 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Data Gap: Bridging LLMs to Enterprise Data Integration
Dec 29, 2024Leading large language models (LLMs) are trained on public data. However, most of the world's data is dark data that is not publicly accessible, mainly in the form of private organizational or enterprise data. We show that the performance of methods based on LLMs seriously degrades when tested on real-world enterprise datasets. Current benchmarks, based on public data, overestimate the performance of LLMs. We release a new benchmark dataset, the GOBY Benchmark, to advance discovery in enterprise data integration. Based on our experience with this enterprise benchmark, we propose techniques to uplift the performance of LLMs on enterprise data, including (1) hierarchical annotation, (2) runtime class-learning, and (3) ontology synthesis. We show that, once these techniques are deployed, the performance on enterprise data becomes on par with that of public data. The Goby benchmark can be obtained at https://goby-benchmark.github.io/.
BEAVER: An Enterprise Benchmark for Text-to-SQL
Sep 03, 2024Existing text-to-SQL benchmarks have largely been constructed using publicly available tables from the web with human-generated tests containing question and SQL statement pairs. They typically show very good results and lead people to think that LLMs are effective at text-to-SQL tasks. In this paper, we apply off-the-shelf LLMs to a benchmark containing enterprise data warehouse data. In this environment, LLMs perform poorly, even when standard prompt engineering and RAG techniques are utilized. As we will show, the reasons for poor performance are largely due to three characteristics: (1) public LLMs cannot train on enterprise data warehouses because they are largely in the "dark web", (2) schemas of enterprise tables are more complex than the schemas in public data, which leads the SQL-generation task innately harder, and (3) business-oriented questions are often more complex, requiring joins over multiple tables and aggregations. As a result, we propose a new dataset BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history. We evaluated this dataset using recent LLMs and demonstrated their poor performance on this task. We hope this dataset will facilitate future researchers building more sophisticated text-to-SQL systems which can do better on this important class of data.
Making LLMs Work for Enterprise Data Tasks
Jul 22, 2024Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
AdaTyper: Adaptive Semantic Column Type Detection
Nov 23, 2023



Understanding the semantics of relational tables is instrumental for automation in data exploration and preparation systems. A key source for understanding a table is the semantics of its columns. With the rise of deep learning, learned table representations are now available, which can be applied for semantic type detection and achieve good performance on benchmarks. Nevertheless, we observe a gap between this performance and its applicability in practice. In this paper, we propose AdaTyper to address one of the most critical deployment challenges: adaptation. AdaTyper uses weak-supervision to adapt a hybrid type predictor towards new semantic types and shifted data distributions at inference time, using minimal human feedback. The hybrid type predictor of AdaTyper combines rule-based methods and a light machine learning model for semantic column type detection. We evaluate the adaptation performance of AdaTyper on real-world database tables hand-annotated with semantic column types through crowdsourcing and find that the f1-score improves for new and existing types. AdaTyper approaches an average precision of 0.6 after only seeing 5 examples, significantly outperforming existing adaptation methods based on human-provided regular expressions or dictionaries.
Machine Learning with DBOS
Aug 10, 2022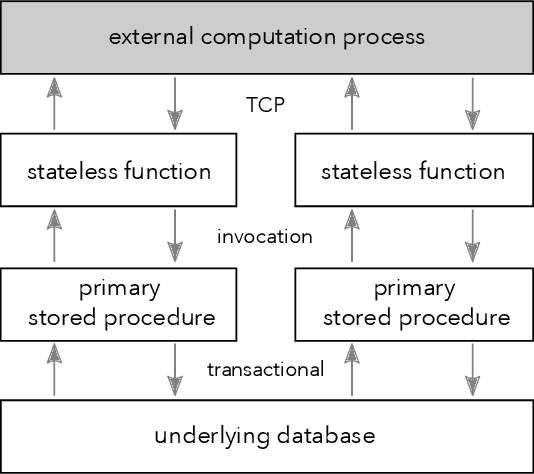
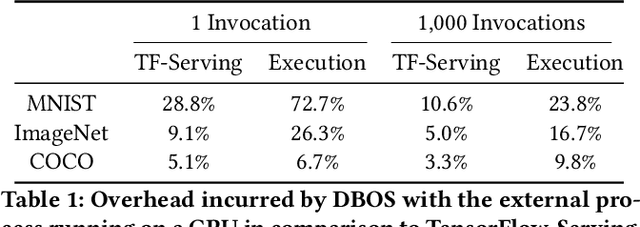

We recently proposed a new cluster operating system stack, DBOS, centered on a DBMS. DBOS enables unique support for ML applications by encapsulating ML code within stored procedures, centralizing ancillary ML data, providing security built into the underlying DBMS, co-locating ML code and data, and tracking data and workflow provenance. Here we demonstrate a subset of these benefits around two ML applications. We first show that image classification and object detection models using GPUs can be served as DBOS stored procedures with performance competitive to existing systems. We then present a 1D CNN trained to detect anomalies in HTTP requests on DBOS-backed web services, achieving SOTA results. We use this model to develop an interactive anomaly detection system and evaluate it through qualitative user feedback, demonstrating its usefulness as a proof of concept for future work to develop learned real-time security services on top of DBOS.
