 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bilateral Retinex for Low-Light Image Enhancement
Jul 04, 2020

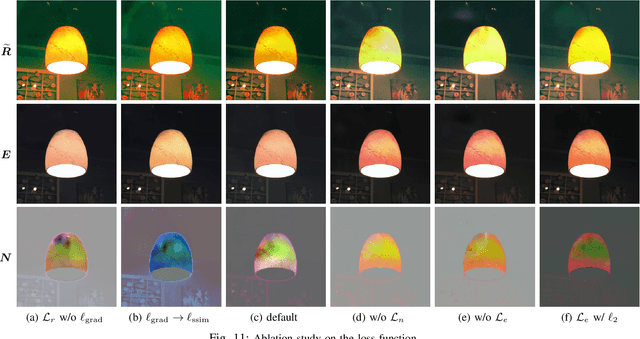
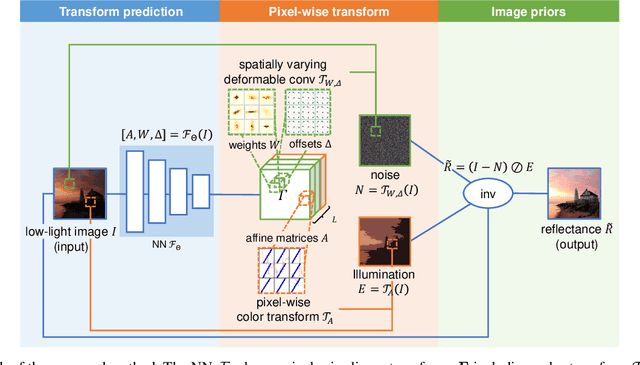
Low-light images, i.e. the images captured in low-light conditions, suffer from very poor visibility caused by low contrast, color distortion and significant measurement noise. Low-light image enhancement is about improving the visibility of low-light images. As the measurement noise in low-light images is usually significant yet complex with spatially-varying characteristic, how to handle the noise effectively is an important yet challenging problem in low-light image enhancement. Based on the Retinex decomposition of natural images, this paper proposes a deep learning method for low-light image enhancement with a particular focus on handling the measurement noise. The basic idea is to train a neural network to generate a set of pixel-wise operators for simultaneously predicting the noise and the illumination layer, where the operators are defined in the bilateral space. Such an integrated approach allows us to have an accurate prediction of the reflectance layer in the presence of significant spatially-varying measurement noise. Extensive experiments on several benchmark datasets have shown that the proposed method is very competitive to the state-of-the-art methods, and has significant advantage over others when processing images captured in extremely low lighting conditions.
STH: Spatio-Temporal Hybrid Convolution for Efficient Action Recognition
Mar 18, 2020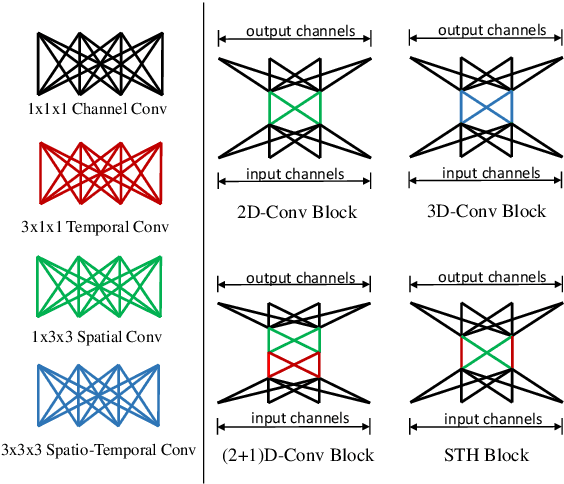
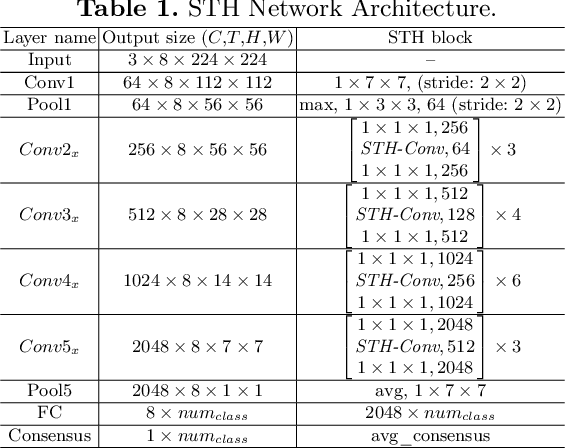
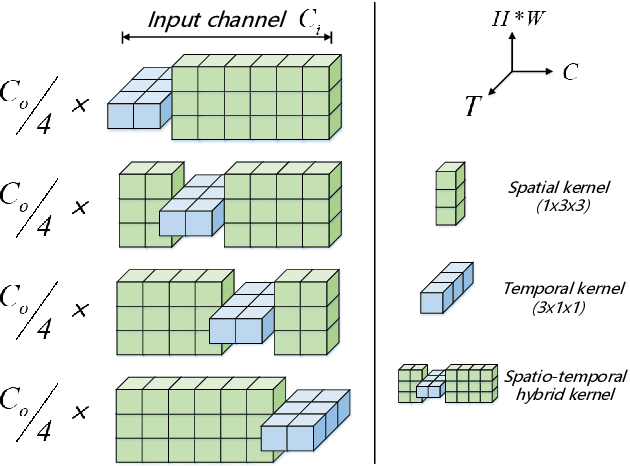
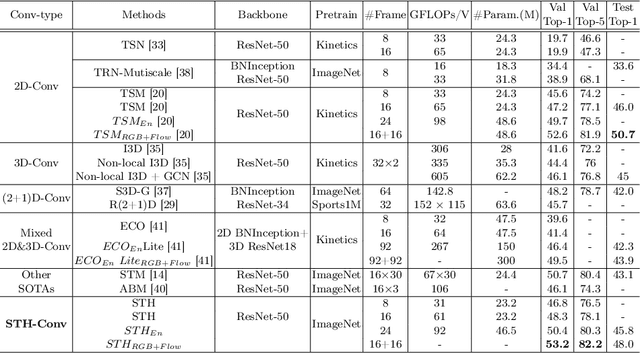
