 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Deraining: From Model-Based to Data-Driven and Beyond
Dec 27, 2019

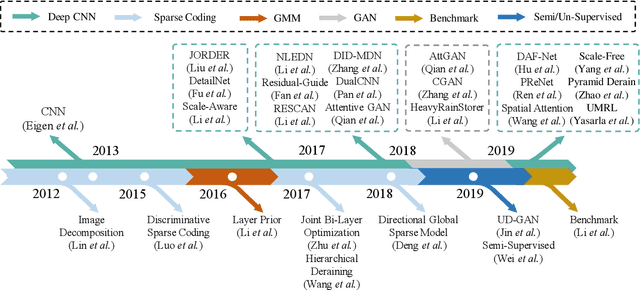
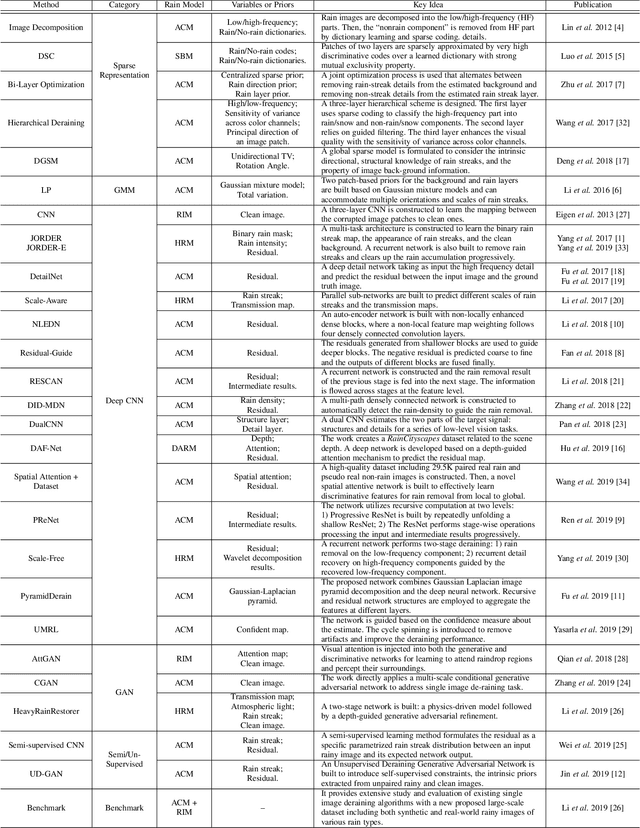
The goal of single-image deraining is to restore the rain-free background scenes of an image degraded by rain streaks and rain accumulation. The early single-image deraining methods employ a cost function, where various priors are developed to represent the properties of rain and background layers. Since 2017, single-image deraining methods step into a deep-learning era, and exploit various types of networks, i.e. convolutional neural networks, recurrent neural networks, generative adversarial networks, etc., demonstrating impressive performance. Given the current rapid development, in this paper, we provide a comprehensive survey of deraining methods over the last decade. We summarize the rain appearance models, and discuss two categories of deraining approaches: model-based and data-driven approaches. For the former, we organize the literature based on their basic models and priors. For the latter, we discuss developed ideas related to architectures, constraints, loss functions, and training datasets. We present milestones of single-image deraining methods, review a broad selection of previous works in different categories, and provide insights on the historical development route from the model-based to data-driven methods. We also summarize performance comparisons quantitatively and qualitatively. Beyond discussing the technicality of deraining methods, we also discuss the future directions.
