 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine-Learned Comorbidity Index
Jun 16, 2026Traditional comorbidity scores (e.g., Charlson and Elixhauser) are widely used for risk adjustment and patient stratification, but they have two key limitations: (i) they are largely mortality-centric and do not align well with other clinical outcomes, and (ii) their linear, rule-based structure cannot capture nonlinear, outcome-specific risk relationships. We propose a Machine-Learned Comorbidity Index (MLCI) that maps diagnosis codes to a single scalar by maximizing the normalized Hilbert-Schmidt Independence Criterion (nHSIC) between the learned score and multiple clinical outcomes. MLCI captures nonlinear risk-outcome dependence and is supported by a theory that characterizes when a unified, informative admission-level ordering can be achieved across outcomes. Empirical results on multiple benchmark electronic health record (EHR) datasets show that MLCI outperforms strong baselines across multiple evaluation metrics.
Multimodal Emergent Fake News Detection via Meta Neural Process Networks
Jun 22, 2021
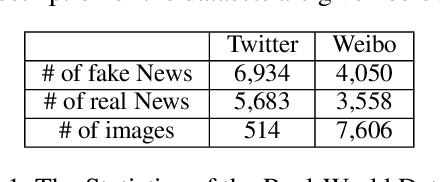
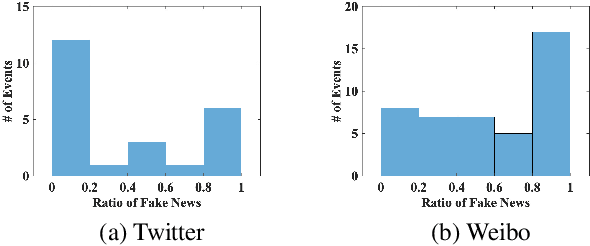

Fake news travels at unprecedented speeds, reaches global audiences and puts users and communities at great risk via social media platforms. Deep learning based models show good performance when trained on large amounts of labeled data on events of interest, whereas the performance of models tends to degrade on other events due to domain shift. Therefore, significant challenges are posed for existing detection approaches to detect fake news on emergent events, where large-scale labeled datasets are difficult to obtain. Moreover, adding the knowledge from newly emergent events requires to build a new model from scratch or continue to fine-tune the model, which can be challenging, expensive, and unrealistic for real-world settings. In order to address those challenges, we propose an end-to-end fake news detection framework named MetaFEND, which is able to learn quickly to detect fake news on emergent events with a few verified posts. Specifically, the proposed model integrates meta-learning and neural process methods together to enjoy the benefits of these approaches. In particular, a label embedding module and a hard attention mechanism are proposed to enhance the effectiveness by handling categorical information and trimming irrelevant posts. Extensive experiments are conducted on multimedia datasets collected from Twitter and Weibo. The experimental results show our proposed MetaFEND model can detect fake news on never-seen events effectively and outperform the state-of-the-art methods.
Knowledge-Base Enriched Word Embeddings for Biomedical Domain
Feb 20, 2021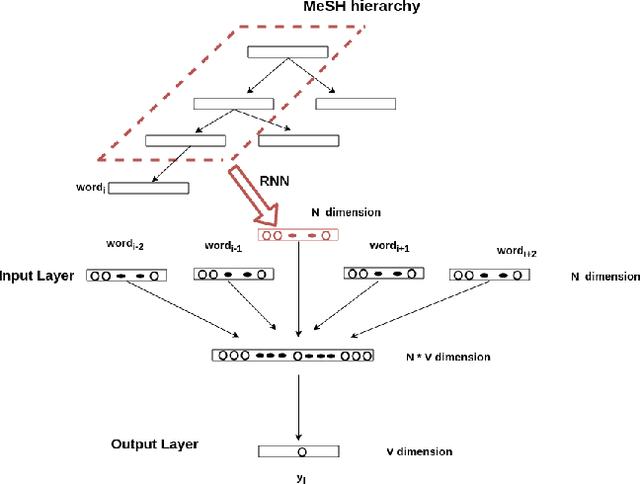


Word embeddings have been shown adept at capturing the semantic and syntactic regularities of the natural language text, as a result of which these representations have found their utility in a wide variety of downstream content analysis tasks. Commonly, these word embedding techniques derive the distributed representation of words based on the local context information. However, such approaches ignore the rich amount of explicit information present in knowledge-bases. This is problematic, as it might lead to poor representation for words with insufficient local context such as domain specific words. Furthermore, the problem becomes pronounced in domain such as bio-medicine where the presence of these domain specific words are relatively high. Towards this end, in this project, we propose a new word embedding based model for biomedical domain that jointly leverages the information from available corpora and domain knowledge in order to generate knowledge-base powered embeddings. Unlike existing approaches, the proposed methodology is simple but adept at capturing the precise knowledge available in domain resources in an accurate way. Experimental results on biomedical concept similarity and relatedness task validates the effectiveness of the proposed approach.