 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Mask Calibration for Unified Domain Adaptive Panoptic Segmentation
Jun 30, 2022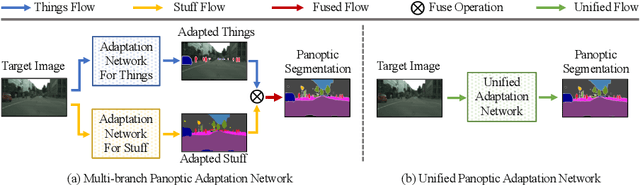

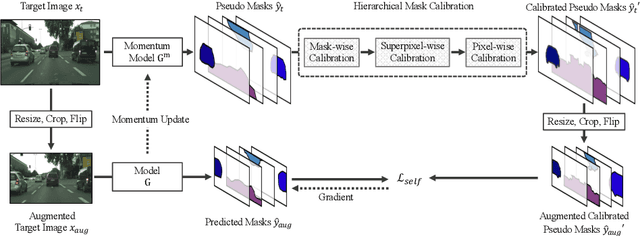

Domain adaptive panoptic segmentation aims to mitigate data annotation challenge by leveraging off-the-shelf annotated data in one or multiple related source domains. However, existing studies employ two networks for instance segmentation and semantic segmentation separately which lead to a large amount of network parameters with complicated and computationally intensive training and inference processes. We design UniDAPS, a Unified Domain Adaptive Panoptic Segmentation network that is simple but capable of achieving domain adaptive instance segmentation and semantic segmentation simultaneously within a single network. UniDAPS introduces Hierarchical Mask Calibration (HMC) that rectifies the predicted pseudo masks, pseudo superpixels and pseudo pixels and performs network re-training via an online self-training process on the fly. It has three unique features: 1) it enables unified domain adaptive panoptic adaptation; 2) it mitigates false predictions and improves domain adaptive panoptic segmentation effectively; 3) it is end-to-end trainable with much less parameters and simpler training and inference pipeline. Extensive experiments over multiple public benchmarks show that UniDAPS achieves superior domain adaptive panoptic segmentation as compared with the state-of-the-art.
An optimal transport approach for selecting a representative subsample with application in efficient kernel density estimation
May 31, 2022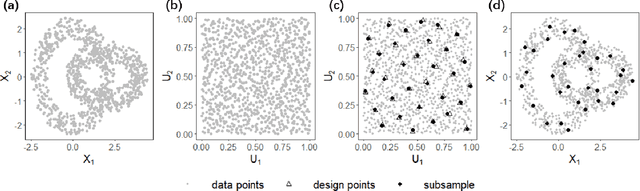
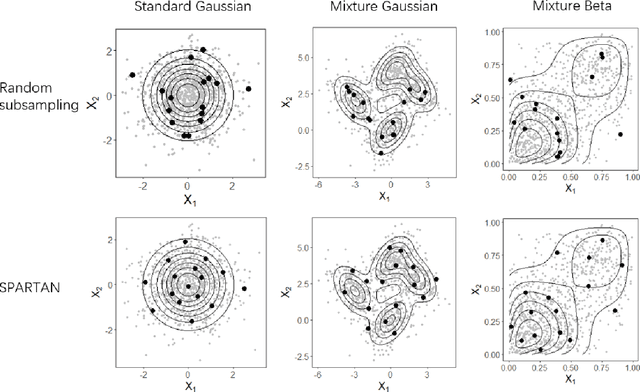
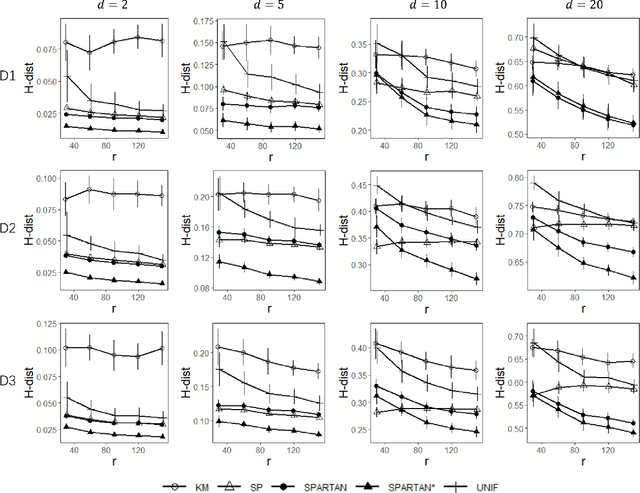
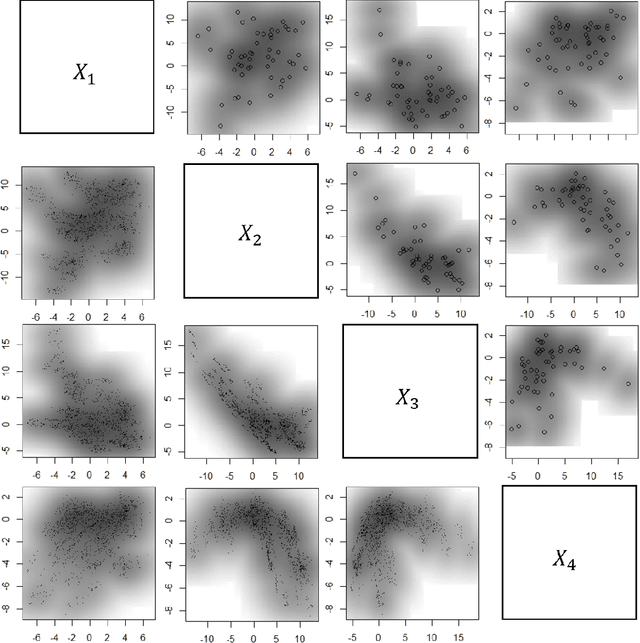