Effective and Efficient spatio-temporal modeling is essential for action recognition. Existing methods suffer from the trade-off between model performance and model complexity. In this paper, we present a novel Spatio-Temporal Hybrid Convolution Network (denoted as "STH") which simultaneously encodes spatial and temporal video information with a small parameter cost. Different from existing works that sequentially or parallelly extract spatial and temporal information with different convolutional layers, we divide the input channels into multiple groups and interleave the spatial and temporal operations in one convolutional layer, which deeply incorporates spatial and temporal clues. Such a design enables efficient spatio-temporal modeling and maintains a small model scale. STH-Conv is a general building block, which can be plugged into existing 2D CNN architectures such as ResNet and MobileNet by replacing the conventional 2D-Conv blocks (2D convolutions). STH network achieves competitive or even better performance than its competitors on benchmark datasets such as Something-Something (V1 & V2), Jester, and HMDB-51. Moreover, STH enjoys performance superiority over 3D CNNs while maintaining an even smaller parameter cost than 2D CNNs.
Weakly-Supervised Multi-Level Attentional Reconstruction Network for Grounding Textual Queries in Videos
Mar 16, 2020
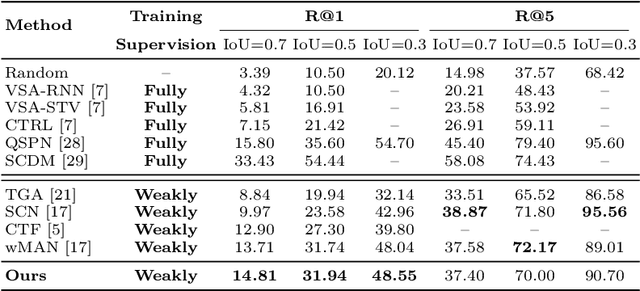
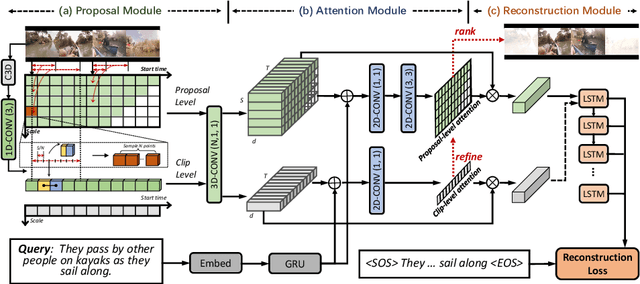
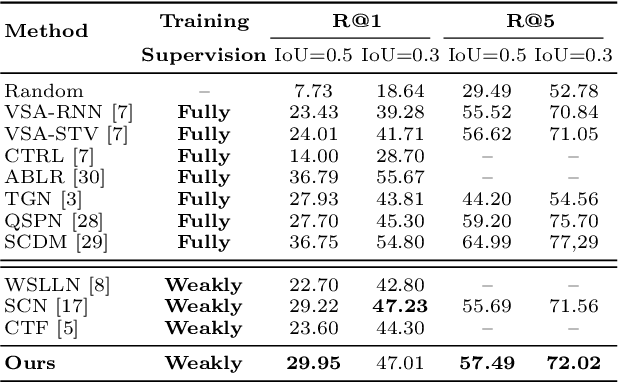
The task of temporally grounding textual queries in videos is to localize one video segment that semantically corresponds to the given query. Most of the existing approaches rely on segment-sentence pairs (temporal annotations) for training, which are usually unavailable in real-world scenarios. In this work we present an effective weakly-supervised model, named as Multi-Level Attentional Reconstruction Network (MARN), which only relies on video-sentence pairs during the training stage. The proposed method leverages the idea of attentional reconstruction and directly scores the candidate segments with the learnt proposal-level attentions. Moreover, another branch learning clip-level attention is exploited to refine the proposals at both the training and