 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive-O3: Empowering Multimodal Large Language Models with Active Perception via GRPO
May 27, 2025Active vision, also known as active perception, refers to the process of actively selecting where and how to look in order to gather task-relevant information. It is a critical component of efficient perception and decision-making in humans and advanced embodied agents. Recently, the use of Multimodal Large Language Models (MLLMs) as central planning and decision-making modules in robotic systems has gained extensive attention. However, despite the importance of active perception in embodied intelligence, there is little to no exploration of how MLLMs can be equipped with or learn active perception capabilities. In this paper, we first provide a systematic definition of MLLM-based active perception tasks. We point out that the recently proposed GPT-o3 model's zoom-in search strategy can be regarded as a special case of active perception; however, it still suffers from low search efficiency and inaccurate region selection. To address these issues, we propose ACTIVE-O3, a purely reinforcement learning based training framework built on top of GRPO, designed to equip MLLMs with active perception capabilities. We further establish a comprehensive benchmark suite to evaluate ACTIVE-O3 across both general open-world tasks, such as small-object and dense object grounding, and domain-specific scenarios, including small object detection in remote sensing and autonomous driving, as well as fine-grained interactive segmentation. In addition, ACTIVE-O3 also demonstrates strong zero-shot reasoning abilities on the V* Benchmark, without relying on any explicit reasoning data. We hope that our work can provide a simple codebase and evaluation protocol to facilitate future research on active perception in MLLMs.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025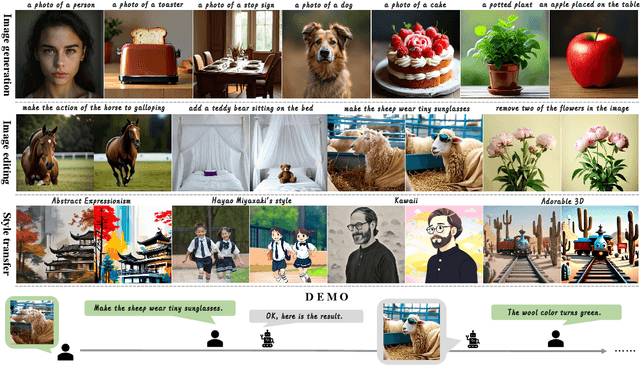

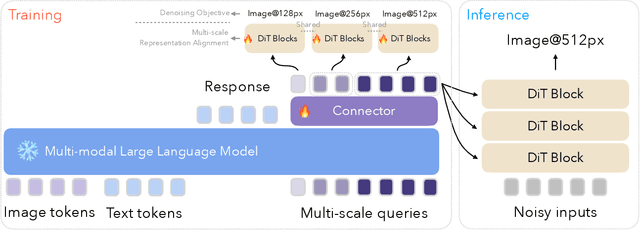
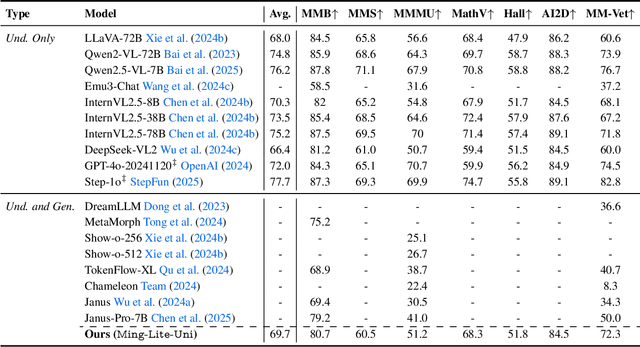
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
Determined blind source separation via modeling adjacent frequency band correlations in speech signals
Apr 05, 2025Multichannel blind source separation (MBSS), which focuses on separating signals of interest from mixed observations, has been extensively studied in acoustic and speech processing. Existing MBSS algorithms, such as independent low-rank matrix analysis (ILRMA) and multichannel nonnegative matrix factorization (MNMF), utilize the low-rank structure of source models but assume that frequency bins are independent. In contrast, independent vector analysis (IVA) does not rely on a low-rank source model but rather captures frequency dependencies based on a uniform correlation assumption. In this work, we demonstrate that dependencies between adjacent frequency bins are significantly stronger than those between bins that are farther apart in typical speech signals. To address this, we introduce a weighted Sinkhorn divergence-based ILRMA (wsILRMA) that simultaneously captures these inter-frequency dependencies and models joint probability distributions. Our approach incorporates an inter-frequency correlation constraint, leading to improved source separation performance compared to existing methods, as evidenced by higher Signal-to-Distortion Ratios (SDRs) and Source-to-Interference Ratios (SIRs).
Spatial-Filter-Bank-Based Neural Method for Multichannel Speech Enhancement
Apr 02, 2025The performance of deep learning-based multi-channel speech enhancement methods often deteriorates when the geometric parameters of the microphone array change. Traditional approaches to mitigate this issue typically involve training on multiple microphone arrays, which can be costly. To address this challenge, we focus on uniform circular arrays and propose the use of a spatial filter bank to extract features that are approximately invariant to geometric parameters. These features are then processed by a two-stage conformer-based model (TSCBM) to enhance speech quality. Experimental results demonstrate that our proposed method can be trained on a fixed microphone array while maintaining effective performance across uniform circular arrays with unseen geometric configurations during applications.
When Large Vision-Language Model Meets Large Remote Sensing Imagery: Coarse-to-Fine Text-Guided Token Pruning
Mar 10, 2025Efficient vision-language understanding of large Remote Sensing Images (RSIs) is meaningful but challenging. Current Large Vision-Language Models (LVLMs) typically employ limited pre-defined grids to process images, leading to information loss when handling gigapixel RSIs. Conversely, using unlimited grids significantly increases computational costs. To preserve image details while reducing computational complexity, we propose a text-guided token pruning method with Dynamic Image Pyramid (DIP) integration. Our method introduces: (i) a Region Focus Module (RFM) that leverages text-aware region localization capability to identify critical vision tokens, and (ii) a coarse-to-fine image tile selection and vision token pruning strategy based on DIP, which is guided by RFM outputs and avoids directly processing the entire large imagery. Additionally, existing benchmarks for evaluating LVLMs' perception ability on large RSI suffer from limited question diversity and constrained image sizes. We construct a new benchmark named LRS-VQA, which contains 7,333 QA pairs across 8 categories, with image length up to 27,328 pixels. Our method outperforms existing high-resolution strategies on four datasets using the same data. Moreover, compared to existing token reduction methods, our approach demonstrates higher efficiency under high-resolution settings. Dataset and code are in https://github.com/VisionXLab/LRS-VQA.
Joint Tensor and Inter-View Low-Rank Recovery for Incomplete Multiview Clustering
Mar 04, 2025



