 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Code: Simple Temporal Latent Code for Efficient Dynamic View Synthesis
Dec 18, 2023Novel view synthesis for dynamic scenes is one of the spotlights in computer vision. The key to efficient dynamic view synthesis is to find a compact representation to store the information across time. Though existing methods achieve fast dynamic view synthesis by tensor decomposition or hash grid feature concatenation, their mixed representations ignore the structural difference between time domain and spatial domain, resulting in sub-optimal computation and storage cost. This paper presents T-Code, the efficient decoupled latent code for the time dimension only. The decomposed feature design enables customizing modules to cater for different scenarios with individual specialty and yielding desired results at lower cost. Based on T-Code, we propose our highly compact hybrid neural graphics primitives (HybridNGP) for multi-camera setting and deformation neural graphics primitives with T-Code (DNGP-T) for monocular scenario. Experiments show that HybridNGP delivers high fidelity results at top processing speed with much less storage consumption, while DNGP-T achieves state-of-the-art quality and high training speed for monocular reconstruction.
PnPNet: Pull-and-Push Networks for Volumetric Segmentation with Boundary Confusion
Dec 13, 2023



Precise boundary segmentation of volumetric images is a critical task for image-guided diagnosis and computer-assisted intervention, especially for boundary confusion in clinical practice. However, U-shape networks cannot effectively resolve this challenge due to the lack of boundary shape constraints. Besides, existing methods of refining boundaries overemphasize the slender structure, which results in the overfitting phenomenon due to networks' limited abilities to model tiny objects. In this paper, we reconceptualize the mechanism of boundary generation by encompassing the interaction dynamics with adjacent regions. Moreover, we propose a unified network termed PnPNet to model shape characteristics of the confused boundary region. Core ingredients of PnPNet contain the pushing and pulling branches. Specifically, based on diffusion theory, we devise the semantic difference module (SDM) from the pushing branch to squeeze the boundary region. Explicit and implicit differential information inside SDM significantly boost representation abilities for inter-class boundaries. Additionally, motivated by the K-means algorithm, the class clustering module (CCM) from the pulling branch is introduced to stretch the intersected boundary region. Thus, pushing and pulling branches will shrink and enlarge the boundary uncertainty respectively. They furnish two adversarial forces to promote models to output a more precise delineation of boundaries. We carry out experiments on three challenging public datasets and one in-house dataset, containing three types of boundary confusion in model predictions. Experimental results demonstrate the superiority of PnPNet over other segmentation networks, especially on evaluation metrics of HD and ASSD. Besides, pushing and pulling branches can serve as plug-and-play modules to enhance classic U-shape baseline models. Codes are available.
SRSNetwork: Siamese Reconstruction-Segmentation Networks based on Dynamic-Parameter Convolution
Dec 04, 2023



In this paper, we present a high-performance deep neural network for weak target image segmentation, including medical image segmentation and infrared image segmentation. To this end, this work analyzes the existing dynamic convolutions and proposes dynamic parameter convolution (DPConv). Furthermore, it reevaluates the relationship between reconstruction tasks and segmentation tasks from the perspective of DPConv, leading to the proposal of a dual-network model called the Siamese Reconstruction-Segmentation Network (SRSNet). The proposed model is not only a universal network but also enhances the segmentation performance without altering its structure, leveraging the reconstruction task. Additionally, as the amount of training data for the reconstruction network increases, the performance of the segmentation network also improves synchronously. On seven datasets including five medical datasets and two infrared image datasets, our SRSNet consistently achieves the best segmentation results. The code is released at https://github.com/fidshu/SRSNet.
MobileUtr: Revisiting the relationship between light-weight CNN and Transformer for efficient medical image segmentation
Dec 04, 2023



