 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition
Apr 01, 2020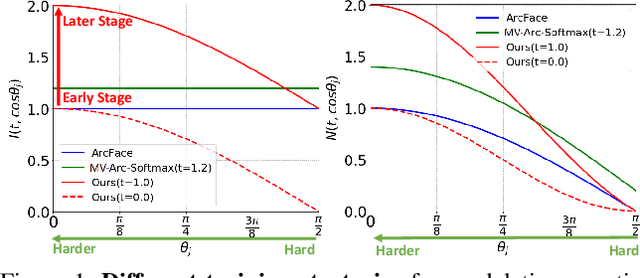
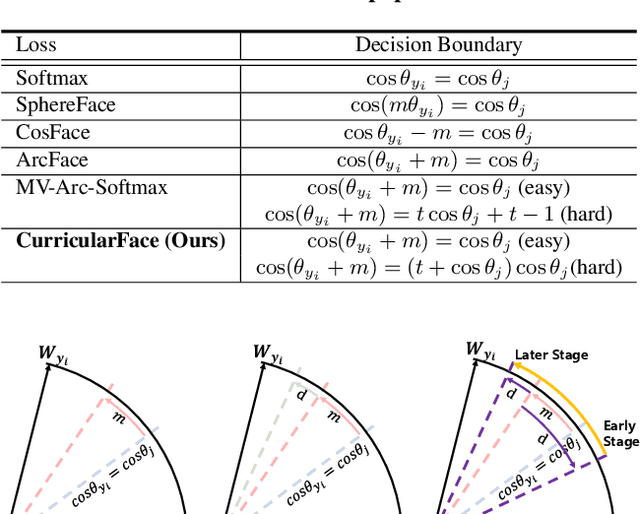
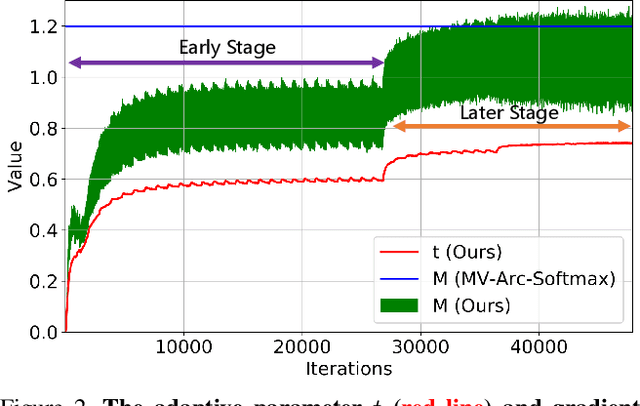
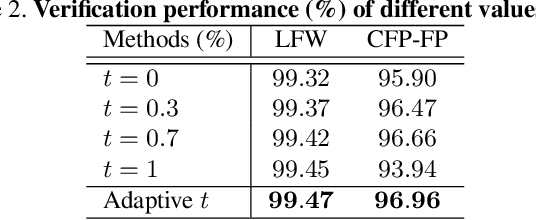
As an emerging topic in face recognition, designing margin-based loss functions can increase the feature margin between different classes for enhanced discriminability. More recently, the idea of mining-based strategies is adopted to emphasize the misclassified samples, achieving promising results. However, during the entire training process, the prior methods either do not explicitly emphasize the sample based on its importance that renders the hard samples not fully exploited; or explicitly emphasize the effects of semi-hard/hard samples even at the early training stage that may lead to convergence issue. In this work, we propose a novel Adaptive Curriculum Learning loss (CurricularFace) that embeds the idea of curriculum learning into the loss function to achieve a novel training strategy for deep face recognition, which mainly addresses easy samples in the early training stage and hard ones in the later stage. Specifically, our CurricularFace adaptively adjusts the relative importance of easy and hard samples during different training stages. In each stage, different samples are assigned with different importance according to their corresponding difficultness. Extensive experimental results on popular benchmarks demonstrate the superiority of our CurricularFace over the state-of-the-art competitors.