Subsampling methods aim to select a subsample as a surrogate for the observed sample. Such methods have been used pervasively in large-scale data analytics, active learning, and privacy-preserving analysis in recent decades. Instead of model-based methods, in this paper, we study model-free subsampling methods, which aim to identify a subsample that is not confined by model assumptions. Existing model-free subsampling methods are usually built upon clustering techniques or kernel tricks. Most of these methods suffer from either a large computational burden or a theoretical weakness. In particular, the theoretical weakness is that the empirical distribution of the selected subsample may not necessarily converge to the population distribution. Such computational and theoretical limitations hinder the broad applicability of model-free subsampling methods in practice. We propose a novel model-free subsampling method by utilizing optimal transport techniques. Moreover, we develop an efficient subsampling algorithm that is adaptive to the unknown probability density function. Theoretically, we show the selected subsample can be used for efficient density estimation by deriving the convergence rate for the proposed subsample kernel density estimator. We also provide the optimal bandwidth for the proposed estimator. Numerical studies on synthetic and real-world datasets demonstrate the performance of the proposed method is superior.
LiDARCap: Long-range Marker-less 3D Human Motion Capture with LiDAR Point Clouds
Mar 28, 2022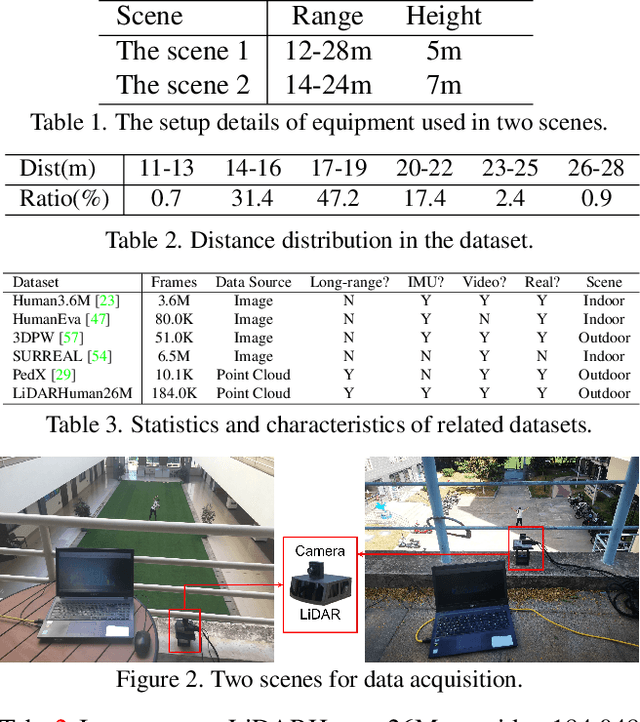
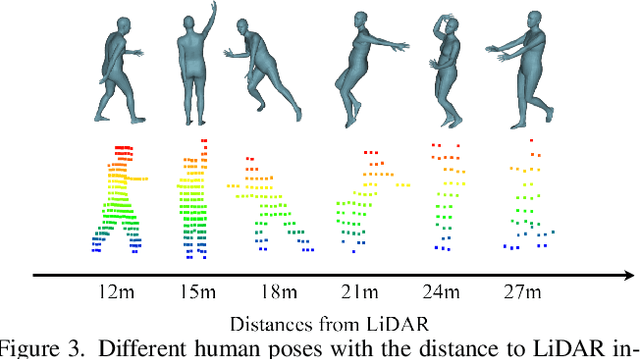
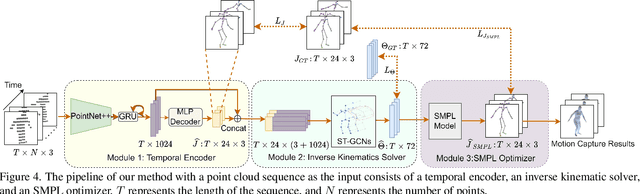
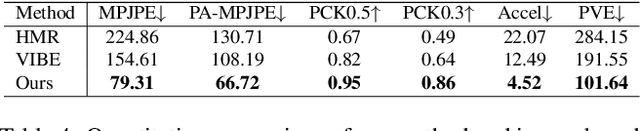
Existing motion capture datasets are largely short-range and cannot yet fit the need of long-range applications. We propose LiDARHuman26M, a new human motion capture dataset captured by LiDAR at a much longer range to overcome this limitation. Our dataset also includes the ground truth human motions acquired by the IMU system and the synchronous RGB images. We further present a strong baseline