 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for speech recognition with Intermediate layer supervision
Dec 16, 2021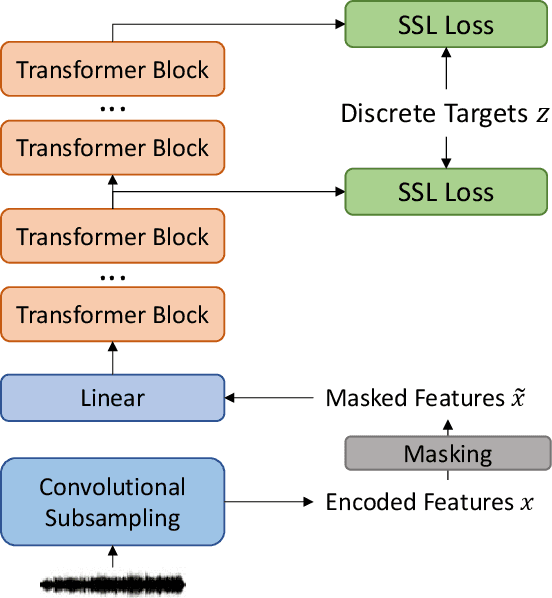
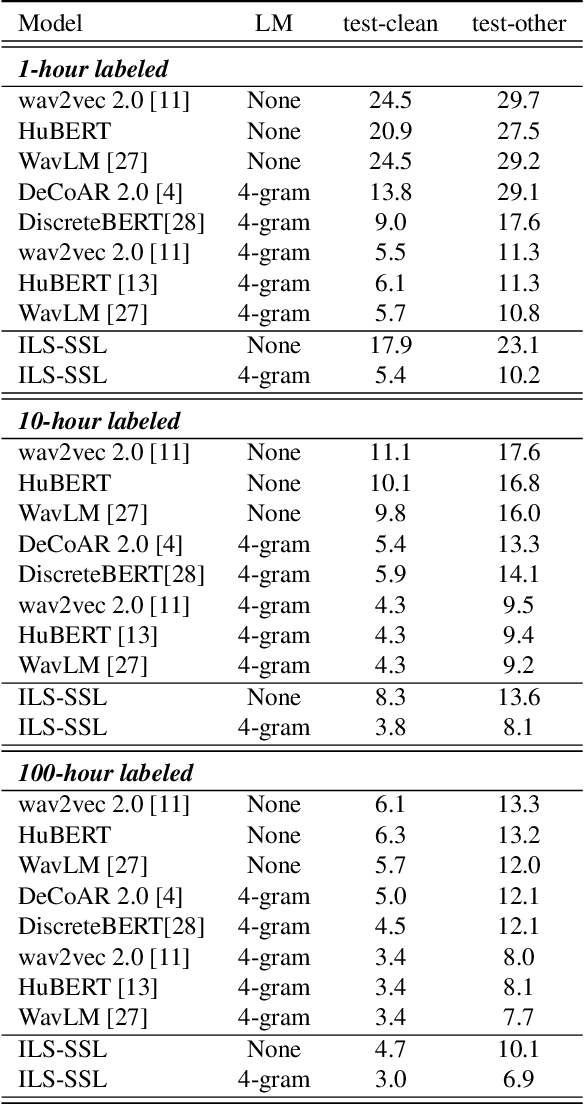
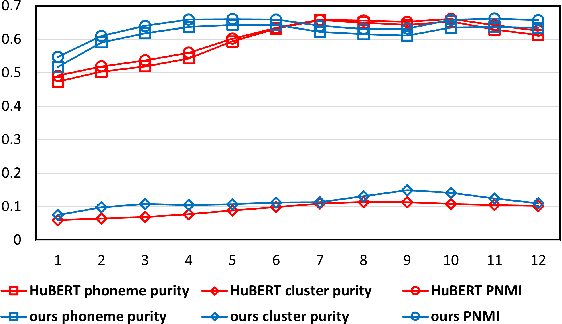
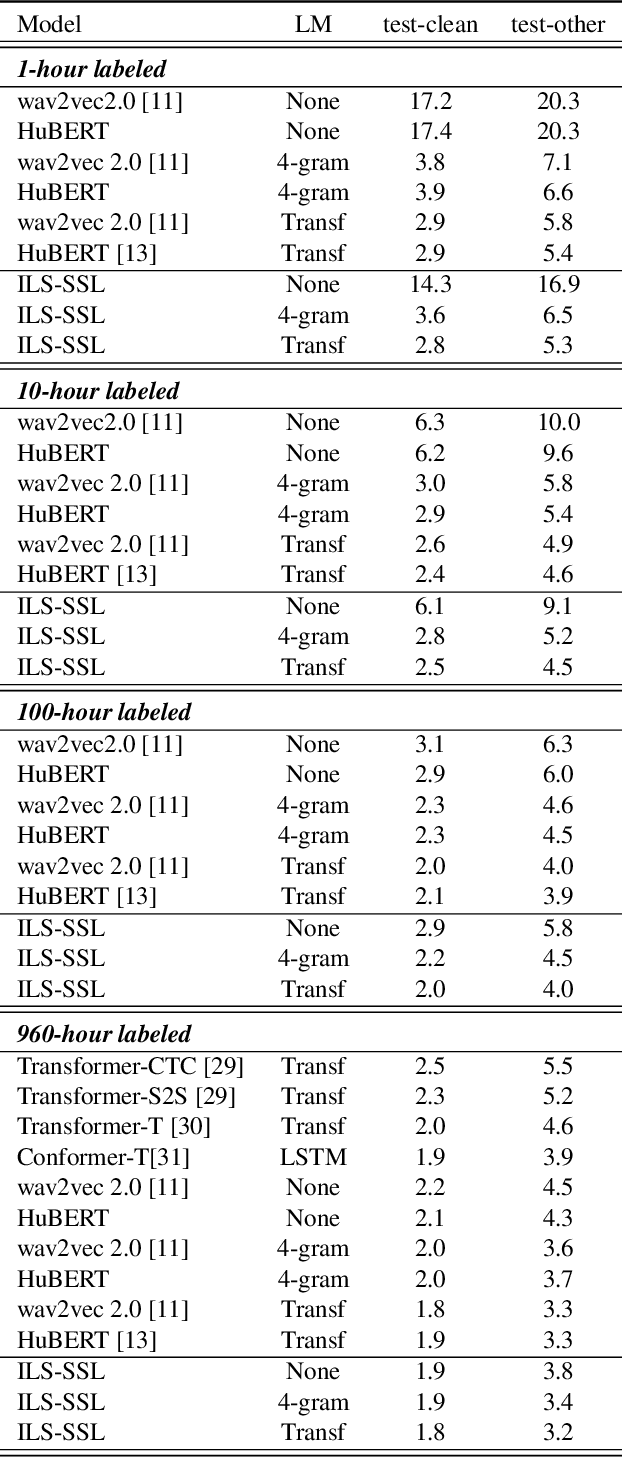
Recently, pioneer work finds that speech pre-trained models can solve full-stack speech processing tasks, because the model utilizes bottom layers to learn speaker-related information and top layers to encode content-related information. Since the network capacity is limited, we believe the speech recognition performance could be further improved if the model is dedicated to audio content information learning. To this end, we propose Intermediate Layer Supervision for Self-Supervised Learning (ILS-SSL), which forces the model to concentrate on content information as much as possible by adding an additional SSL loss on the intermediate layers. Experiments on LibriSpeech test-other