Due to the scarcity and specific imaging characteristics in medical images, light-weighting Vision Transformers (ViTs) for efficient medical image segmentation is a significant challenge, and current studies have not yet paid attention to this issue. This work revisits the relationship between CNNs and Transformers in lightweight universal networks for medical image segmentation, aiming to integrate the advantages of both worlds at the infrastructure design level. In order to leverage the inductive bias inherent in CNNs, we abstract a Transformer-like lightweight CNNs block (ConvUtr) as the patch embeddings of ViTs, feeding Transformer with denoised, non-redundant and highly condensed semantic information. Moreover, an adaptive Local-Global-Local (LGL) block is introduced to facilitate efficient local-to-global information flow exchange, maximizing Transformer's global context information extraction capabilities. Finally, we build an efficient medical image segmentation model (MobileUtr) based on CNN and Transformer. Extensive experiments on five public medical image datasets with three different modalities demonstrate the superiority of MobileUtr over the state-of-the-art methods, while boasting lighter weights and lower computational cost. Code is available at https://github.com/FengheTan9/MobileUtr.
TIDE: Test Time Few Shot Object Detection
Nov 30, 2023Few-shot object detection (FSOD) aims to extract semantic knowledge from limited object instances of novel categories within a target domain. Recent advances in FSOD focus on fine-tuning the base model based on a few objects via meta-learning or data augmentation. Despite their success, the majority of them are grounded with parametric readjustment to generalize on novel objects, which face considerable challenges in Industry 5.0, such as (i) a certain amount of fine-tuning time is required, and (ii) the parameters of the constructed model being unavailable due to the privilege protection, making the fine-tuning fail. Such constraints naturally limit its application in scenarios with real-time configuration requirements or within black-box settings. To tackle the challenges mentioned above, we formalize a novel FSOD task, referred to as Test TIme Few Shot DEtection (TIDE), where the model is un-tuned in the configuration procedure. To that end, we introduce an asymmetric architecture for learning a support-instance-guided dynamic category classifier. Further, a cross-attention module and a multi-scale resizer are provided to enhance the model performance. Experimental results on multiple few-shot object detection platforms reveal that the proposed TIDE significantly outperforms existing contemporary methods. The implementation codes are available at https://github.com/deku-0621/TIDE
READS-V: Real-time Automated Detection of Epileptic Seizures from Surveillance Videos via Skeleton-based Spatiotemporal ViG
Nov 24, 2023



An accurate and efficient epileptic seizure onset detection system can significantly benefit patients. Traditional diagnostic methods, primarily relying on electroencephalograms (EEGs), often result in cumbersome and non-portable solutions, making continuous patient monitoring challenging. The video-based seizure detection system is expected to free patients from the constraints of scalp or implanted EEG devices and enable remote monitoring in residential settings. Previous video-based methods neither enable all-day monitoring nor provide short detection latency due to insufficient resources and ineffective patient action recognition techniques. Additionally, skeleton-based action recognition approaches remain limitations in identifying subtle seizure-related actions. To address these challenges, we propose a novel skeleton-based spatiotemporal vision graph neural network (STViG) for efficient, accurate, and timely REal-time Automated Detection of epileptic Seizures from surveillance Videos (READS-V). Our experimental results indicate STViG outperforms previous state-of-the-art action recognition models on our collected patients' video data with higher accuracy (5.9% error) and lower FLOPs (0.4G). Furthermore, by integrating a decision-making rule that combines output probabilities and an accumulative function, our READS-V system achieves a 5.1 s EEG onset detection latency, a 13.1 s advance in clinical onset detection, and zero false detection rate.
Low-Dimensional Gradient Helps Out-of-Distribution Detection
Oct 26, 2023



