 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Summary Loop: Learning to Write Abstractive Summaries Without Examples
May 11, 2021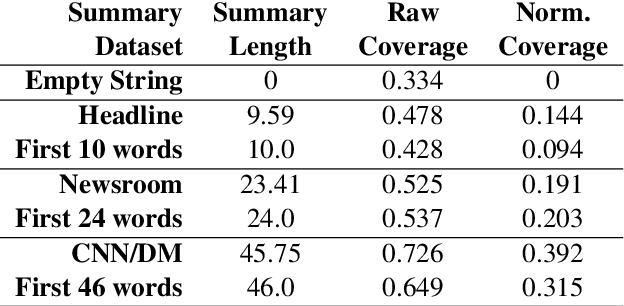
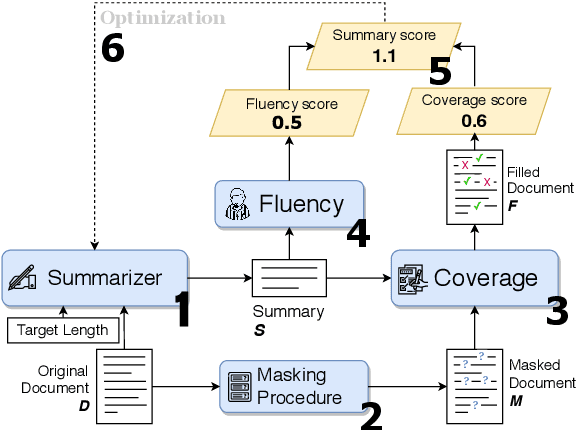
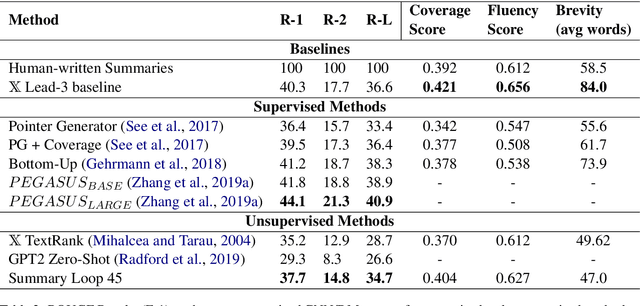
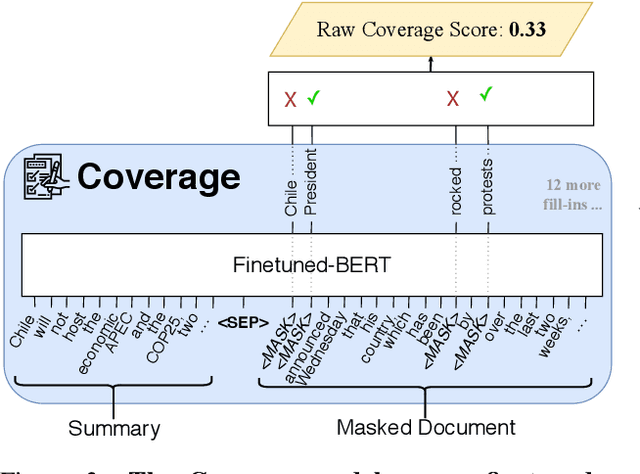
This work presents a new approach to unsupervised abstractive summarization based on maximizing a combination of coverage and fluency for a given length constraint. It introduces a novel method that encourages the inclusion of key terms from the original document into the summary: key terms are masked out of the original document and must be filled in by a coverage model using the current generated summary. A novel unsupervised training procedure leverages this coverage model along with a fluency model to generate and score summaries. When tested on popular news summarization datasets, the method outperforms previous unsupervised methods by more than 2 R-1 points, and approaches results of competitive supervised methods. Our model attains higher levels of abstraction with copied passages roughly two times shorter than prior work, and learns to compress and merge sentences without supervision.
