 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotating Columns with Pre-trained Language Models
Apr 05, 2021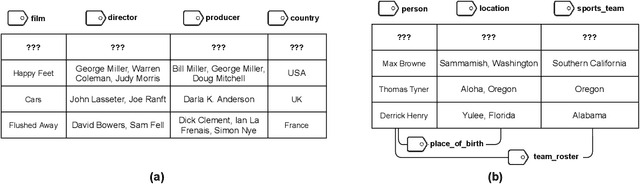
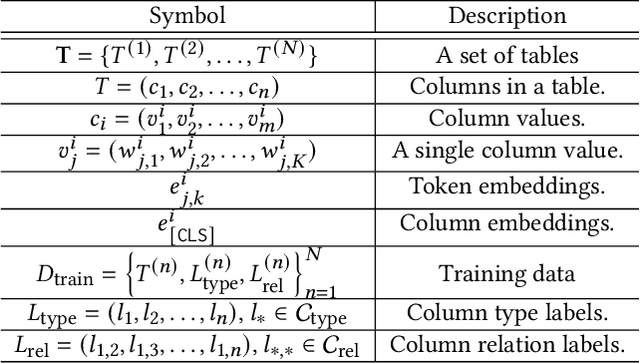
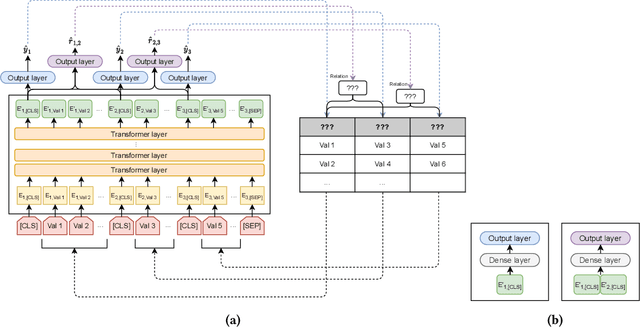
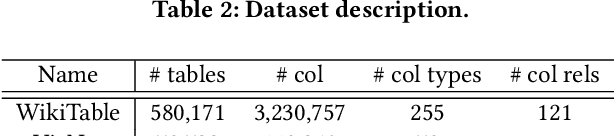
Inferring meta information about tables, such as column headers or relationships between columns, is an active research topic in data management as we find many tables are missing some of this information. In this paper, we study the problem of annotating table columns (i.e., predicting column types and the relationships between columns) using only information from the table itself. We show that a multi-task learning approach (called Doduo), trained using pre-trained language models on both tasks outperforms individual learning approaches. Experimental results show that Doduo establishes new state-of-the-art performance on two benchmarks for the column type prediction and column relation prediction tasks with up to 4.0% and 11.9% improvements, respectively. We also establish that Doduo can already perform the previous state-of-the-art performance with a minimal number of tokens, only 8 tokens per column.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021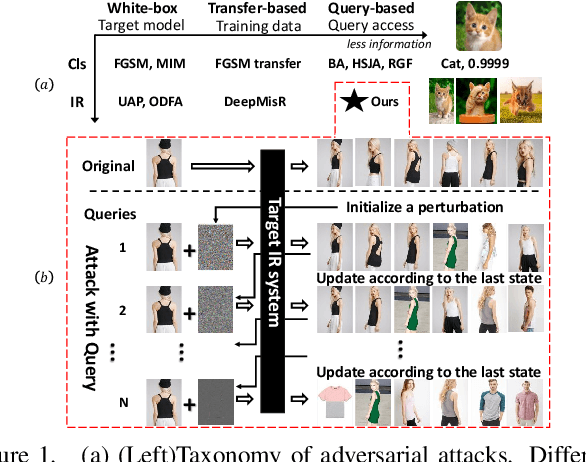
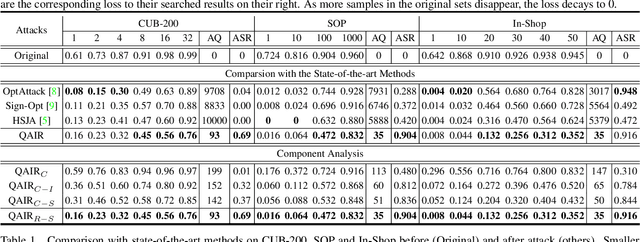
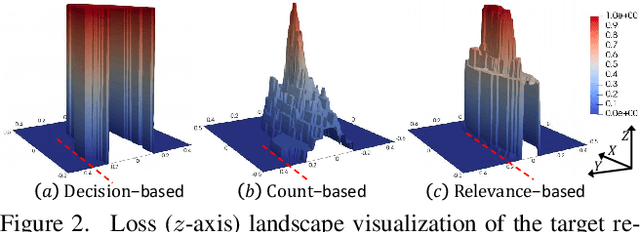
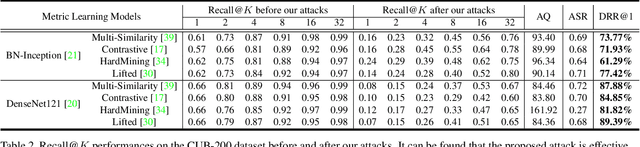
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
Enhancing Model Robustness By Incorporating Adversarial Knowledge Into Semantic Representation