testing stage. We develop a novel proposal sampling mechanism to leverage intra-proposal information for learning better proposal representation and adopt 2D convolution to exploit inter-proposal clues for learning reliable attention map. Experiments on Charades-STA and ActivityNet-Captions datasets demonstrate the superiority of our MARN over the existing weakly-supervised methods.
Pathomic Fusion: An Integrated Framework for Fusing Histopathology and Genomic Features for Cancer Diagnosis and Prognosis
Dec 30, 2019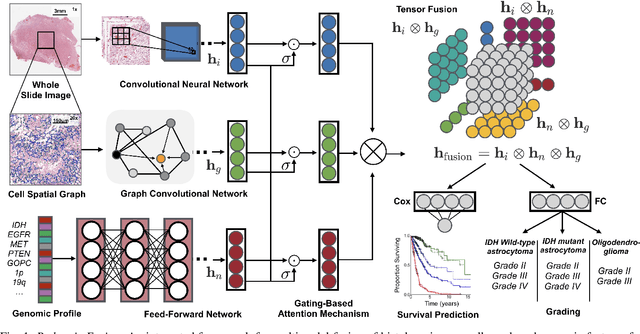
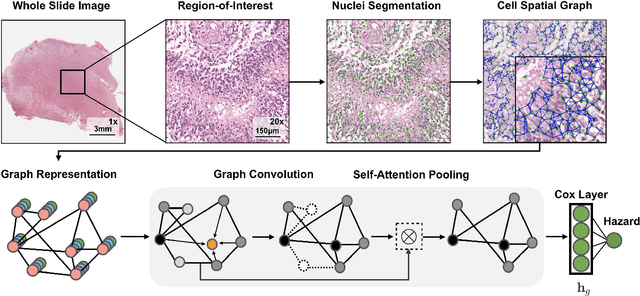
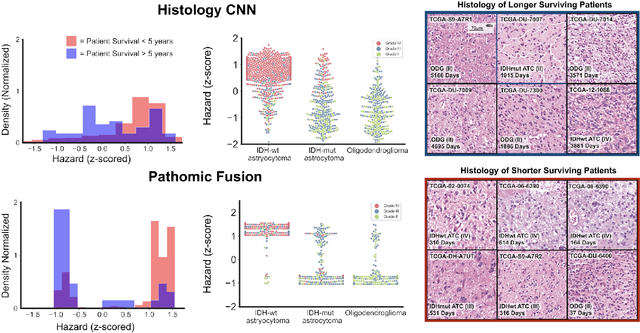
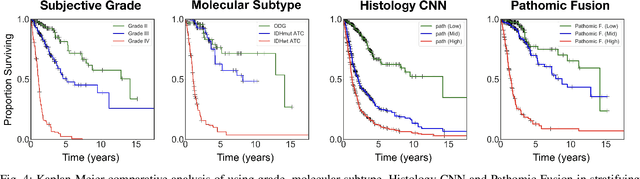
Cancer diagnosis, prognosis, and therapeutic response predictions are based on morphological information from histology slides and molecular profiles from genomic data. However, most deep learning-based objective outcome prediction and grading paradigms are based on histology or genomics alone and do not make use of the complementary information in an intuitive manner. In this work, we propose Pathomic Fusion, a strategy for end-to-end multimodal fusion of histology image and genomic (mutations, CNV, mRNAseq) features for survival outcome prediction. Our approach models pairwise feature interactions across modalities by taking the Kronecker product of gated feature representations and controls the expressiveness of each representation via a gating-based attention mechanism. The proposed framework is able to model pairwise interactions across features in different modalities and control their relative importance. We validate our approach using glioma datasets from the Cancer Genome Atlas (TCGA), which contains paired whole-slide image, genotype, and transcriptome data with ground truth survival and histologic grade labels. Based on a rigorous 15-fold cross-validation, our results demonstrate that the proposed multimodal fusion paradigm improves prognostic determinations from grading and molecular