 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025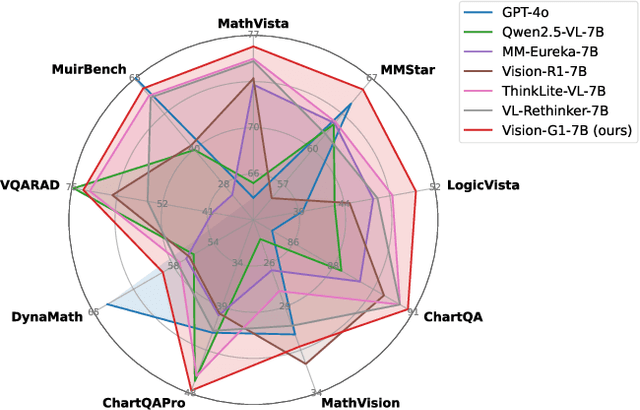

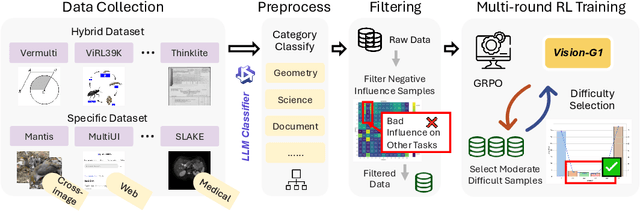

Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
AMFT: Aligning LLM Reasoners by Meta-Learning the Optimal Imitation-Exploration Balance
Aug 12, 2025Large Language Models (LLMs) are typically fine-tuned for reasoning tasks through a two-stage pipeline of Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL), a process fraught with catastrophic forgetting and suboptimal trade-offs between imitation and exploration. Recent single-stage methods attempt to unify SFT and RL using heuristics, but lack a principled mechanism for dynamically balancing the two paradigms. In this paper, we reframe this challenge through the theoretical lens of \textbf{implicit rewards}, viewing SFT and RL not as distinct methods but as complementary reward signals. We introduce \textbf{Adaptive Meta Fine-Tuning (AMFT)}, a novel single-stage algorithm that learns the optimal balance between SFT's implicit, path-level reward and RL's explicit, outcome-based reward. The core of AMFT is a \textbf{meta-gradient adaptive weight controller} that treats the SFT-RL balance as a learnable parameter, dynamically optimizing it to maximize long-term task performance. This forward-looking approach, regularized by policy entropy for stability, autonomously discovers an effective training curriculum. We conduct a comprehensive evaluation on challenging benchmarks spanning mathematical reasoning, abstract visual reasoning (General Points), and vision-language navigation (V-IRL). AMFT consistently establishes a new state-of-the-art and demonstrats superior generalization on out-of-distribution (OOD) tasks. Ablation studies and training dynamic analysis confirm that the meta-learning controller is crucial for AMFT's stability, sample efficiency, and performance, offering a more principled and effective paradigm for LLM alignment. Our codes are open-sourced via https://github.com/hlxtsyj/AMFT.
UniMove: A Unified Model for Multi-city Human Mobility Prediction
Aug 09, 2025Human mobility prediction is vital for urban planning, transportation optimization, and personalized services. However, the inherent randomness, non-uniform time intervals, and complex patterns of human mobility, compounded by the heterogeneity introduced by varying city structures, infrastructure, and population densities, present significant challenges in modeling. Existing solutions often require training separate models for each city due to distinct spatial representations and geographic coverage. In this paper, we propose UniMove, a unified model for multi-city human mobility prediction, addressing two challenges: (1) constructing universal spatial representations for effective token sharing across cities, and (2) modeling heterogeneous mobility patterns from varying city characteristics. We propose a trajectory-location dual-tower architecture, with a location tower for universal spatial encoding and a trajectory tower for sequential mobility modeling. We also design MoE Transformer blocks to adaptively select experts to handle diverse movement patterns. Extensive experiments across multiple datasets from diverse cities demonstrate that UniMove truly embodies the essence of a unified model. By enabling joint training on multi-city data with mutual data enhancement, it significantly improves mobility prediction accuracy by over 10.2\%. UniMove represents a key advancement toward realizing a true foundational model with a unified architecture for human mobility. We release the implementation at https://github.com/tsinghua-fib-lab/UniMove/.