Feb 23, 2021
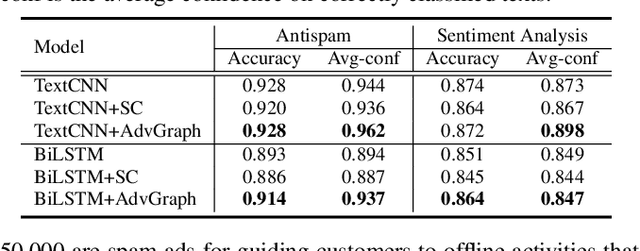
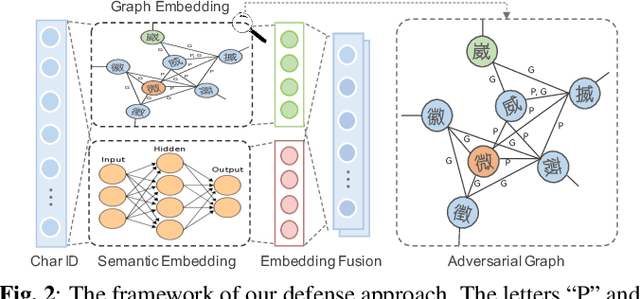
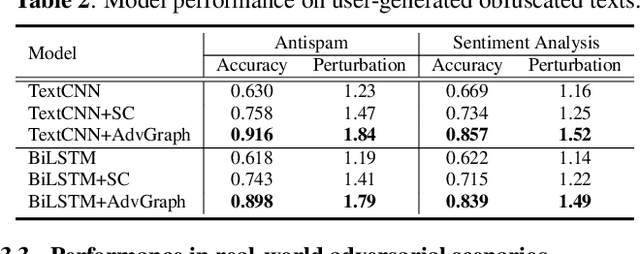
Despite that deep neural networks (DNNs) have achieved enormous success in many domains like natural language processing (NLP), they have also been proven to be vulnerable to maliciously generated adversarial examples. Such inherent vulnerability has threatened various real-world deployed DNNs-based applications. To strength the model robustness, several countermeasures have been proposed in the English NLP domain and obtained satisfactory performance. However, due to the unique language properties of Chinese, it is not trivial to extend existing defenses to the Chinese domain. Therefore, we propose AdvGraph, a novel defense which enhances the robustness of Chinese-based NLP models by incorporating adversarial knowledge into the semantic representation of the input. Extensive experiments on two real-world tasks show that AdvGraph exhibits better performance compared with previous work: (i) effective - it significantly strengthens the model robustness even under the adaptive attacks setting without negative impact on model performance over legitimate input; (ii) generic - its key component, i.e., the representation of connotative adversarial knowledge is task-agnostic, which can be reused in any Chinese-based NLP models without retraining; and (iii) efficient - it is a light-weight defense with sub-linear computational complexity, which can guarantee the efficiency required in practical scenarios.