method, LiDARCap, for LiDAR point cloud human motion capture. Specifically, we first utilize PointNet++ to encode features of points and then employ the inverse kinematics solver and SMPL optimizer to regress the pose through aggregating the temporally encoded features hierarchically. Quantitative and qualitative experiments show that our method outperforms the techniques based only on RGB images. Ablation experiments demonstrate that our dataset is challenging and worthy of further research. Finally, the experiments on the KITTI Dataset and the Waymo Open Dataset show that our method can be generalized to different LiDAR sensor settings.
Oversampling Divide-and-conquer for Response-skewed Kernel Ridge Regression
Jul 13, 2021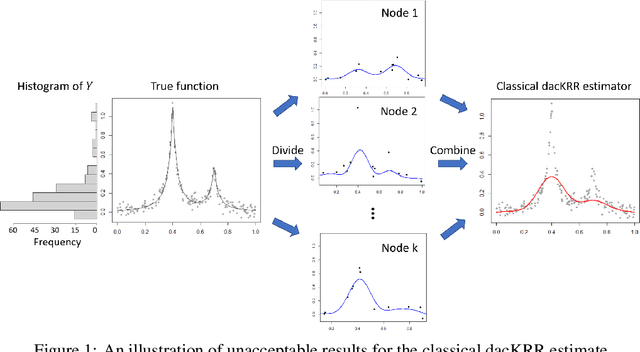
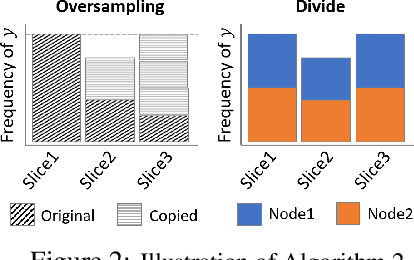
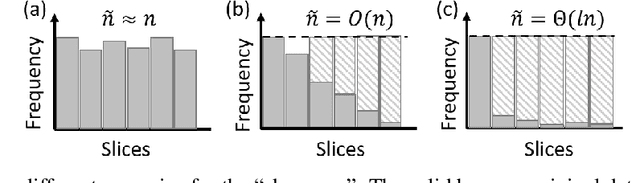
The divide-and-conquer method has been widely used for estimating large-scale kernel ridge regression estimates. Unfortunately, when the response variable is highly skewed, the divide-and-conquer kernel ridge regression (dacKRR) may overlook the underrepresented region and result in unacceptable results. We develop a novel response-adaptive partition strategy to overcome the limitation. In particular, we propose to allocate the replicates of some carefully identified informative observations to multiple nodes (local processors). The idea is analogous to the popular oversampling technique. Although such a technique has been widely used for addressing discrete label skewness, extending it to the dacKRR setting is nontrivial. We provide both theoretical and practical guidance on how to effectively over-sample the observations under the dacKRR setting. Furthermore, we show the proposed estimate has a smaller asymptotic mean squared error (AMSE) than that of the classical dacKRR estimate under mild conditions. Our theoretical findings are supported by both simulated and real-data analyses.
