 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Tree Explanation Methods for Anomaly Reasoning: A Case Study of SHAP TreeExplainer and TreeInterpreter
Oct 13, 2020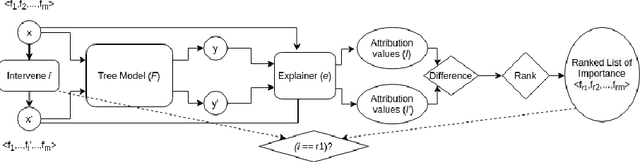
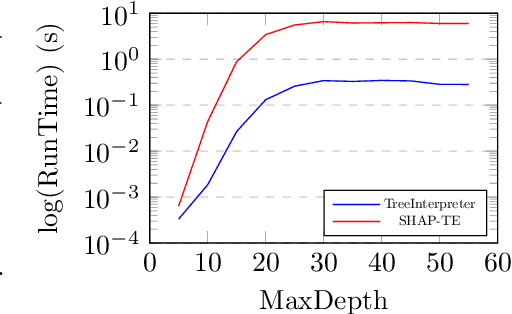
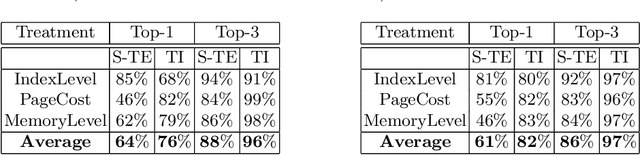
Understanding predictions made by Machine Learning models is critical in many applications. In this work, we investigate the performance of two methods for explaining tree-based models- Tree Interpreter (TI) and SHapley Additive exPlanations TreeExplainer (SHAP-TE). Using a case study on detecting anomalies in job runtimes of applications that utilize cloud-computing platforms, we compare these approaches using a variety of metrics, including computation time, significance of attribution value, and explanation accuracy. We find that, although the SHAP-TE offers consistency guarantees over TI, at the cost of increased computation, consistency does not necessarily improve the explanation performance in our case study.
Examination and Extension of Strategies for Improving Personalized Language Modeling via Interpolation
Jun 09, 2020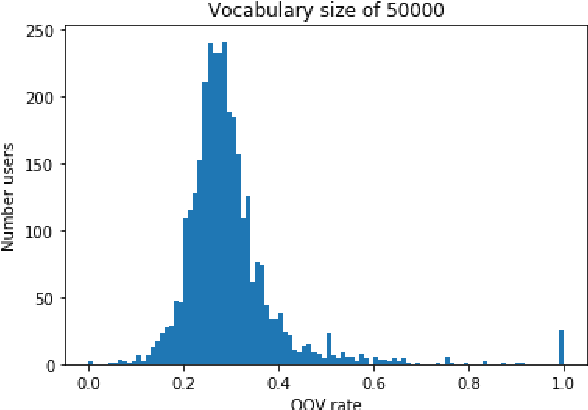
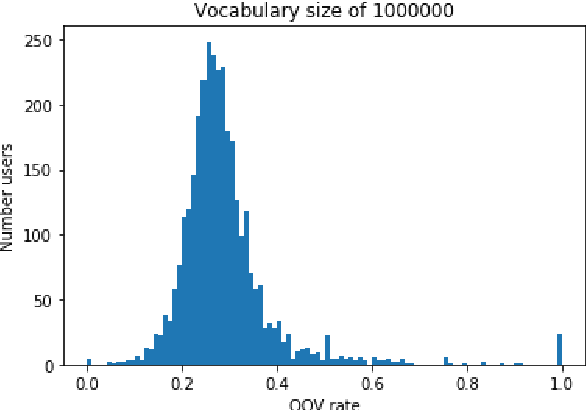
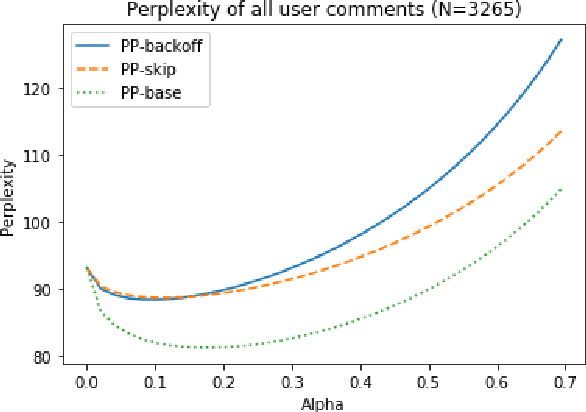
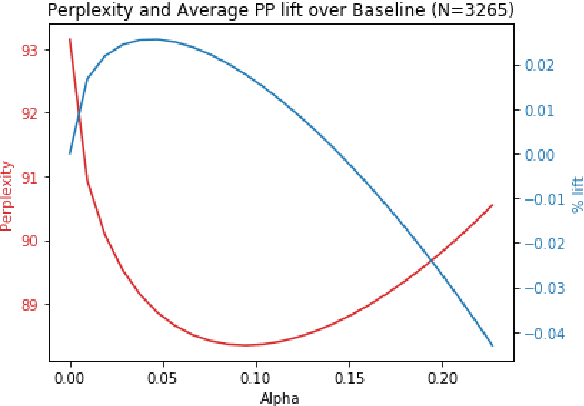
In this paper, we detail novel strategies for interpolating personalized language models and methods to handle out-of-vocabulary (OOV) tokens to improve personalized language models. Using publicly available data from Reddit, we demonstrate improvements in offline metrics at the user level by interpolating a global LSTM-based authoring model with a user-personalized n-gram model. By optimizing this approach with a back-off to uniform OOV penalty and the interpolation coefficient, we observe that over 80% of users receive a lift in perplexity, with an average of 5.2% in perplexity lift per user. In doing this research we extend previous work in building NLIs and improve the robustness of metrics for downstream tasks.