Learning Domain-invariant Graph for Adaptive Semi-supervised Domain Adaptation with Few Labeled Source Samples
Aug 21, 2020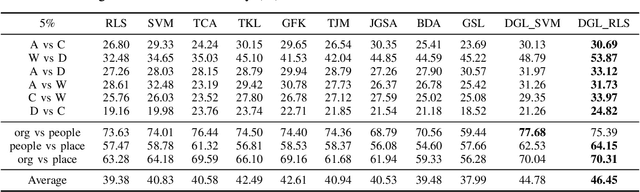
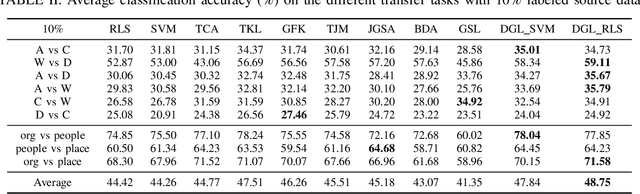
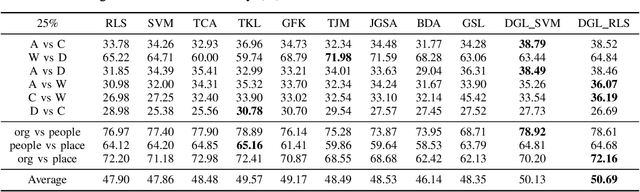
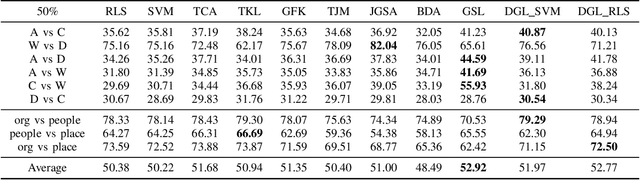
Domain adaptation aims to generalize a model from a source domain to tackle tasks in a related but different target domain. Traditional domain adaptation algorithms assume that enough labeled data, which are treated as the prior knowledge are available in the source domain. However, these algorithms will be infeasible when only a few labeled data exist in the source domain, and thus the performance decreases significantly. To address this challenge, we propose a Domain-invariant Graph Learning (DGL) approach for domain adaptation with only a few labeled source samples. Firstly, DGL introduces the Nystrom method to construct a plastic graph that shares similar geometric property as the target domain. And then, DGL flexibly employs the Nystrom approximation error to measure the divergence between plastic graph and source graph to formalize the distribution mismatch from the geometric perspective. Through minimizing the approximation error, DGL learns a domain-invariant geometric graph to bridge source and target domains. Finally, we integrate the learned domain-invariant graph with the semi-supervised learning and further propose an adaptive semi-supervised model to handle the cross-domain problems. The results of extensive experiments on popular datasets verify the superiority of DGL, especially when only a few labeled source samples are available.
Deep or Simple Models for Semantic Tagging? It Depends on your Data
Jul 11, 2020
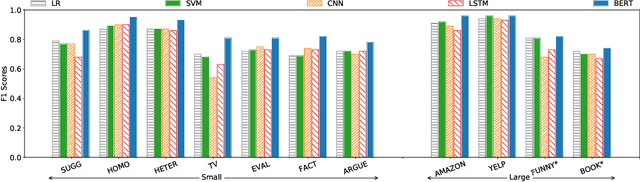
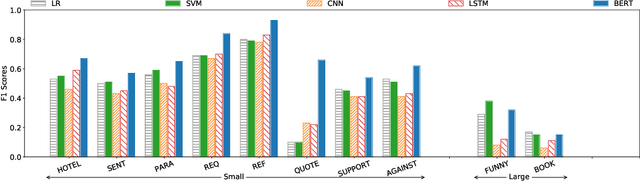
Semantic tagging, which has extensive applications in text mining, predicts whether a given piece of text conveys the meaning of a given semantic tag. The problem of semantic tagging is largely solved with supervised learning and today, deep learning models are widely perceived to be better for semantic tagging. However, there is no comprehensive study supporting the popular belief. Practitioners often have to train different types of models for each semantic tagging task to identify the best model. This process is both expensive and inefficient. We embark on a systematic study to investigate the following question: Are deep models the best performing model for all semantic tagging tasks? To answer this question, we compare deep models against "simple models" over datasets with varying characteristics. Specifically, we select three prevalent deep models (i.e. CNN, LSTM, and BERT) and two simple models (i.e. LR and SVM), and compare their performance on the semantic tagging task over 21 datasets. Results show that the size, the label ratio, and the label cleanliness of a dataset significantly impact the quality of semantic tagging. Simple models achieve similar tagging quality to deep models on large datasets, but the runtime of simple models is much shorter. Moreover, simple models can achieve better tagging quality than deep models when targeting datasets show worse label cleanliness and/or more severe imbalance. Based on these findings, our study can systematically guide practitioners in selecting the right learning model for their semantic tagging task.