Spectral Unsupervised Domain Adaptation for Visual Recognition
Jun 11, 2021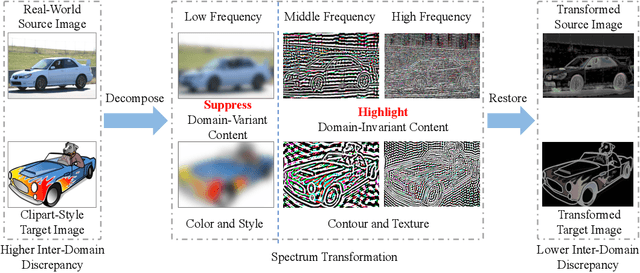
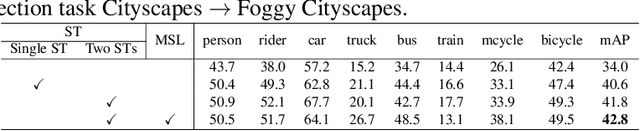
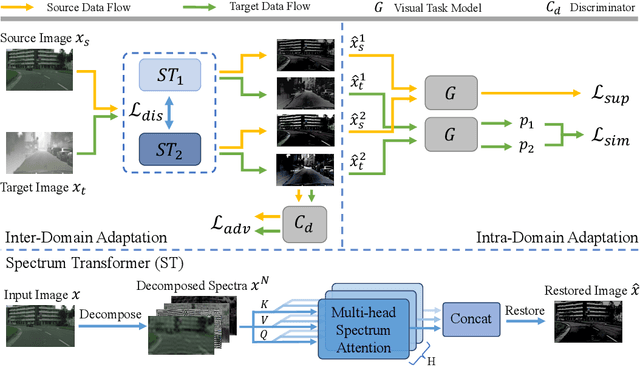

Unsupervised domain adaptation (UDA) aims to learn a well-performed model in an unlabeled target domain by leveraging labeled data from one or multiple related source domains. It remains a great challenge due to 1) the lack of annotations in the target domain and 2) the rich discrepancy between the distributions of source and target data. We propose Spectral UDA (SUDA), an efficient yet effective UDA technique that works in the spectral space and is generic across different visual recognition tasks in detection, classification and segmentation. SUDA addresses UDA challenges from two perspectives. First, it mitigates inter-domain discrepancies by a spectrum transformer (ST) that maps source and target images into spectral space and learns to enhance domain-invariant spectra while suppressing domain-variant spectra simultaneously. To this end, we design novel adversarial multi-head spectrum attention that leverages contextual information to identify domain-variant and domain-invariant spectra effectively. Second, it mitigates the lack of annotations in target domain by introducing multi-view spectral learning which aims to learn comprehensive yet confident target representations by maximizing the mutual information among multiple ST augmentations capturing different spectral views of each target sample. Extensive experiments over different visual tasks (e.g., detection, classification and segmentation) show that SUDA achieves superior accuracy and it is also complementary with state-of-the-art UDA methods with consistent performance boosts but little extra computation.