ASFD: Automatic and Scalable Face Detector
Mar 31, 2020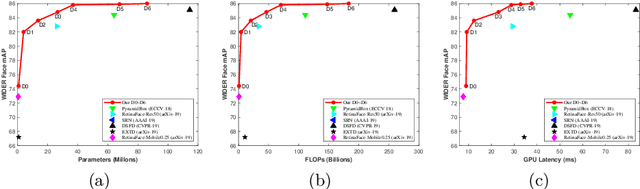

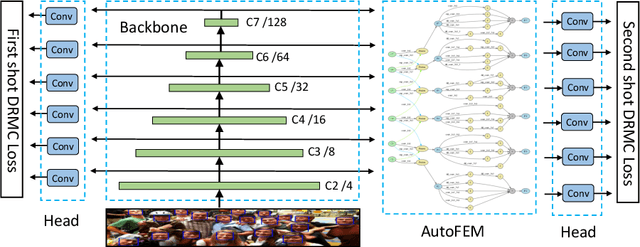

In this paper, we propose a novel Automatic and Scalable Face Detector (ASFD), which is based on a combination of neural architecture search techniques as well as a new loss design. First, we propose an automatic feature enhance module named Auto-FEM by improved differential architecture search, which allows efficient multi-scale feature fusion and context enhancement. Second, we use Distance-based Regression and Margin-based Classification (DRMC) multi-task loss to predict accurate bounding boxes and learn highly discriminative deep features. Third, we adopt compound scaling methods and uniformly scale the backbone, feature modules, and head networks to develop a family of ASFD, which are consistently more efficient than the state-of-the-art face detectors. Extensive experiments conducted on popular benchmarks, e.g. WIDER FACE and FDDB, demonstrate that our ASFD-D6 outperforms the prior strong competitors, and our lightweight ASFD-D0 runs at more than 120 FPS with Mobilenet for VGA-resolution images.
Towards Palmprint Verification On Smartphones
Mar 30, 2020



With the rapid development of mobile devices, smartphones have gradually become an indispensable part of people's lives. Meanwhile, biometric authentication has been corroborated to be an effective method for establishing a person's identity with high confidence. Hence, recently, biometric technologies for smartphones have also become increasingly sophisticated and popular. But it is noteworthy that the application potential of palmprints for smartphones is seriously underestimated. Studies in the past two decades have shown that palmprints have outstanding merits in uniqueness and permanence, and have high user acceptance. However, currently, studies specializing in palmprint verification for smartphones are still quite sporadic, especially when compared to face- or fingerprint-oriented ones. In this paper, aiming to fill the aforementioned research gap, we conducted a thorough study of palmprint verification on smartphones and our contributions are twofold. First, to facilitate the study of palmprint verification on smartphones, we established an annotated palmprint dataset named MPD, which was collected by multi-brand smartphones in two separate sessions with various backgrounds and illumination conditions. As the largest dataset in this field, MPD contains 16,000 palm images collected from 200 subjects. Second, we built a DCNN-based palmprint verification system named DeepMPV+ for smartphones. In DeepMPV+, two key steps, ROI extraction and ROI matching, are both formulated as learning problems and then solved naturally by modern DCNN models. The efficiency and efficacy of DeepMPV+ have been corroborated by extensive experiments. To make our results fully reproducible, the labeled dataset and the relevant source codes have been made publicly available at https://cslinzhang.github.io/MobilePalmPrint/.