ExplainIt: Explainable Review Summarization with Opinion Causality Graphs
May 29, 2020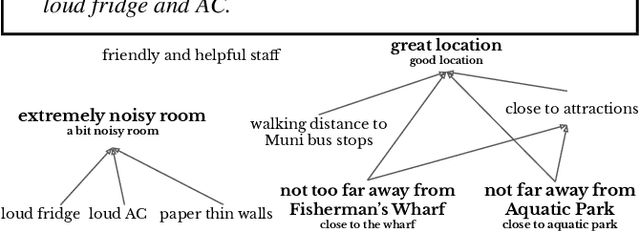


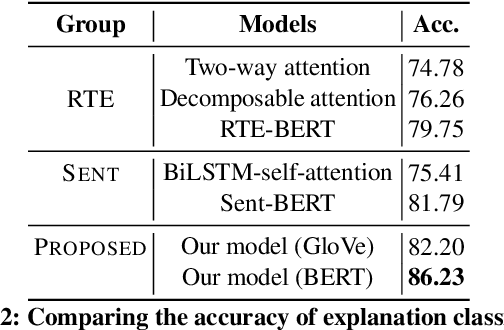
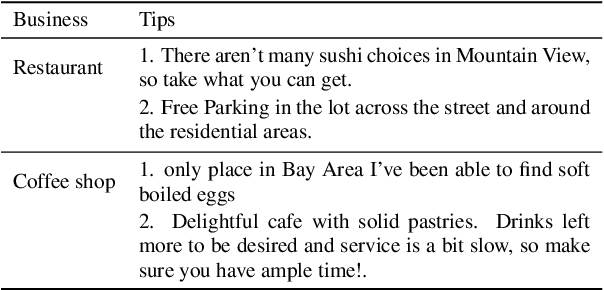
We present ExplainIt, a review summarization system centered around opinion explainability: the simple notion of high-level opinions (e.g. "noisy room") being explainable by lower-level ones (e.g., "loud fridge"). ExplainIt utilizes a combination of supervised and unsupervised components to mine the opinion phrases from reviews and organize them in an Opinion Causality Graph (OCG), a novel semi-structured representation which summarizes causal relations. To construct an OCG, we cluster semantically similar opinions in single nodes, thus canonicalizing opinion paraphrases, and draw directed edges between node pairs that are likely connected by a causal relation. OCGs can be used to generate structured summaries at different levels of granularity and for certain aspects of interest, while simultaneously providing explanations. In this paper, we present the system's individual components and evaluate their effectiveness on their respective sub-tasks, where we report substantial improvements over baselines across two domains. Finally, we validate these results with a user study, showing that ExplainIt produces reasonable opinion explanations according to human judges.