Large-scale optimal transport map estimation using projection pursuit
Jun 09, 2021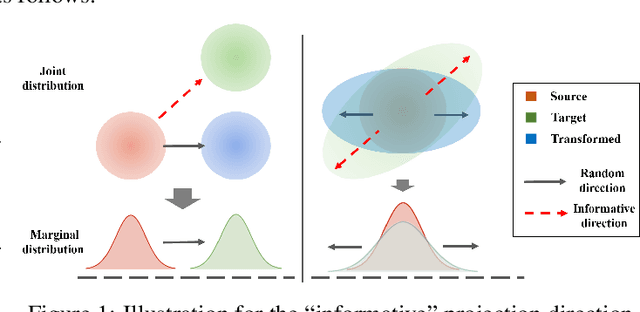

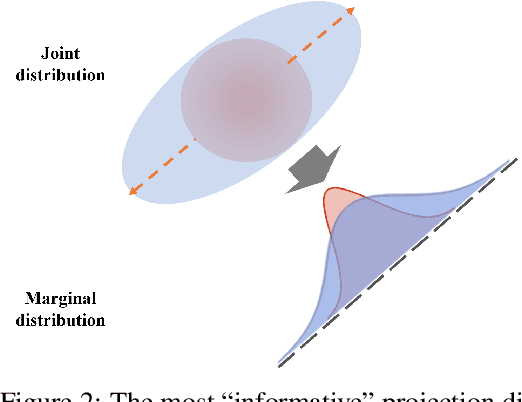

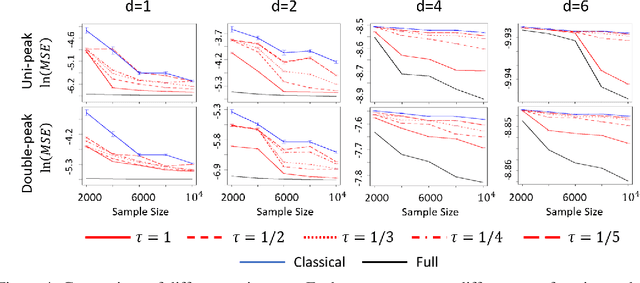
This paper studies the estimation of large-scale optimal transport maps (OTM), which is a well-known challenging problem owing to the curse of dimensionality. Existing literature approximates the large-scale OTM by a series of one-dimensional OTM problems through iterative random projection. Such methods, however, suffer from slow or none convergence in practice due to the nature of randomly selected projection directions. Instead, we propose an estimation method of large-scale OTM by combining the idea of projection pursuit regression and sufficient dimension reduction. The proposed method, named projection pursuit Monge map (PPMM), adaptively selects the most ``informative'' projection direction in each iteration. We theoretically show the proposed dimension reduction method can consistently estimate the most ``informative'' projection direction in each iteration. Furthermore, the PPMM algorithm weakly convergences to the target large-scale OTM in a reasonable number of steps. Empirically, PPMM is computationally easy and converges fast. We assess its finite sample performance through the applications of Wasserstein distance estimation and generative models.
