 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Explain: Supervised Token Attribution from Transformer Attention Patterns
Jan 21, 2026Explainable AI (XAI) has become critical as transformer-based models are deployed in high-stakes applications including healthcare, legal systems, and financial services, where opacity hinders trust and accountability. Transformers self-attention mechanisms have proven valuable for model interpretability, with attention weights successfully used to understand model focus and behavior (Xu et al., 2015); (Wiegreffe and Pinter, 2019). However, existing attention-based explanation methods rely on manually defined aggregation strategies and fixed attribution rules (Abnar and Zuidema, 2020a); (Chefer et al., 2021), while model-agnostic approaches (LIME, SHAP) treat the model as a black box and incur significant computational costs through input perturbation. We introduce Explanation Network (ExpNet), a lightweight neural network that learns an explicit mapping from transformer attention patterns to token-level importance scores. Unlike prior methods, ExpNet discovers optimal attention feature combinations automatically rather than relying on predetermined rules. We evaluate ExpNet in a challenging cross-task setting and benchmark it against a broad spectrum of model-agnostic methods and attention-based techniques spanning four methodological families.
LIME-LLM: Probing Models with Fluent Counterfactuals, Not Broken Text
Jan 16, 2026Local explanation methods such as LIME (Ribeiro et al., 2016) remain fundamental to trustworthy AI, yet their application to NLP is limited by a reliance on random token masking. These heuristic perturbations frequently generate semantically invalid, out-of-distribution inputs that weaken the fidelity of local surrogate models. While recent generative approaches such as LLiMe (Angiulli et al., 2025b) attempt to mitigate this by employing Large Language Models for neighborhood generation, they rely on unconstrained paraphrasing that introduces confounding variables, making it difficult to isolate specific feature contributions. We introduce LIME-LLM, a framework that replaces random noise with hypothesis-driven, controlled perturbations. By enforcing a strict "Single Mask-Single Sample" protocol and employing distinct neutral infill and boundary infill strategies, LIME-LLM constructs fluent, on-manifold neighborhoods that rigorously isolate feature effects. We evaluate our method against established baselines (LIME, SHAP, Integrated Gradients) and the generative LLiMe baseline across three diverse benchmarks: CoLA, SST-2, and HateXplain using human-annotated rationales as ground truth. Empirical results demonstrate that LIME-LLM establishes a new benchmark for black-box NLP explainability, achieving significant improvements in local explanation fidelity compared to both traditional perturbation-based methods and recent generative alternatives.
Tagging-Augmented Generation: Assisting Language Models in Finding Intricate Knowledge In Long Contexts
Oct 27, 2025Recent investigations into effective context lengths of modern flagship large language models (LLMs) have revealed major limitations in effective question answering (QA) and reasoning over long and complex contexts for even the largest and most impressive cadre of models. While approaches like retrieval-augmented generation (RAG) and chunk-based re-ranking attempt to mitigate this issue, they are sensitive to chunking, embedding and retrieval strategies and models, and furthermore, rely on extensive pre-processing, knowledge acquisition and indexing steps. In this paper, we propose Tagging-Augmented Generation (TAG), a lightweight data augmentation strategy that boosts LLM performance in long-context scenarios, without degrading and altering the integrity and composition of retrieved documents. We validate our hypothesis by augmenting two challenging and directly relevant question-answering benchmarks -- NoLima and NovelQA -- and show that tagging the context or even just adding tag definitions into QA prompts leads to consistent performance gains over the baseline -- up to 17% for 32K token contexts, and 2.9% in complex reasoning question-answering for multi-hop queries requiring knowledge across a wide span of text. Additional details are available at https://sites.google.com/view/tag-emnlp.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019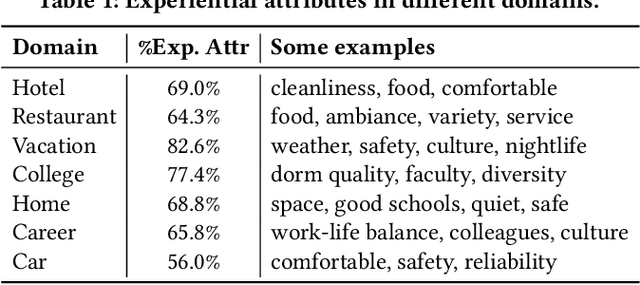
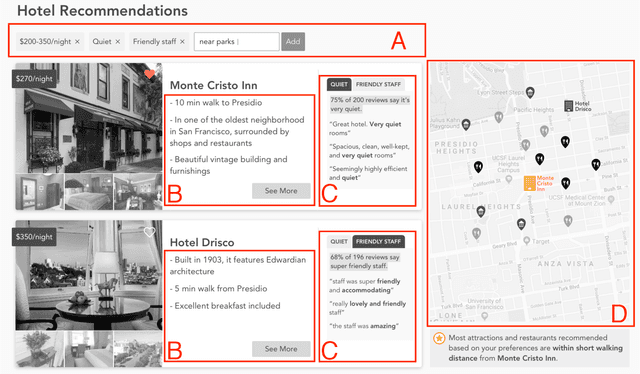
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.
Scalable Semantic Querying of Text
May 03, 2018
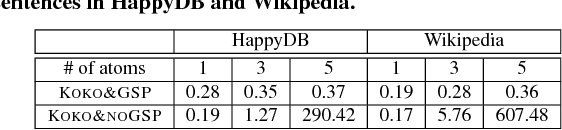
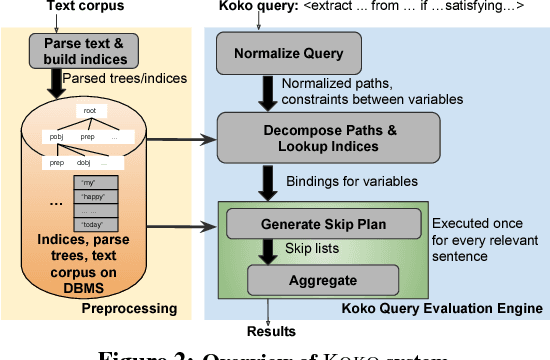
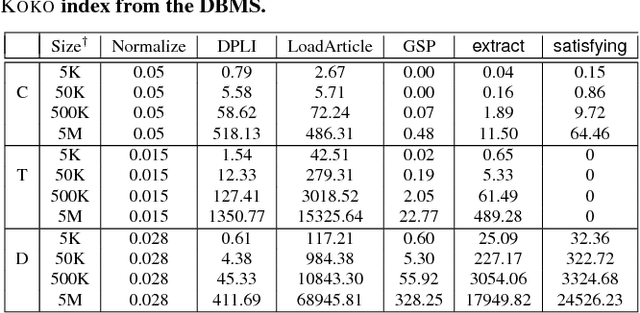
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.