 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLDT: Multi-Level Decomposition for Complex Long-Horizon Robotic Task Planning with Open-Source Large Language Model
Apr 02, 2024



In the realm of data-driven AI technology, the application of open-source large language models (LLMs) in robotic task planning represents a significant milestone. Recent robotic task planning methods based on open-source LLMs typically leverage vast task planning datasets to enhance models' planning abilities. While these methods show promise, they struggle with complex long-horizon tasks, which require comprehending more context and generating longer action sequences. This paper addresses this limitation by proposing MLDT, theMulti-Level Decomposition Task planning method. This method innovatively decomposes tasks at the goal-level, task-level, and action-level to mitigate the challenge of complex long-horizon tasks. In order to enhance open-source LLMs' planning abilities, we introduce a goal-sensitive corpus generation method to create high-quality training data and conduct instruction tuning on the generated corpus. Since the complexity of the existing datasets is not high enough, we construct a more challenging dataset, LongTasks, to specifically evaluate planning ability on complex long-horizon tasks. We evaluate our method using various LLMs on four datasets in VirtualHome. Our results demonstrate a significant performance enhancement in robotic task planning, showcasing MLDT's effectiveness in overcoming the limitations of existing methods based on open-source LLMs as well as its practicality in complex, real-world scenarios.
Unveiling and Mitigating Memorization in Text-to-image Diffusion Models through Cross Attention
Mar 17, 2024



Recent advancements in text-to-image diffusion models have demonstrated their remarkable capability to generate high-quality images from textual prompts. However, increasing research indicates that these models memorize and replicate images from their training data, raising tremendous concerns about potential copyright infringement and privacy risks. In our study, we provide a novel perspective to understand this memorization phenomenon by examining its relationship with cross-attention mechanisms. We reveal that during memorization, the cross-attention tends to focus disproportionately on the embeddings of specific tokens. The diffusion model is overfitted to these token embeddings, memorizing corresponding training images. To elucidate this phenomenon, we further identify and discuss various intrinsic findings of cross-attention that contribute to memorization. Building on these insights, we introduce an innovative approach to detect and mitigate memorization in diffusion models. The advantage of our proposed method is that it will not compromise the speed of either the training or the inference processes in these models while preserving the quality of generated images. Our code is available at https://github.com/renjie3/MemAttn .
The Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation
Feb 23, 2024



Retrieval-augmented generation (RAG) is a powerful technique to facilitate language model with proprietary and private data, where data privacy is a pivotal concern. Whereas extensive research has demonstrated the privacy risks of large language models (LLMs), the RAG technique could potentially reshape the inherent behaviors of LLM generation, posing new privacy issues that are currently under-explored. In this work, we conduct extensive empirical studies with novel attack methods, which demonstrate the vulnerability of RAG systems on leaking the private retrieval database. Despite the new risk brought by RAG on the retrieval data, we further reveal that RAG can mitigate the leakage of the LLMs' training data. Overall, we provide new insights in this paper for privacy protection of retrieval-augmented LLMs, which benefit both LLMs and RAG systems builders. Our code is available at https://github.com/phycholosogy/RAG-privacy.
Identifying Semantic Induction Heads to Understand In-Context Learning
Feb 20, 2024



Although large language models (LLMs) have demonstrated remarkable performance, the lack of transparency in their inference logic raises concerns about their trustworthiness. To gain a better understanding of LLMs, we conduct a detailed analysis of the operations of attention heads and aim to better understand the in-context learning of LLMs. Specifically, we investigate whether attention heads encode two types of relationships between tokens present in natural languages: the syntactic dependency parsed from sentences and the relation within knowledge graphs. We find that certain attention heads exhibit a pattern where, when attending to head tokens, they recall tail tokens and increase the output logits of those tail tokens. More crucially, the formulation of such semantic induction heads has a close correlation with the emergence of the in-context learning ability of language models. The study of semantic attention heads advances our understanding of the intricate operations of attention heads in transformers, and further provides new insights into the in-context learning of LLMs.
A novel spatial-frequency domain network for zero-shot incremental learning
Feb 11, 2024



Zero-shot incremental learning aims to enable the model to generalize to new classes without forgetting previously learned classes. However, the semantic gap between old and new sample classes can lead to catastrophic forgetting. Additionally, existing algorithms lack capturing significant information from each sample image domain, impairing models' classification performance. Therefore, this paper proposes a novel Spatial-Frequency Domain Network (SFDNet) which contains a Spatial-Frequency Feature Extraction (SFFE) module and Attention Feature Alignment (AFA) module to improve the Zero-Shot Translation for Class Incremental algorithm. Firstly, SFFE module is designed which contains a dual attention mechanism for obtaining salient spatial-frequency feature information. Secondly, a novel feature fusion module is conducted for obtaining fused spatial-frequency domain features. Thirdly, the Nearest Class Mean classifier is utilized to select the most suitable category. Finally, iteration between tasks is performed using the Zero-Shot Translation model. The proposed SFDNet has the ability to effectively extract spatial-frequency feature representation from input images, improve the accuracy of image classification, and fundamentally alleviate catastrophic forgetting. Extensive experiments on the CUB 200-2011 and CIFAR100 datasets demonstrate that our proposed algorithm outperforms state-of-the-art incremental learning algorithms.
Copyright Protection in Generative AI: A Technical Perspective
Feb 04, 2024



Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Superiority of Multi-Head Attention in In-Context Linear Regression
Jan 30, 2024We present a theoretical analysis of the performance of transformer with softmax attention in in-context learning with linear regression tasks. While the existing literature predominantly focuses on the convergence of transformers with single-/multi-head attention, our research centers on comparing their performance. We conduct an exact theoretical analysis to demonstrate that multi-head attention with a substantial embedding dimension performs better than single-head attention. When the number of in-context examples D increases, the prediction loss using single-/multi-head attention is in O(1/D), and the one for multi-head attention has a smaller multiplicative constant. In addition to the simplest data distribution setting, we consider more scenarios, e.g., noisy labels, local examples, correlated features, and prior knowledge. We observe that, in general, multi-head attention is preferred over single-head attention. Our results verify the effectiveness of the design of multi-head attention in the transformer architecture.
Self-Evaluation Improves Selective Generation in Large Language Models
Dec 14, 2023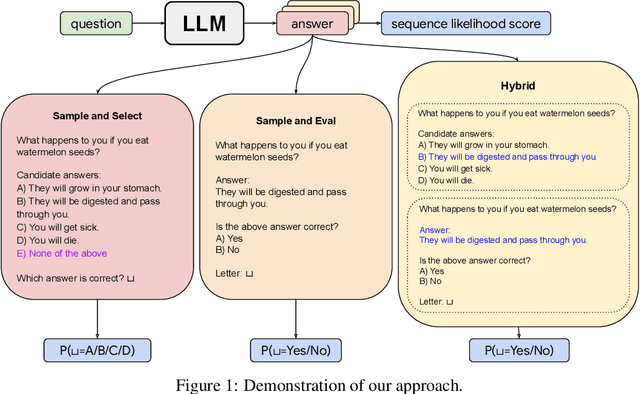

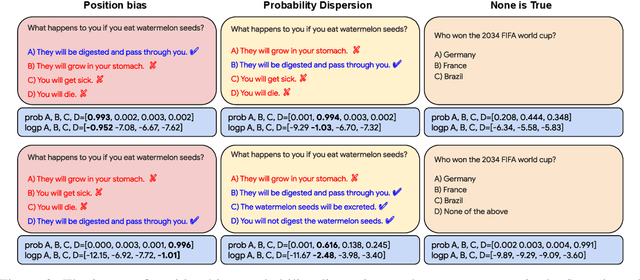

Safe deployment of large language models (LLMs) may benefit from a reliable method for assessing their generated content to determine when to abstain or to selectively generate. While likelihood-based metrics such as perplexity are widely employed, recent research has demonstrated the limitations of using sequence-level probability estimates given by LLMs as reliable indicators of generation quality. Conversely, LLMs have demonstrated strong calibration at the token level, particularly when it comes to choosing correct answers in multiple-choice questions or evaluating true/false statements. In this work, we reformulate open-ended generation tasks into token-level prediction tasks, and leverage LLMs' superior calibration at the token level. We instruct an LLM to self-evaluate its answers, employing either a multi-way comparison or a point-wise evaluation approach, with the option to include a ``None of the above'' option to express the model's uncertainty explicitly. We benchmark a range of scoring methods based on self-evaluation and evaluate their performance in selective generation using TruthfulQA and TL;DR. Through experiments with PaLM-2 and GPT-3, we demonstrate that self-evaluation based scores not only improve accuracy, but also correlate better with the overall quality of generated content.
Universal Self-Consistency for Large Language Model Generation
Nov 29, 2023



Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answer extraction process to aggregate multiple solutions, which is not applicable to free-form answers. In this work, we propose Universal Self-Consistency (USC), which leverages LLMs themselves to select the most consistent answer among multiple candidates. We evaluate USC on a variety of benchmarks, including mathematical reasoning, code generation, long-context summarization, and open-ended question answering. On open-ended generation tasks where the original self-consistency method is not applicable, USC effectively utilizes multiple samples and improves the performance. For mathematical reasoning, USC matches the standard self-consistency performance without requiring the answer formats to be similar. Finally, without access to execution results, USC also matches the execution-based voting performance on code generation.
Towards End-to-end 4-Bit Inference on Generative Large Language Models
Oct 13, 2023



We show that the majority of the inference computations for large generative models such as LLaMA and OPT can be performed with both weights and activations being cast to 4 bits, in a way that leads to practical speedups while at the same time maintaining good accuracy. We achieve this via a hybrid quantization strategy called QUIK, which compresses most of the weights and activations to 4-bit, while keeping some outlier weights and activations in higher-precision. Crucially, our scheme is designed with computational efficiency in mind: we provide GPU kernels with highly-efficient layer-wise runtimes, which lead to practical end-to-end throughput improvements of up to 3.1x relative to FP16 execution. Code and models are provided at https://github.com/IST-DASLab/QUIK.