Griffon: Reasoning about Job Anomalies with Unlabeled Data in Cloud-based Platforms
Aug 23, 2019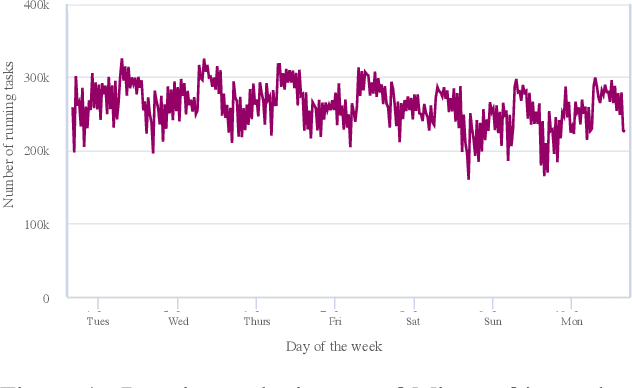

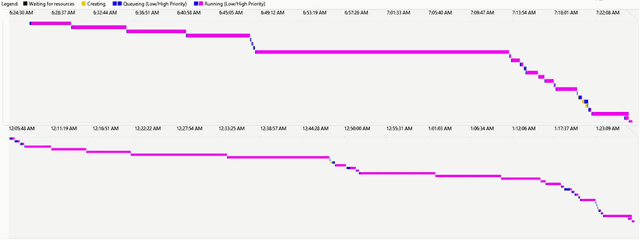
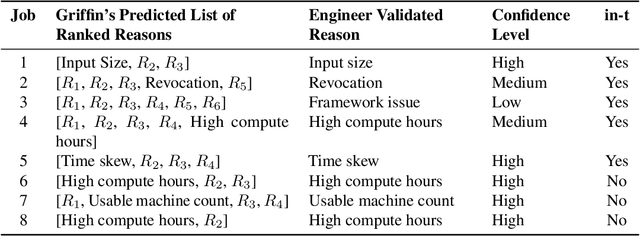
Microsoft's internal big data analytics platform is comprised of hundreds of thousands of machines, serving over half a million jobs daily, from thousands of users. The majority of these jobs are recurring and are crucial for the company's operation. Although administrators spend significant effort tuning system performance, some jobs inevitably experience slowdowns, i.e., their execution time degrades over previous runs. Currently, the investigation of such slowdowns is a labor-intensive and error-prone process, which costs Microsoft significant human and machine resources, and negatively impacts several lines of businesses. In this work, we present Griffin, a system we built and have deployed in production last year to automatically discover the root cause of job slowdowns. Existing solutions either rely on labeled data (i.e., resolved incidents with labeled reasons for job slowdowns), which is in most cases non-existent or non-trivial to acquire, or on time-series analysis of individual metrics that do not target specific jobs holistically. In contrast, in Griffin we cast the problem to a corresponding regression one that predicts the runtime of a job, and show how the relative contributions of the features used to train our interpretable model can be exploited to rank the potential causes of job slowdowns. Evaluated over historical incidents, we show that Griffin discovers slowdown causes that are consistent with the ones validated by domain-expert engineers, in a fraction of the time required by them.
