integrating exteroceptive and proprioceptive perception for legged locomotion. We leverage an attention-based recurrent encoder that integrates proprioceptive and exteroceptive input. The encoder is trained end-to-end and learns to seamlessly combine the different perception modalities without resorting to heuristics. The result is a legged locomotion controller with high robustness and speed. The controller was tested in a variety of challenging natural and urban environments over multiple seasons and completed an hour-long hike in the Alps in the time recommended for human hikers.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

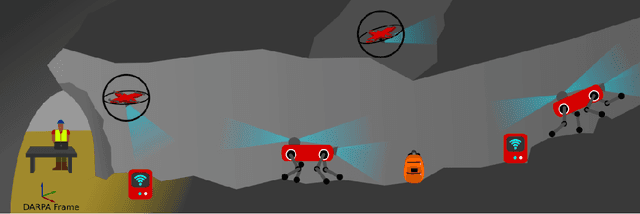

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Combining Learning-based Locomotion Policy with Model-based Manipulation for Legged Mobile Manipulators
Jan 11, 2022
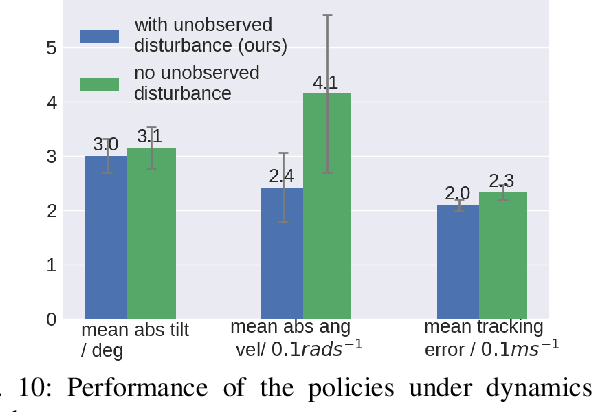
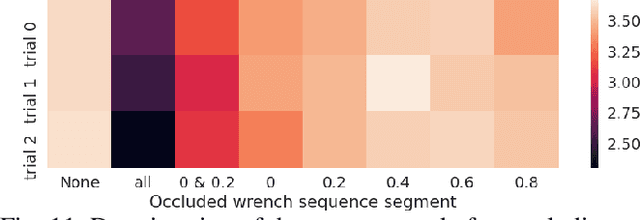
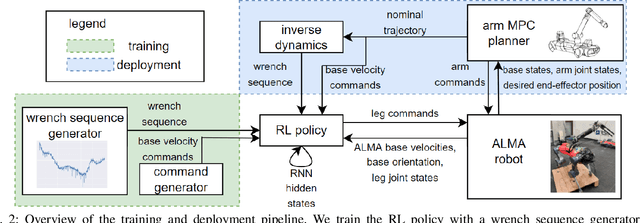
Deep reinforcement learning produces robust locomotion policies for legged robots over challenging terrains. To date, few studies have leveraged model-based methods to combine these locomotion skills with the precise control of manipulators. Here, we incorporate external dynamics plans into learning-based locomotion policies for mobile manipulation. We train the base policy by applying a random wrench sequence on the robot base in simulation and adding the noisified wrench sequence prediction to the policy observations. The policy then learns to counteract the partially-known future disturbance. The random wrench sequences are replaced with the wrench prediction generated with the dynamics plans from model predictive control to enable deployment. We show zero-shot adaptation for manipulators unseen during training. On the hardware, we demonstrate stable locomotion of legged robots with the prediction of the external wrench.
Circus ANYmal: A Quadruped Learning Dexterous Manipulation with Its Limbs
Dec 10, 2020

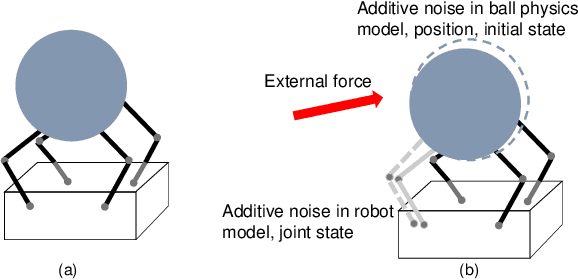
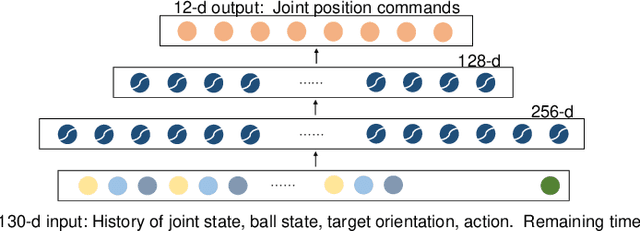
Quadrupedal robots are skillful at locomotion tasks while lacking manipulation skills, not to mention dexterous manipulation abilities. Inspired by the animal behavior and the duality between multi-legged locomotion and multi-fingered manipulation, we showcase a circus ball challenge on a quadrupedal robot, ANYmal. We employ a model-free reinforcement learning approach to train a deep policy that enables the robot to balance and manipulate a light-weight ball robustly using its limbs without any contact measurement sensor. The policy is trained in the simulation, in which we randomize many physical properties with additive noise and inject random disturbance force during manipulation, and achieves zero-shot deployment on the real robot without any adjustment. In the hardware experiments, dynamic performance is achieved with a maximum rotation speed of 15 deg/s, and robust recovery is showcased under external poking. To our best knowledge, it is the first work that demonstrates the dexterous dynamic manipulation on a real quadrupedal robot.