A Novel Twitter Sentiment Analysis Model with Baseline Correlation for Financial Market Prediction with Improved Efficiency
Apr 21, 2020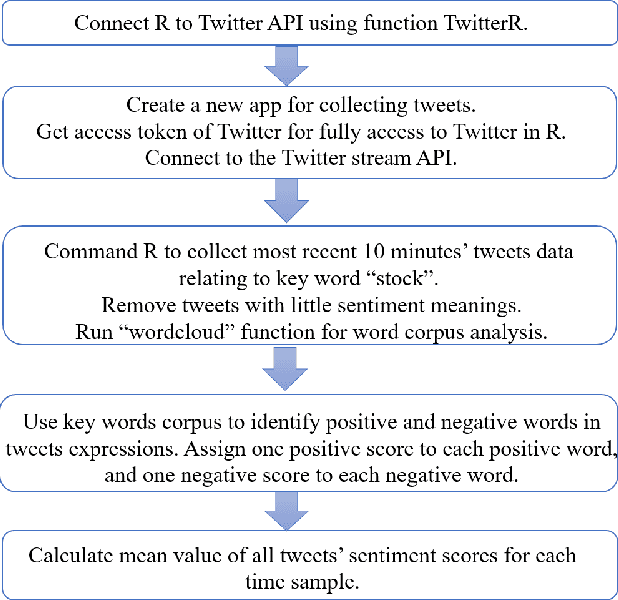
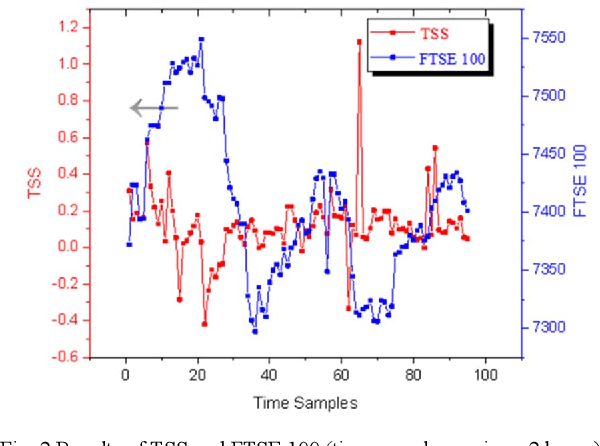
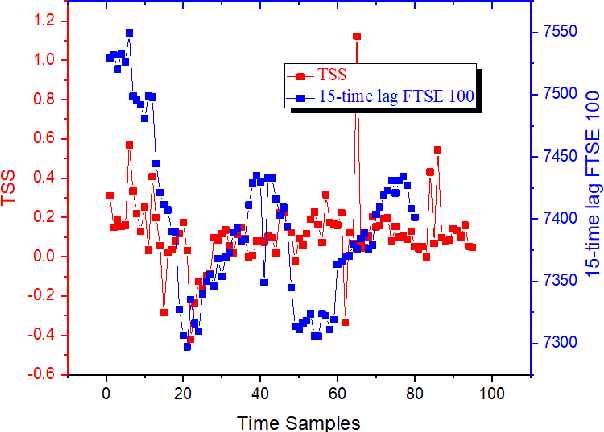
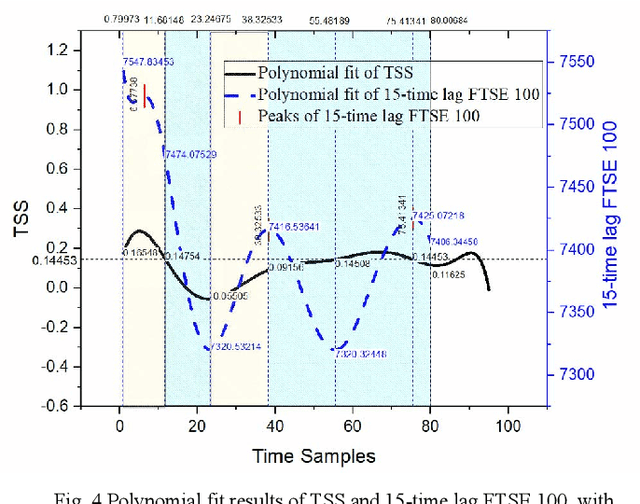
A novel social networks sentiment analysis model is proposed based on Twitter sentiment score (TSS) for real-time prediction of the future stock market price FTSE 100, as compared with conventional econometric models of investor sentiment based on closed-end fund discount (CEFD). The proposed TSS model features a new baseline correlation approach, which not only exhibits a decent prediction accuracy, but also reduces the computation burden and enables a fast decision making without the knowledge of historical data. Polynomial regression, classification modelling and lexicon-based sentiment analysis are performed using R. The obtained TSS predicts the future stock market trend in advance by 15 time samples (30 working hours) with an accuracy of 67.22% using the proposed baseline criterion without referring to historical TSS or market data. Specifically, TSS's prediction performance of an upward market is found far better than that of a downward market. Under the logistic regression and linear discriminant analysis, the accuracy of TSS in predicting the upward trend of the future market achieves 97.87%.