Disentangled Image Matting
Sep 10, 2019
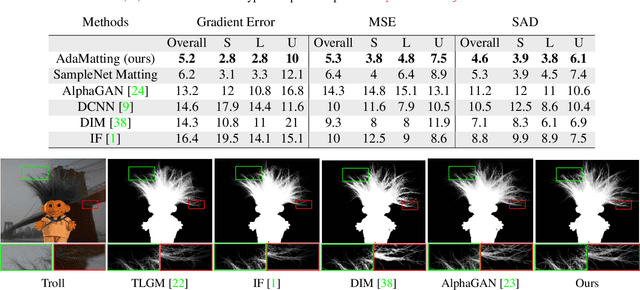
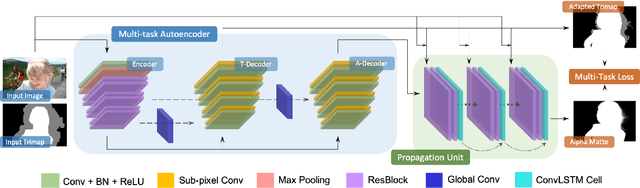
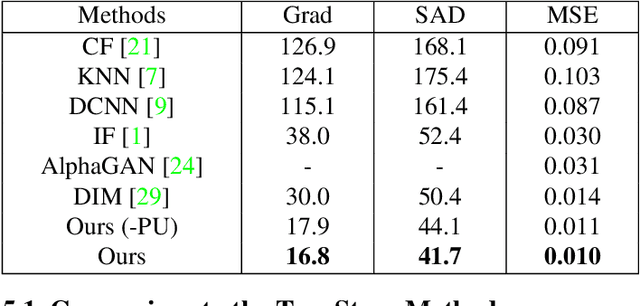
Most previous image matting methods require a roughly-specificed trimap as input, and estimate fractional alpha values for all pixels that are in the unknown region of the trimap. In this paper, we argue that directly estimating the alpha matte from a coarse trimap is a major limitation of previous methods, as this practice tries to address two difficult and inherently different problems at the same time: identifying true blending pixels inside the trimap region, and estimate accurate alpha values for them. We propose AdaMatting, a new end-to-end matting framework that disentangles this problem into two sub-tasks: trimap adaptation and alpha estimation. Trimap adaptation is a pixel-wise classification problem that infers the global structure of the input image by identifying definite foreground, background, and semi-transparent image regions. Alpha estimation is a regression problem that calculates the opacity value of each blended pixel. Our method separately handles these two sub-tasks within a single deep convolutional neural network (CNN). Extensive experiments show that AdaMatting has additional structure awareness and trimap fault-tolerance. Our method achieves the state-of-the-art performance on Adobe Composition-1k dataset both qualitatively and quantitatively. It is also the current best-performing method on the alphamatting.com online evaluation for all commonly-used metrics.
A Comprehensive Benchmark for Single Image Compression Artifacts Reduction
Sep 09, 2019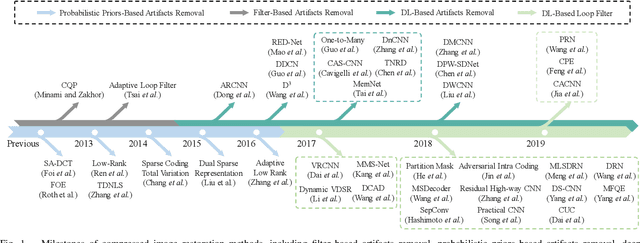
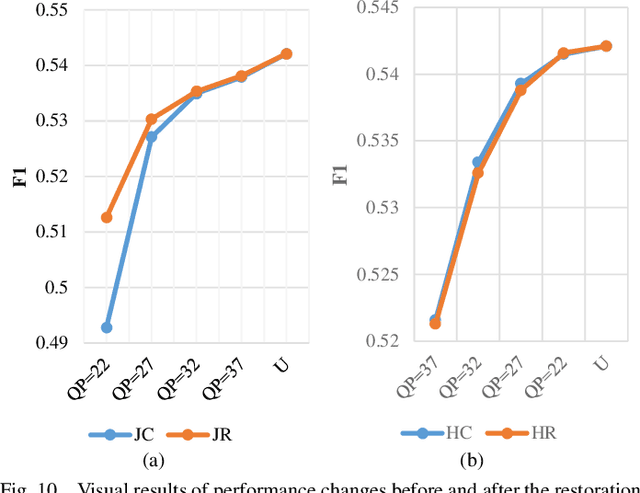
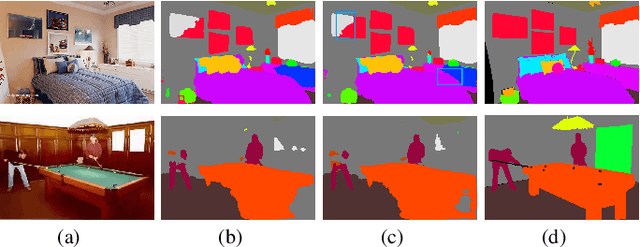
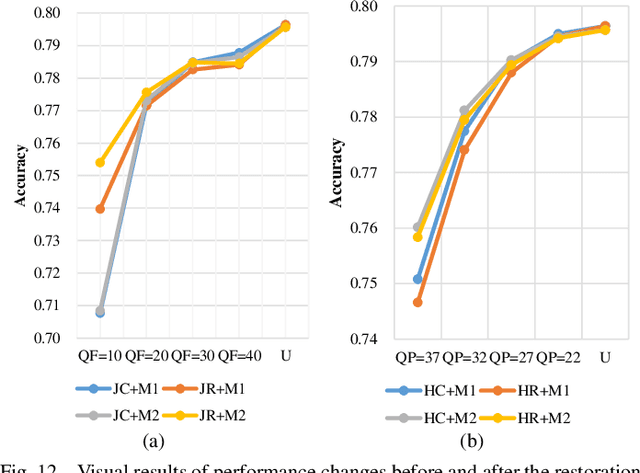
We present a comprehensive study and evaluation of existing single image compression artifacts removal algorithms, using a new 4K resolution benchmark including diversified foreground objects and background scenes with rich structures, called Large-scale Ideal Ultra high definition 4K (LIU4K) benchmark. Compression artifacts removal, as a common post-processing technique, aims at alleviating undesirable artifacts such as blockiness, ringing, and banding caused by quantization and approximation in the compression process. In this work, a systematic listing of the reviewed methods is presented based on their basic models (handcrafted models and deep networks). The main