Ensemble machine learning approach for screening of coronary heart disease based on echocardiography and risk factors
May 20, 2021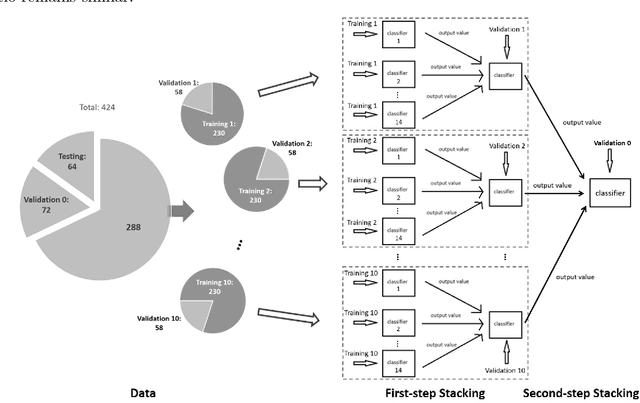
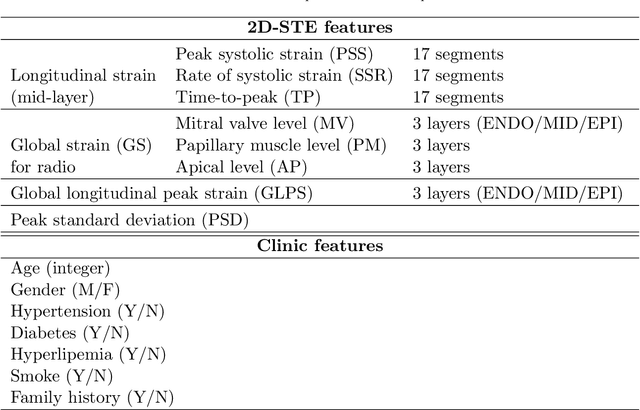
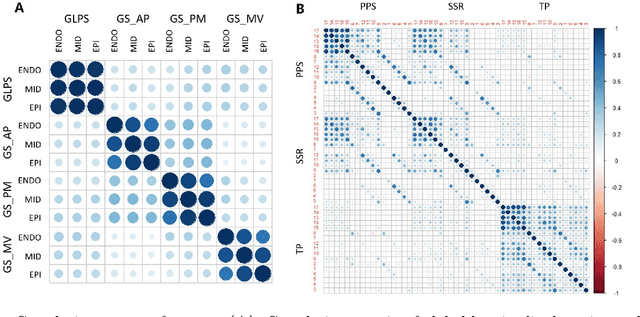
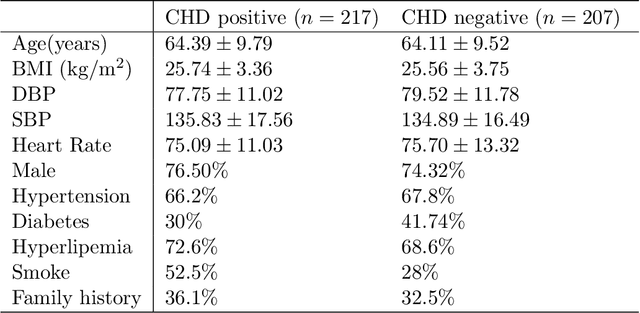
Background: Extensive clinical evidence suggests that a preventive screening of coronary heart disease (CHD) at an earlier stage can greatly reduce the mortality rate. We use 64 two-dimensional speckle tracking echocardiography (2D-STE) features and seven clinical features to predict whether one has CHD. Methods: We develop a machine learning approach that integrates a number of popular classification methods together by model stacking, and generalize the traditional stacking method to a two-step stacking method to improve the diagnostic performance. Results: By borrowing strengths from multiple classification models through the proposed method, we improve the CHD classification accuracy from around 70% to 87.7% on the testing set. The sensitivity of the proposed method is 0.903 and the specificity is 0.843, with an AUC of 0.904, which is significantly higher than those of the individual classification models. Conclusions: Our work lays a foundation for the deployment of speckle tracking echocardiography-based screening tools for coronary heart disease.
