 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimFair: A Unified Framework for Fairness-Aware Multi-Label Classification
Feb 22, 2023



Recent years have witnessed increasing concerns towards unfair decisions made by machine learning algorithms. To improve fairness in model decisions, various fairness notions have been proposed and many fairness-aware methods are developed. However, most of existing definitions and methods focus only on single-label classification. Fairness for multi-label classification, where each instance is associated with more than one labels, is still yet to establish. To fill this gap, we study fairness-aware multi-label classification in this paper. We start by extending Demographic Parity (DP) and Equalized Opportunity (EOp), two popular fairness notions, to multi-label classification scenarios. Through a systematic study, we show that on multi-label data, because of unevenly distributed labels, EOp usually fails to construct a reliable estimate on labels with few instances. We then propose a new framework named Similarity $s$-induced Fairness ($s_\gamma$-SimFair). This new framework utilizes data that have similar labels when estimating fairness on a particular label group for better stability, and can unify DP and EOp. Theoretical analysis and experimental results on real-world datasets together demonstrate the advantage of over existing methods $s_\gamma$-SimFair on multi-label classification tasks.
Multi-rater Prism: Learning self-calibrated medical image segmentation from multiple raters
Dec 01, 2022



In medical image segmentation, it is often necessary to collect opinions from multiple experts to make the final decision. This clinical routine helps to mitigate individual bias. But when data is multiply annotated, standard deep learning models are often not applicable. In this paper, we propose a novel neural network framework, called Multi-Rater Prism (MrPrism) to learn the medical image segmentation from multiple labels. Inspired by the iterative half-quadratic optimization, the proposed MrPrism will combine the multi-rater confidences assignment task and calibrated segmentation task in a recurrent manner. In this recurrent process, MrPrism can learn inter-observer variability taking into account the image semantic properties, and finally converges to a self-calibrated segmentation result reflecting the inter-observer agreement. Specifically, we propose Converging Prism (ConP) and Diverging Prism (DivP) to process the two tasks iteratively. ConP learns calibrated segmentation based on the multi-rater confidence maps estimated by DivP. DivP generates multi-rater confidence maps based on the segmentation masks estimated by ConP. The experimental results show that by recurrently running ConP and DivP, the two tasks can achieve mutual improvement. The final converged segmentation result of MrPrism outperforms state-of-the-art (SOTA) strategies on a wide range of medical image segmentation tasks.
Towards Reliable Item Sampling for Recommendation Evaluation
Nov 28, 2022



Since Rendle and Krichene argued that commonly used sampling-based evaluation metrics are ``inconsistent'' with respect to the global metrics (even in expectation), there have been a few studies on the sampling-based recommender system evaluation. Existing methods try either mapping the sampling-based metrics to their global counterparts or more generally, learning the empirical rank distribution to estimate the top-$K$ metrics. However, despite existing efforts, there is still a lack of rigorous theoretical understanding of the proposed metric estimators, and the basic item sampling also suffers from the ``blind spot'' issue, i.e., estimation accuracy to recover the top-$K$ metrics when $K$ is small can still be rather substantial. In this paper, we provide an in-depth investigation into these problems and make two innovative contributions. First, we propose a new item-sampling estimator that explicitly optimizes the error with respect to the ground truth, and theoretically highlight its subtle difference against prior work. Second, we propose a new adaptive sampling method which aims to deal with the ``blind spot'' problem and also demonstrate the expectation-maximization (EM) algorithm can be generalized for such a setting. Our experimental results confirm our statistical analysis and the superiority of the proposed works. This study helps lay the theoretical foundation for adopting item sampling metrics for recommendation evaluation, and provides strong evidence towards making item sampling a powerful and reliable tool for recommendation evaluation.
AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning
Nov 02, 2022



Standard fine-tuning of large pre-trained language models (PLMs) for downstream tasks requires updating hundreds of millions to billions of parameters, and storing a large copy of the PLM weights for every task resulting in increased cost for storing, sharing and serving the models. To address this, parameter-efficient fine-tuning (PEFT) techniques were introduced where small trainable components are injected in the PLM and updated during fine-tuning. We propose AdaMix as a general PEFT method that tunes a mixture of adaptation modules -- given the underlying PEFT method of choice -- introduced in each Transformer layer while keeping most of the PLM weights frozen. For instance, AdaMix can leverage a mixture of adapters like Houlsby or a mixture of low rank decomposition matrices like LoRA to improve downstream task performance over the corresponding PEFT methods for fully supervised and few-shot NLU and NLG tasks. Further, we design AdaMix such that it matches the same computational cost and the number of tunable parameters as the underlying PEFT method. By only tuning 0.1-0.2% of PLM parameters, we show that AdaMix outperforms SOTA parameter-efficient fine-tuning and full model fine-tuning for both NLU and NLG tasks.
