 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEARN: A Unified Framework for Multi-Task Domain Adapt Few-Shot Learning
Dec 20, 2024



Both few-shot learning and domain adaptation sub-fields in Computer Vision have seen significant recent progress in terms of the availability of state-of-the-art algorithms and datasets. Frameworks have been developed for each sub-field; however, building a common system or framework that combines both is something that has not been explored. As part of our research, we present the first unified framework that combines domain adaptation for the few-shot learning setting across 3 different tasks - image classification, object detection and video classification. Our framework is highly modular with the capability to support few-shot learning with/without the inclusion of domain adaptation depending on the algorithm. Furthermore, the most important configurable feature of our framework is the on-the-fly setup for incremental $n$-shot tasks with the optional capability to configure the system to scale to a traditional many-shot task. With more focus on Self-Supervised Learning (SSL) for current few-shot learning approaches, our system also supports multiple SSL pre-training configurations. To test our framework's capabilities, we provide benchmarks on a wide range of algorithms and datasets across different task and problem settings. The code is open source has been made publicly available here: https://gitlab.kitware.com/darpa_learn/learn
Perceptual-Score: A Psychophysical Measure for Assessing the Biological Plausibility of Visual Recognition Models
Oct 16, 2022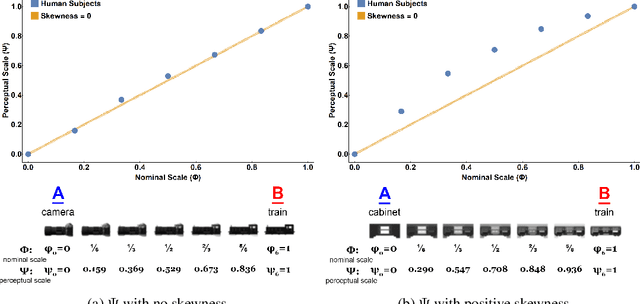

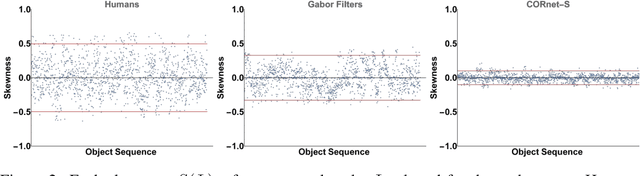
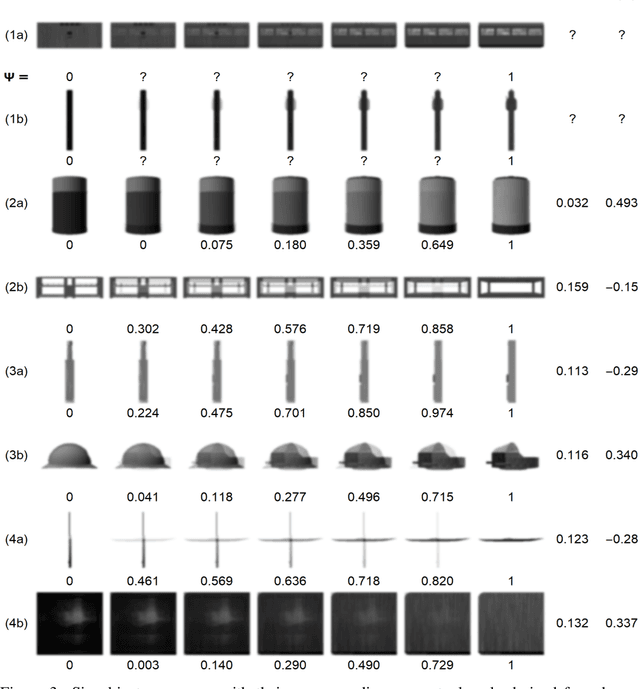
For the last decade, convolutional neural networks (CNNs) have vastly superseded their predecessors in nearly all vision tasks in artificial intelligence, including object recognition. However, in spite of abundant advancements, they continue to pale in comparison to biological vision. This chasm has prompted the development of biologically-inspired models that have attempted to mimic the human visual system, primarily at a neural-level, which are evaluated using standard dataset benchmarks. However, more work is needed to understand how these models actually perceive the visual world. This article proposes a state-of-the-art procedure that generates a new metric, Perceptual-Score, which is grounded in visual psychophysics, and is capable of reliably estimating perceptual responses across numerous models -- representing a large range in complexity and biological inspiration. We perform the procedure on twelve models that vary in degree of biological inspiration and complexity, and compare the results against the aggregated results of 2,390 Amazon Mechanical Turk workers who together provided ~2.7 million perceptual responses. Each model's Perceptual-Score is compared against the state-of-the-art neural activity-based metric, Brain-Score. Our study indicates that models with high correlation to human perceptual behavior also have high correlation with the corresponding neural activity.
A Study of the Human Perception of Synthetic Faces
Nov 08, 2021