contributions and novelties of these methods are highlighted, and the main development directions, including architectures, multi-domain sources, signal structures, and new targeted units, are summarized. Furthermore, based on a unified deep learning configuration (i.e. same training data, loss function, optimization algorithm, etc.), we evaluate recent deep learning-based methods based on diversified evaluation measures. The experimental results show the state-of-the-art performance comparison of existing methods based on both full-reference, non-reference and task-driven metrics. Our survey would give a comprehensive reference source for future research on single image compression artifacts removal and inspire new directions of the related fields.
Reprojection R-CNN: A Fast and Accurate Object Detector for 360° Images
Jul 27, 2019
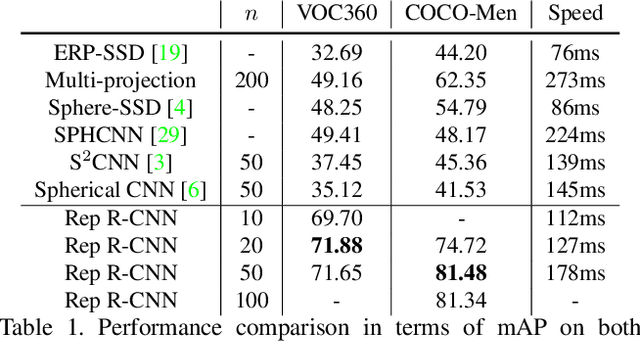
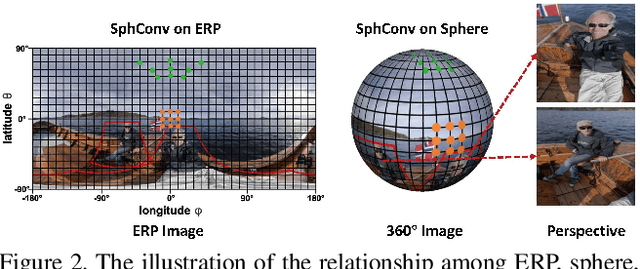
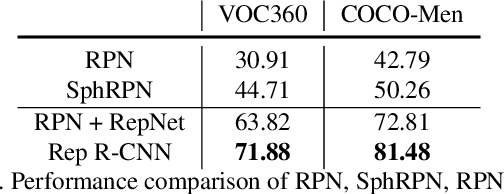
360{\deg} images are usually represented in either equirectangular projection (ERP) or multiple perspective projections. Different from the flat 2D images, the detection task is challenging for 360{\deg} images due to the distortion of ERP and the inefficiency of perspective projections. However, existing methods mostly focus on one of the above representations instead of both, leading to limited detection performance. Moreover, the lack of appropriate bounding-box annotations as well as the annotated datasets further increases the difficulties of the detection task. In this paper, we present a standard object detection framework for 360{\deg} images. Specifically, we adapt the terminologies of the traditional object detection task to the omnidirectional scenarios, and propose a novel two-stage object detector, i.e., Reprojection R-CNN by combining both ERP and perspective projection. Owing to the omnidirectional field-of-view of ERP, Reprojection R-CNN first generates coarse region proposals efficiently by a distortion-aware spherical region proposal network. Then, it leverages the distortion-free perspective projection and refines the proposed regions by a novel reprojection network. We construct two novel synthetic datasets for training and evaluation. Experiments reveal that Reprojection R-CNN outperforms the previous state-of-the-art methods on the mAP metric. In addition, the proposed detector could run at 178ms per image in the panoramic datasets, which implies its practicability in real-world applications.