Generating an Overview Report over Many Documents
Aug 17, 2019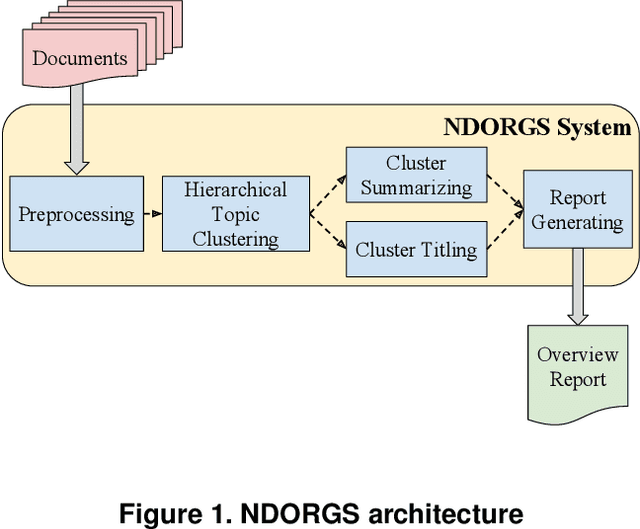
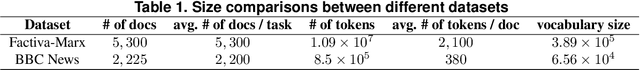
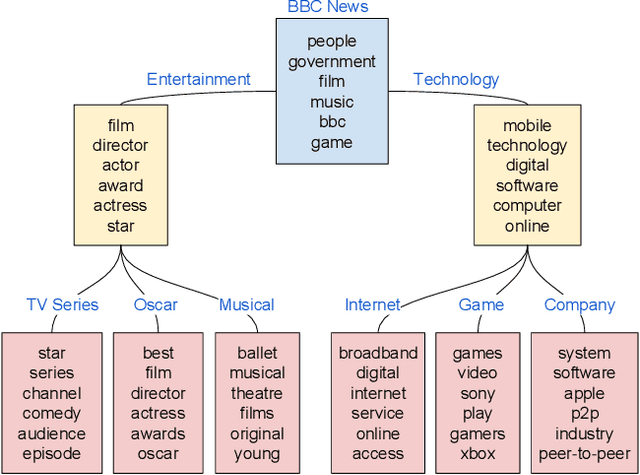

How to efficiently generate an accurate, well-structured overview report (ORPT) over thousands of related documents is challenging. A well-structured ORPT consists of sections of multiple levels (e.g., sections and subsections). None of the existing multi-document summarization (MDS) algorithms is directed toward this task. To overcome this obstacle, we present NDORGS (Numerous Documents' Overview Report Generation Scheme) that integrates text filtering, keyword scoring, single-document summarization (SDS), topic modeling, MDS, and title generation to generate a coherent, well-structured ORPT. We then devise a multi-criteria evaluation method using techniques of text mining and multi-attribute decision making on a combination of human judgments, running time, information coverage, and topic diversity. We evaluate ORPTs generated by NDORGS on two large corpora of documents, where one is classified and the other unclassified. We show that, using Saaty's pairwise comparison 9-point scale and under TOPSIS, the ORPTs generated on SDS's with the length of 20% of the original documents are the best overall on both datasets.