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Jul 31, 20253D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
Mem4Nav: Boosting Vision-and-Language Navigation in Urban Environments with a Hierarchical Spatial-Cognition Long-Short Memory System
Jun 24, 2025Vision-and-Language Navigation (VLN) in large-scale urban environments requires embodied agents to ground linguistic instructions in complex scenes and recall relevant experiences over extended time horizons. Prior modular pipelines offer interpretability but lack unified memory, while end-to-end (M)LLM agents excel at fusing vision and language yet remain constrained by fixed context windows and implicit spatial reasoning. We introduce \textbf{Mem4Nav}, a hierarchical spatial-cognition long-short memory system that can augment any VLN backbone. Mem4Nav fuses a sparse octree for fine-grained voxel indexing with a semantic topology graph for high-level landmark connectivity, storing both in trainable memory tokens embedded via a reversible Transformer. Long-term memory (LTM) compresses and retains historical observations at both octree and graph nodes, while short-term memory (STM) caches recent multimodal entries in relative coordinates for real-time obstacle avoidance and local planning. At each step, STM retrieval sharply prunes dynamic context, and, when deeper history is needed, LTM tokens are decoded losslessly to reconstruct past embeddings. Evaluated on Touchdown and Map2Seq across three backbones (modular, state-of-the-art VLN with prompt-based LLM, and state-of-the-art VLN with strided-attention MLLM), Mem4Nav yields 7-13 pp gains in Task Completion, sufficient SPD reduction, and >10 pp nDTW improvement. Ablations confirm the indispensability of both the hierarchical map and dual memory modules. Our codes are open-sourced via https://github.com/tsinghua-fib-lab/Mem4Nav.
CAMS: A CityGPT-Powered Agentic Framework for Urban Human Mobility Simulation
Jun 16, 2025Human mobility simulation plays a crucial role in various real-world applications. Recently, to address the limitations of traditional data-driven approaches, researchers have explored leveraging the commonsense knowledge and reasoning capabilities of large language models (LLMs) to accelerate human mobility simulation. However, these methods suffer from several critical shortcomings, including inadequate modeling of urban spaces and poor integration with both individual mobility patterns and collective mobility distributions. To address these challenges, we propose \textbf{C}ityGPT-Powered \textbf{A}gentic framework for \textbf{M}obility \textbf{S}imulation (\textbf{CAMS}), an agentic framework that leverages the language based urban foundation model to simulate human mobility in urban space. \textbf{CAMS} comprises three core modules, including MobExtractor to extract template mobility patterns and synthesize new ones based on user profiles, GeoGenerator to generate anchor points considering collective knowledge and generate candidate urban geospatial knowledge using an enhanced version of CityGPT, TrajEnhancer to retrieve spatial knowledge based on mobility patterns and generate trajectories with real trajectory preference alignment via DPO. Experiments on real-world datasets show that \textbf{CAMS} achieves superior performance without relying on externally provided geospatial information. Moreover, by holistically modeling both individual mobility patterns and collective mobility constraints, \textbf{CAMS} generates more realistic and plausible trajectories. In general, \textbf{CAMS} establishes a new paradigm that integrates the agentic framework with urban-knowledgeable LLMs for human mobility simulation.
Breaking Data Silos: Towards Open and Scalable Mobility Foundation Models via Generative Continual Learning
Jun 07, 2025Foundation models have revolutionized fields such as natural language processing and computer vision by enabling general-purpose learning across diverse tasks and datasets. However, building analogous models for human mobility remains challenging due to the privacy-sensitive nature of mobility data and the resulting data silos across institutions. To bridge this gap, we propose MoveGCL, a scalable and privacy-preserving framework for training mobility foundation models via generative continual learning. Without sharing raw data, MoveGCL enables decentralized and progressive model evolution by replaying synthetic trajectories generated from a frozen teacher model, and reinforces knowledge retention through a tailored distillation strategy that mitigates catastrophic forgetting. To address the heterogeneity of mobility patterns, MoveGCL incorporates a Mixture-of-Experts Transformer with a mobility-aware expert routing mechanism, and employs a layer-wise progressive adaptation strategy to stabilize continual updates. Experiments on six real-world urban datasets demonstrate that MoveGCL achieves performance comparable to joint training and significantly outperforms federated learning baselines, while offering strong privacy protection. MoveGCL marks a crucial step toward unlocking foundation models for mobility, offering a practical blueprint for open, scalable, and privacy-preserving model development in the era of foundation models.
