 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlangDIT: Benchmarking LLMs in Interpretative Slang Translation
May 20, 2025The challenge of slang translation lies in capturing context-dependent semantic extensions, as slang terms often convey meanings beyond their literal interpretation. While slang detection, explanation, and translation have been studied as isolated tasks in the era of large language models (LLMs), their intrinsic interdependence remains underexplored. The main reason is lacking of a benchmark where the two tasks can be a prerequisite for the third one, which can facilitate idiomatic translation. In this paper, we introduce the interpretative slang translation task (named SlangDIT) consisting of three sub-tasks: slang detection, cross-lingual slang explanation, and slang translation within the current context, aiming to generate more accurate translation with the help of slang detection and slang explanation. To this end, we construct a SlangDIT dataset, containing over 25k English-Chinese sentence pairs. Each source sentence mentions at least one slang term and is labeled with corresponding cross-lingual slang explanation. Based on the benchmark, we propose a deep thinking model, named SlangOWL. It firstly identifies whether the sentence contains a slang, and then judges whether the slang is polysemous and analyze its possible meaning. Further, the SlangOWL provides the best explanation of the slang term targeting on the current context. Finally, according to the whole thought, the SlangOWL offers a suitable translation. Our experiments on LLMs (\emph{e.g.}, Qwen2.5 and LLama-3.1), show that our deep thinking approach indeed enhances the performance of LLMs where the proposed SLangOWL significantly surpasses the vanilla models and supervised fine-tuned models without thinking.
THOR-MoE: Hierarchical Task-Guided and Context-Responsive Routing for Neural Machine Translation
May 20, 2025The sparse Mixture-of-Experts (MoE) has achieved significant progress for neural machine translation (NMT). However, there exist two limitations in current MoE solutions which may lead to sub-optimal performance: 1) they directly use the task knowledge of NMT into MoE (\emph{e.g.}, domain/linguistics-specific knowledge), which are generally unavailable at practical application and neglect the naturally grouped domain/linguistic properties; 2) the expert selection only depends on the localized token representation without considering the context, which fully grasps the state of each token in a global view. To address the above limitations, we propose THOR-MoE via arming the MoE with hierarchical task-guided and context-responsive routing policies. Specifically, it 1) firstly predicts the domain/language label and then extracts mixed domain/language representation to allocate task-level experts in a hierarchical manner; 2) injects the context information to enhance the token routing from the pre-selected task-level experts set, which can help each token to be accurately routed to more specialized and suitable experts. Extensive experiments on multi-domain translation and multilingual translation benchmarks with different architectures consistently demonstrate the superior performance of THOR-MoE. Additionally, the THOR-MoE operates as a plug-and-play module compatible with existing Top-$k$~\cite{shazeer2017} and Top-$p$~\cite{huang-etal-2024-harder} routing schemes, ensuring broad applicability across diverse MoE architectures. For instance, compared with vanilla Top-$p$~\cite{huang-etal-2024-harder} routing, the context-aware manner can achieve an average improvement of 0.75 BLEU with less than 22\% activated parameters on multi-domain translation tasks.
An Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025



Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
ExTrans: Multilingual Deep Reasoning Translation via Exemplar-Enhanced Reinforcement Learning
May 19, 2025In recent years, the emergence of large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, has shown impressive capabilities in complex problems, e.g., mathematics and coding. Some pioneering studies attempt to bring the success of LRMs in neural machine translation (MT). They try to build LRMs with deep reasoning MT ability via reinforcement learning (RL). Despite some progress that has been made, these attempts generally focus on several high-resource languages, e.g., English and Chinese, leaving the performance on other languages unclear. Besides, the reward modeling methods in previous work do not fully unleash the potential of reinforcement learning in MT. In this work, we first design a new reward modeling method that compares the translation results of the policy MT model with a strong LRM (i.e., DeepSeek-R1-671B), and quantifies the comparisons to provide rewards. Experimental results demonstrate the superiority of the reward modeling method. Using Qwen2.5-7B-Instruct as the backbone, the trained model achieves the new state-of-the-art performance in literary translation, and outperforms strong LRMs including OpenAI-o1 and DeepSeeK-R1. Furthermore, we extend our method to the multilingual settings with 11 languages. With a carefully designed lightweight reward modeling in RL, we can simply transfer the strong MT ability from a single direction into multiple (i.e., 90) translation directions and achieve impressive multilingual MT performance.