Learning by Analogy: Reliable Supervision from Transformations for Unsupervised Optical Flow Estimation
Mar 29, 2020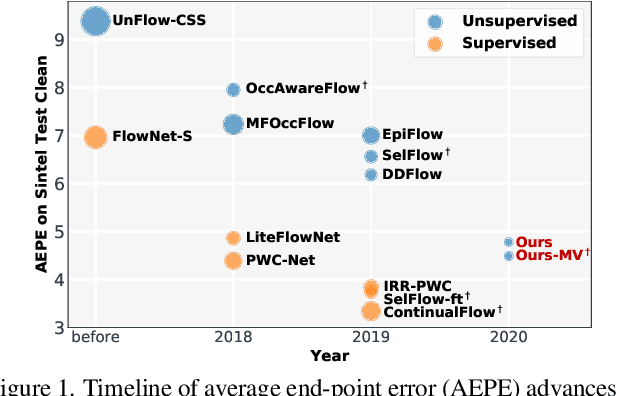
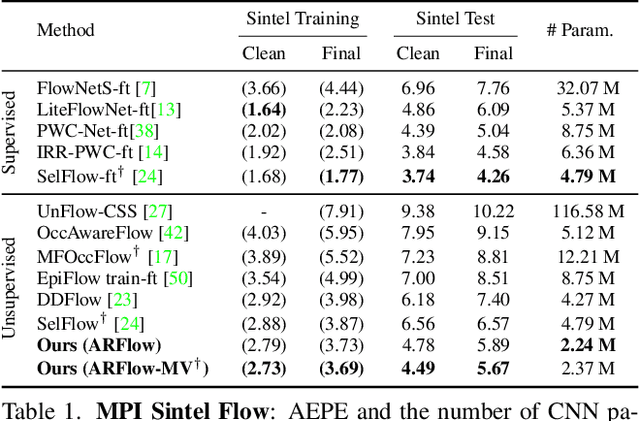
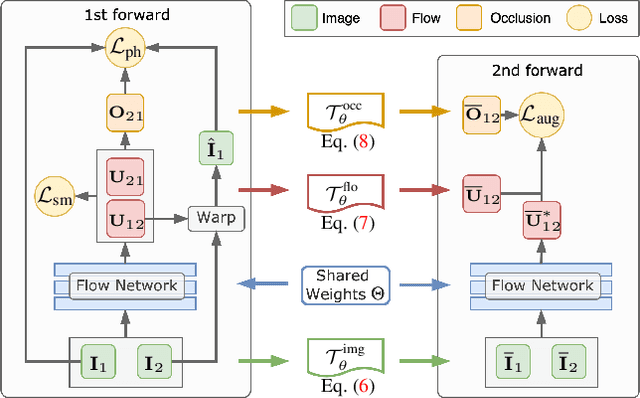
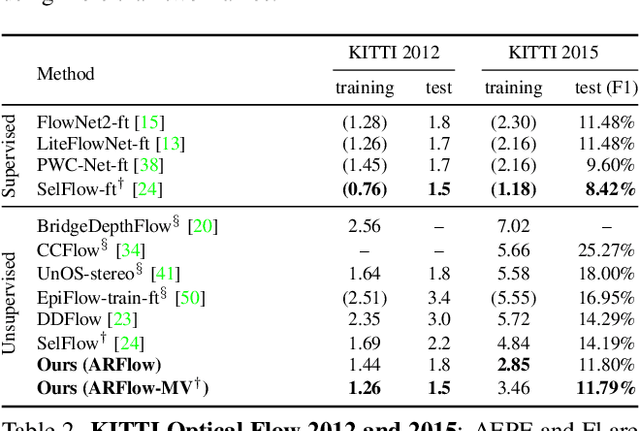
Unsupervised learning of optical flow, which leverages the supervision from view synthesis, has emerged as a promising alternative to supervised methods. However, the objective of unsupervised learning is likely to be unreliable in challenging scenes. In this work, we present a framework to use more reliable supervision from transformations. It simply twists the general unsupervised learning pipeline by running another forward pass with transformed data from augmentation, along with using transformed predictions of original data as the self-supervision signal. Besides, we further introduce a lightweight network with multiple frames by a highly-shared flow decoder. Our method consistently gets a leap of performance on several benchmarks with the best accuracy among deep unsupervised methods. Also, our method achieves competitive results to recent fully supervised methods while with much fewer parameters.