subtyping as well as unimodal deep networks trained on histology and genomic data alone. The proposed method establishes insight and theory on how to train deep networks on multimodal biomedical data in an intuitive manner, which will be useful for other problems in medicine that seek to combine heterogeneous data streams for understanding diseases and predicting response and resistance to treatment.
Weakly Supervised Prostate TMA Classification via Graph Convolutional Networks
Nov 06, 2019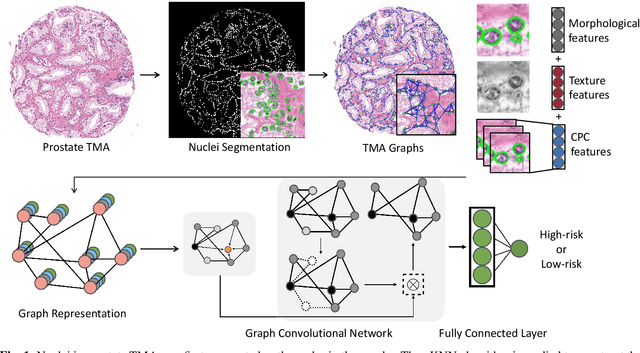

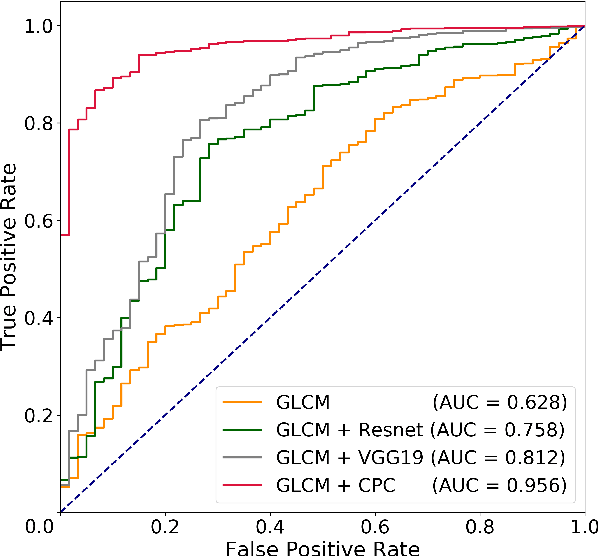
Histology-based grade classification is clinically important for many cancer types in stratifying patients distinct treatment groups. In prostate cancer, the Gleason score is a grading system used to measure the aggressiveness of prostate cancer from the spatial organization of cells and the distribution of glands. However, the subjective interpretation of Gleason score often suffers from large interobserver and intraobserver variability. Previous work in deep learning-based objective Gleason grading requires manual pixel-level annotation. In this work, we propose a weakly-supervised approach for grade classification in tissue micro-arrays (TMA) using graph convolutional networks (GCNs), in which we model the spatial organization of cells as a graph to better capture the proliferation and community structure of tumor cells. As node-level features in our graph representation, we learn the morphometry of each cell using a contrastive predictive coding (CPC)-based self-supervised approach. We demonstrate that on a five-fold cross validation our method can achieve $0.9659\pm0.0096$ AUC using only TMA-level labels. Our method demonstrates a 39.80\% improvement over standard GCNs with texture features and a 29.27% improvement over GCNs with VGG19 features. Our proposed pipeline can be used to objectively stratify low and high risk cases, reducing inter- and intra-observer variability and pathologist workload.