set show that our method outperforms HuBERT significantly, which achieves a 23.5%/11.6% relative word error rate reduction in the w/o language model setting for base/large models. Detailed analysis shows the bottom layers of our model have a better correlation with phonetic units, which is consistent with our intuition and explains the success of our method for ASR.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021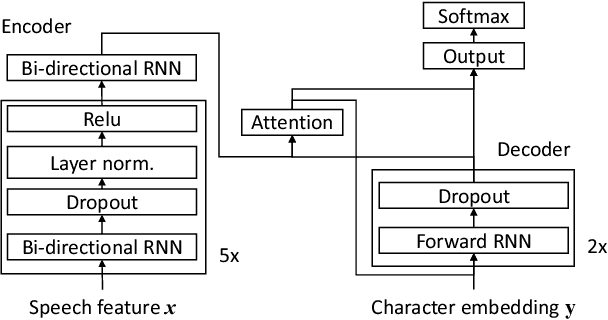
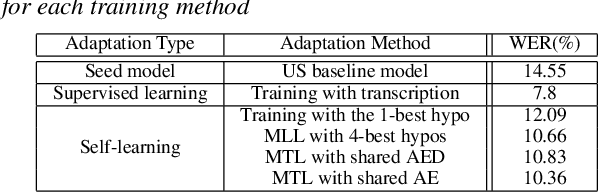
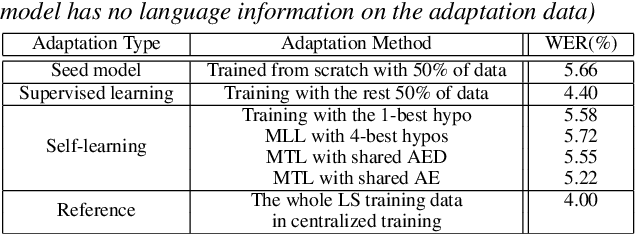
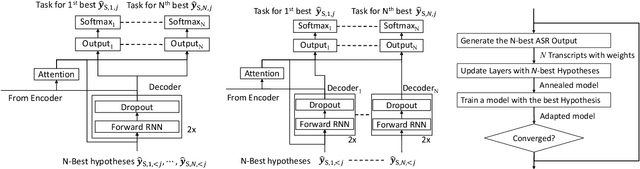
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
Separating Long-Form Speech with Group-Wise Permutation Invariant Training
Nov 17, 2021
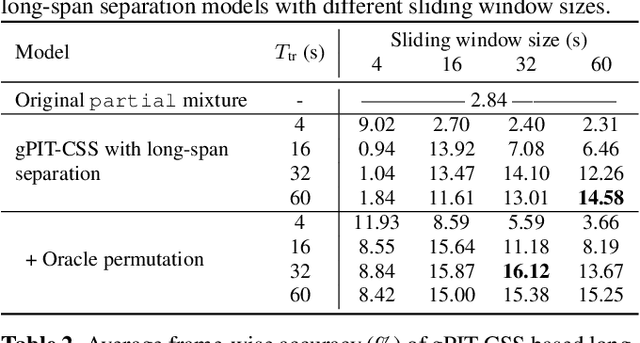
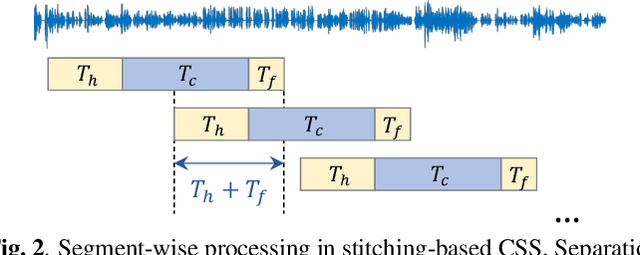
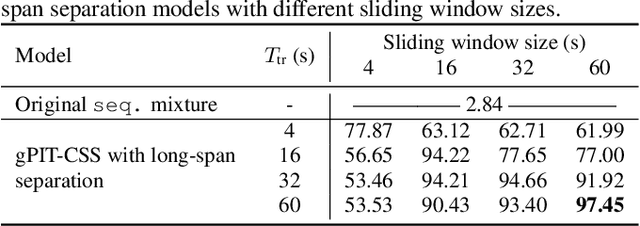
Multi-talker conversational speech processing has drawn many interests for various applications such as meeting transcription. Speech separation is often required to handle overlapped speech that is commonly observed in conversation. Although the original utterancelevel permutation invariant training-based continuous speech separation approach has proven to be effective in various conditions, it lacks the ability to leverage the long-span relationship of utterances and is computationally inefficient due to the highly overlapped sliding windows. To overcome these drawbacks, we propose a novel training scheme named Group-PIT, which allows direct training of the speech separation models on the long-form speech with a low computational cost for label assignment. Two different speech separation approaches with Group-PIT are explored, including direct long-span speech separation and short-span speech separation with long-span tracking. The experiments on the simulated meeting-style data demonstrate the effectiveness of our proposed approaches, especially in dealing with a very long speech input.