Distribution Distillation Loss: Generic Approach for Improving Face Recognition from Hard Samples
Feb 10, 2020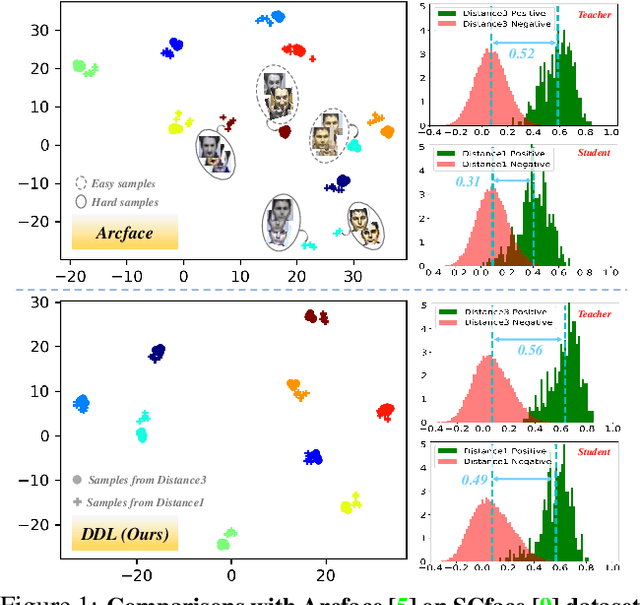
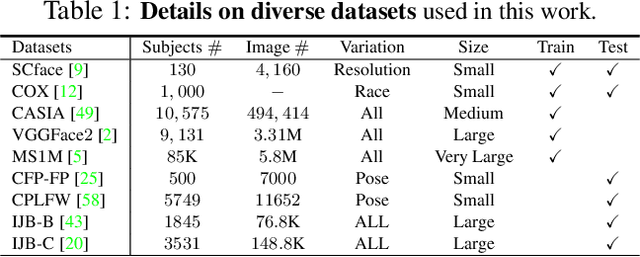
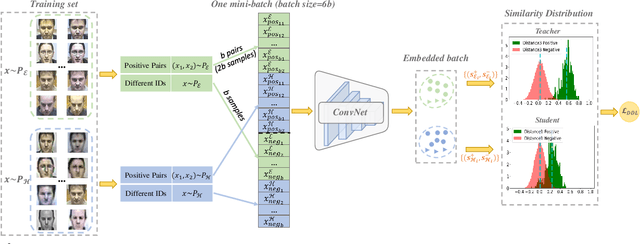
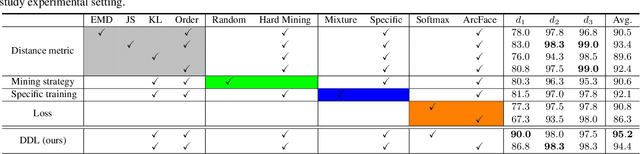
Large facial variations are the main challenge in face recognition. To this end, previous variation-specific methods make full use of task-related prior to design special network losses, which are typically not general among different tasks and scenarios. In contrast, the existing generic methods focus on improving the feature discriminability to minimize the intra-class distance while maximizing the interclass distance, which perform well on easy samples but fail on hard samples. To improve the performance on those hard samples for general tasks, we propose a novel Distribution Distillation Loss to narrow the performance gap between easy and hard samples, which is a simple, effective and generic for various types of facial variations. Specifically, we first adopt state-of-the-art classifiers such as ArcFace to construct two similarity distributions: teacher distribution from easy samples and student distribution from hard samples. Then, we propose a novel distribution-driven loss to constrain the student distribution to approximate the teacher distribution, which thus leads to smaller overlap between the positive and negative pairs in the student distribution. We have conducted extensive experiments on both generic large-scale face benchmarks and benchmarks with diverse variations on race, resolution and pose. The quantitative results demonstrate the superiority of our method over strong baselines, e.g., Arcface and Cosface.