Efficient Speech Language Modeling via Energy Distance in Continuous Latent Space
May 19, 2025We introduce SLED, an alternative approach to speech language modeling by encoding speech waveforms into sequences of continuous latent representations and modeling them autoregressively using an energy distance objective. The energy distance offers an analytical measure of the distributional gap by contrasting simulated and target samples, enabling efficient training to capture the underlying continuous autoregressive distribution. By bypassing reliance on residual vector quantization, SLED avoids discretization errors and eliminates the need for the complicated hierarchical architectures common in existing speech language models. It simplifies the overall modeling pipeline while preserving the richness of speech information and maintaining inference efficiency. Empirical results demonstrate that SLED achieves strong performance in both zero-shot and streaming speech synthesis, showing its potential for broader applications in general-purpose speech language models.
Task-Core Memory Management and Consolidation for Long-term Continual Learning
May 15, 2025



In this paper, we focus on a long-term continual learning (CL) task, where a model learns sequentially from a stream of vast tasks over time, acquiring new knowledge while retaining previously learned information in a manner akin to human learning. Unlike traditional CL settings, long-term CL involves handling a significantly larger number of tasks, which exacerbates the issue of catastrophic forgetting. Our work seeks to address two critical questions: 1) How do existing CL methods perform in the context of long-term CL? and 2) How can we mitigate the catastrophic forgetting that arises from prolonged sequential updates? To tackle these challenges, we propose a novel framework inspired by human memory mechanisms for long-term continual learning (Long-CL). Specifically, we introduce a task-core memory management strategy to efficiently index crucial memories and adaptively update them as learning progresses. Additionally, we develop a long-term memory consolidation mechanism that selectively retains hard and discriminative samples, ensuring robust knowledge retention. To facilitate research in this area, we construct and release two multi-modal and textual benchmarks, MMLongCL-Bench and TextLongCL-Bench, providing a valuable resource for evaluating long-term CL approaches. Experimental results show that Long-CL outperforms the previous state-of-the-art by 7.4\% and 6.5\% AP on the two benchmarks, respectively, demonstrating the effectiveness of our approach.
Reinforced Interactive Continual Learning via Real-time Noisy Human Feedback
May 15, 2025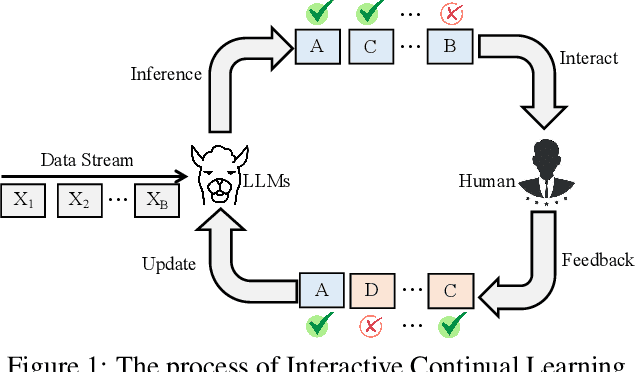
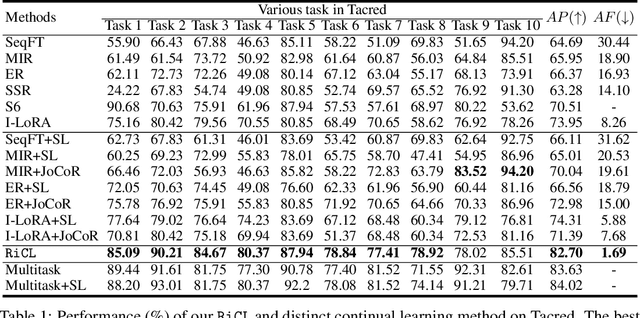
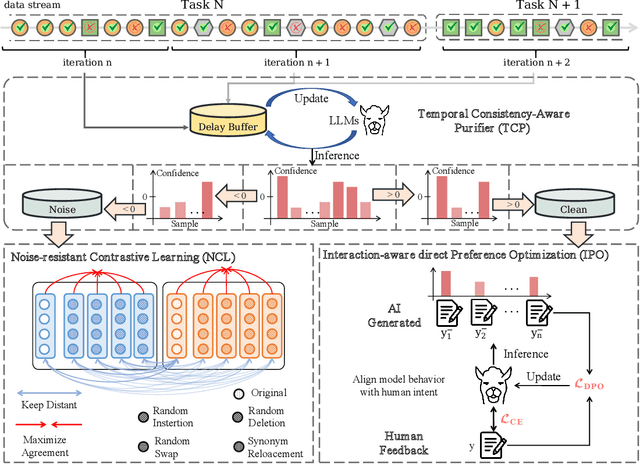

This paper introduces an interactive continual learning paradigm where AI models dynamically learn new skills from real-time human feedback while retaining prior knowledge. This paradigm distinctively addresses two major limitations of traditional continual learning: (1) dynamic model updates using streaming, real-time human-annotated data, rather than static datasets with fixed labels, and (2) the assumption of clean labels, by explicitly handling the noisy feedback common in real-world interactions. To tackle these problems, we propose RiCL, a Reinforced interactive Continual Learning framework leveraging Large Language Models (LLMs) to learn new skills effectively from dynamic feedback. RiCL incorporates three key components: a temporal consistency-aware purifier to automatically discern clean from noisy samples in data streams; an interaction-aware direct preference optimization strategy to align model behavior with human intent by reconciling AI-generated and human-provided feedback; and a noise-resistant contrastive learning module that captures robust representations by exploiting inherent data relationships, thus avoiding reliance on potentially unreliable labels. Extensive experiments on two benchmark datasets (FewRel and TACRED), contaminated with realistic noise patterns, demonstrate that our RiCL approach substantially outperforms existing combinations of state-of-the-art online continual learning and noisy-label learning methods.