Recent Advances in End-to-End Automatic Speech Recognition
Nov 02, 2021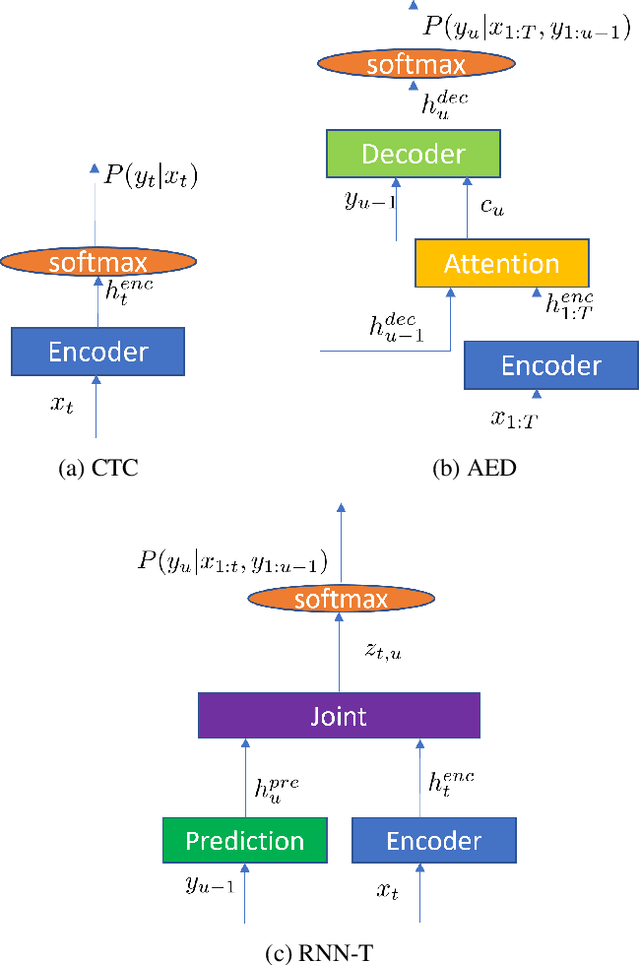
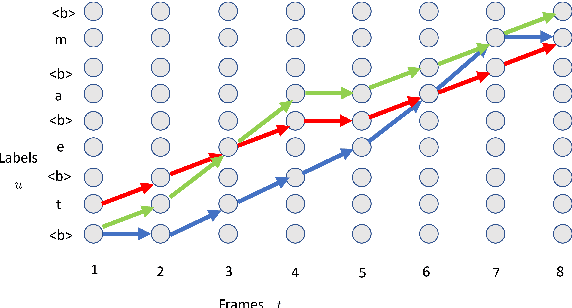

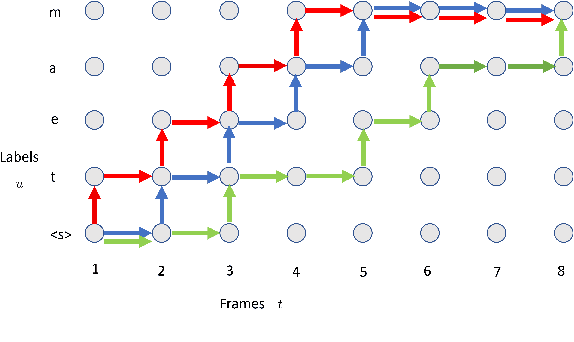
Recently, the speech community is seeing a significant trend of moving from deep neural network based hybrid modeling to end-to-end (E2E) modeling for automatic speech recognition (ASR). While E2E models achieve the state-of-the-art results in most benchmarks in terms of ASR accuracy, hybrid models are still used in a large proportion of commercial ASR systems at the current time. There are lots of practical factors that affect the production model deployment decision. Traditional hybrid models, being optimized for production for decades, are usually good at these factors. Without providing excellent solutions to all these factors, it is hard for E2E models to be widely commercialized. In this paper, we will overview the recent advances in E2E models, focusing on technologies addressing those challenges from the industry's perspective.