TEINet: Towards an Efficient Architecture for Video Recognition
Nov 21, 2019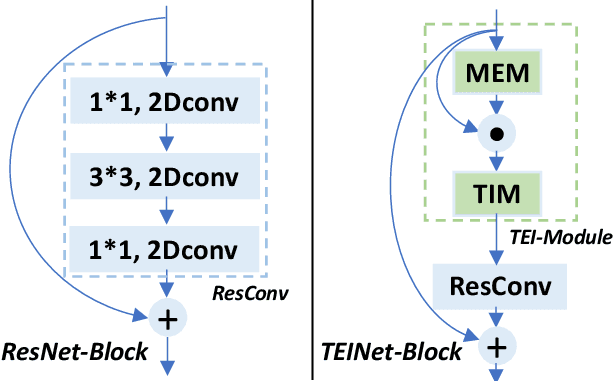
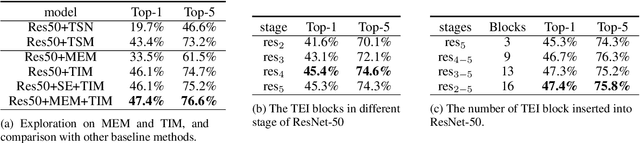
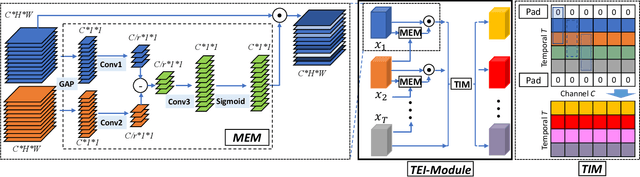
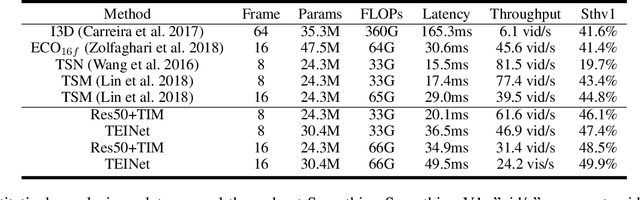
Efficiency is an important issue in designing video architectures for action recognition. 3D CNNs have witnessed remarkable progress in action recognition from videos. However, compared with their 2D counterparts, 3D convolutions often introduce a large amount of parameters and cause high computational cost. To relieve this problem, we propose an efficient temporal module, termed as Temporal Enhancement-and-Interaction (TEI Module), which could be plugged into the existing 2D CNNs (denoted by TEINet). The TEI module presents a different paradigm to learn temporal features by decoupling the modeling of channel correlation and temporal interaction. First, it contains a Motion Enhanced Module (MEM) which is to enhance the motion-related features while suppress irrelevant information (e.g., background). Then, it introduces a Temporal Interaction Module (TIM) which supplements the temporal contextual information in a channel-wise manner. This two-stage modeling scheme is not only able to capture temporal structure flexibly and effectively, but also efficient for model inference. We conduct extensive experiments to verify the effectiveness of TEINet on several benchmarks (e.g., Something-Something V1&V2, Kinetics, UCF101 and HMDB51). Our proposed TEINet can achieve a good recognition accuracy on these datasets but still preserve a high efficiency.
Fast Learning of Temporal Action Proposal via Dense Boundary Generator
Nov 11, 2019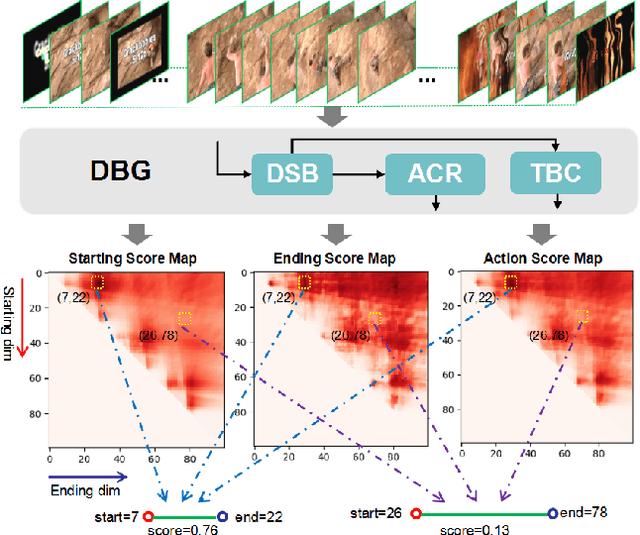
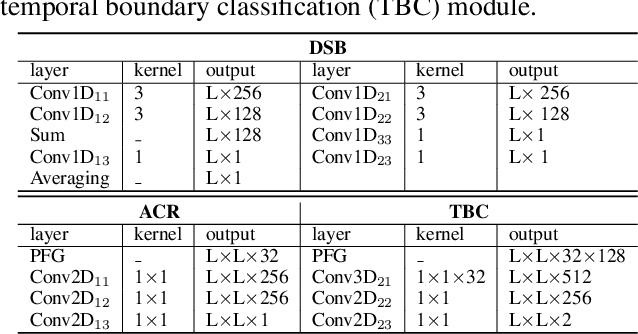
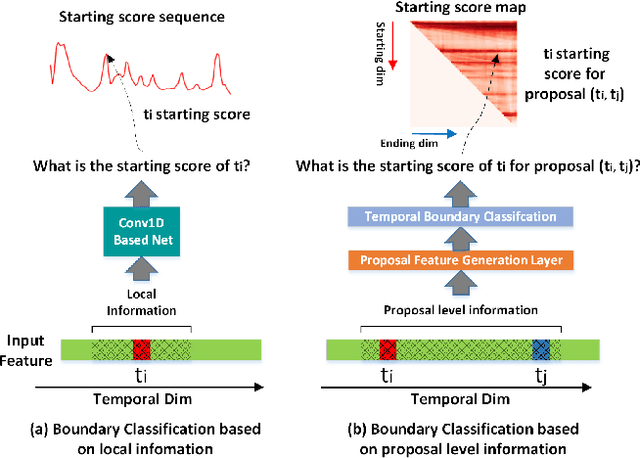
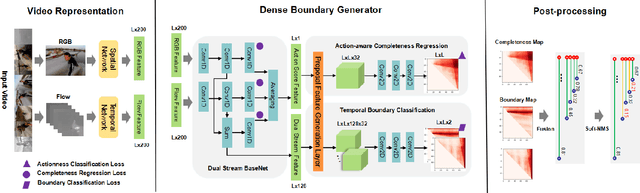