Reinforced Neighborhood Selection Guided Multi-Relational Graph Neural Networks
Apr 16, 2021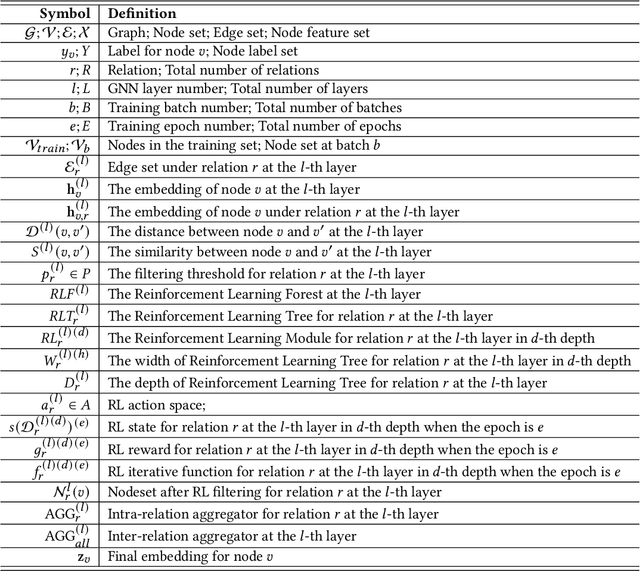
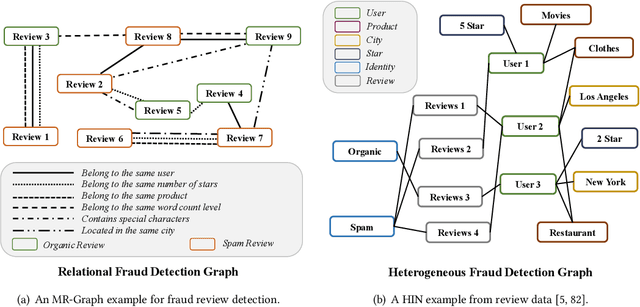
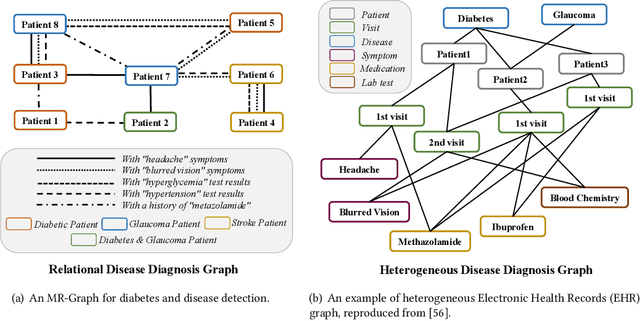
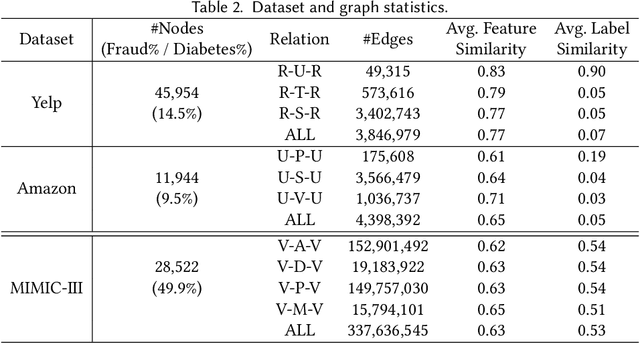
Graph Neural Networks (GNNs) have been widely used for the representation learning of various structured graph data, typically through message passing among nodes by aggregating their neighborhood information via different operations. While promising, most existing GNNs oversimplified the complexity and diversity of the edges in the graph, and thus inefficient to cope with ubiquitous heterogeneous graphs, which are typically in the form of multi-relational graph representations. In this paper, we propose RioGNN, a novel Reinforced, recursive and flexible neighborhood selection guided multi-relational Graph Neural Network architecture, to navigate complexity of neural network structures whilst maintaining relation-dependent representations. We first construct a multi-relational graph, according to the practical task, to reflect the heterogeneity of nodes, edges, attributes and labels. To avoid the embedding over-assimilation among different types of nodes, we employ a label-aware neural similarity measure to ascertain the most similar neighbors based on node attributes. A reinforced relation-aware neighbor selection mechanism is developed to choose the most similar neighbors of a targeting node within a relation before aggregating all neighborhood information from different relations to obtain the eventual node embedding. Particularly, to improve the efficiency of neighbor selecting, we propose a new recursive and scalable reinforcement learning framework with estimable depth and width for different scales of multi-relational graphs. RioGNN can learn more discriminative node embedding with enhanced explainability due to the recognition of individual importance of each relation via the filtering threshold mechanism.