* 2019 Sixth IEEE International Conference on Social Networks Analysis, Management and Security (SNAMS)
Enhancing Review Comprehension with Domain-Specific Commonsense
Apr 06, 2020
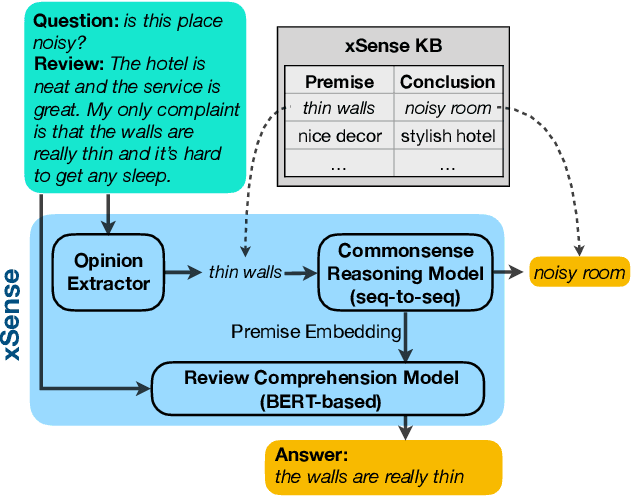
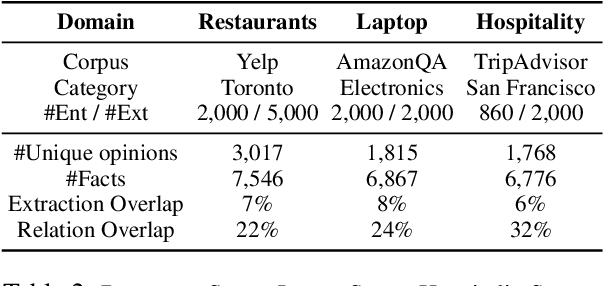
Review comprehension has played an increasingly important role in improving the quality of online services and products and commonsense knowledge can further enhance review comprehension. However, existing general-purpose commonsense knowledge bases lack sufficient coverage and precision to meaningfully improve the comprehension of domain-specific reviews. In this paper, we introduce xSense, an effective system for review comprehension using domain-specific commonsense knowledge bases (xSense KBs). We show that xSense KBs can be constructed inexpensively and present a knowledge distillation method that enables us to use xSense KBs along with BERT to boost the performance of various review comprehension tasks. We evaluate xSense over three review comprehension tasks: aspect extraction, aspect sentiment classification, and question answering. We find that xSense outperforms the state-of-the-art models for the first two tasks and improves the baseline BERT QA model significantly, demonstrating the usefulness of incorporating commonsense into review comprehension pipelines. To facilitate future research and applications, we publicly release three domain-specific knowledge bases and a domain-specific question answering benchmark along with this paper.