Generating temporal action proposals remains a very challenging problem, where the main issue lies in predicting precise temporal proposal boundaries and reliable action confidence in long and untrimmed real-world videos. In this paper, we propose an efficient and unified framework to generate temporal action proposals named Dense Boundary Generator (DBG), which draws inspiration from boundary-sensitive methods and implements boundary classification and action completeness regression for densely distributed proposals. In particular, the DBG consists of two modules: Temporal boundary classification (TBC) and Action-aware completeness regression (ACR). The TBC aims to provide two temporal boundary confidence maps by low-level two-stream features, while the ACR is designed to generate an action completeness score map by high-level action-aware features. Moreover, we introduce a dual stream BaseNet (DSB) to encode RGB and optical flow information, which helps to capture discriminative boundary and actionness features. Extensive experiments on popular benchmarks ActivityNet-1.3 and THUMOS14 demonstrate the superiority of DBG over the state-of-the-art proposal generator (e.g., MGG and BMN). Our code will be made available upon publication.
Anti-Confusing: Region-Aware Network for Human Pose Estimation
May 27, 2019
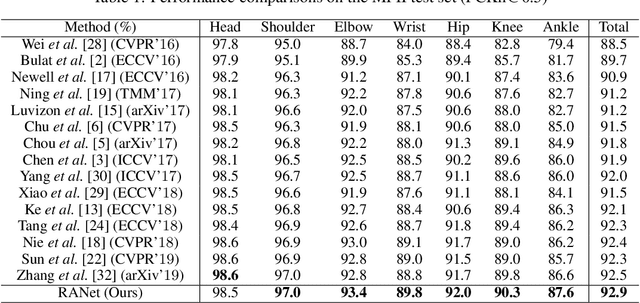
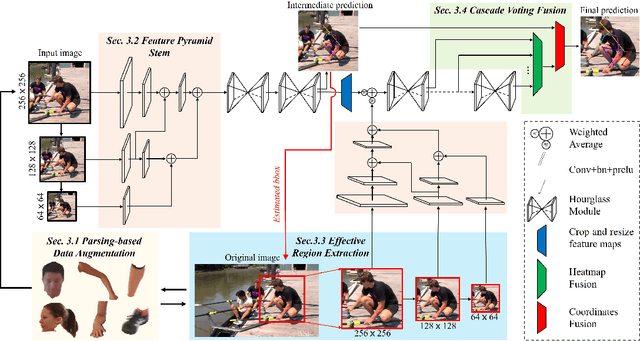
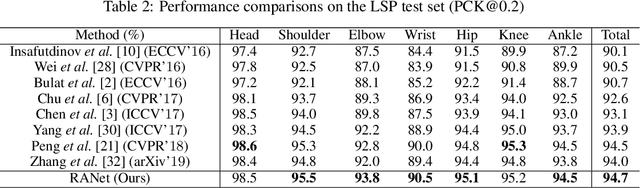
In this work, we propose a novel framework named Region-Aware Network (RANet), which learns the ability of anti-confusing in case of heavy occlusion, nearby person and symmetric appearance, for human pose estimation. Specifically, the proposed method addresses three key aspects, i.e., data augmentation, feature learning and prediction fusion, respectively. First, we propose Parsing-based Data