Temporal Spatial Decomposition and Fusion Network for Time Series Forecasting
Oct 06, 2022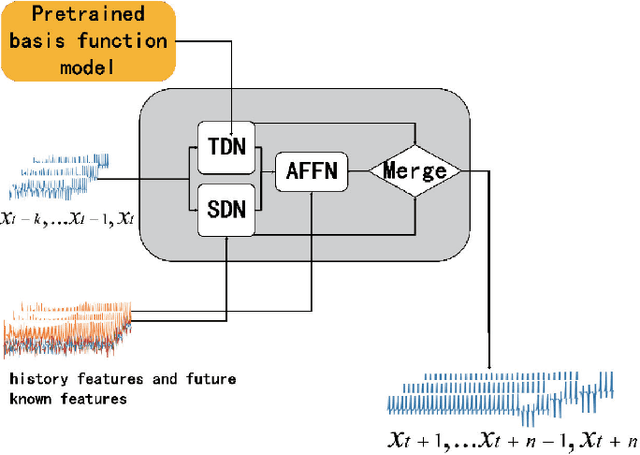
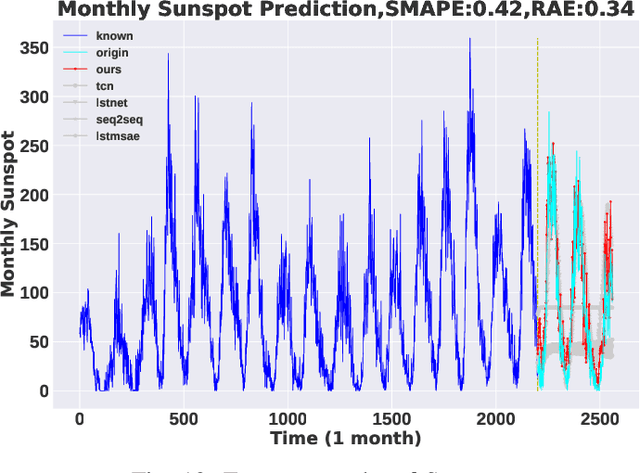
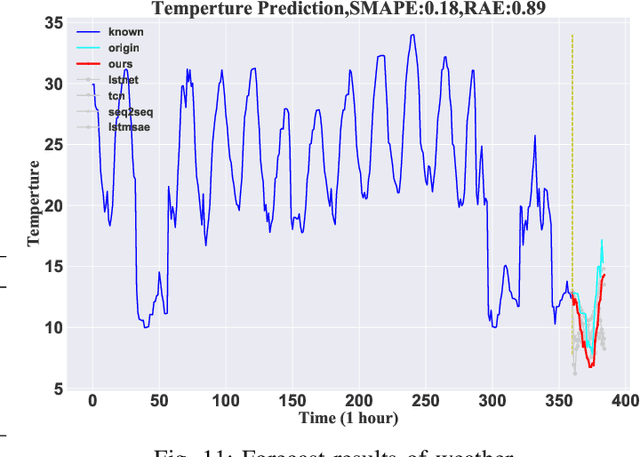
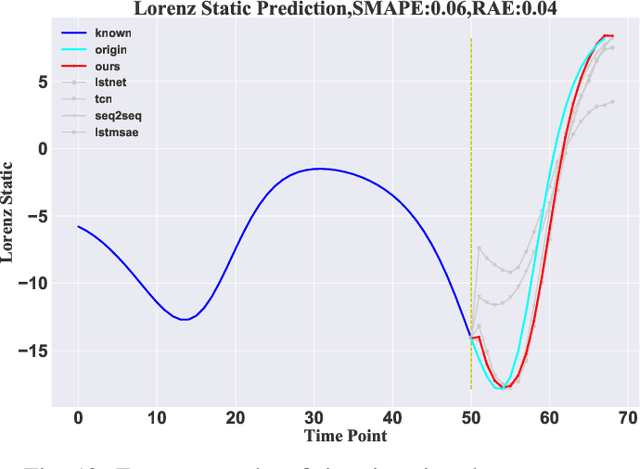
Feature engineering is required to obtain better results for time series forecasting, and decomposition is a crucial one. One decomposition approach often cannot be used for numerous forecasting tasks since the standard time series decomposition lacks flexibility and robustness. Traditional feature selection relies heavily on preexisting domain knowledge, has no generic methodology, and requires a lot of labor. However, most time series prediction models based on deep learning typically suffer from interpretability issue, so the "black box" results lead to a lack of confidence. To deal with the above issues forms the motivation of the thesis. In the paper we propose TSDFNet as a neural network with self-decomposition mechanism and an attentive feature fusion mechanism, It abandons feature engineering as a preprocessing convention and creatively integrates it as an internal module with the deep model. The self-decomposition mechanism empowers TSDFNet with extensible and adaptive decomposition capabilities for any time series, users can choose their own basis functions to decompose the sequence into temporal and generalized spatial dimensions. Attentive feature fusion mechanism has the ability to capture the importance of external variables and the causality with target variables. It can automatically suppress the unimportant features while enhancing the effective ones, so that users do not have to struggle with feature selection. Moreover, TSDFNet is easy to look into the "black box" of the deep neural network by feature visualization and analyze the prediction results. We demonstrate performance improvements over existing widely accepted models on more than a dozen datasets, and three experiments showcase the interpretability of TSDFNet.
