 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Sketch with Deep Q Networks and Demonstrated Strokes
Oct 14, 2018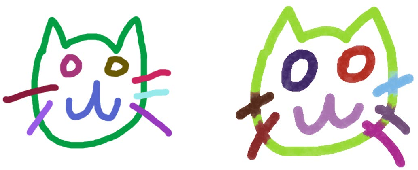


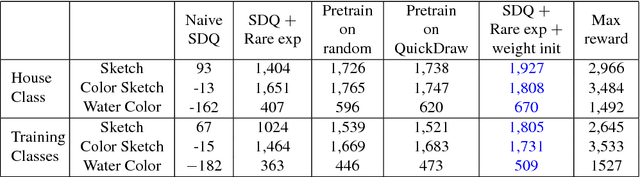
Doodling is a useful and common intelligent skill that people can learn and master. In this work, we propose a two-stage learning framework to teach a machine to doodle in a simulated painting environment via Stroke Demonstration and deep Q-learning (SDQ). The developed system, Doodle-SDQ, generates a sequence of pen actions to reproduce a reference drawing and mimics the behavior of human painters. In the first stage, it learns to draw simple strokes by imitating in supervised fashion from a set of strokeaction pairs collected from artist paintings. In the second stage, it is challenged to draw real and more complex doodles without ground truth actions; thus, it is trained with Qlearning. Our experiments confirm that (1) doodling can be learned without direct stepby- step action supervision and (2) pretraining with stroke demonstration via supervised learning is important to improve performance. We further show that Doodle-SDQ is effective at producing plausible drawings in different media types, including sketch and watercolor.
Flow-Grounded Spatial-Temporal Video Prediction from Still Images
Aug 26, 2018

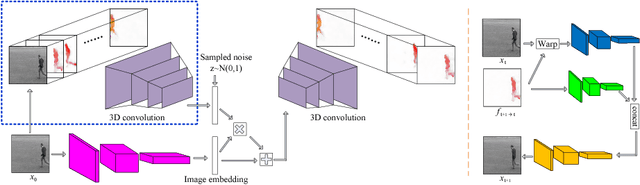

Existing video prediction methods mainly rely on observing multiple historical frames or focus on predicting the next one-frame. In this work, we study the problem of generating consecutive multiple future frames by observing one single still image only. We formulate the multi-frame prediction task as a multiple time step flow (multi-flow) prediction phase followed by a flow-to-frame synthesis phase. The multi-flow prediction is modeled in a variational probabilistic manner with spatial-temporal relationships learned through 3D convolutions. The flow-to-frame synthesis is modeled as a generative process in order to keep the predicted results lying closer to the manifold shape of real video sequence. Such a two-phase design prevents the model from directly looking at the high-dimensional pixel space of the frame sequence and is demonstrated to be more effective in predicting better and diverse results. Extensive experimental results on videos with different types of motion show that the proposed algorithm performs favorably against existing methods in terms of quality, diversity and human perceptual evaluation.
BodyNet: Volumetric Inference of 3D Human Body Shapes
Aug 18, 2018
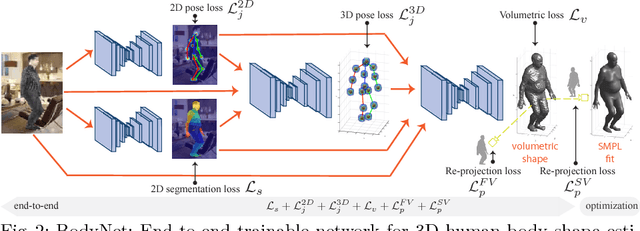
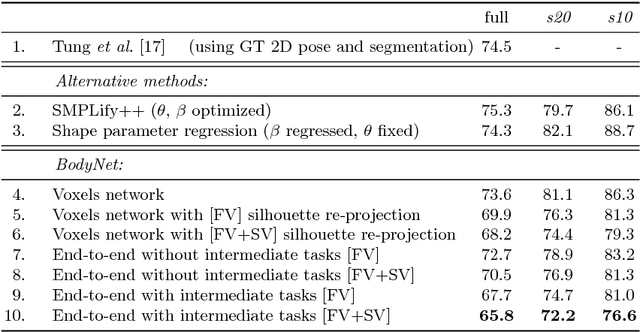