Augmentation (PDA) to generate abundant data that synthesizes confusing textures. Second, we not only propose a Feature Pyramid Stem (FPS) to learn stronger low-level features in lower stage; but also incorporate an Effective Region Extraction (ERE) module to excavate better target-specific features. Third, we introduce Cascade Voting Fusion (CVF) to explicitly exclude the inferior predictions and fuse the rest effective predictions for the final pose estimation. Extensive experimental results on two popular benchmarks, i.e. MPII and LSP, demonstrate the effectiveness of our method against the state-of-the-art competitors. Especially on easily-confusable joints, our method makes significant improvement.
Aurora Guard: Real-Time Face Anti-Spoofing via Light Reflection
Feb 27, 2019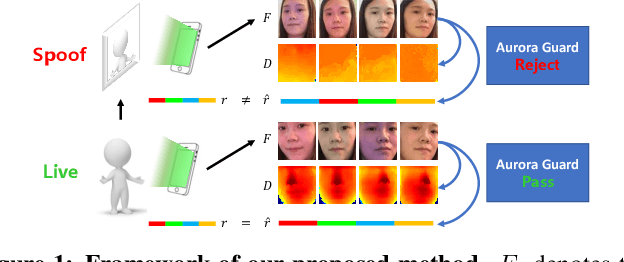
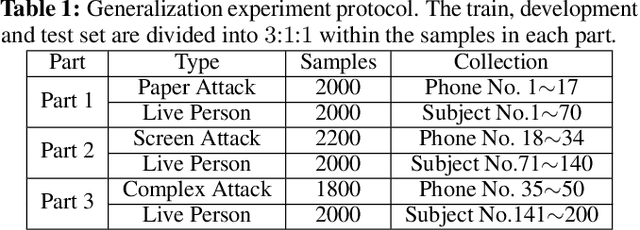
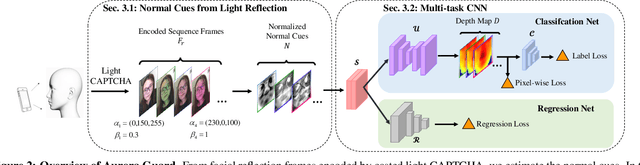
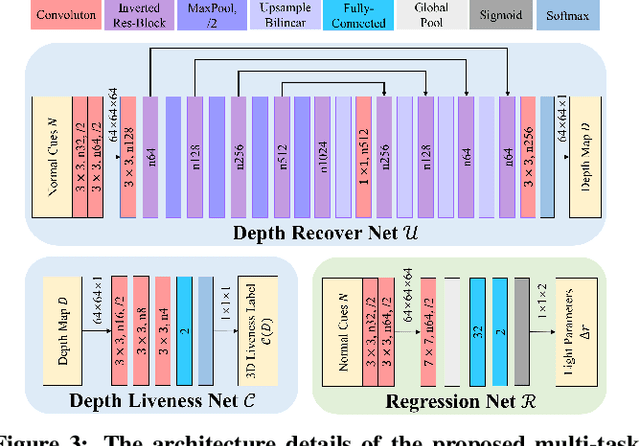
In this paper, we propose a light reflection based face anti-spoofing method named Aurora Guard (AG), which is fast, simple yet effective that has already been deployed in real-world systems serving for millions of users. Specifically, our method first extracts the normal cues via light reflection analysis, and then uses an end-to-end trainable multi-task Convolutional Neural Network (CNN) to not only recover subjects' depth maps to assist liveness classification, but also provide the light CAPTCHA checking mechanism in the regression branch to further improve the system reliability. Moreover, we further collect a large-scale dataset containing $12,000$ live and spoofing samples, which covers abundant imaging qualities and Presentation Attack Instruments (PAI). Extensive experiments on both public and our datasets demonstrate the superiority of our proposed method over the state of the arts.