Detecting out-of-distribution (OOD) samples is essential for ensuring the reliability of deep neural networks (DNNs) in real-world scenarios. While previous research has predominantly investigated the disparity between in-distribution (ID) and OOD data through forward information analysis, the discrepancy in parameter gradients during the backward process of DNNs has received insufficient attention. Existing studies on gradient disparities mainly focus on the utilization of gradient norms, neglecting the wealth of information embedded in gradient directions. To bridge this gap, in this paper, we conduct a comprehensive investigation into leveraging the entirety of gradient information for OOD detection. The primary challenge arises from the high dimensionality of gradients due to the large number of network parameters. To solve this problem, we propose performing linear dimension reduction on the gradient using a designated subspace that comprises principal components. This innovative technique enables us to obtain a low-dimensional representation of the gradient with minimal information loss. Subsequently, by integrating the reduced gradient with various existing detection score functions, our approach demonstrates superior performance across a wide range of detection tasks. For instance, on the ImageNet benchmark, our method achieves an average reduction of 11.15% in the false positive rate at 95% recall (FPR95) compared to the current state-of-the-art approach. The code would be released.
Revisiting Deep Ensemble for Out-of-Distribution Detection: A Loss Landscape Perspective
Oct 22, 2023Existing Out-of-Distribution (OoD) detection methods address to detect OoD samples from In-Distribution data (InD) mainly by exploring differences in features, logits and gradients in Deep Neural Networks (DNNs). We in this work propose a new perspective upon loss landscape and mode ensemble to investigate OoD detection. In the optimization of DNNs, there exist many local optima in the parameter space, or namely modes. Interestingly, we observe that these independent modes, which all reach low-loss regions with InD data (training and test data), yet yield significantly different loss landscapes with OoD data. Such an observation provides a novel view to investigate the OoD detection from the loss landscape and further suggests significantly fluctuating OoD detection performance across these modes. For instance, FPR values of the RankFeat method can range from 46.58% to 84.70% among 5 modes, showing uncertain detection performance evaluations across independent modes. Motivated by such diversities on OoD loss landscape across modes, we revisit the deep ensemble method for OoD detection through mode ensemble, leading to improved performance and benefiting the OoD detector with reduced variances. Extensive experiments covering varied OoD detectors and network structures illustrate high variances across modes and also validate the superiority of mode ensemble in boosting OoD detection. We hope this work could attract attention in the view of independent modes in the OoD loss landscape and more reliable evaluations on OoD detectors.
UniPose: Detecting Any Keypoints
Oct 12, 2023This work proposes a unified framework called UniPose to detect keypoints of any articulated (e.g., human and animal), rigid, and soft objects via visual or textual prompts for fine-grained vision understanding and manipulation. Keypoint is a structure-aware, pixel-level, and compact representation of any object, especially articulated objects. Existing fine-grained promptable tasks mainly focus on object instance detection and segmentation but often fail to identify fine-grained granularity and structured information of image and instance, such as eyes, leg, paw, etc. Meanwhile, prompt-based keypoint detection is still under-explored. To bridge the gap, we make the first attempt to develop an end-to-end prompt-based keypoint detection framework called UniPose to detect keypoints of any objects. As keypoint detection tasks are unified in this framework, we can leverage 13 keypoint detection datasets with 338 keypoints across 1,237 categories over 400K instances to train a generic keypoint detection model. UniPose can effectively align text-to-keypoint and image-to-keypoint due to the mutual enhancement of textual and visual prompts based on the cross-modality contrastive learning optimization objectives. Our experimental results show that UniPose has strong fine-grained localization and generalization abilities across image styles, categories, and poses. Based on UniPose as a generalist keypoint detector, we hope it could serve fine-grained visual perception, understanding, and generation.
ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
Oct 12, 2023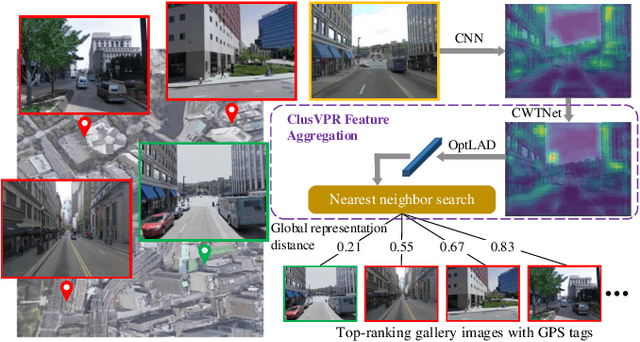
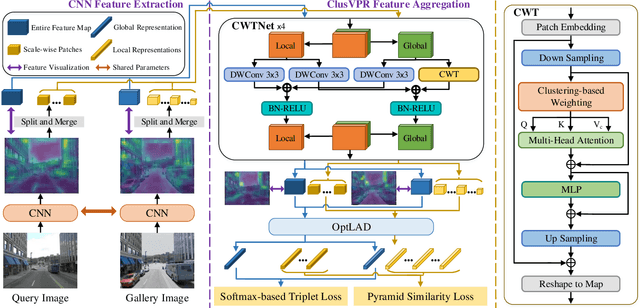
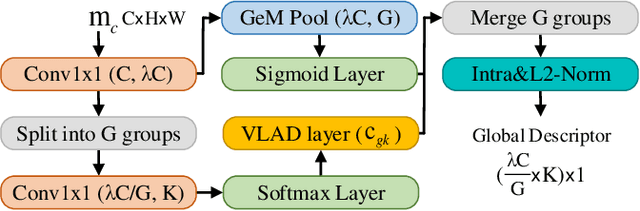
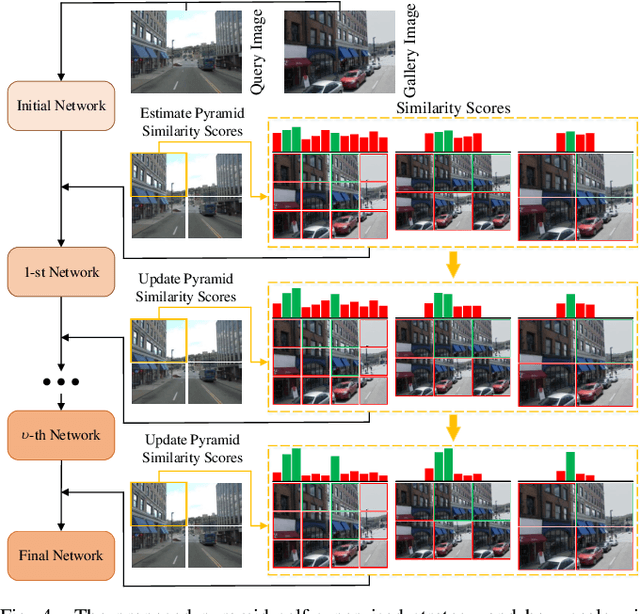
Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.