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Oct 29, 2021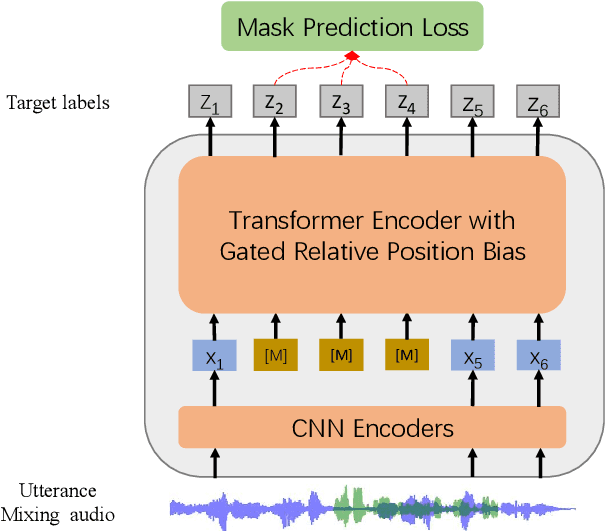
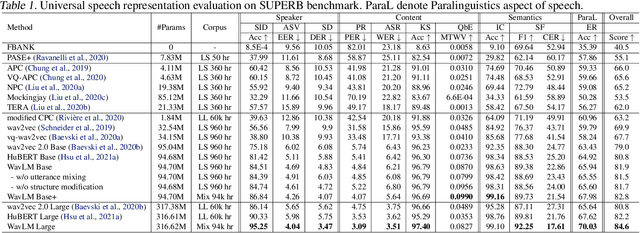
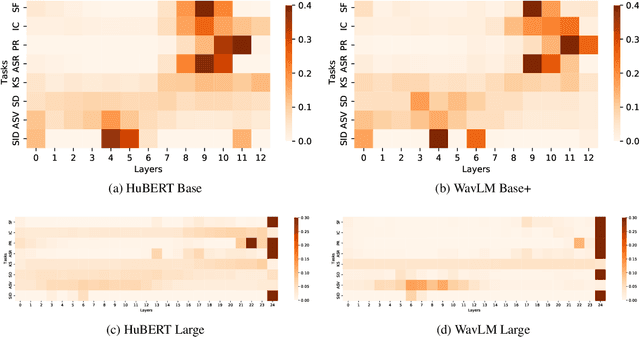
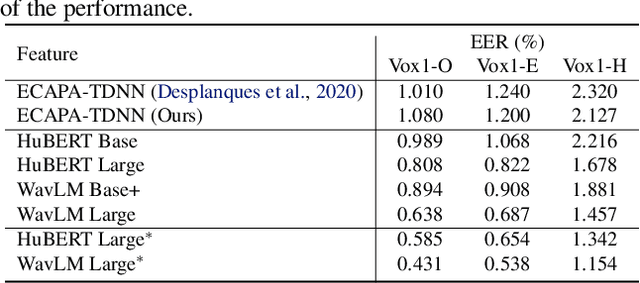
Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks. The code and pretrained models are available at https://aka.ms/wavlm.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021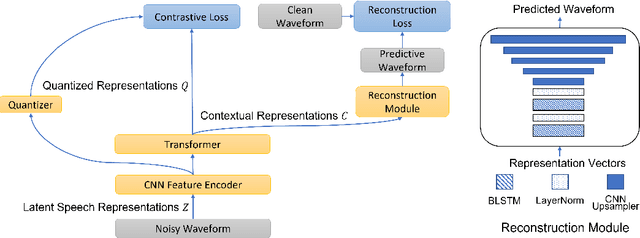
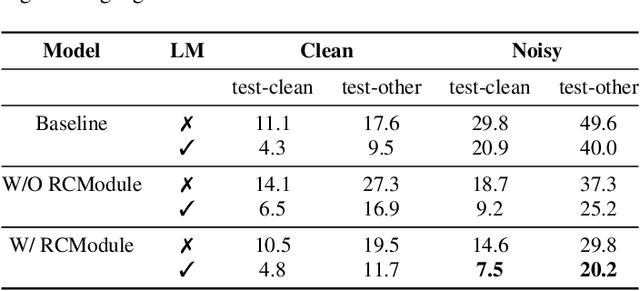
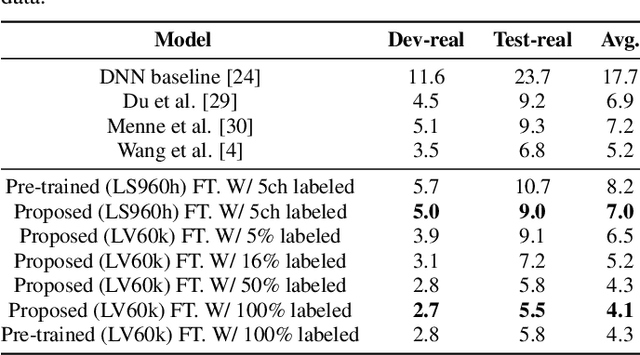
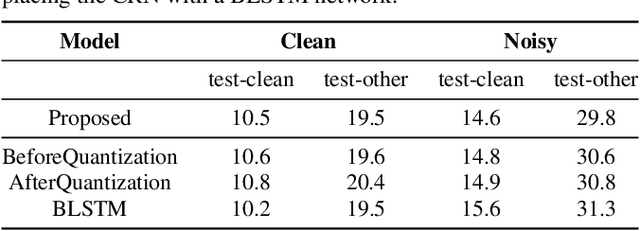
Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.
Continuous Speech Separation with Recurrent Selective Attention Network
Oct 28, 2021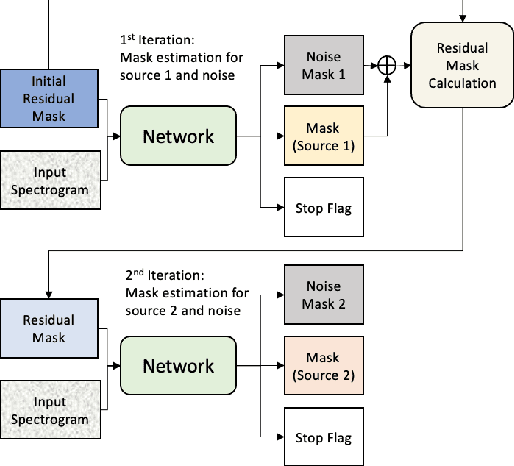
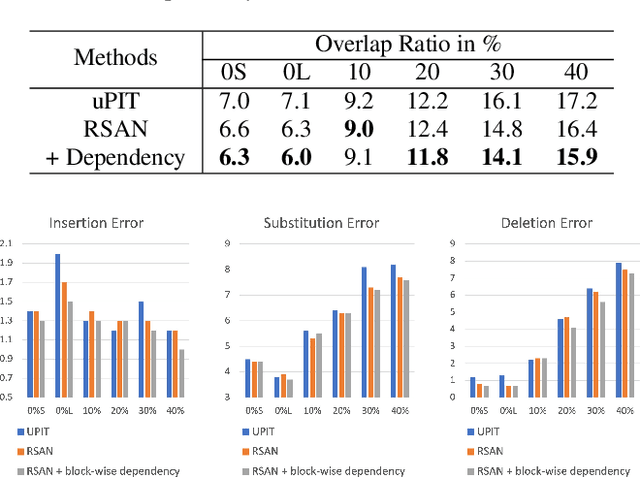
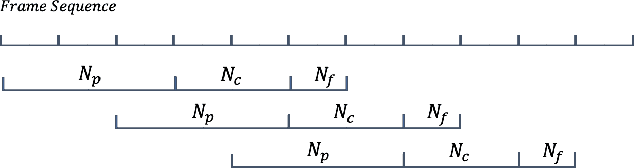
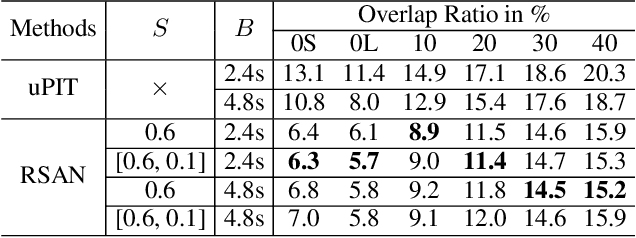
While permutation invariant training (PIT) based continuous speech separation (CSS) significantly improves the conversation transcription accuracy, it often suffers from speech leakages and failures in separation at "hot spot" regions because it has a fixed number of output channels. In this paper, we propose to apply recurrent selective attention network (RSAN) to CSS, which generates a variable number of output channels based on active speaker counting. In addition, we propose a novel block-wise dependency extension of RSAN by introducing dependencies between adjacent processing blocks in the CSS framework. It enables the network to utilize the separation results from the previous blocks to facilitate the current block processing. Experimental results on the LibriCSS dataset show that the RSAN-based CSS (RSAN-CSS) network consistently improves the speech recognition accuracy over PIT-based models. The proposed block-wise dependency modeling further boosts the performance of RSAN-CSS.