An Efficient Person Clustering Algorithm for Open Checkout-free Groceries
Aug 05, 2022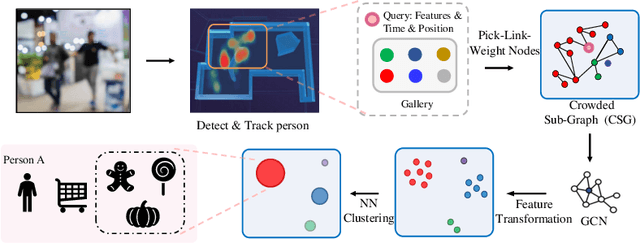

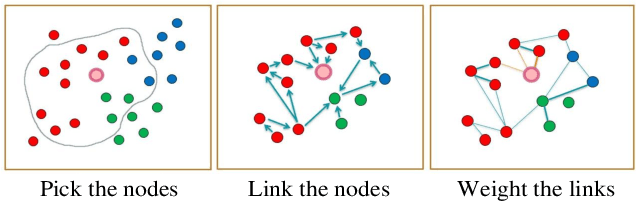
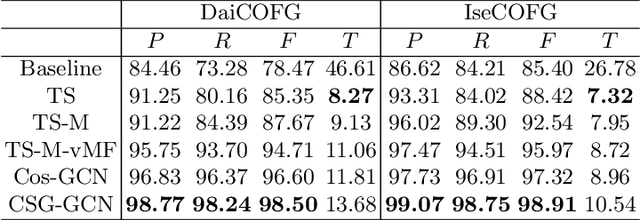
Open checkout-free grocery is the grocery store where the customers never have to wait in line to check out. Developing a system like this is not trivial since it faces challenges of recognizing the dynamic and massive flow of people. In particular, a clustering method that can efficiently assign each snapshot to the corresponding customer is essential for the system. In order to address the unique challenges in the open checkout-free grocery, we propose an efficient and effective person clustering method. Specifically, we first propose a Crowded Sub-Graph (CSG) to localize the relationship among massive and continuous data streams. CSG is constructed by the proposed Pick-Link-Weight (PLW) strategy, which \textbf{picks} the nodes based on time-space information, \textbf{links} the nodes via trajectory information, and \textbf{weighs} the links by the proposed von Mises-Fisher (vMF) similarity metric. Then, to ensure that the method adapts to the dynamic and unseen person flow, we propose Graph Convolutional Network (GCN) with a simple Nearest Neighbor (NN) strategy to accurately cluster the instances of CSG. GCN is adopted to project the features into low-dimensional separable space, and NN is able to quickly produce a result in this space upon dynamic person flow. The experimental results show that the proposed method outperforms other alternative algorithms in this scenario. In practice, the whole system has been implemented and deployed in several real-world open checkout-free groceries.