Incomplete multiview clustering (IMVC) has gained significant attention for its effectiveness in handling missing sample challenges across various views in real-world multiview clustering applications. Most IMVC approaches tackle this problem by either learning consensus representations from available views or reconstructing missing samples using the underlying manifold structure. However, the reconstruction of learned similarity graph tensor in prior studies only exploits the low-tubal-rank information, neglecting the exploration of inter-view correlations. This paper propose a novel joint tensor and inter-view low-rank Recovery (JTIV-LRR), framing IMVC as a joint optimization problem that integrates incomplete similarity graph learning and tensor representation recovery. By leveraging both intra-view and inter-view low rank information, the method achieves robust estimation of the complete similarity graph tensor through sparse noise removal and low-tubal-rank constraints along different modes. Extensive experiments on both synthetic and real-world datasets demonstrate the superiority of the proposed approach, achieving significant improvements in clustering accuracy and robustness compared to state-of-the-art methods.
M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Feb 26, 2025We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.
Determined Blind Source Separation with Sinkhorn Divergence-based Optimal Allocation of the Source Power
Feb 25, 2025



Blind source separation (BSS) refers to the process of recovering multiple source signals from observations recorded by an array of sensors. Common approaches to BSS, including independent vector analysis (IVA), and independent low-rank matrix analysis (ILRMA), typically rely on second-order models to capture the statistical independence of source signals for separation. However, these methods generally do not account for the implicit structural information across frequency bands, which may lead to model mismatches between the assumed source distributions and the distributions of the separated source signals estimated from the observed mixtures. To tackle these limitations, this paper shows that conventional approaches such as IVA and ILRMA can easily be leveraged by the Sinkhorn divergence, incorporating an optimal transport (OT) framework to adaptively correct source variance estimates. This allows for the recovery of the source distribution while modeling the inter-band signal dependence and reallocating source power across bands. As a result, enhanced versions of these algorithms are developed, integrating a Sinkhorn iterative scheme into their standard implementations. Extensive simulations demonstrate that the proposed methods consistently enhance BSS performance.
Advances in Microphone Array Processing and Multichannel Speech Enhancement
Feb 13, 2025This paper reviews pioneering works in microphone array processing and multichannel speech enhancement, highlighting historical achievements, technological evolution, commercialization aspects, and key challenges. It provides valuable insights into the progression and future direction of these areas. The paper examines foundational developments in microphone array design and optimization, showcasing innovations that improved sound acquisition and enhanced speech intelligibility in noisy and reverberant environments. It then introduces recent advancements and cutting-edge research in the field, particularly the integration of deep learning techniques such as all-neural beamformers. The paper also explores critical applications, discussing their evolution and current state-of-the-art technologies that significantly impact user experience. Finally, the paper outlines future research directions, identifying challenges and potential solutions that could drive further innovation in these fields. By providing a comprehensive overview and forward-looking perspective, this paper aims to inspire ongoing research and contribute to the sustained growth and development of microphone arrays and multichannel speech enhancement.
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Jan 23, 2025



With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model's ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.