Towards Highly Accurate and Stable Face Alignment for High-Resolution Videos
Nov 01, 2018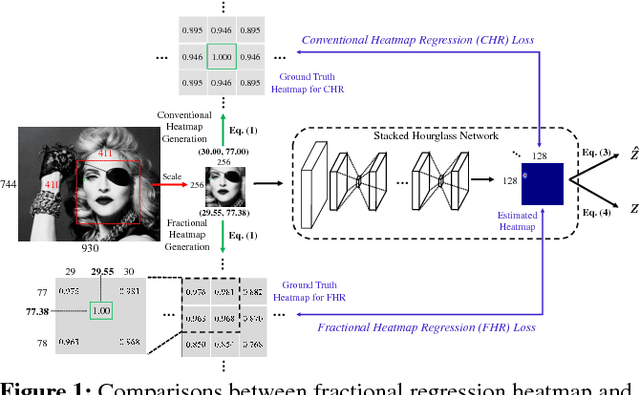
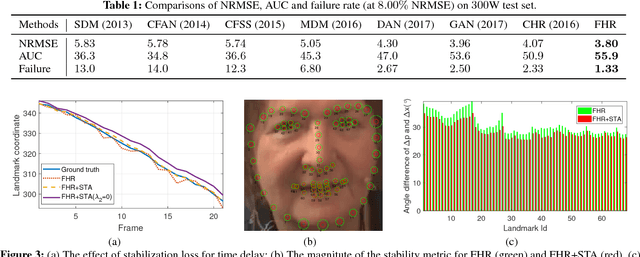
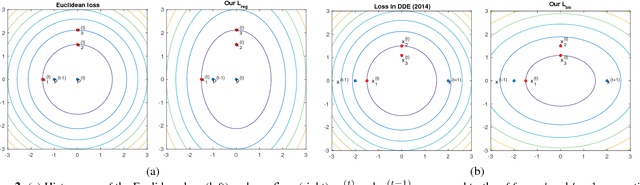
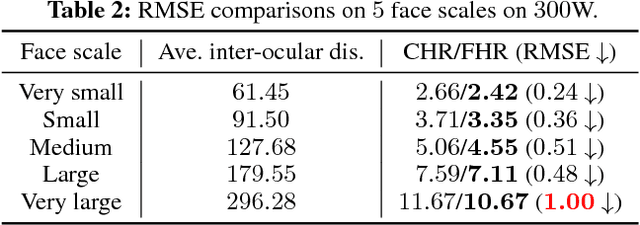
In recent years, heatmap regression based models have shown their effectiveness in face alignment and pose estimation. However, Conventional Heatmap Regression (CHR) is not accurate nor stable when dealing with high-resolution facial videos, since it finds the maximum activated location in heatmaps which are generated from rounding coordinates, and thus leads to quantization errors when scaling back to the original high-resolution space. In this paper, we propose a Fractional Heatmap Regression (FHR) for high-resolution video-based face alignment. The proposed FHR can accurately estimate the fractional part according to the 2D Gaussian function by sampling three points in heatmaps. To further stabilize the landmarks among continuous video frames while maintaining the precise at the same time, we propose a novel stabilization loss that contains two terms to address time delay and non-smooth issues, respectively. Experiments on 300W, 300-VW and Talking Face datasets clearly demonstrate that the proposed method is more accurate and stable than the state-of-the-art models.