Learning Quadrupedal Locomotion over Challenging Terrain
Oct 21, 2020Some of the most challenging environments on our planet are accessible to quadrupedal animals but remain out of reach for autonomous machines. Legged locomotion can dramatically expand the operational domains of robotics. However, conventional controllers for legged locomotion are based on elaborate state machines that explicitly trigger the execution of motion primitives and reflexes. These designs have escalated in complexity while falling short of the generality and robustness of animal locomotion. Here we present a radically robust controller for legged locomotion in challenging natural environments. We present a novel solution to incorporating proprioceptive feedback in locomotion control and demonstrate remarkable zero-shot generalization from simulation to natural environments. The controller is trained by reinforcement learning in simulation. It is based on a neural network that acts on a stream of proprioceptive signals. The trained controller has taken two generations of quadrupedal ANYmal robots to a variety of natural environments that are beyond the reach of prior published work in legged locomotion. The controller retains its robustness under conditions that have never been encountered during training: deformable terrain such as mud and snow, dynamic footholds such as rubble, and overground impediments such as thick vegetation and gushing water. The presented work opens new frontiers for robotics and indicates that radical robustness in natural environments can be achieved by training in much simpler domains.
DeepGait: Planning and Control of Quadrupedal Gaits using Deep Reinforcement Learning
Sep 18, 2019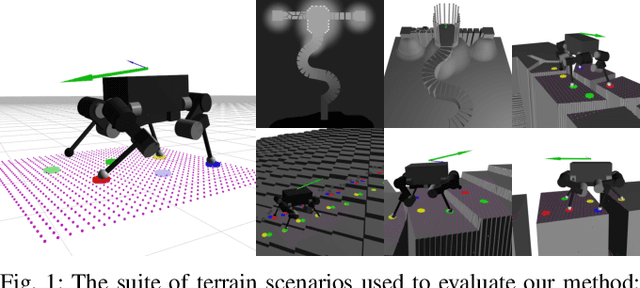
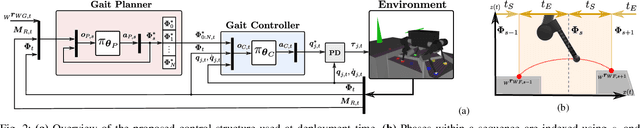
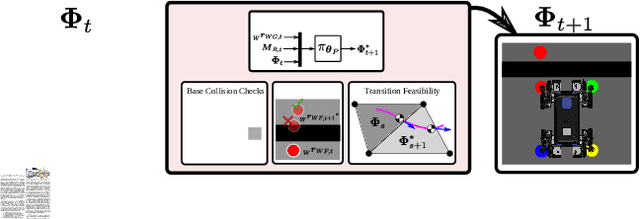
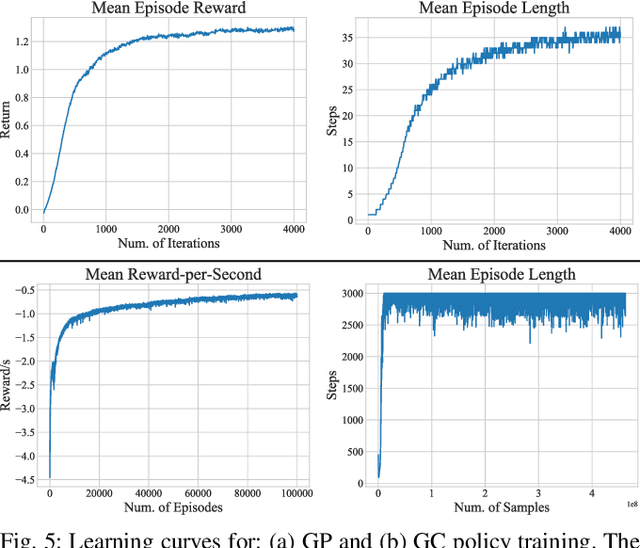
This paper addresses the problem of legged locomotion in non-flat terrain. As legged robots such as quadrupeds are to be deployed in terrains with geometries which are difficult to model and predict, the need arises to equip them with the capability to generalize well to unforeseen situations. In this work, we propose a novel technique for training neural-network policies for terrain-aware locomotion, which combines state-of-the-art methods for model-based motion planning and reinforcement learning. Our approach is centered on formulating Markov decision processes using the evaluation of dynamic feasibility criteria in place of physical simulation. We thus employ policy-gradient methods to independently train policies which respectively plan and execute foothold and base motions in 3D environments using both proprioceptive and exteroceptive measurements. We apply our method within a challenging suite of simulated terrain scenarios which contain features such as narrow bridges, gaps and stepping-stones, and train policies which succeed in locomoting effectively in all cases.