Deep Entity Matching with Pre-Trained Language Models
Apr 01, 2020

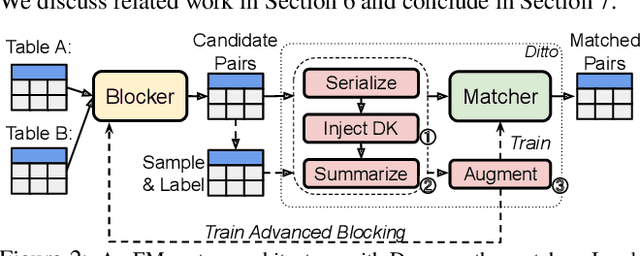

We present Ditto, a novel entity matching system based on pre-trained Transformer-based language models. We fine-tune and cast EM as a sequence-pair classification problem to leverage such models with a simple architecture. Our experiments show that a straightforward application of language models such as BERT, DistilBERT, or ALBERT pre-trained on large text corpora already significantly improves the matching quality and outperforms previous state-of-the-art (SOTA), by up to 19% of F1 score on benchmark datasets. We also developed three optimization techniques to further improve Ditto's matching capability. Ditto allows domain knowledge to be injected by highlighting important pieces of input information that may be of interest when making matching decisions. Ditto also summarizes strings that are too long so that only the essential information is retained and used for EM. Finally, Ditto adapts a SOTA technique on data augmentation for text to EM to augment the training data with (difficult) examples. This way, Ditto is forced to learn "harder" to improve the model's matching capability. The optimizations we developed further boost the performance of Ditto by up to 8.5%. Perhaps more surprisingly, we establish that Ditto can achieve the previous SOTA results with at most half the number of labeled data. Finally, we demonstrate Ditto's effectiveness on a real-world large-scale EM task. On matching two company datasets consisting of 789K and 412K records, Ditto achieves a high F1 score of 96.5%.
Sato: Contextual Semantic Type Detection in Tables
Nov 14, 2019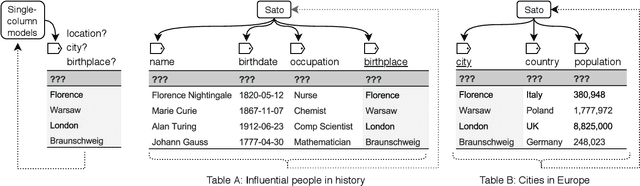

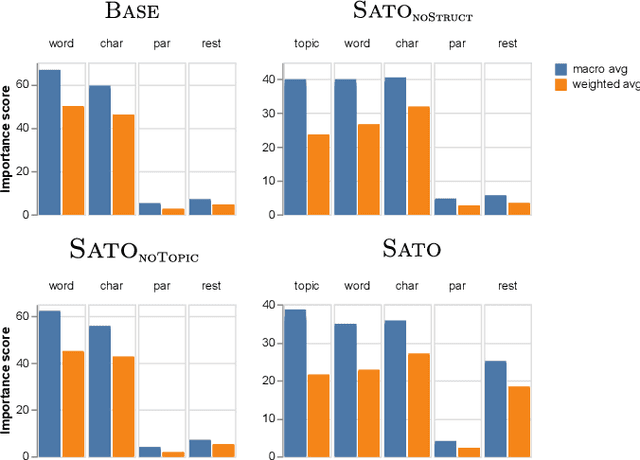
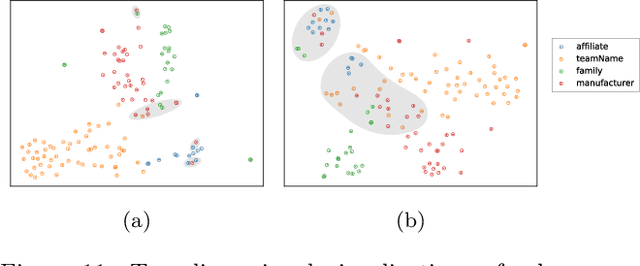
Detecting the semantic types of data columns in relational tables is important for various data preparation and information retrieval tasks such as data cleaning, schema matching, data discovery, and semantic search. However, existing detection approaches either perform poorly with dirty data, support only a limited number of semantic types, fail to incorporate the table context of columns or rely on large sample sizes in the training data. We introduce Sato, a hybrid machine learning model to automatically detect the semantic types of columns in tables, exploiting the signals from the context as well as the column values. Sato combines a deep learning model trained on a large-scale table corpus with topic modeling and structured prediction to achieve support-weighted and macro average F1 scores of 0.901 and 0.973, respectively, exceeding the state-of-the-art performance by a significant margin. We extensively analyze the overall and per-type performance of Sato, discussing how individual modeling components, as well as feature categories, contribute to its performance.