Deep Reference Generation with Multi-Domain Hierarchical Constraints for Inter Prediction
May 16, 2019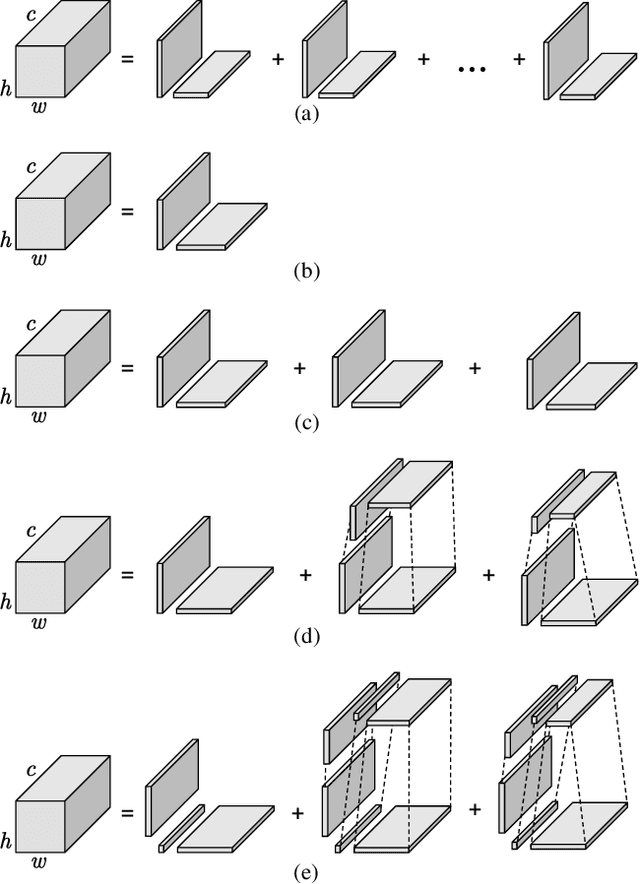
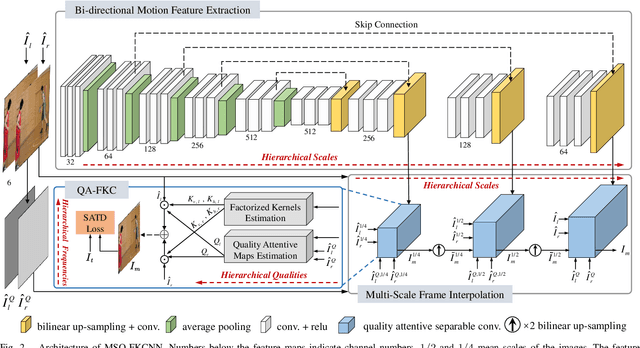
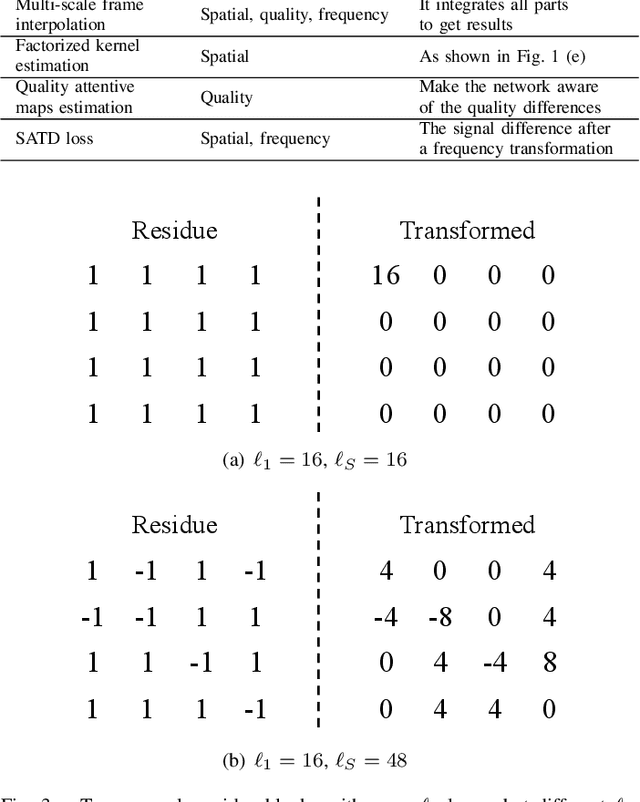
Inter prediction is an important module in video coding for temporal redundancy removal, where similar reference blocks are searched from previously coded frames and employed to predict the block to be coded. Although traditional video codecs can estimate and compensate for block-level motions, their inter prediction performance is still heavily affected by the remaining inconsistent pixel-wise displacement caused by irregular rotation and deformation. In this paper, we address the problem by proposing a deep frame interpolation network to generate additional reference frames in coding scenarios. First, we summarize the previous adaptive convolutions used for frame interpolation and propose a factorized kernel convolutional network to improve the modeling capacity and simultaneously keep its compact form. Second, to better train this network, multi-domain hierarchical constraints are introduced to regularize the training of our factorized kernel convolutional network. For spatial domain, we use a gradually down-sampled and up-sampled auto-encoder to generate the factorized kernels for frame interpolation at different scales. For quality domain, considering the inconsistent quality of the input frames, the factorized kernel convolution is modulated with quality-related features to learn to exploit more information from high quality frames. For frequency domain, a sum of absolute transformed difference loss that performs frequency transformation is utilized to facilitate network