* ACL2020, 16 pages, 9 figures
Active Learning for Video Description With Cluster-Regularized Ensemble Ranking
Jul 29, 2020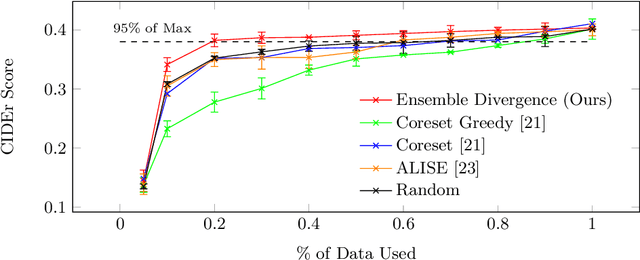
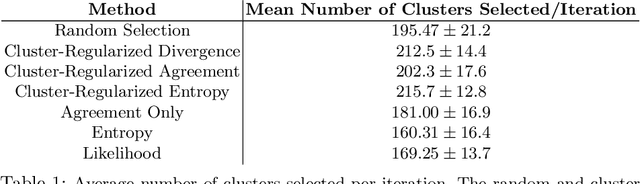
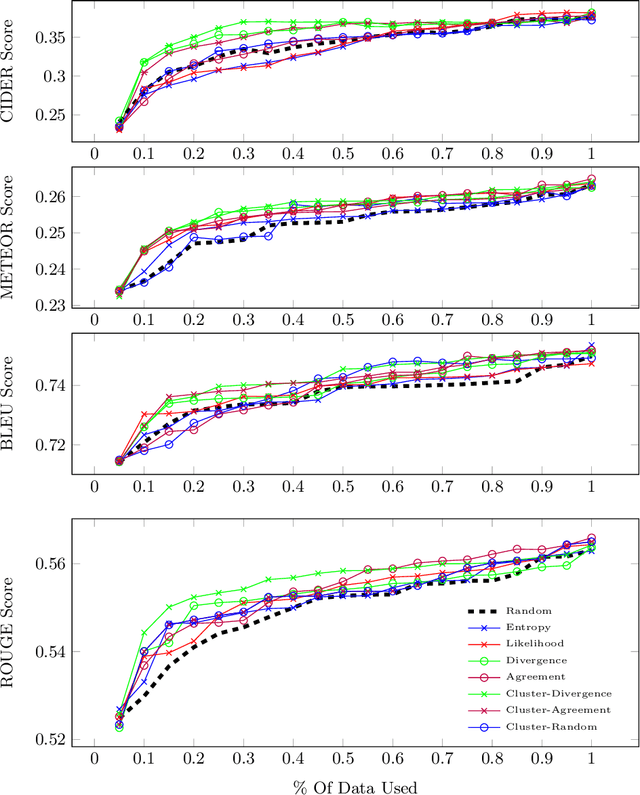
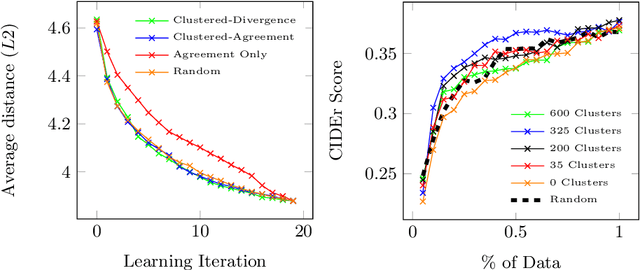
Automatic video captioning aims to train models to generate text descriptions for all segments in a video, however, the most effective approaches require large amounts of manual annotation which is slow and expensive. Active learning is a promising way to efficiently build a training set for video captioning tasks while reducing the need to manually label uninformative examples. In this work we both explore various active learning approaches for automatic video captioning and show that a cluster-regularized ensemble strategy provides the best active learning approach to efficiently gather training sets for video captioning. We evaluate our approaches on the MSR-VTT and LSMDC datasets using both transformer and LSTM based captioning models and show that our novel strategy can achieve high performance while using up to 60% fewer training data than the strong state of the art baselines.