Semi-Supervised Histology Classification using Deep Multiple Instance Learning and Contrastive Predictive Coding
Nov 02, 2019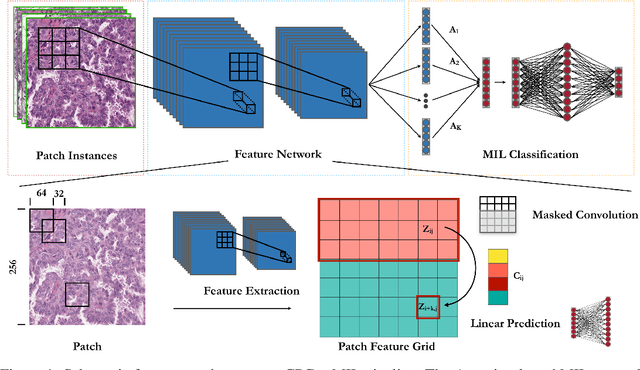

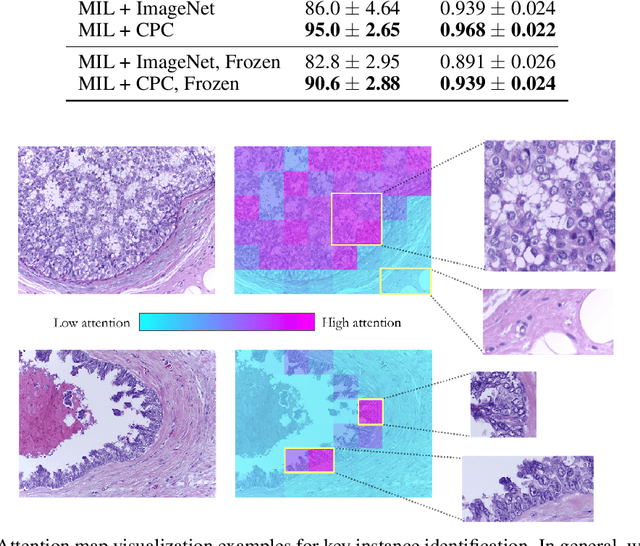
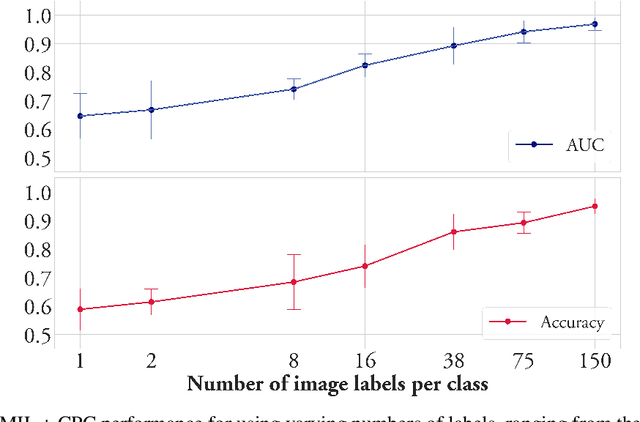
Convolutional neural networks can be trained to perform histology slide classification using weak annotations with multiple instance learning (MIL). However, given the paucity of labeled histology data, direct application of MIL can easily suffer from overfitting and the network is unable to learn rich feature representations due to the weak supervisory signal. We propose to overcome such limitations with a two-stage semi-supervised approach that combines the power of data-efficient self-supervised feature learning via contrastive predictive coding (CPC) and the interpretability and flexibility of regularized attention-based MIL. We apply our two-stage CPC + MIL semi-supervised pipeline to the binary classification of breast cancer histology images. Across five random splits, we report state-of-the-art performance with a mean validation accuracy of 95% and an area under the ROC curve of 0.968. We further evaluate the quality of features learned via CPC relative to simple transfer learning and show that strong classification performance using CPC features can be efficiently leveraged under the MIL framework even with the feature encoder frozen.