SeATrans: Learning Segmentation-Assisted diagnosis model via Transformer
Jun 22, 2022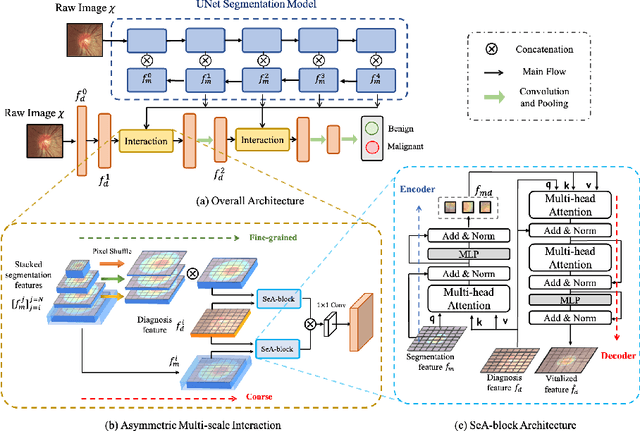
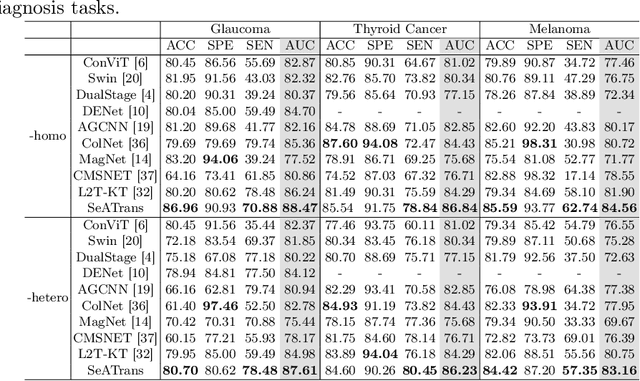
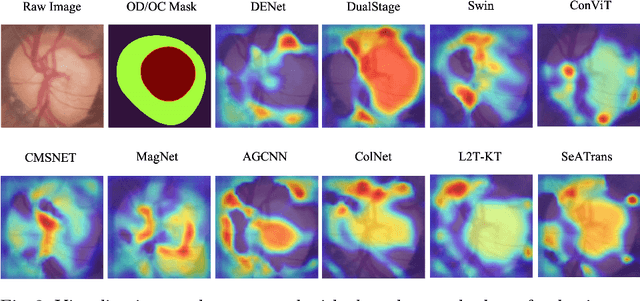
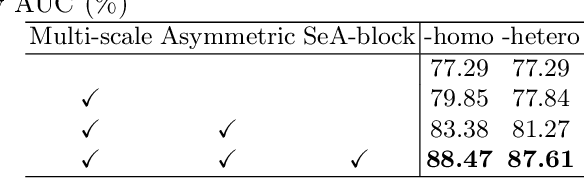
Clinically, the accurate annotation of lesions/tissues can significantly facilitate the disease diagnosis. For example, the segmentation of optic disc/cup (OD/OC) on fundus image would facilitate the glaucoma diagnosis, the segmentation of skin lesions on dermoscopic images is helpful to the melanoma diagnosis, etc. With the advancement of deep learning techniques, a wide range of methods proved the lesions/tissues segmentation can also facilitate the automated disease diagnosis models. However, existing methods are limited in the sense that they can only capture static regional correlations in the images. Inspired by the global and dynamic nature of Vision Transformer, in this paper, we propose Segmentation-Assisted diagnosis Transformer (SeATrans) to transfer the segmentation knowledge to the disease diagnosis network. Specifically, we first propose an asymmetric multi-scale interaction strategy to correlate each single low-level diagnosis feature with multi-scale segmentation features. Then, an effective strategy called SeA-block is adopted to vitalize diagnosis feature via correlated segmentation features. To model the segmentation-diagnosis interaction, SeA-block first embeds the diagnosis feature based on the segmentation information via the encoder, and then transfers the embedding back to the diagnosis feature space by a decoder. Experimental results demonstrate that SeATrans surpasses a wide range of state-of-the-art (SOTA) segmentation-assisted diagnosis methods on several disease diagnosis tasks.