Advances in face synthesis have raised alarms about the deceptive use of synthetic faces. Can synthetic identities be effectively used to fool human observers? In this paper, we introduce a study of the human perception of synthetic faces generated using different strategies including a state-of-the-art deep learning-based GAN model. This is the first rigorous study of the effectiveness of synthetic face generation techniques grounded in experimental techniques from psychology. We answer important questions such as how often do GAN-based and more traditional image processing-based techniques confuse human observers, and are there subtle cues within a synthetic face image that cause humans to perceive it as a fake without having to search for obvious clues? To answer these questions, we conducted a series of large-scale crowdsourced behavioral experiments with different sources of face imagery. Results show that humans are unable to distinguish synthetic faces from real faces under several different circumstances. This finding has serious implications for many different applications where face images are presented to human users.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019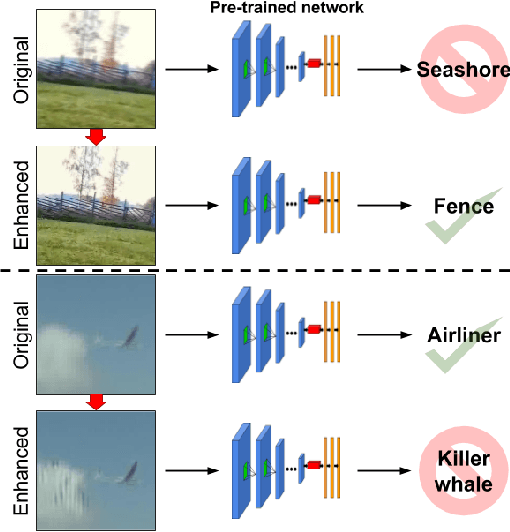
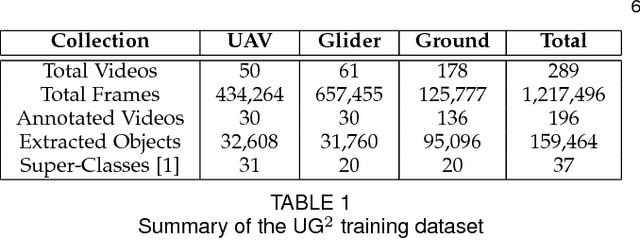

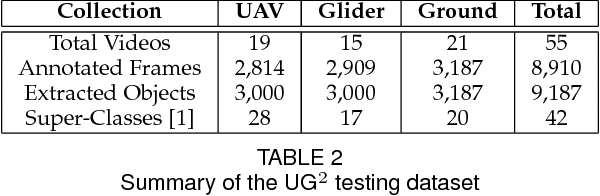
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.
Visual Psychophysics for Making Face Recognition Algorithms More Explainable
Jul 19, 2018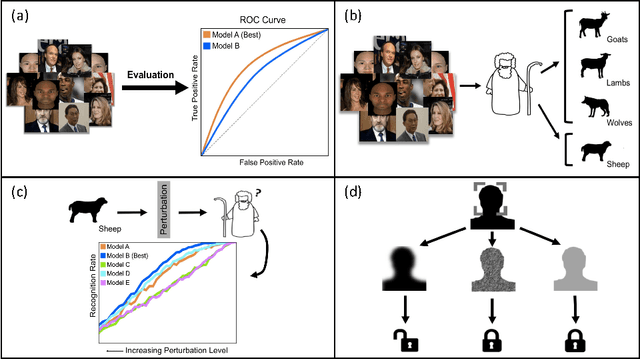
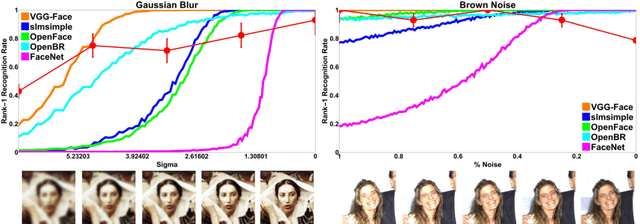
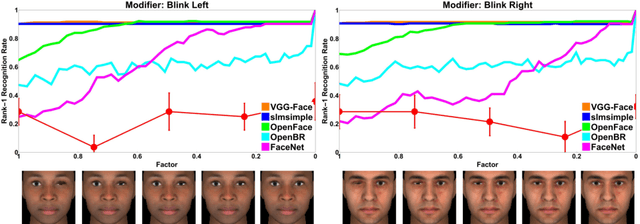
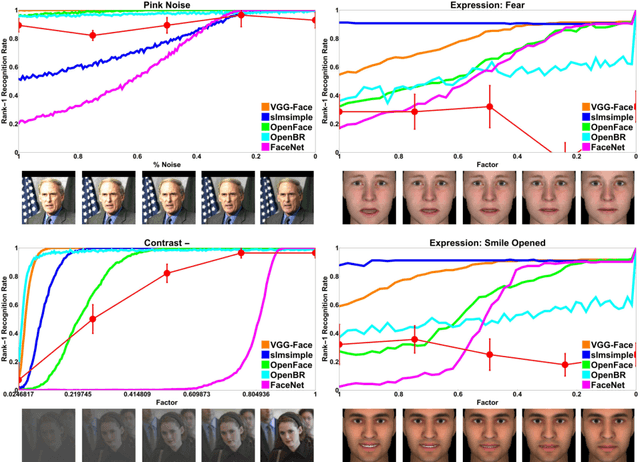
Scientific fields that are interested in faces have developed their own sets of concepts and procedures for understanding how a target model system (be it a person or algorithm) perceives a face under varying conditions. In computer vision, this has largely been in the form of dataset evaluation for recognition tasks where summary statistics are used to measure progress. While aggregate performance has continued to improve, understanding individual causes of failure has been difficult, as it is not always clear why a particular face fails to be recognized, or why an impostor is recognized by an algorithm. Importantly, other fields studying vision have addressed this via the use of visual psychophysics: the controlled manipulation of stimuli and careful study of the responses they evoke in a model system. In this paper, we suggest that visual psychophysics is a viable methodology for making face recognition algorithms more explainable. A comprehensive set of procedures is developed for assessing face recognition algorithm behavior, which is then deployed over state-of-the-art convolutional neural networks and more basic, yet still widely used, shallow and handcrafted feature-based approaches.
A Neurobiological Cross-domain Evaluation Metric for Predictive Coding Networks
Jul 09, 2018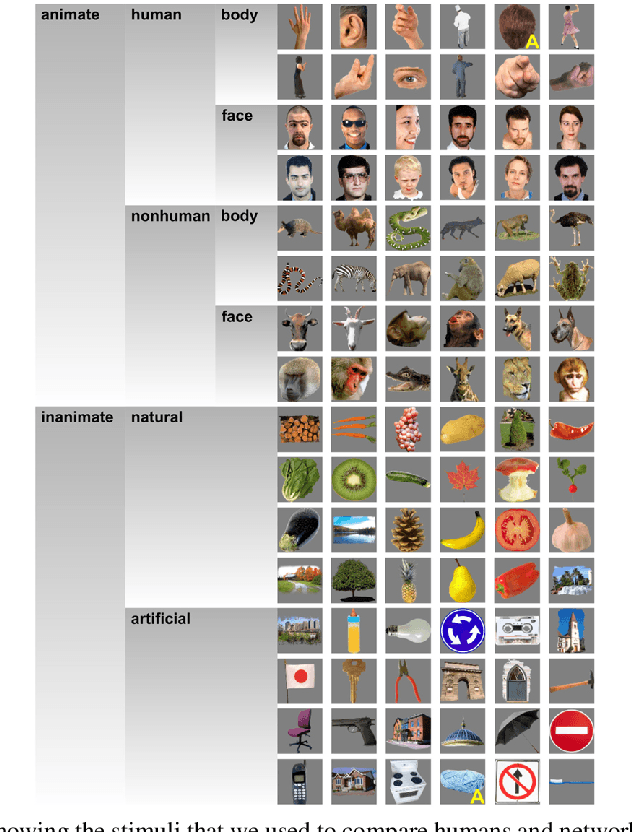