Semantic Conditioned Dynamic Modulation for Temporal Sentence Grounding in Videos
Oct 31, 2019
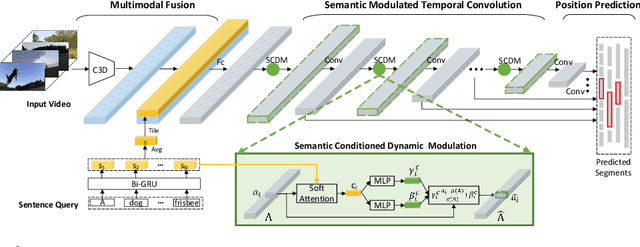
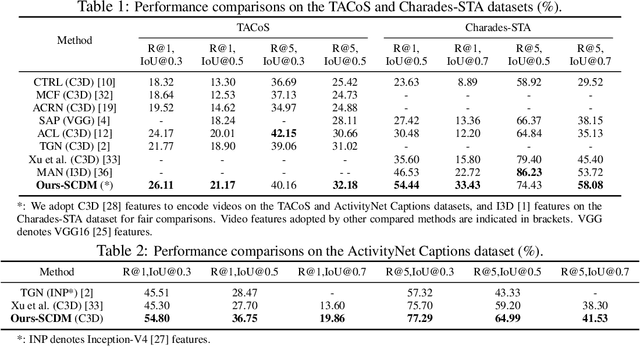
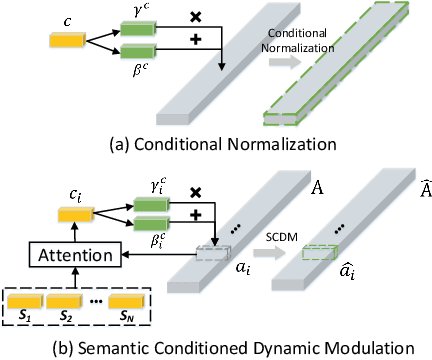
Temporal sentence grounding in videos aims to detect and localize one target video segment, which semantically corresponds to a given sentence. Existing methods mainly tackle this task via matching and aligning semantics between a sentence and candidate video segments, while neglect the fact that the sentence information plays an important role in temporally correlating and composing the described contents in videos. In this paper, we propose a novel semantic conditioned dynamic modulation (SCDM) mechanism, which relies on the sentence semantics to modulate the temporal convolution operations for better correlating and composing the sentence related video contents over time. More importantly, the proposed SCDM performs dynamically with respect to the diverse video contents so as to establish a more precise matching relationship between sentence and video, thereby improving the temporal grounding accuracy. Extensive experiments on three public datasets demonstrate that our proposed model outperforms the state-of-the-arts with clear margins, illustrating the ability of SCDM to better associate and localize relevant video contents for temporal sentence grounding. Our code for this paper is available at https://github.com/yytzsy/SCDM .
Temporally Grounding Language Queries in Videos by Contextual Boundary-aware Prediction
Sep 11, 2019
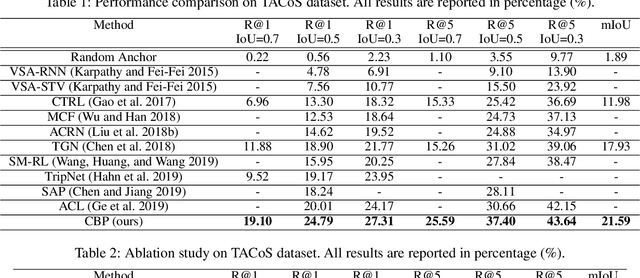
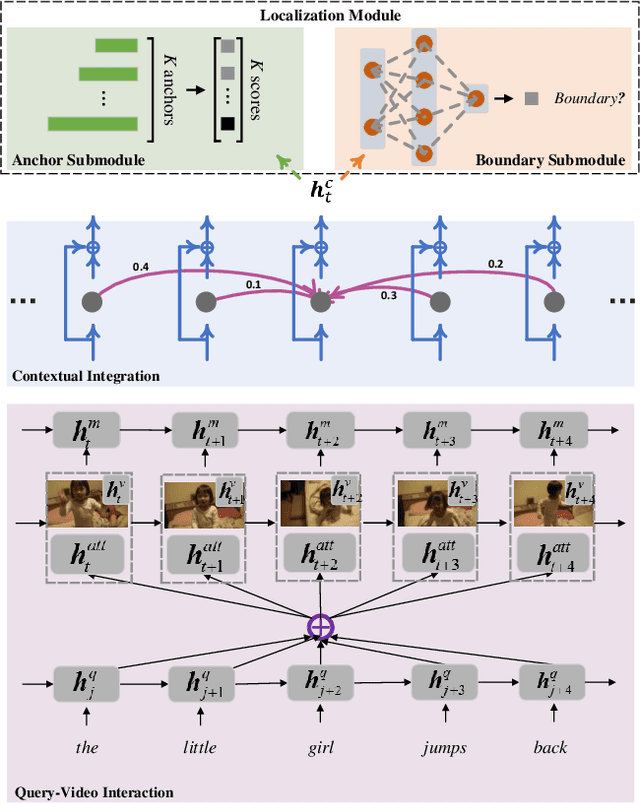
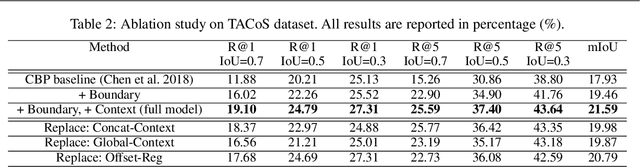
The task of temporally grounding language queries in videos is to temporally localize the best matched video segment corresponding to a given language (sentence). It requires certain models to simultaneously perform visual and linguistic understandings. Previous work predominantly ignores the precision of segment localization. Sliding window based methods use predefined search window sizes, which suffer from redundant computation, while existing anchor-based approaches fail to yield precise localization. We address this issue by proposing