Human shape estimation is an important task for video editing, animation and fashion industry. Predicting 3D human body shape from natural images, however, is highly challenging due to factors such as variation in human bodies, clothing and viewpoint. Prior methods addressing this problem typically attempt to fit parametric body models with certain priors on pose and shape. In this work we argue for an alternative representation and propose BodyNet, a neural network for direct inference of volumetric body shape from a single image. BodyNet is an end-to-end trainable network that benefits from (i) a volumetric 3D loss, (ii) a multi-view re-projection loss, and (iii) intermediate supervision of 2D pose, 2D body part segmentation, and 3D pose. Each of them results in performance improvement as demonstrated by our experiments. To evaluate the method, we fit the SMPL model to our network output and show state-of-the-art results on the SURREAL and Unite the People datasets, outperforming recent approaches. Besides achieving state-of-the-art performance, our method also enables volumetric body-part segmentation.
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

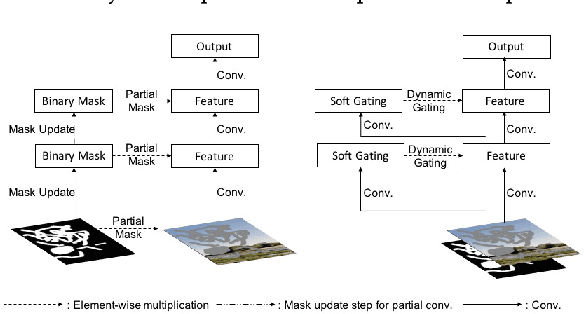

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2
PlaneNet: Piece-wise Planar Reconstruction from a Single RGB Image
Apr 17, 2018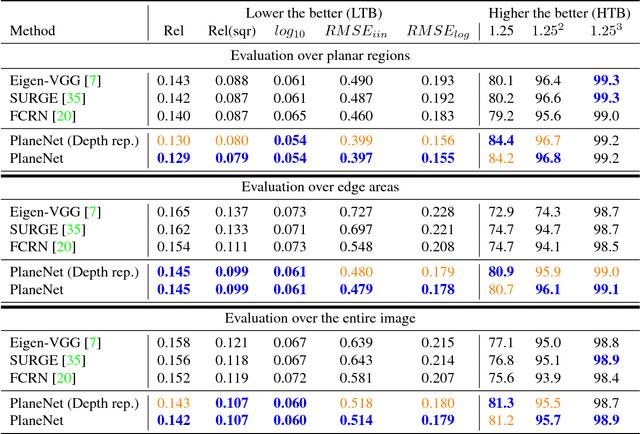
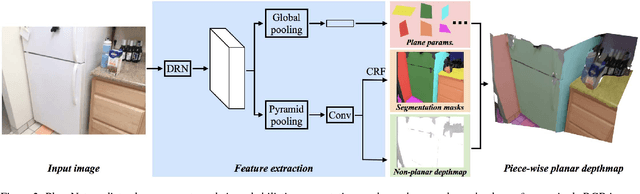