Augmenting Decision Making via Interactive What-If Analysis
Sep 21, 2021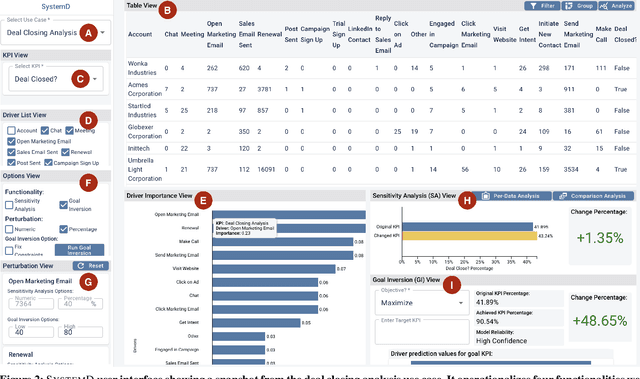

The fundamental goal of business data analysis is to improve business decisions using data. Business users such as sales, marketing, product, or operations managers often make decisions to achieve key performance indicator (KPI) goals such as increasing customer retention, decreasing cost, and increasing sales. To discover the relationship between data attributes hypothesized to be drivers and those corresponding to KPIs of interest, business users currently need to perform lengthy exploratory analyses, considering multitudes of combinations and scenarios, slicing, dicing, and transforming the data accordingly. For example, analyzing customer retention across quarters of the year or suggesting optimal media channels across strata of customers. However, the increasing complexity of datasets combined with the cognitive limitations of humans makes it challenging to carry over multiple hypotheses, even for simple datasets. Therefore mentally performing such analyses is hard. Existing commercial tools either provide partial solutions whose effectiveness remains unclear or fail to cater to business users. Here we argue for four functionalities that we believe are necessary to enable business users to interactively learn and reason about the relationships (functions) between sets of data attributes, facilitating data-driven decision making. We implement these functionalities in SystemD, an interactive visual analysis system enabling business users to experiment with the data by asking what-if questions. We evaluate the system through three business use cases: marketing mix modeling analysis, customer retention analysis, and deal closing analysis, and report on feedback from multiple business users. Overall, business users find SystemD intuitive and useful for quick testing and validation of their hypotheses around interested KPI as well as in making effective and fast data-driven decisions.
Making Table Understanding Work in Practice
Sep 11, 2021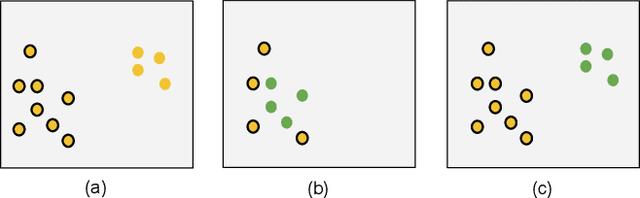

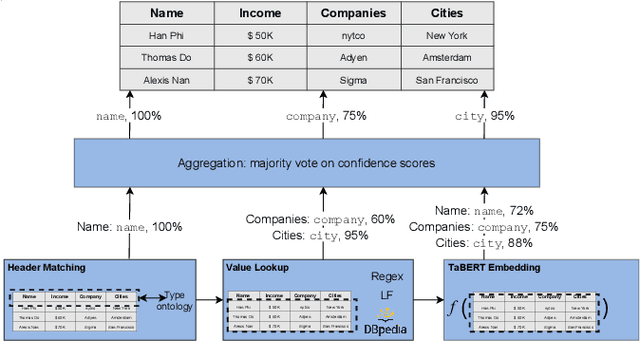
Understanding the semantics of tables at scale is crucial for tasks like data integration, preparation, and search. Table understanding methods aim at detecting a table's topic, semantic column types, column relations, or entities. With the rise of deep learning, powerful models have been developed for these tasks with excellent accuracy on benchmarks. However, we observe that there exists a gap between the performance of these models on these benchmarks and their applicability in practice. In this paper, we address the question: what do we need for these models to work in practice? We discuss three challenges of deploying table understanding models and propose a framework to address them. These challenges include 1) difficulty in customizing models to specific domains, 2) lack of training data for typical database tables often found in enterprises, and 3) lack of confidence in the inferences made by models. We present SigmaTyper which implements this framework for the semantic column type detection task. SigmaTyper encapsulates a hybrid model trained on GitTables and integrates a lightweight human-in-the-loop approach to customize the model. Lastly, we highlight avenues for future research that further close the gap towards making table understanding effective in practice.