an end-to-end boundary-aware model, which uses a lightweight branch to predict semantic boundaries corresponding to the given linguistic information. To better detect semantic boundaries, we propose to aggregate contextual information by explicitly modeling the relationship between the current element and its neighbors. The most confident segments are subsequently selected based on both anchor and boundary predictions at the testing stage. The proposed model, dubbed Contextual Boundary-aware Prediction (CBP), outperforms its competitors with a clear margin on three public datasets.
Controllable Video Captioning with POS Sequence Guidance Based on Gated Fusion Network
Aug 27, 2019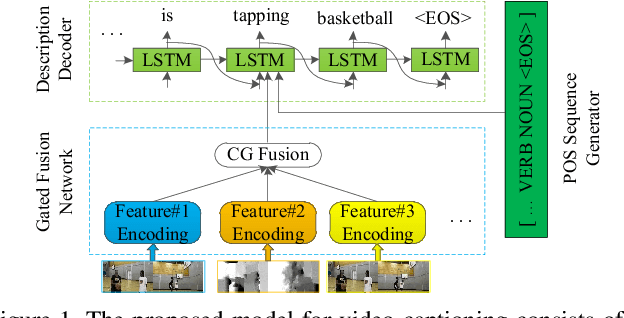
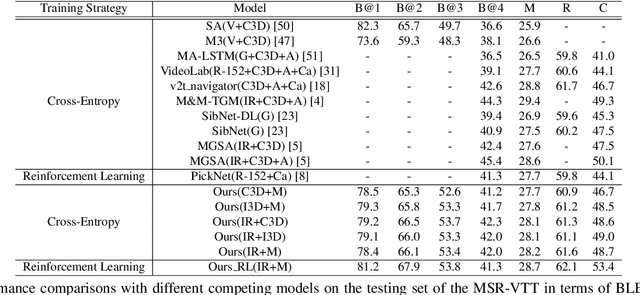
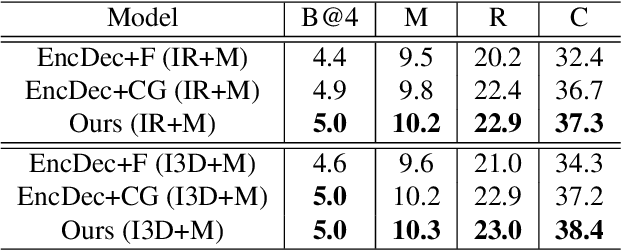
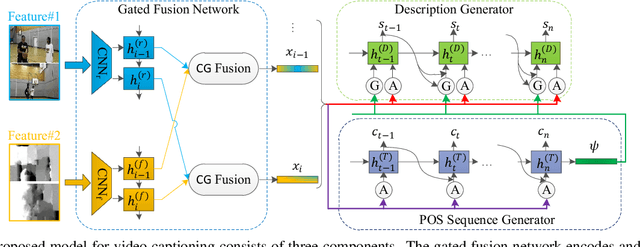
In this paper, we propose to guide the video caption generation with Part-of-Speech (POS) information, based on a gated fusion of multiple representations of input videos. We construct a novel gated fusion network, with one particularly designed cross-gating (CG) block, to effectively encode and fuse different types of representations, e.g., the motion and content features of an input video. One POS sequence generator relies on this fused representation to predict the global syntactic structure, which is thereafter leveraged to guide the video captioning generation and control the syntax of the generated sentence. Specifically, a gating strategy is proposed to dynamically and adaptively incorporate the global syntactic POS information into the decoder for generating each word. Experimental results on two benchmark datasets, namely MSR-VTT and MSVD, demonstrate that the proposed model can well exploit complementary information from multiple representations, resulting in improved performances. Moreover, the generated global POS information can well capture the global syntactic structure of the sentence, and thus be exploited to control the syntactic structure of the description. Such POS information not only boosts the video captioning performance but also improves the diversity of the generated captions. Our code is at: https://github.com/vsislab/Controllable_XGating.