DTATG: An Automatic Title Generator based on Dependency Trees
Oct 01, 2017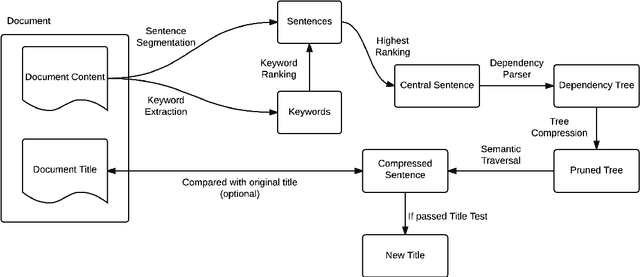
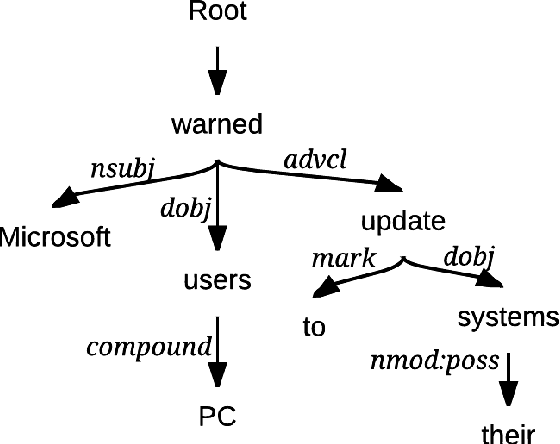
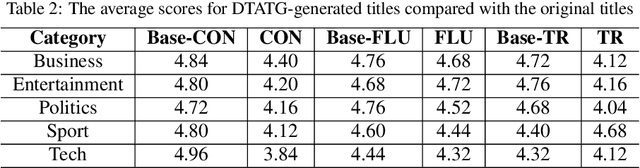
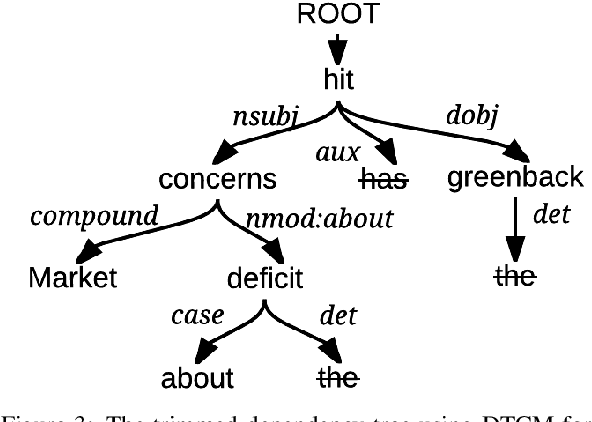
We study automatic title generation for a given block of text and present a method called DTATG to generate titles. DTATG first extracts a small number of central sentences that convey the main meanings of the text and are in a suitable structure for conversion into a title. DTATG then constructs a dependency tree for each of these sentences and removes certain branches using a Dependency Tree Compression Model we devise. We also devise a title test to determine if a sentence can be used as a title. If a trimmed sentence passes the title test, then it becomes a title candidate. DTATG selects the title candidate with the highest ranking score as the final title. Our experiments showed that DTATG can generate adequate titles. We also showed that DTATG-generated titles have higher F1 scores than those generated by the previous methods.
Efficient and Effective Single-Document Summarizations and A Word-Embedding Measurement of Quality
Oct 01, 2017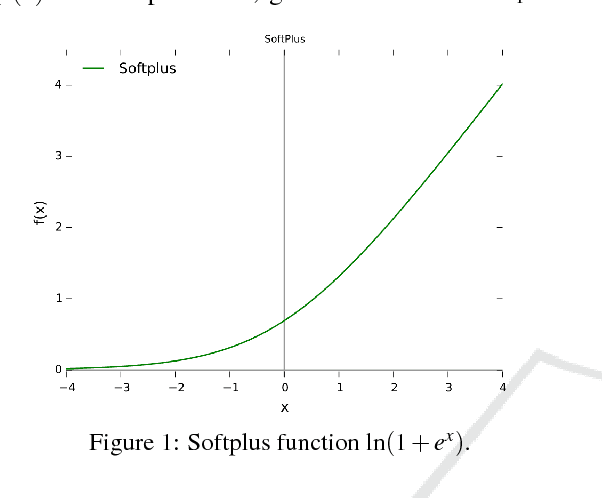
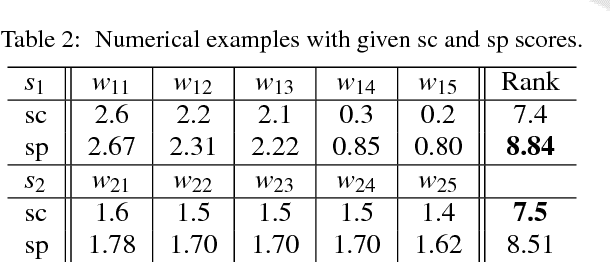


Our task is to generate an effective summary for a given document with specific realtime requirements. We use the softplus function to enhance keyword rankings to favor important sentences, based on which we present a number of summarization algorithms using various keyword extraction and topic clustering methods. We show that our algorithms meet the realtime requirements and yield the best ROUGE recall scores on DUC-02 over all previously-known algorithms. We show that our algorithms meet the realtime requirements and yield the best ROUGE recall scores on DUC-02 over all previously-known algorithms. To evaluate the quality of summaries without human-generated benchmarks, we define a measure called WESM based on word-embedding using Word Mover's Distance. We show that the orderings of the ROUGE and WESM scores of our algorithms are highly comparable, suggesting that WESM may serve as a viable alternative for measuring the quality of a summary.