AdaMix: Mixture-of-Adapter for Parameter-efficient Tuning of Large Language Models
May 24, 2022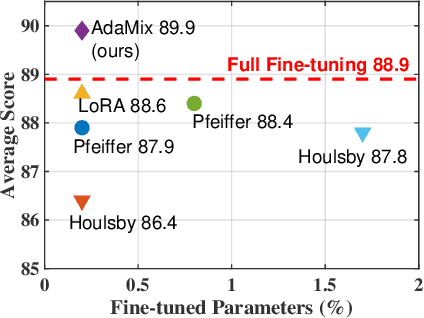
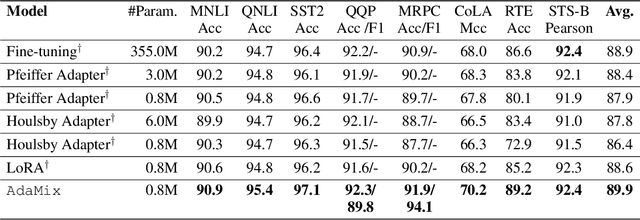
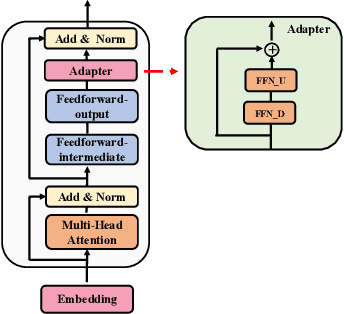
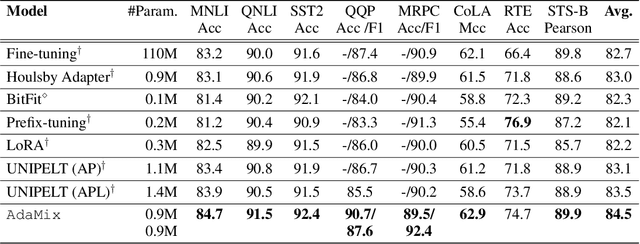
Fine-tuning large-scale pre-trained language models to downstream tasks require updating hundreds of millions of parameters. This not only increases the serving cost to store a large copy of the model weights for every task, but also exhibits instability during few-shot task adaptation. Parameter-efficient techniques have been developed that tune small trainable components (e.g., adapters) injected in the large model while keeping most of the model weights frozen. The prevalent mechanism to increase adapter capacity is to increase the bottleneck dimension which increases the adapter parameters. In this work, we introduce a new mechanism to improve adapter capacity without increasing parameters or computational cost by two key techniques. (i) We introduce multiple shared adapter components in each layer of the Transformer architecture. We leverage sparse learning via random routing to update the adapter parameters (encoder is kept frozen) resulting in the same amount of computational cost (FLOPs) as that of training a single adapter. (ii) We propose a simple merging mechanism to average the weights of multiple adapter components to collapse to a single adapter in each Transformer layer, thereby, keeping the overall parameters also the same but with significant performance improvement. We demonstrate these techniques to work well across multiple task settings including fully supervised and few-shot Natural Language Understanding tasks. By only tuning 0.23% of a pre-trained language model's parameters, our model outperforms the full model fine-tuning performance and several competing methods.
Label a Herd in Minutes: Individual Holstein-Friesian Cattle Identification
Apr 22, 2022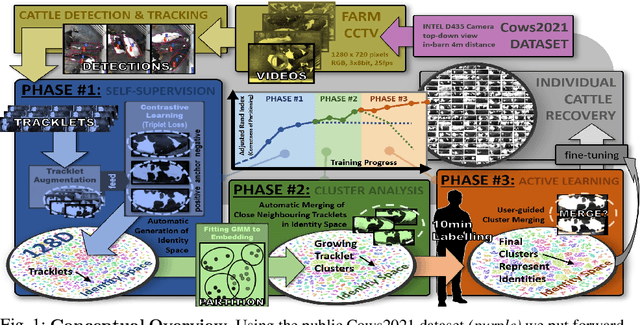


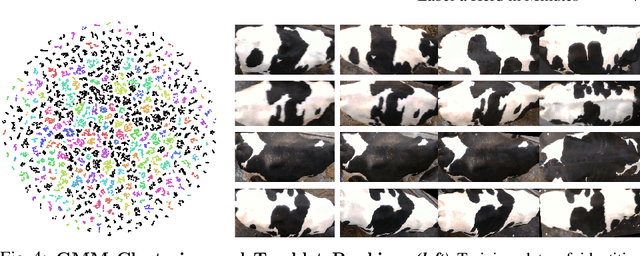
We describe a practically evaluated approach for training visual cattle ID systems for a whole farm requiring only ten minutes of labelling effort. In particular, for the task of automatic identification of individual Holstein-Friesians in real-world farm CCTV, we show that self-supervision, metric learning, cluster analysis, and active learning can complement each other to significantly reduce the annotation requirements usually needed to train cattle identification frameworks. Evaluating the approach on the test portion of the publicly available Cows2021 dataset, for training we use 23,350 frames across 435 single individual tracklets generated by automated oriented cattle detection and tracking in operational farm footage. Self-supervised metric learning is first employed to initialise a candidate identity space where each tracklet is considered a distinct entity. Grouping entities into equivalence classes representing cattle identities is then performed by automated merging via cluster analysis and active learning. Critically, we identify the inflection point at which automated choices cannot replicate improvements based on human intervention to reduce annotation to a minimum. Experimental results show that cluster analysis and a few minutes of labelling after automated self-supervision can improve the test identification accuracy of 153 identities to 92.44% (ARI=0.93) from the 74.9% (ARI=0.754) obtained by self-supervision only. These promising results indicate that a tailored combination of human and machine reasoning in visual cattle ID pipelines can be highly effective whilst requiring only minimal labelling effort. We provide all key source code and network weights with this paper for easy result reproduction.