ProbAct: A Probabilistic Activation Function for Deep Neural Networks
May 26, 2019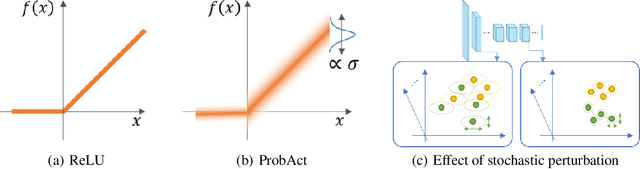
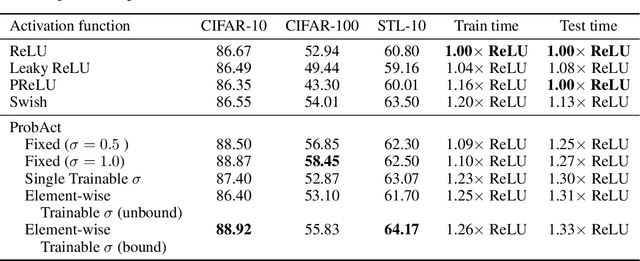
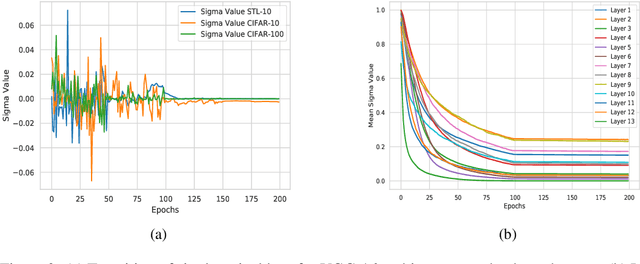

Activation functions play an important role in the training of artificial neural networks and the Rectified Linear Unit (ReLU) has been the mainstream in recent years. Most of the activation functions currently used are deterministic in nature, whose input-output relationship is fixed. In this work, we propose a probabilistic activation function, called ProbAct. The output value of ProbAct is sampled from a normal distribution, with the mean value same as the output of ReLU and with a fixed or trainable variance for each element. In the trainable ProbAct, the variance of the activation distribution is trained through back-propagation. We also show that the stochastic perturbation through ProbAct is a viable generalization technique that can prevent overfitting. In our experiments, we demonstrate that when using ProbAct, it is possible to boost the image classification performance on CIFAR-10, CIFAR-100, and STL-10 datasets.
Learning agile and dynamic motor skills for legged robots
Jan 24, 2019Legged robots pose one of the greatest challenges in robotics. Dynamic and agile maneuvers of animals cannot be imitated by existing methods that are crafted by humans. A compelling alternative is reinforcement learning, which requires minimal craftsmanship and promotes the natural evolution of a control policy. However, so far, reinforcement learning research for legged robots is mainly limited to simulation, and only few and comparably simple examples have been deployed on real systems. The primary reason is that training with real robots, particularly with dynamically balancing systems, is complicated and expensive. In the present work, we introduce a method for training a neural network policy in simulation and transferring it to a state-of-the-art legged system, thereby leveraging fast, automated, and cost-effective data generation schemes. The approach is applied to the ANYmal robot, a sophisticated medium-dog-sized quadrupedal system. Using policies trained in simulation, the quadrupedal machine achieves locomotion skills that go beyond what had been achieved with prior methods: ANYmal is capable of precisely and energy-efficiently following high-level body velocity commands, running faster than before, and recovering from falling even in complex configurations.