Predictive Information Accelerates Learning in RL
Jul 24, 2020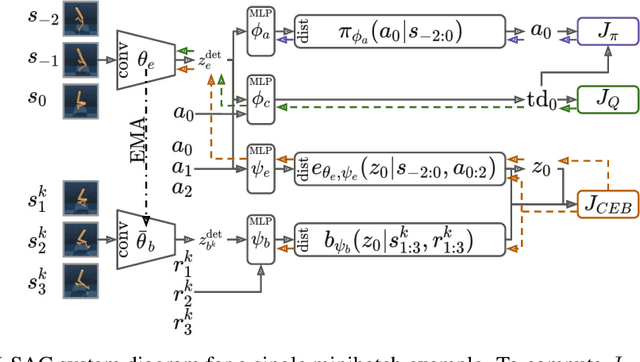
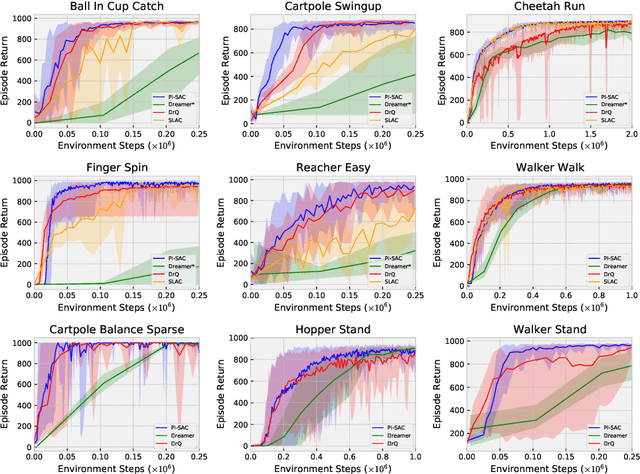
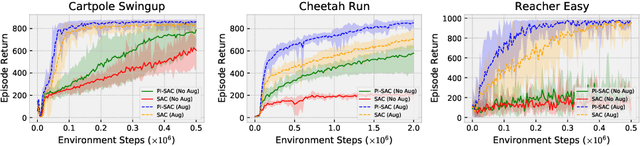
The Predictive Information is the mutual information between the past and the future, I(X_past; X_future). We hypothesize that capturing the predictive information is useful in RL, since the ability to model what will happen next is necessary for success on many tasks. To test our hypothesis, we train Soft Actor-Critic (SAC) agents from pixels with an auxiliary task that learns a compressed representation of the predictive information of the RL environment dynamics using a contrastive version of the Conditional Entropy Bottleneck (CEB) objective. We refer to these as Predictive Information SAC (PI-SAC) agents. We show that PI-SAC agents can substantially improve sample efficiency over challenging baselines on tasks from the DM Control suite of continuous control environments. We evaluate PI-SAC agents by comparing against uncompressed PI-SAC agents, other compressed and uncompressed agents, and SAC agents directly trained from pixels.
A Dataset and Benchmarks for Multimedia Social Analysis
Jun 05, 2020
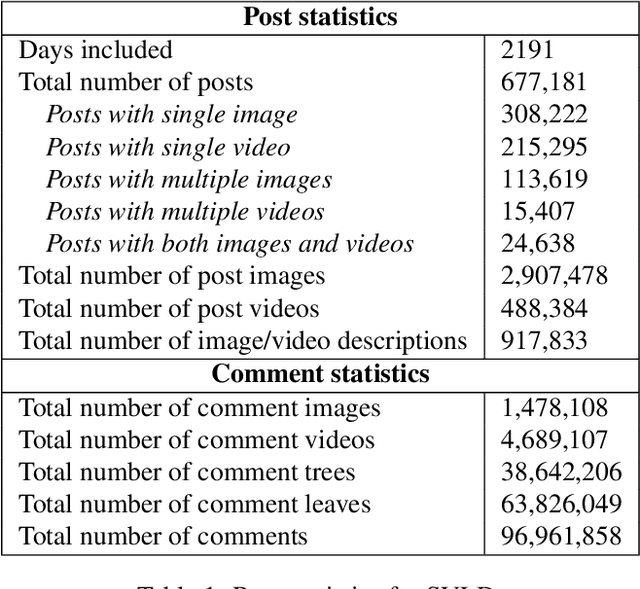
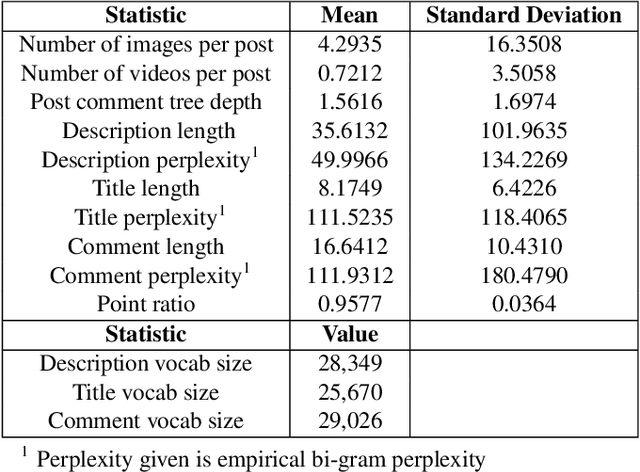
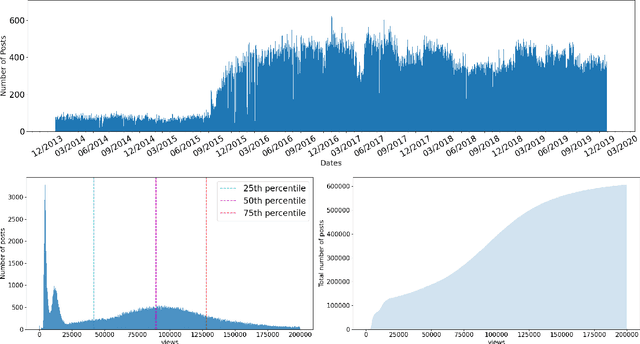
We present a new publicly available dataset with the goal of advancing multi-modality learning by offering vision and language data within the same context. This is achieved by obtaining data from a social media website with posts containing multiple paired images/videos and text, along with comment trees containing images/videos and/or text. With a