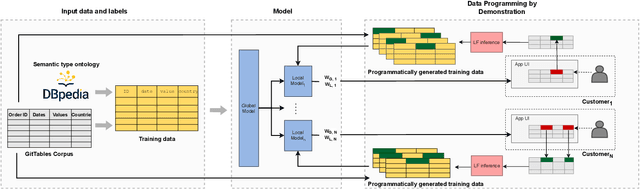
TagRuler: Interactive Tool for Span-Level Data Programming by Demonstration
Jun 24, 2021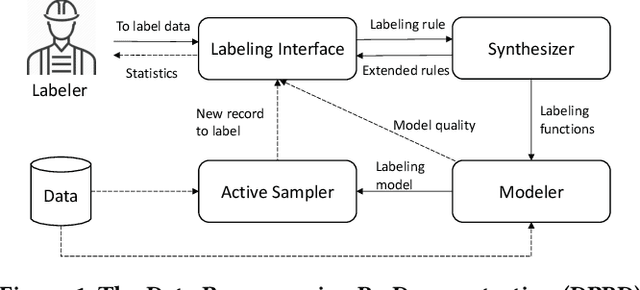
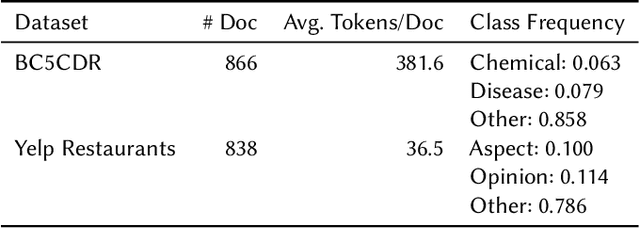
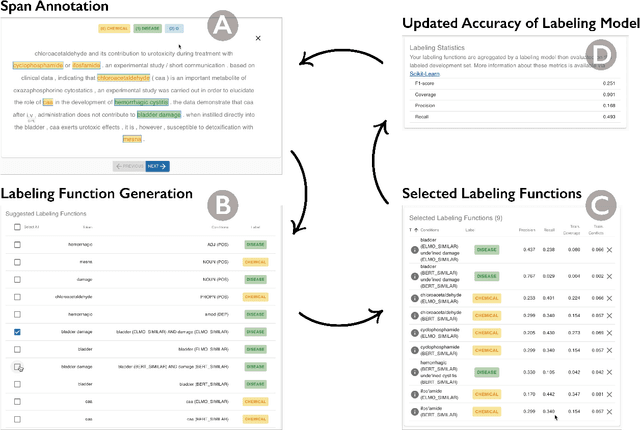

Despite rapid developments in the field of machine learning research, collecting high-quality labels for supervised learning remains a bottleneck for many applications. This difficulty is exacerbated by the fact that state-of-the-art models for NLP tasks are becoming deeper and more complex, often increasing the amount of training data required even for fine-tuning. Weak supervision methods, including data programming, address this problem and reduce the cost of label collection by using noisy label sources for supervision. However, until recently, data programming was only accessible to users who knew how to program. To bridge this gap, the Data Programming by Demonstration framework was proposed to facilitate the automatic creation of labeling functions based on a few examples labeled by a domain expert. This framework has proven successful for generating high-accuracy labeling models for document classification. In this work, we extend the DPBD framework to span-level annotation tasks, arguably one of the most time-consuming NLP labeling tasks. We built a novel tool, TagRuler, that makes it easy for annotators to build span-level labeling functions without programming and encourages them to explore trade-offs between different labeling models and active learning strategies. We empirically demonstrated that an annotator could achieve a higher F1 score using the proposed tool compared to manual labeling for different span-level annotation tasks.