Factorized Neural Transducer for Efficient Language Model Adaptation
Oct 18, 2021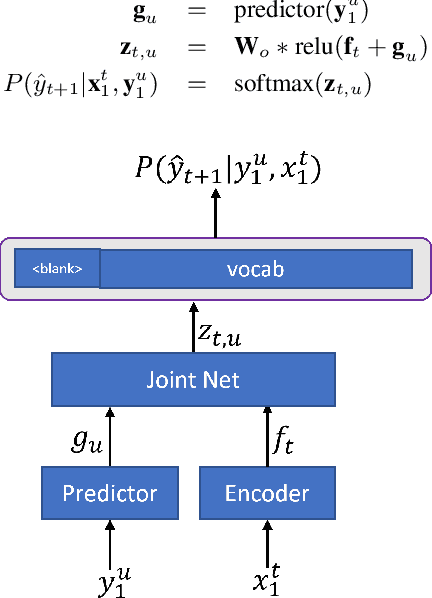

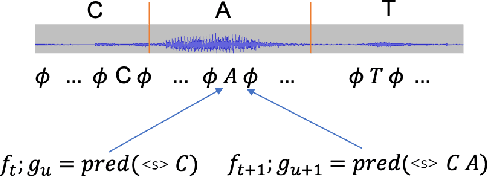
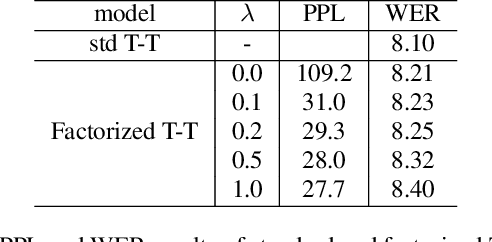
In recent years, end-to-end (E2E) based automatic speech recognition (ASR) systems have achieved great success due to their simplicity and promising performance. Neural Transducer based models are increasingly popular in streaming E2E based ASR systems and have been reported to outperform the traditional hybrid system in some scenarios. However, the joint optimization of acoustic model, lexicon and language model in neural Transducer also brings about challenges to utilize pure text for language model adaptation. This drawback might prevent their potential applications in practice. In order to address this issue, in this paper, we propose a novel model, factorized neural Transducer, by factorizing the blank and vocabulary prediction, and adopting a standalone language model for the vocabulary prediction. It is expected that this factorization can transfer the improvement of the standalone language model to the Transducer for speech recognition, which allows various language model adaptation techniques to be applied. We demonstrate that the proposed factorized neural Transducer yields 15% to 20% WER improvements when out-of-domain text data is used for language model adaptation, at the cost of a minor degradation in WER on a general test set.