This paper proposes a deep neural network (DNN) for piece-wise planar depthmap reconstruction from a single RGB image. While DNNs have brought remarkable progress to single-image depth prediction, piece-wise planar depthmap reconstruction requires a structured geometry representation, and has been a difficult task to master even for DNNs. The proposed end-to-end DNN learns to directly infer a set of plane parameters and corresponding plane segmentation masks from a single RGB image. We have generated more than 50,000 piece-wise planar depthmaps for training and testing from ScanNet, a large-scale RGBD video database. Our qualitative and quantitative evaluations demonstrate that the proposed approach outperforms baseline methods in terms of both plane segmentation and depth estimation accuracy. To the best of our knowledge, this paper presents the first end-to-end neural architecture for piece-wise planar reconstruction from a single RGB image. Code and data are available at https://github.com/art-programmer/PlaneNet.
Neural Kinematic Networks for Unsupervised Motion Retargetting
Apr 16, 2018
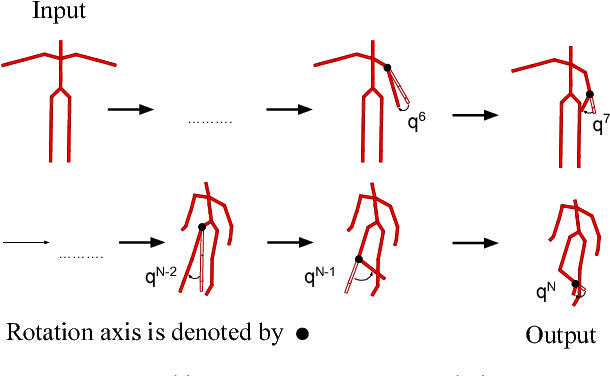
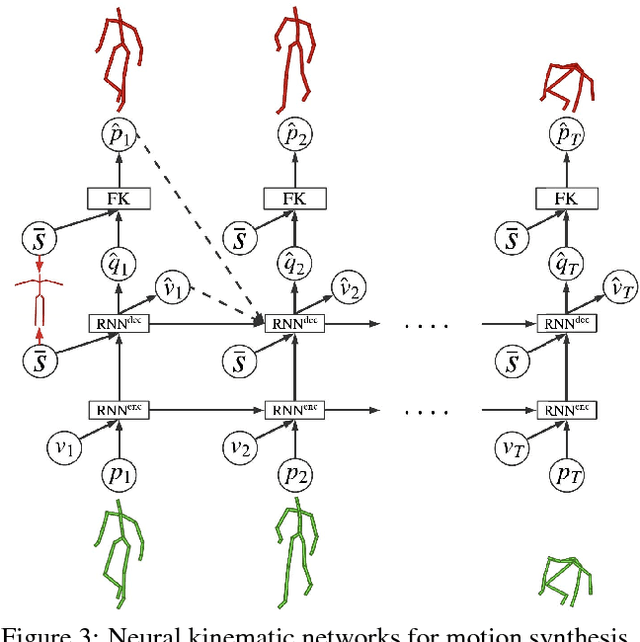
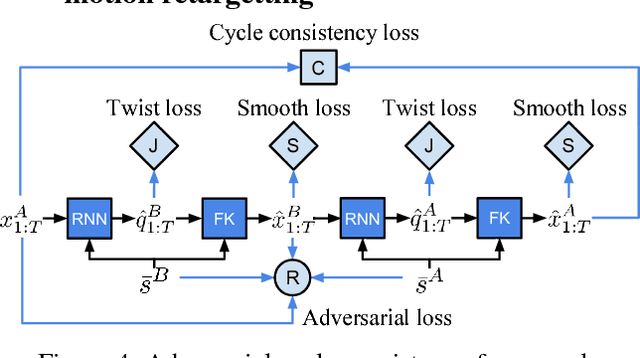
We propose a recurrent neural network architecture with a Forward Kinematics layer and cycle consistency based adversarial training objective for unsupervised motion retargetting. Our network captures the high-level properties of an input motion by the forward kinematics layer, and adapts them to a target character with different skeleton bone lengths (e.g., shorter, longer arms etc.). Collecting paired motion training sequences from different characters is expensive. Instead, our network utilizes cycle consistency to learn to solve the Inverse Kinematics problem in an unsupervised manner. Our method works online, i.e., it adapts the motion sequence on-the-fly as new frames are received. In our experiments, we use the Mixamo animation data to test our method for a variety of motions and characters and achieve state-of-the-art results. We also demonstrate motion retargetting from monocular human videos to 3D characters using an off-the-shelf 3D pose estimator.
MAttNet: Modular Attention Network for Referring Expression Comprehension
Mar 27, 2018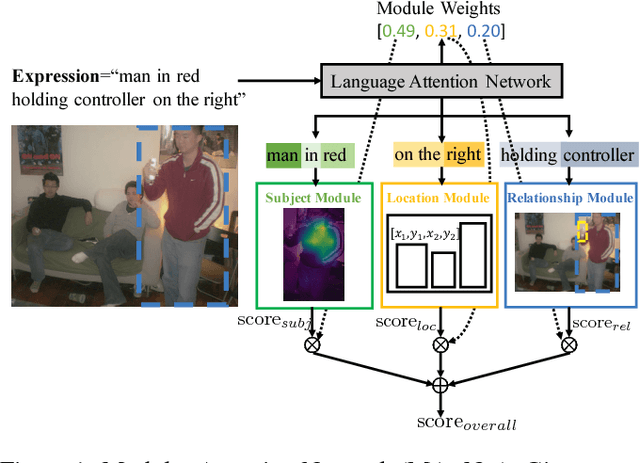
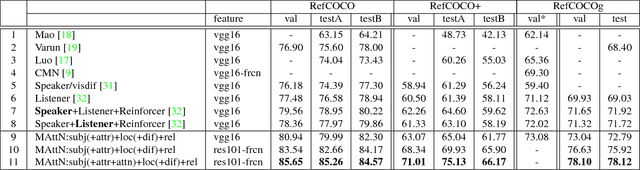
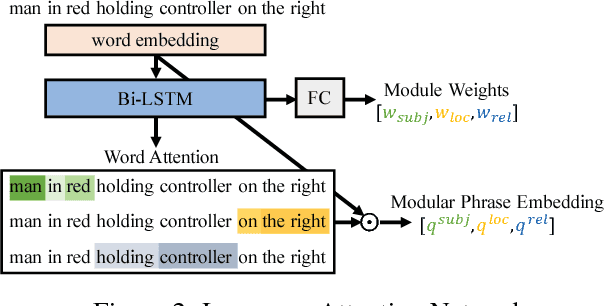
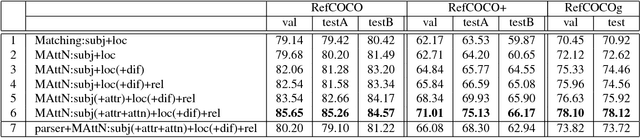
In this paper, we address referring expression comprehension: localizing an image region described by a natural language expression. While most recent work treats expressions as a single unit, we propose to decompose them into three modular components related to subject appearance, location, and relationship to other objects. This allows us to flexibly adapt to expressions containing different types of information in an end-to-end framework. In our model, which we call the Modular Attention Network (MAttNet), two types of attention are utilized: language-based attention that learns the module weights as well as the word/phrase attention that each module should focus on; and visual attention that allows the subject and relationship modules to focus on relevant image components. Module weights combine scores from all three modules dynamically to output an overall score. Experiments show that MAttNet outperforms previous state-of-art methods by a large margin on both bounding-box-level and pixel-level comprehension tasks. Demo and code are provided.
Generative Image Inpainting with Contextual Attention
Mar 21, 2018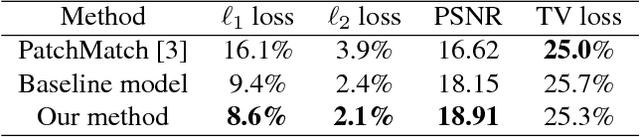