CNN LEGO: Disassembling and Assembling Convolutional Neural Network
Mar 25, 2022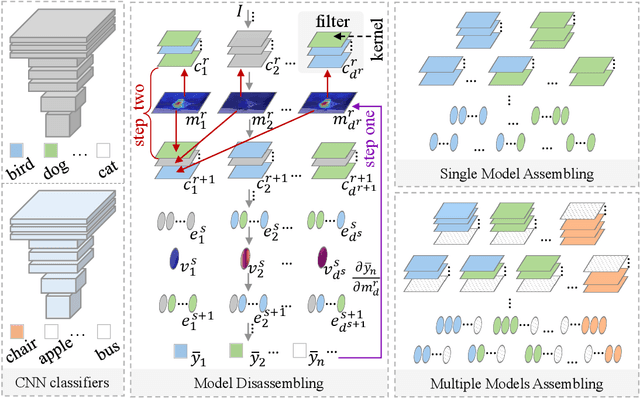
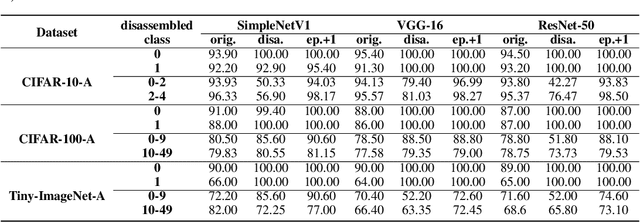
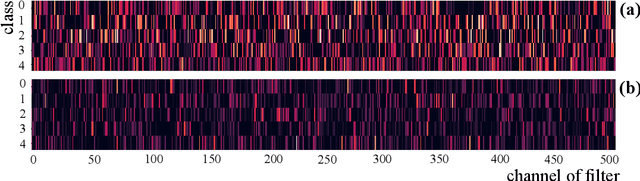
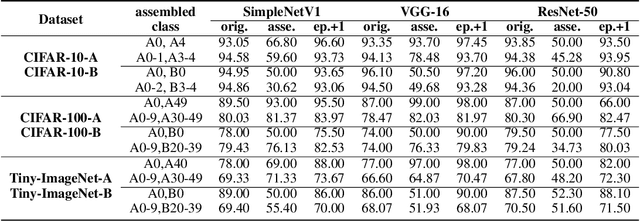
Convolutional Neural Network (CNN), which mimics human visual perception mechanism, has been successfully used in many computer vision areas. Some psychophysical studies show that the visual perception mechanism synchronously processes the form, color, movement, depth, etc., in the initial stage [7,20] and then integrates all information for final recognition [38]. What's more, the human visual system [20] contains different subdivisions or different tasks. Inspired by the above visual perception mechanism, we investigate a new task, termed as Model Disassembling and Assembling (MDA-Task), which can disassemble the deep models into independent parts and assemble those parts into a new deep model without performance cost like playing LEGO toys. To this end, we propose a feature route attribution technique (FRAT) for disassembling CNN classifiers in this paper. In FRAT, the positive derivatives of predicted class probability w.r.t. the feature maps are adopted to locate the critical features in each layer. Then, relevance analysis between the critical features and preceding/subsequent parameter layers is adopted to bridge the route between two adjacent parameter layers. In the assembling phase, class-wise components of each layer are assembled into a new deep model for a specific task. Extensive experiments demonstrate that the assembled CNN classifier can achieve close accuracy with the original classifier without any fine-tune, and excess original performance with one-epoch fine-tune. What's more, we also conduct massive experiments to verify the broad application of MDA-Task on model decision route visualization, model compression, knowledge distillation, transfer learning, incremental learning, and so on.