optimization from the view of coding performance. With the well-designed frame interpolation network regularized by multi-domain hierarchical constraints, our method surpasses HEVC on average 6.1% BD-rate saving and up to 11.0% BD-rate saving for the luma component under the random access configuration.
TE141K: Artistic Text Benchmark for Text Effects Transfer
May 10, 2019

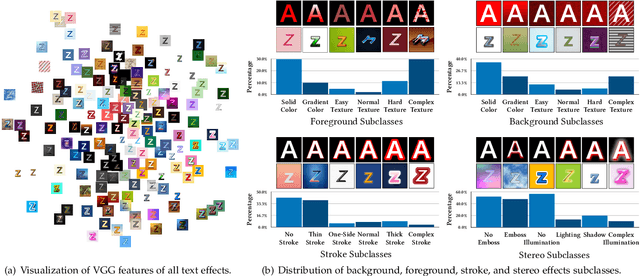

Text effects are combinations of visual elements such as outlines, colors and textures of text, which can dramatically improve its artistry. Although text effects are extensively utilized in the design industry, they are usually created by human experts due to their extreme complexity, which is laborious and not practical for normal users. In recent years, some efforts have been made for automatic text effects transfer, however, the lack of data limits the capability of transfer models. To address this problem, we introduce a new text effects dataset, TE141K, with 141,081 text effects/glyph pairs in total. Our dataset consists of 152 professionally designed text effects, rendered on glyphs including English letters, Chinese characters, Arabic numerals, etc. To the best of our knowledge, this is the largest dataset for text effects transfer as far. Based on this dataset, we propose a baseline approach named Text Effects Transfer GAN (TET-GAN), which supports the transfer of all 152 styles in one model and can efficiently extend to new styles. Finally, we conduct a comprehensive comparison where 14 style transfer models are benchmarked. Experimental results demonstrate the superiority of TET-GAN both qualitatively and quantitatively, and indicate that our dataset is effective and challenging.