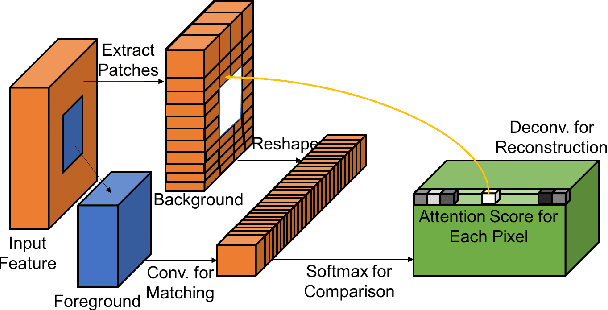
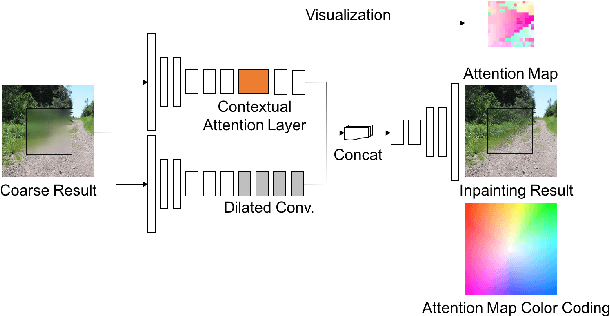
Recent deep learning based approaches have shown promising results for the challenging task of inpainting large missing regions in an image. These methods can generate visually plausible image structures and textures, but often create distorted structures or blurry textures inconsistent with surrounding areas. This is mainly due to ineffectiveness of convolutional neural networks in explicitly borrowing or copying information from distant spatial locations. On the other hand, traditional texture and patch synthesis approaches are particularly suitable when it needs to borrow textures from the surrounding regions. Motivated by these observations, we propose a new deep generative model-based approach which can not only synthesize novel image structures but also explicitly utilize surrounding image features as references during network training to make better predictions. The model is a feed-forward, fully convolutional neural network which can process images with multiple holes at arbitrary locations and with variable sizes during the test time. Experiments on multiple datasets including faces (CelebA, CelebA-HQ), textures (DTD) and natural images (ImageNet, Places2) demonstrate that our proposed approach generates higher-quality inpainting results than existing ones. Code, demo and models are available at: https://github.com/JiahuiYu/generative_inpainting.
Learning to Generate Long-term Future via Hierarchical Prediction
Jan 08, 2018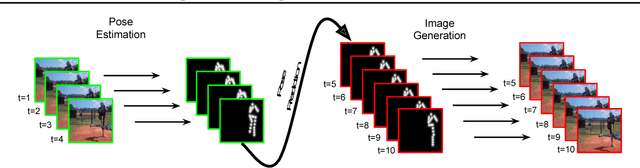
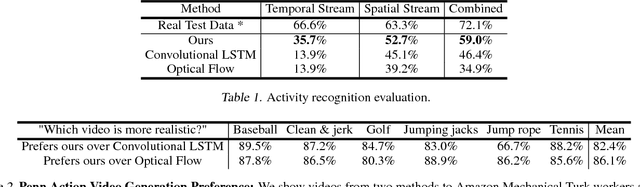
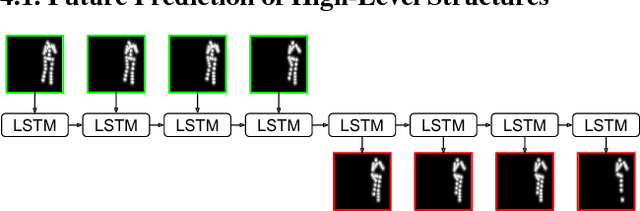
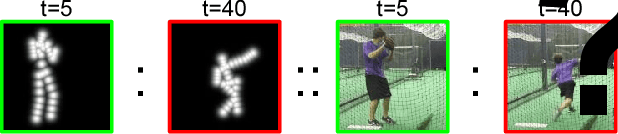
We propose a hierarchical approach for making long-term predictions of future frames. To avoid inherent compounding errors in recursive pixel-level prediction, we propose to first estimate high-level structure in the input frames, then predict how that structure evolves in the future, and finally by observing a single frame from the past and the predicted high-level structure, we construct the future frames without having to observe any of the pixel-level predictions. Long-term video prediction is difficult to perform by recurrently observing the predicted frames because the small errors in pixel space exponentially amplify as predictions are made deeper into the future. Our approach prevents pixel-level error propagation from happening by removing the need to observe the predicted frames. Our model is built with a combination of LSTM and analogy based encoder-decoder convolutional neural networks, which independently predict the video structure and generate the future frames, respectively. In experiments, our model is evaluated on the Human3.6M and Penn Action datasets on the task of long-term pixel-level video prediction of humans performing actions and demonstrate significantly better results than the state-of-the-art.
Decomposing Motion and Content for Natural Video Sequence Prediction
Jan 08, 2018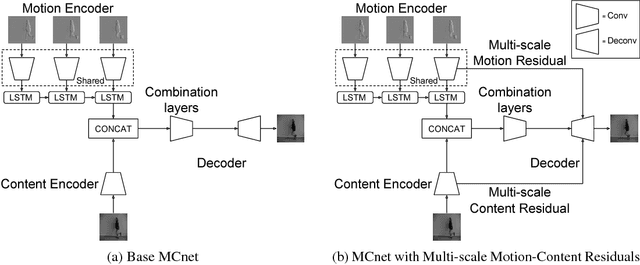
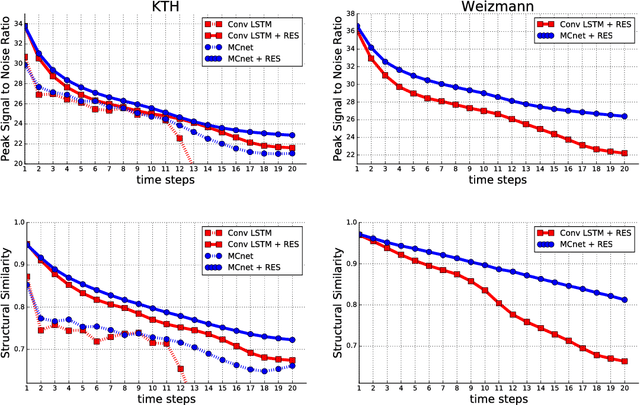