Continuous Visual Autoregressive Generation via Score Maximization
May 12, 2025



Conventional wisdom suggests that autoregressive models are used to process discrete data. When applied to continuous modalities such as visual data, Visual AutoRegressive modeling (VAR) typically resorts to quantization-based approaches to cast the data into a discrete space, which can introduce significant information loss. To tackle this issue, we introduce a Continuous VAR framework that enables direct visual autoregressive generation without vector quantization. The underlying theoretical foundation is strictly proper scoring rules, which provide powerful statistical tools capable of evaluating how well a generative model approximates the true distribution. Within this framework, all we need is to select a strictly proper score and set it as the training objective to optimize. We primarily explore a class of training objectives based on the energy score, which is likelihood-free and thus overcomes the difficulty of making probabilistic predictions in the continuous space. Previous efforts on continuous autoregressive generation, such as GIVT and diffusion loss, can also be derived from our framework using other strictly proper scores. Source code: https://github.com/shaochenze/EAR.
Examining the Source of Defects from a Mechanical Perspective for 3D Anomaly Detection
May 09, 2025In this paper, we go beyond identifying anomalies only in structural terms and think about better anomaly detection motivated by anomaly causes. Most anomalies are regarded as the result of unpredictable defective forces from internal and external sources, and their opposite forces are sought to correct the anomalies. We introduced a Mechanics Complementary framework for 3D anomaly detection (MC4AD) to generate internal and external Corrective forces for each point. A Diverse Anomaly-Generation (DA-Gen) module is first proposed to simulate various anomalies. Then, we present a Corrective Force Prediction Network (CFP-Net) with complementary representations for point-level representation to simulate the different contributions of internal and external corrective forces. A combined loss was proposed, including a new symmetric loss and an overall loss, to constrain the corrective forces properly. As a highlight, we consider 3D anomaly detection in industry more comprehensively, creating a hierarchical quality control strategy based on a three-way decision and contributing a dataset named Anomaly-IntraVariance with intraclass variance to evaluate the model. On the proposed and existing five datasets, we obtained nine state-of-the-art performers with the minimum parameters and the fastest inference speed. The source is available at https://github.com/hzzzzzhappy/MC4AD
ConCISE: Confidence-guided Compression in Step-by-step Efficient Reasoning
May 08, 2025Large Reasoning Models (LRMs) perform strongly in complex reasoning tasks via Chain-of-Thought (CoT) prompting, but often suffer from verbose outputs caused by redundant content, increasing computational overhead, and degrading user experience. Existing compression methods either operate post-hoc pruning, risking disruption to reasoning coherence, or rely on sampling-based selection, which fails to intervene effectively during generation. In this work, we introduce a confidence-guided perspective to explain the emergence of redundant reflection in LRMs, identifying two key patterns: Confidence Deficit, where the model reconsiders correct steps due to low internal confidence, and Termination Delay, where reasoning continues even after reaching a confident answer. Based on this analysis, we propose ConCISE (Confidence-guided Compression In Step-by-step Efficient Reasoning), a framework that simplifies reasoning chains by reinforcing the model's confidence during inference, thus preventing the generation of redundant reflection steps. It integrates Confidence Injection to stabilize intermediate steps and Early Stopping to terminate reasoning when confidence is sufficient. Extensive experiments demonstrate that fine-tuning LRMs on ConCISE-generated data yields significantly shorter outputs, reducing length by up to approximately 50% under SimPO, while maintaining high task accuracy. ConCISE consistently outperforms existing baselines across multiple reasoning benchmarks.