Controllable Artistic Text Style Transfer via Shape-Matching GAN
May 03, 2019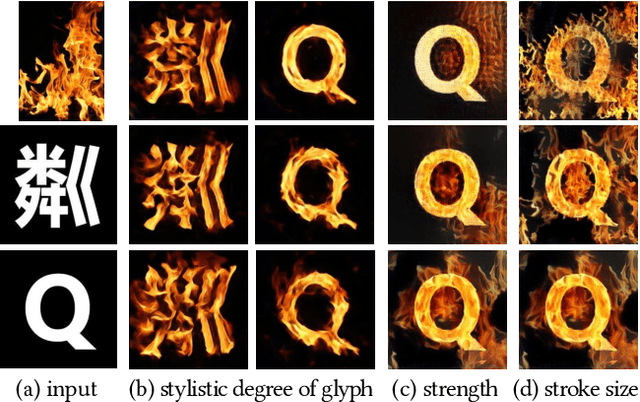
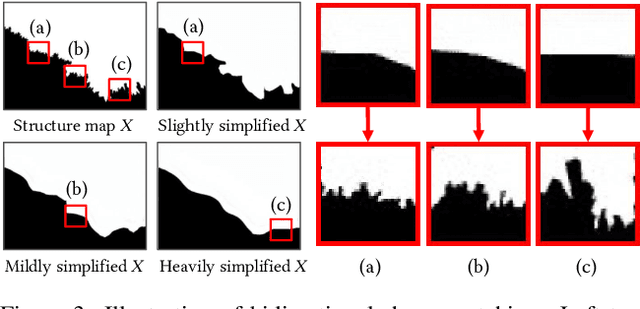
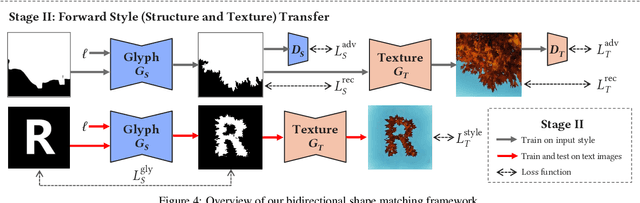
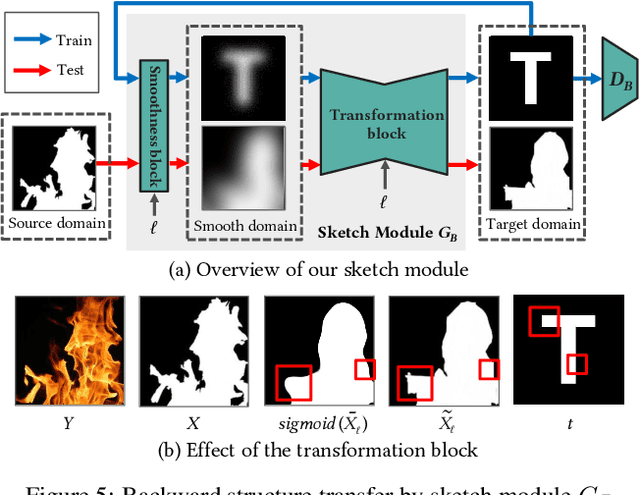
Artistic text style transfer is the task of migrating the style from a source image to the target text to create artistic typography. Recent style transfer methods have considered texture control to enhance usability. However, controlling the stylistic degree in terms of shape deformation remains an important open challenge. In this paper, we present the first text style transfer network that allows for real-time control of the crucial stylistic degree of the glyph through an adjustable parameter. Our key contribution is a novel bidirectional shape matching framework to establish an effective glyph-style mapping at various deformation levels without paired ground truth. Based on this idea, we propose a scale-controllable module to empower a single network to continuously characterize the multi-scale shape features of the style image and transfer these features to the target text. The proposed method demonstrates its superiority over previous state-of-the-arts in generating diverse, controllable and high-quality stylized text.