Internal Language Model Adaptation with Text-Only Data for End-to-End Speech Recognition
Oct 14, 2021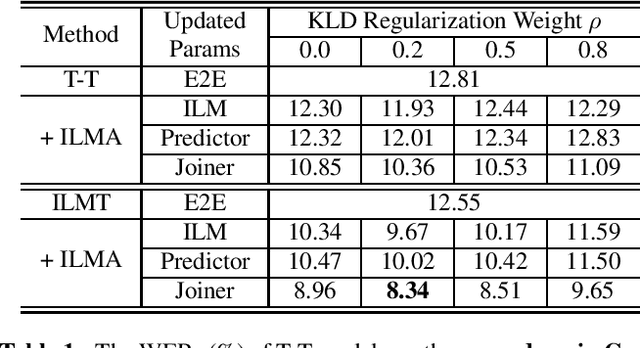
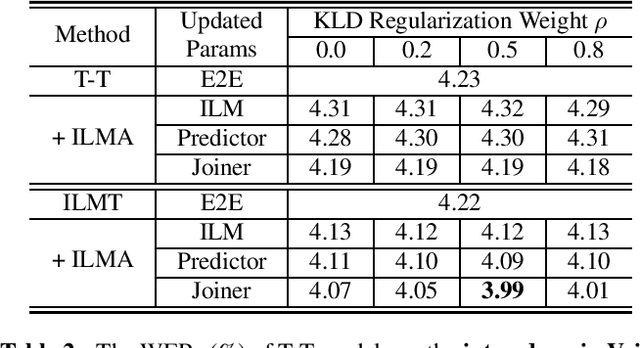
Text-only adaptation of an end-to-end (E2E) model remains a challenging task for automatic speech recognition (ASR). Language model (LM) fusion-based approaches require an additional external LM during inference, significantly increasing the computation cost. To overcome this, we propose an internal LM adaptation (ILMA) of the E2E model using text-only data. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the token sequence probability which is approximated by the E2E model output after zeroing out the encoder contribution. During ILMA, we fine-tune the internal LM, i.e., the E2E components excluding the encoder, to minimize a cross-entropy loss. To make ILMA effective, it is essential to train the E2E model with an internal LM loss besides the standard E2E loss. Furthermore, we propose to regularize ILMA by minimizing the Kullback-Leibler divergence between the output distributions of the adapted and unadapted internal LMs. ILMA is the most effective when we update only the last linear layer of the joint network. ILMA enables a fast text-only adaptation of the E2E model without increasing the run-time computational cost. Experimented with 30K-hour trained transformer transducer models, ILMA achieves up to 34.9% relative word error rate reduction from the unadapted baseline.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021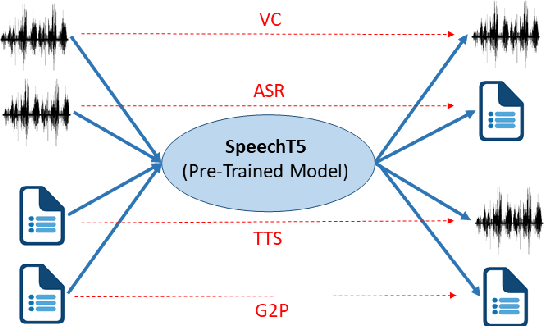
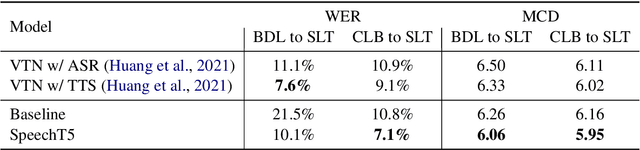
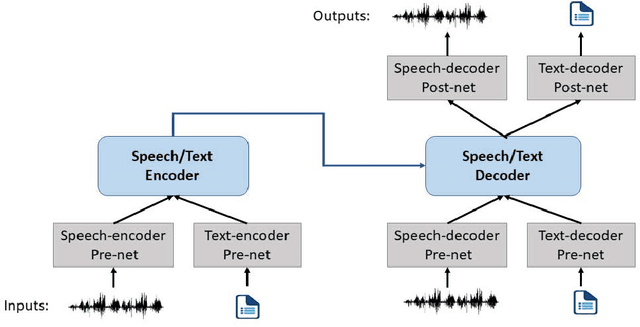
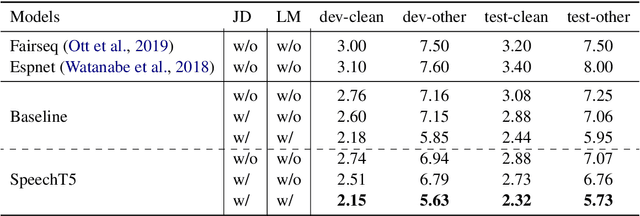
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.