total of 677k posts, 2.9 million post images, 488k post videos, 1.4 million comment images, 4.6 million comment videos, and 96.9 million comments, data from different modalities can be jointly used to improve performances for a variety of tasks such as image captioning, image classification, next frame prediction, sentiment analysis, and language modeling. We present a wide range of statistics for our dataset. Finally, we provide baseline performance analysis for one of the regression tasks using pre-trained models and several fully connected networks.
Scones: Towards Conversational Authoring of Sketches
May 12, 2020

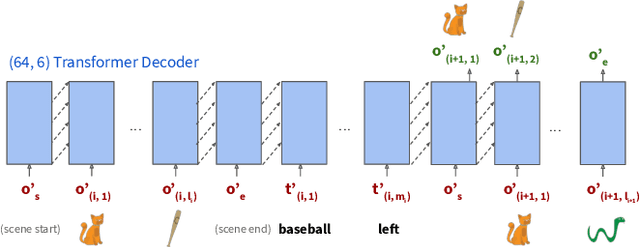
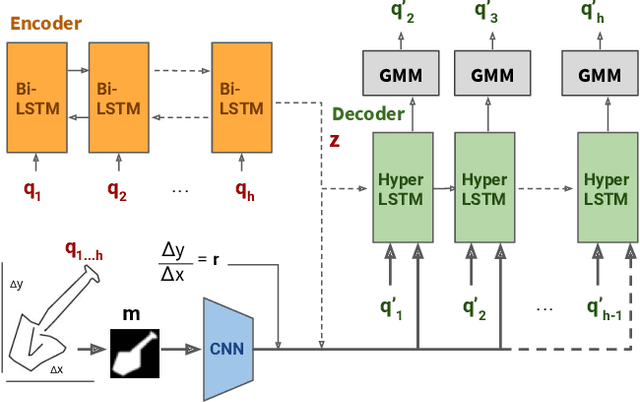
Iteratively refining and critiquing sketches are crucial steps to developing effective designs. We introduce Scones, a mixed-initiative, machine-learning-driven system that enables users to iteratively author sketches from text instructions. Scones is a novel deep-learning-based system that iteratively generates scenes of sketched objects composed with semantic specifications from natural language. Scones exceeds state-of-the-art performance on a text-based scene modification task, and introduces a mask-conditioned sketching model that can generate sketches with poses specified by high-level scene information. In an exploratory user evaluation of Scones, participants reported enjoying an iterative drawing task with Scones, and suggested additional features for further applications. We believe Scones is an early step towards automated, intelligent systems that support human-in-the-loop applications for communicating ideas through sketching in art and design.