Unsupervised Person Image Generation with Semantic Parsing Transformation
Apr 18, 2019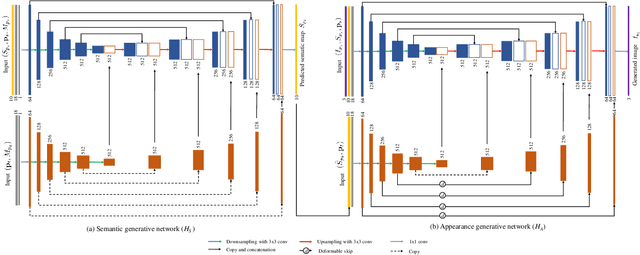

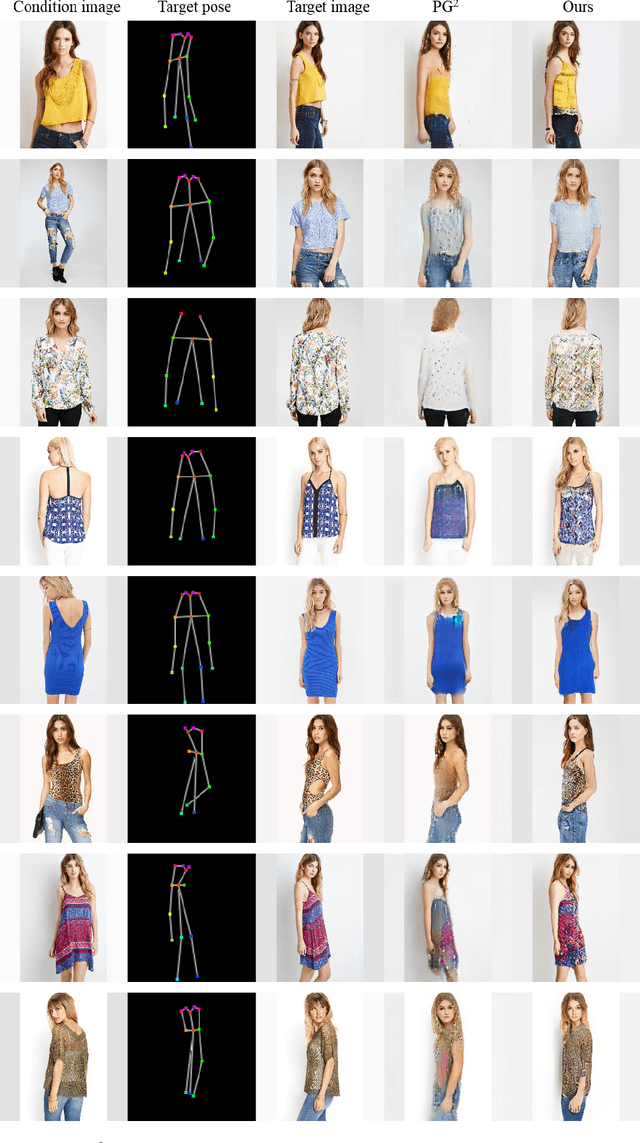
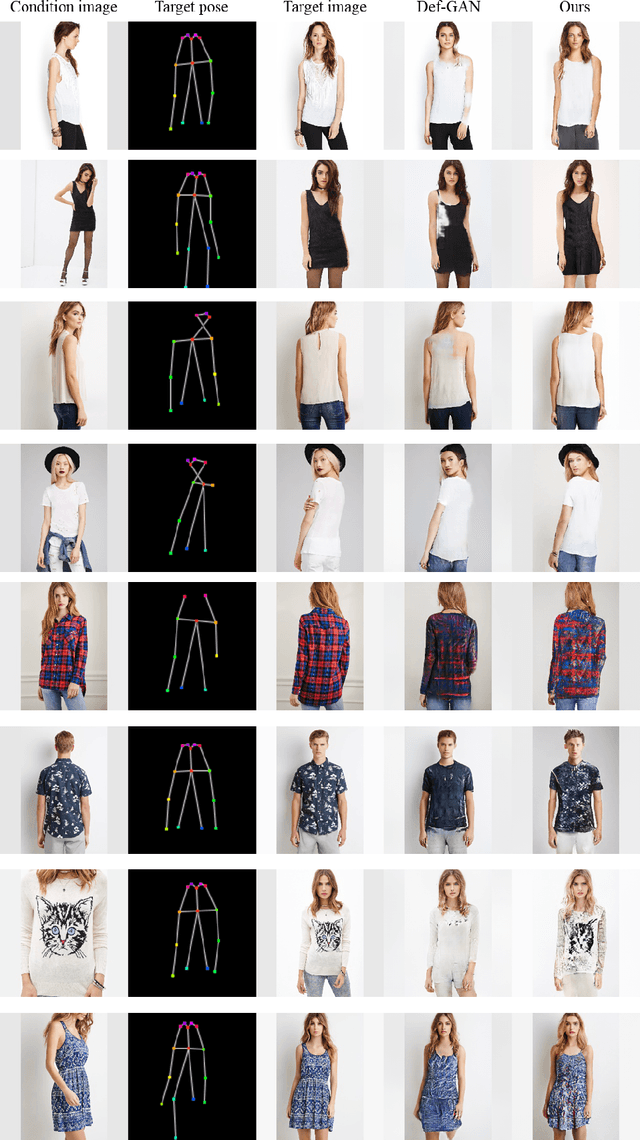
In this paper, we address unsupervised pose-guided person image generation, which is known challenging due to non-rigid deformation. Unlike previous methods learning a rock-hard direct mapping between human bodies, we propose a new pathway to decompose the hard mapping into two more accessible subtasks, namely, semantic parsing transformation and appearance generation. Firstly, a semantic generative network is proposed to transform between semantic parsing maps, in order to simplify the non-rigid deformation learning. Secondly, an appearance generative network learns to synthesize semantic-aware textures. Thirdly, we demonstrate that training our framework in an end-to-end manner further refines the semantic maps and final results accordingly. Our method is generalizable to other semantic-aware person image generation tasks, eg, clothing texture transfer and controlled image manipulation. Experimental results demonstrate the superiority of our method on DeepFashion and Market-1501 datasets, especially in keeping the clothing attributes and better body shapes.