GitTables: A Large-Scale Corpus of Relational Tables
Jun 14, 2021


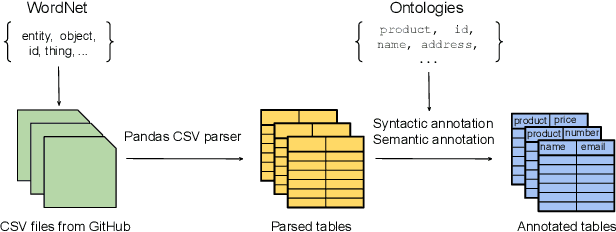
The practical success of deep learning has sparked interest in improving relational table tasks, like data search, with models trained on large table corpora. Existing corpora primarily contain tables extracted from HTML pages, limiting the capability to represent offline database tables. To train and evaluate high-capacity models for applications beyond the Web, we need additional resources with tables that resemble relational database tables. Here we introduce GitTables, a corpus of currently 1.7M relational tables extracted from GitHub. Our continuing curation aims at growing the corpus to at least 20M tables. We annotate table columns in GitTables with more than 2K different semantic types from Schema.org and DBpedia. Our column annotations consist of semantic types, hierarchical relations, range types and descriptions. The corpus is available at https://gittables.github.io. Our analysis of GitTables shows that its structure, content, and topical coverage differ significantly from existing table corpora. We evaluate our annotation pipeline on hand-labeled tables from the T2Dv2 benchmark and find that our approach provides results on par with human annotations. We demonstrate a use case of GitTables by training a semantic type detection model on it and obtain high prediction accuracy. We also show that the same model trained on tables from theWeb generalizes poorly.
Annotating Columns with Pre-trained Language Models
Apr 05, 2021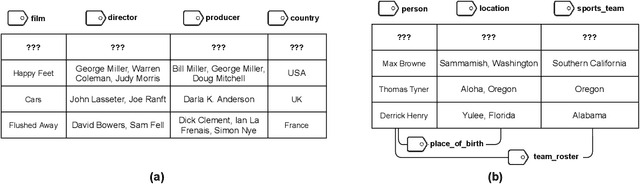
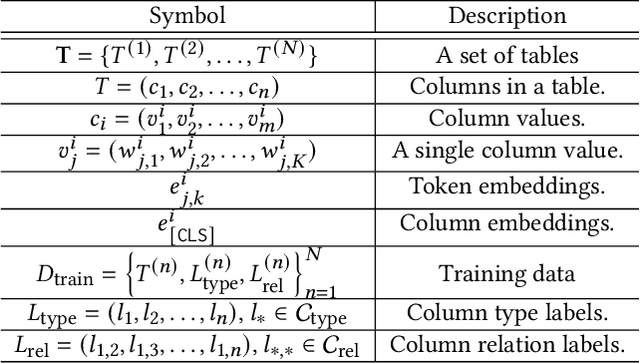
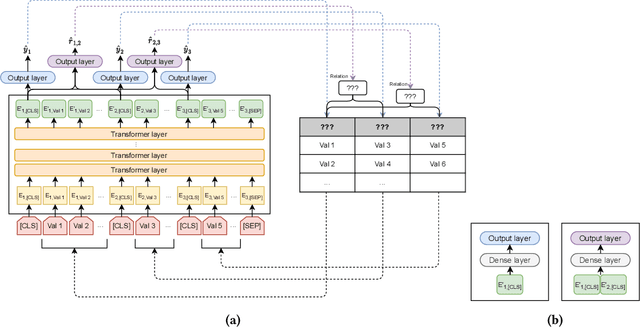
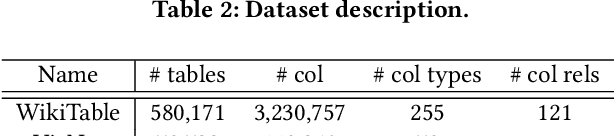
Inferring meta information about tables, such as column headers or relationships between columns, is an active research topic in data management as we find many tables are missing some of this information. In this paper, we study the problem of annotating table columns (i.e., predicting column types and the relationships between columns) using only information from the table itself. We show that a multi-task learning approach (called Doduo), trained using pre-trained language models on both tasks outperforms individual learning approaches. Experimental results show that Doduo establishes new state-of-the-art performance on two benchmarks for the column type prediction and column relation prediction tasks with up to 4.0% and 11.9% improvements, respectively. We also establish that Doduo can already perform the previous state-of-the-art performance with a minimal number of tokens, only 8 tokens per column.