Generating an Overview Report over Many Documents
Aug 17, 2019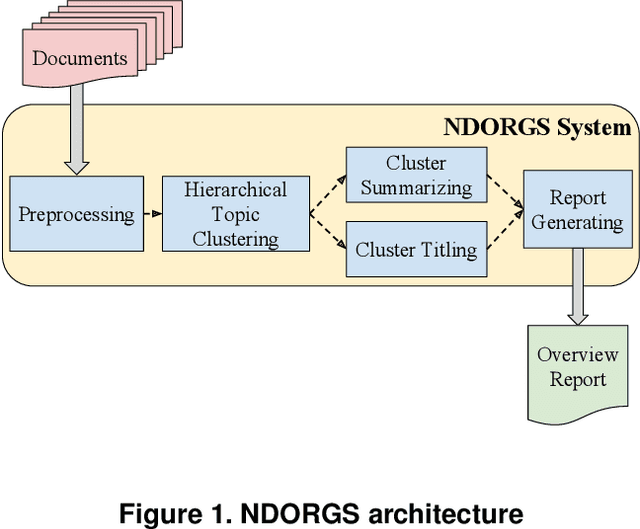
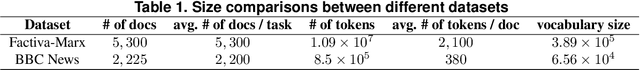
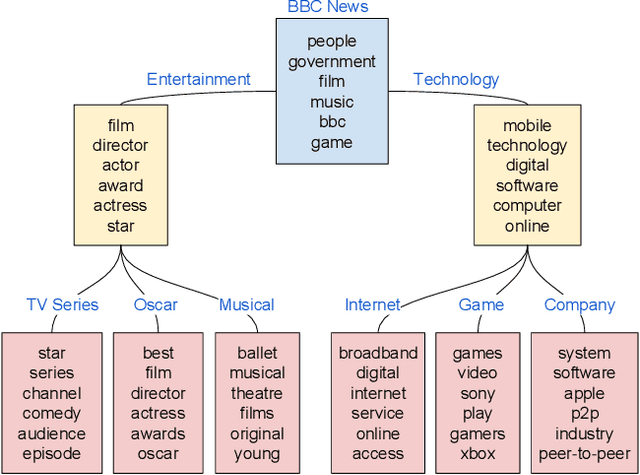

How to efficiently generate an accurate, well-structured overview report (ORPT) over thousands of related documents is challenging. A well-structured ORPT consists of sections of multiple levels (e.g., sections and subsections). None of the existing multi-document summarization (MDS) algorithms is directed toward this task. To overcome this obstacle, we present NDORGS (Numerous Documents' Overview Report Generation Scheme) that integrates text filtering, keyword scoring, single-document summarization (SDS), topic modeling, MDS, and title generation to generate a coherent, well-structured ORPT. We then devise a multi-criteria evaluation method using techniques of text mining and multi-attribute decision making on a combination of human judgments, running time, information coverage, and topic diversity. We evaluate ORPTs generated by NDORGS on two large corpora of documents, where one is classified and the other unclassified. We show that, using Saaty's pairwise comparison 9-point scale and under TOPSIS, the ORPTs generated on SDS's with the length of 20% of the original documents are the best overall on both datasets.