Exploring Exploration: Comparing Children with RL Agents in Unified Environments
May 06, 2020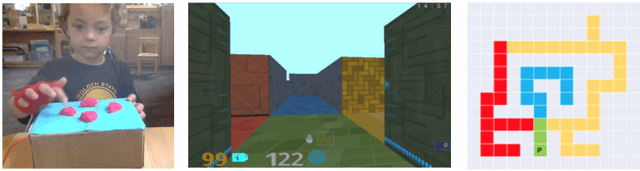
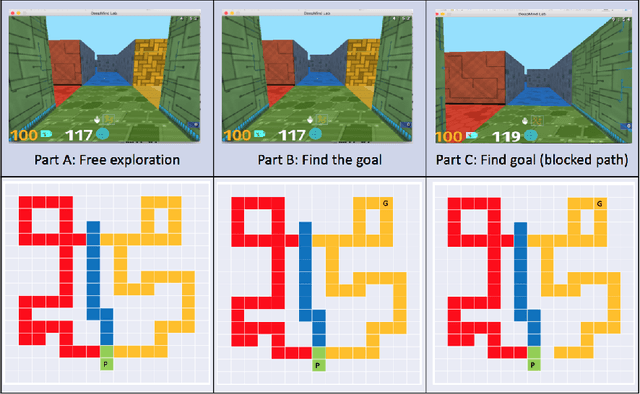
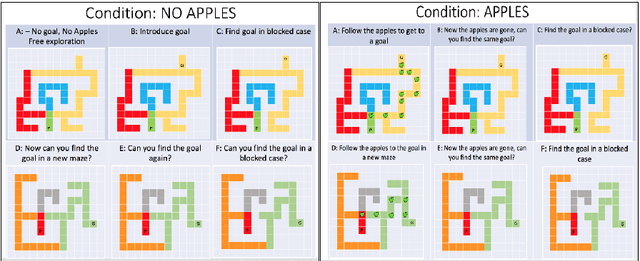
Research in developmental psychology consistently shows that children explore the world thoroughly and efficiently and that this exploration allows them to learn. In turn, this early learning supports more robust generalization and intelligent behavior later in life. While much work has gone into developing methods for exploration in machine learning, artificial agents have not yet reached the high standard set by their human counterparts. In this work we propose using DeepMind Lab (Beattie et al., 2016) as a platform to directly compare child and agent behaviors and to develop new exploration techniques. We outline two ongoing experiments to demonstrate the effectiveness of a direct comparison, and outline a number of open research questions that we believe can be tested using this methodology.
Measuring the Reliability of Reinforcement Learning Algorithms
Dec 10, 2019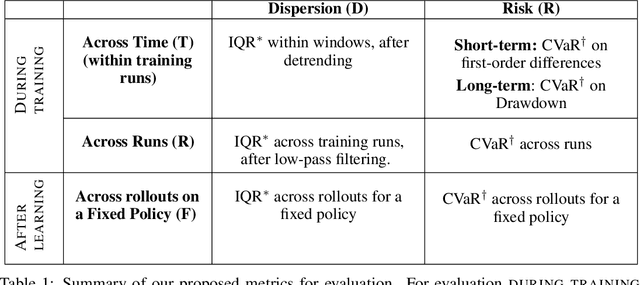
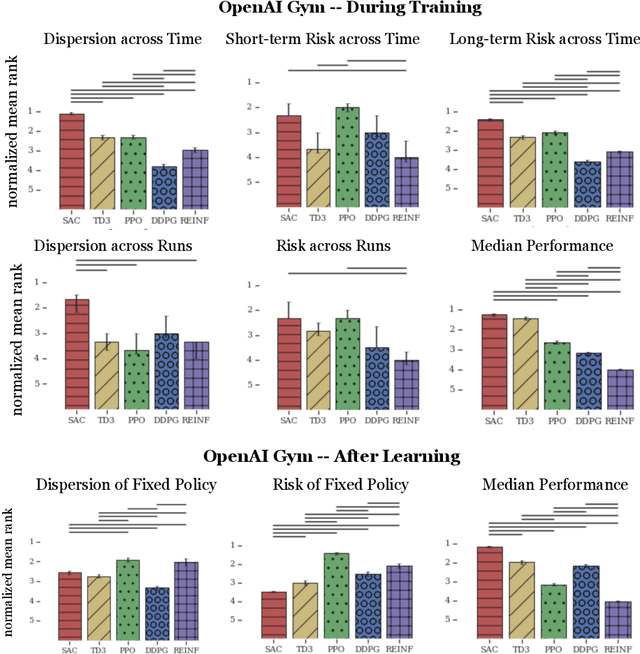
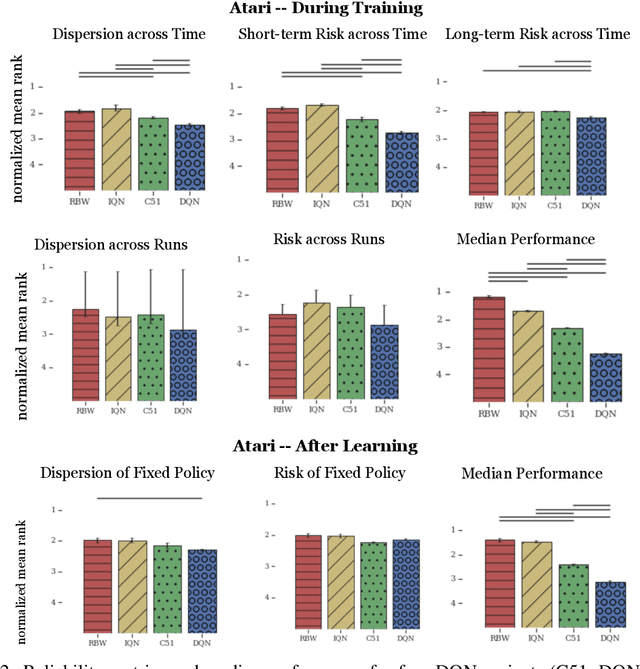
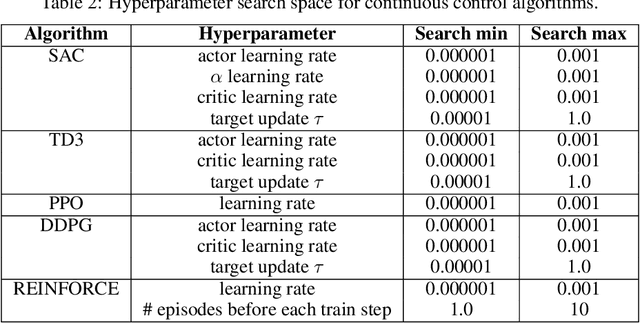
Lack of reliability is a well-known issue for reinforcement learning (RL) algorithms. This problem has gained increasing attention in recent years, and efforts to improve it have grown substantially. To aid RL researchers and production users with the evaluation and improvement of reliability, we propose a set of metrics that quantitatively measure different aspects of reliability. In this work, we focus on variability and risk, both during training and after learning (on a fixed policy). We designed these metrics to be general-purpose, and we also designed complementary statistical tests to enable rigorous comparisons on these metrics. In this paper, we first