UrbanPlanBench: A Comprehensive Urban Planning Benchmark for Evaluating Large Language Models
Apr 23, 2025The advent of Large Language Models (LLMs) holds promise for revolutionizing various fields traditionally dominated by human expertise. Urban planning, a professional discipline that fundamentally shapes our daily surroundings, is one such field heavily relying on multifaceted domain knowledge and experience of human experts. The extent to which LLMs can assist human practitioners in urban planning remains largely unexplored. In this paper, we introduce a comprehensive benchmark, UrbanPlanBench, tailored to evaluate the efficacy of LLMs in urban planning, which encompasses fundamental principles, professional knowledge, and management and regulations, aligning closely with the qualifications expected of human planners. Through extensive evaluation, we reveal a significant imbalance in the acquisition of planning knowledge among LLMs, with even the most proficient models falling short of meeting professional standards. For instance, we observe that 70% of LLMs achieve subpar performance in understanding planning regulations compared to other aspects. Besides the benchmark, we present the largest-ever supervised fine-tuning (SFT) dataset, UrbanPlanText, comprising over 30,000 instruction pairs sourced from urban planning exams and textbooks. Our findings demonstrate that fine-tuned models exhibit enhanced performance in memorization tests and comprehension of urban planning knowledge, while there exists significant room for improvement, particularly in tasks requiring domain-specific terminology and reasoning. By making our benchmark, dataset, and associated evaluation and fine-tuning toolsets publicly available at https://github.com/tsinghua-fib-lab/PlanBench, we aim to catalyze the integration of LLMs into practical urban planning, fostering a symbiotic collaboration between human expertise and machine intelligence.
A Survey of Large Language Model-Powered Spatial Intelligence Across Scales: Advances in Embodied Agents, Smart Cities, and Earth Science
Apr 14, 2025Over the past year, the development of large language models (LLMs) has brought spatial intelligence into focus, with much attention on vision-based embodied intelligence. However, spatial intelligence spans a broader range of disciplines and scales, from navigation and urban planning to remote sensing and earth science. What are the differences and connections between spatial intelligence across these fields? In this paper, we first review human spatial cognition and its implications for spatial intelligence in LLMs. We then examine spatial memory, knowledge representations, and abstract reasoning in LLMs, highlighting their roles and connections. Finally, we analyze spatial intelligence across scales -- from embodied to urban and global levels -- following a framework that progresses from spatial memory and understanding to spatial reasoning and intelligence. Through this survey, we aim to provide insights into interdisciplinary spatial intelligence research and inspire future studies.
EgoSplat: Open-Vocabulary Egocentric Scene Understanding with Language Embedded 3D Gaussian Splatting
Mar 14, 2025



Egocentric scenes exhibit frequent occlusions, varied viewpoints, and dynamic interactions compared to typical scene understanding tasks. Occlusions and varied viewpoints can lead to multi-view semantic inconsistencies, while dynamic objects may act as transient distractors, introducing artifacts into semantic feature modeling. To address these challenges, we propose EgoSplat, a language-embedded 3D Gaussian Splatting framework for open-vocabulary egocentric scene understanding. A multi-view consistent instance feature aggregation method is designed to leverage the segmentation and tracking capabilities of SAM2 to selectively aggregate complementary features across views for each instance, ensuring precise semantic representation of scenes. Additionally, an instance-aware spatial-temporal transient prediction module is constructed to improve spatial integrity and temporal continuity in predictions by incorporating spatial-temporal associations across multi-view instances, effectively reducing artifacts in the semantic reconstruction of egocentric scenes. EgoSplat achieves state-of-the-art performance in both localization and segmentation tasks on two datasets, outperforming existing methods with a 8.2% improvement in localization accuracy and a 3.7% improvement in segmentation mIoU on the ADT dataset, and setting a new benchmark in open-vocabulary egocentric scene understanding. The code will be made publicly available.