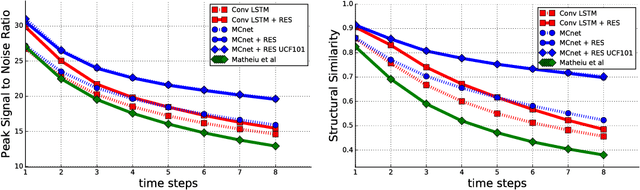
We propose a deep neural network for the prediction of future frames in natural video sequences. To effectively handle complex evolution of pixels in videos, we propose to decompose the motion and content, two key components generating dynamics in videos. Our model is built upon the Encoder-Decoder Convolutional Neural Network and Convolutional LSTM for pixel-level prediction, which independently capture the spatial layout of an image and the corresponding temporal dynamics. By independently modeling motion and content, predicting the next frame reduces to converting the extracted content features into the next frame content by the identified motion features, which simplifies the task of prediction. Our model is end-to-end trainable over multiple time steps, and naturally learns to decompose motion and content without separate training. We evaluate the proposed network architecture on human activity videos using KTH, Weizmann action, and UCF-101 datasets. We show state-of-the-art performance in comparison to recent approaches. To the best of our knowledge, this is the first end-to-end trainable network architecture with motion and content separation to model the spatiotemporal dynamics for pixel-level future prediction in natural videos.