describe the desired properties of the metrics and their design, the aspects of reliability that they measure, and their applicability to different scenarios. We then describe the statistical tests and make additional practical recommendations for reporting results. The metrics and accompanying statistical tools have been made available as an open-source library, here: https://github.com/google-research/rl-reliability-metrics . We apply our metrics to a set of common RL algorithms and environments, compare them, and analyze the results.
Grounding Human-to-Vehicle Advice for Self-driving Vehicles
Nov 16, 2019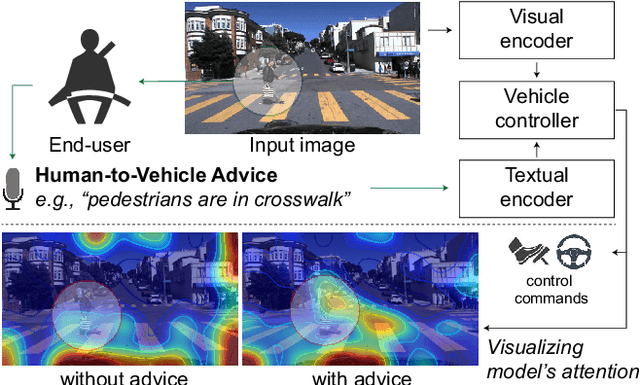

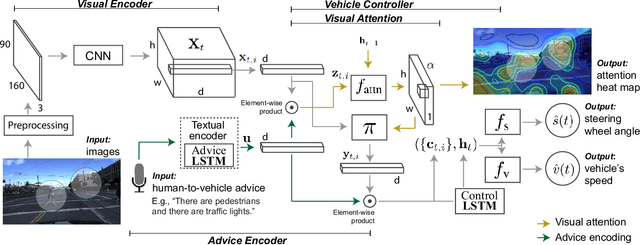
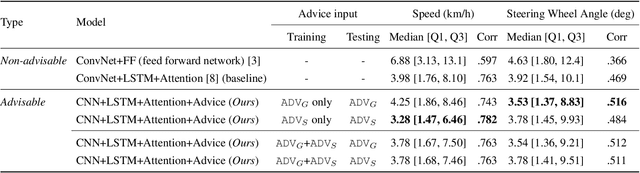
Recent success suggests that deep neural control networks are likely to be a key component of self-driving vehicles. These networks are trained on large datasets to imitate human actions, but they lack semantic understanding of image contents. This makes them brittle and potentially unsafe in situations that do not match training data. Here, we propose to address this issue by augmenting training data with natural language advice from a human. Advice includes guidance about what to do and where to attend. We present the first step toward advice giving, where we train an end-to-end vehicle controller that accepts advice. The controller adapts the way it attends to the scene (visual attention) and the control (steering and speed). Attention mechanisms tie controller behavior to salient objects in the advice. We evaluate our model on a novel advisable driving dataset with manually annotated human-to-vehicle advice called Honda Research Institute-Advice Dataset (HAD). We show that taking advice improves the performance of the end-to-end network, while the network cues on a variety of visual features that are provided by advice. The dataset is available at https://usa.honda-ri.com/HAD.