A Detector-oblivious Multi-arm Network for Keypoint Matching
Apr 05, 2021
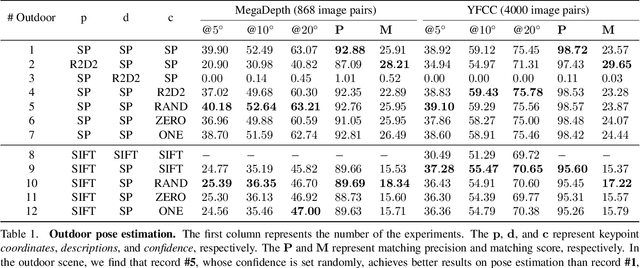
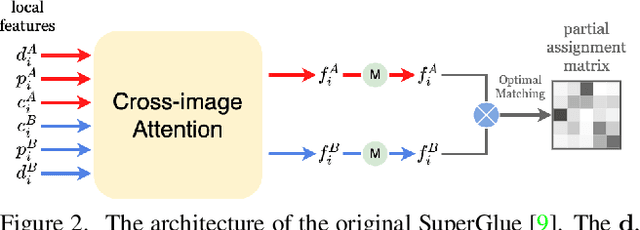
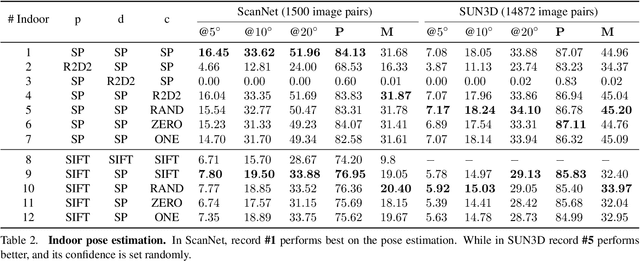
This paper presents a matching network to establish point correspondence between images. We propose a Multi-Arm Network (MAN) to learn region overlap and depth, which can greatly improve the keypoint matching robustness while bringing little computational cost during the inference stage. Another design that makes this framework different from many existing learning based pipelines that require re-training when a different keypoint detector is adopted, our network can directly work with different keypoint detectors without such a time-consuming re-training process. Comprehensive experiments conducted on outdoor and indoor datasets demonstrated that our proposed MAN outperforms state-of-the-art methods. Code will be made publicly available.
DA-DETR: Domain Adaptive Detection Transformer by Hybrid Attention
Mar 31, 2021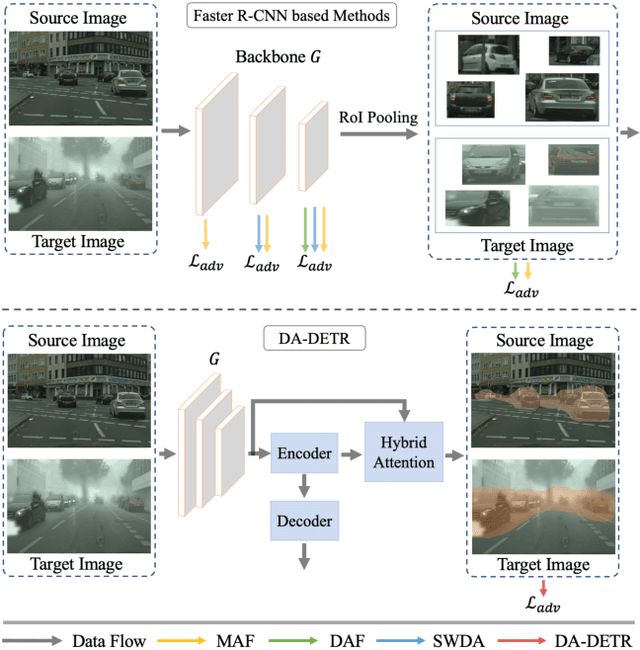



The prevalent approach in domain adaptive object detection adopts a two-stage architecture (Faster R-CNN) that involves a number of hyper-parameters and hand-crafted designs such as anchors, region pooling, non-maximum suppression, etc. Such architecture makes it very complicated while adopting certain existing domain adaptation methods with different ways of feature alignment. In this work, we adopt a one-stage detector and design DA-DETR, a simple yet effective domain adaptive object detection network that performs inter-domain alignment with a single discriminator. DA-DETR introduces a hybrid attention module that explicitly pinpoints the hard-aligned features for simple yet effective alignment across domains. It greatly simplifies traditional domain adaptation pipelines by eliminating sophisticated routines that involve multiple adversarial learning frameworks with different types of features. Despite its simplicity, extensive experiments show that DA-DETR demonstrates superior accuracy as compared with highly-optimized state-of-the-art approaches.