UG$^{2+}$ Track 2: A Collective Benchmark Effort for Evaluating and Advancing Image Understanding in Poor Visibility Environments
Apr 09, 2019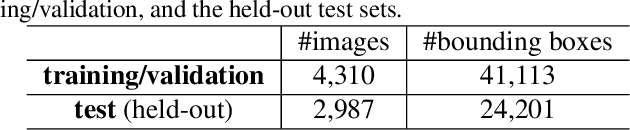


The UG$^{2+}$ challenge in IEEE CVPR 2019 aims to evoke a comprehensive discussion and exploration about how low-level vision techniques can benefit the high-level automatic visual recognition in various scenarios. In its second track, we focus on object or face detection in poor visibility enhancements caused by bad weathers (haze, rain) and low light conditions. While existing enhancement methods are empirically expected to help the high-level end task, that is observed to not always be the case in practice. To provide a more thorough examination and fair comparison, we introduce three benchmark sets collected in real-world hazy, rainy, and low-light conditions, respectively, with annotate objects/faces annotated. To our best knowledge, this is the first and currently largest effort of its kind. Baseline results by cascading existing enhancement and detection models are reported, indicating the highly challenging nature of our new data as well as the large room for further technical innovations. We expect a large participation from the broad research community to address these challenges together.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019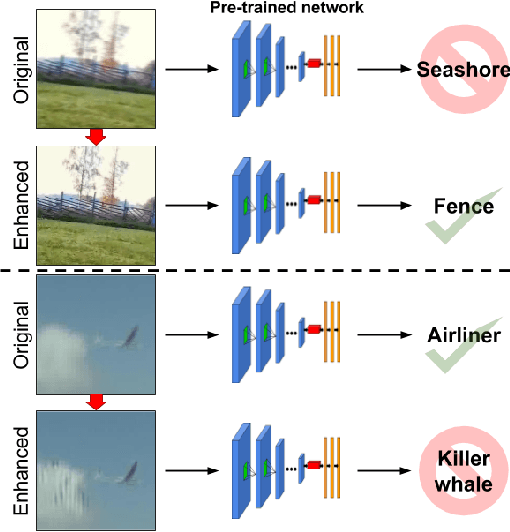
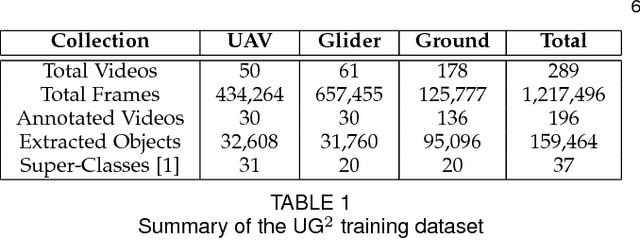

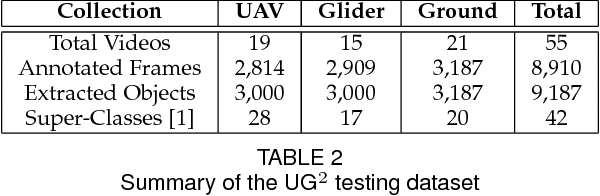
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.