ZPD Teaching Strategies for Deep Reinforcement Learning from Demonstrations
Oct 26, 2019

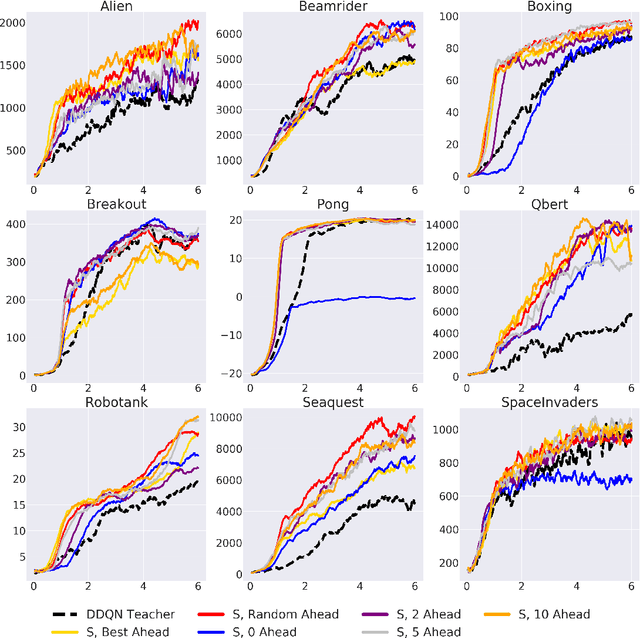

Learning from demonstrations is a popular tool for accelerating and reducing the exploration requirements of reinforcement learning. When providing expert demonstrations to human students, we know that the demonstrations must fall within a particular range of difficulties called the "Zone of Proximal Development (ZPD)". If they are too easy the student learns nothing, but if they are too difficult the student is unable to follow along. This raises the question: Given a set of potential demonstrators, which among them is best suited for teaching any particular learner? Prior work, such as the popular Deep Q-learning from Demonstrations (DQfD) algorithm has generally focused on single demonstrators. In this work we consider the problem of choosing among multiple demonstrators of varying skill levels. Our results align with intuition from human learners: it is not always the best policy to draw demonstrations from the best performing demonstrator (in terms of reward). We show that careful selection of teaching strategies can result in sample efficiency gains in the learner's environment across nine Atari games
Deep Imitation Learning of Sequential Fabric Smoothing Policies
Sep 23, 2019



Sequential pulling policies to flatten and smooth fabrics have applications from surgery to manufacturing to home tasks such as bed making and folding clothes. Due to the complexity of fabric states and dynamics, we apply deep imitation learning to learn policies that, given color or depth images of a rectangular fabric sample, estimate pick points and pull vectors to spread the fabric to maximize coverage. To generate data, we develop a fabric simulator and an algorithmic demonstrator that has access to complete state information. We train policies in simulation using domain randomization and dataset aggregation (DAgger) on three tiers of difficulty in the initial randomized configuration. We present results comparing five baseline policies to learned policies and report systematic comparisons of color vs. depth images as inputs. In simulation, learned policies achieve comparable or superior performance to analytic baselines. In 120 physical experiments with the da Vinci Research Kit (dVRK) surgical robot, policies trained in simulation attain 86% and 69% final coverage for color and depth inputs, respectively, suggesting the feasibility of learning fabric smoothing policies from simulation. Supplementary material is available at https://sites.google.com/view/ fabric-smoothing.