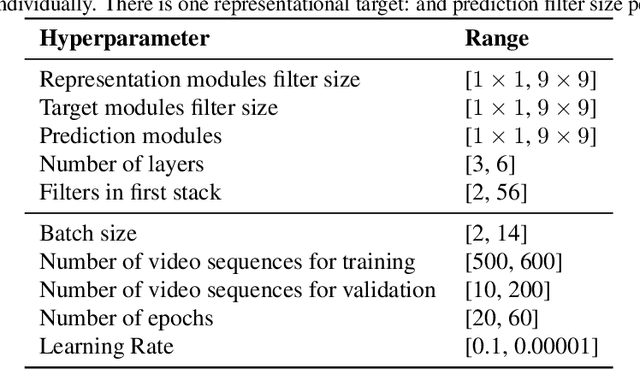
Achieving a good measure of model generalization remains a challenge within machine learning. One of the highest-performing learning models is the biological brain, which has unparalleled generalization capabilities. In this work, we propose and evaluate a human-model similarity metric for determining model correspondence to the human brain, as inspired by representational similarity analysis. We evaluate this metric on unsupervised predictive coding networks. These models are designed to mimic the phenomenon of residual error propagation in the visual cortex, implying their potential for biological fidelity. The human-model similarity metric is calculated by measuring the similarity between human brain fMRI activations and predictive coding network activations over a shared set of stimuli. In order to study our metric in relation to standard performance evaluations on cross-domain tasks, we train a multitude of predictive coding models across various conditions. Each unsupervised model is trained on next frame prediction in video and evaluated using three metrics: 1) mean squared error of next frame prediction, 2) object matching accuracy, and 3) our human-model similarity metric. Through this evaluation, we show that models with higher human-model similarity are more likely to generalize to cross-domain tasks. We also show that our metric facilitates a substantial decrease in model search time because the similarity metric stabilizes quickly --- in as few as 10 epochs. We propose that this metric could be deployed in model search to quickly identify and eliminate weaker models.
PsyPhy: A Psychophysics Driven Evaluation Framework for Visual Recognition
Jul 04, 2018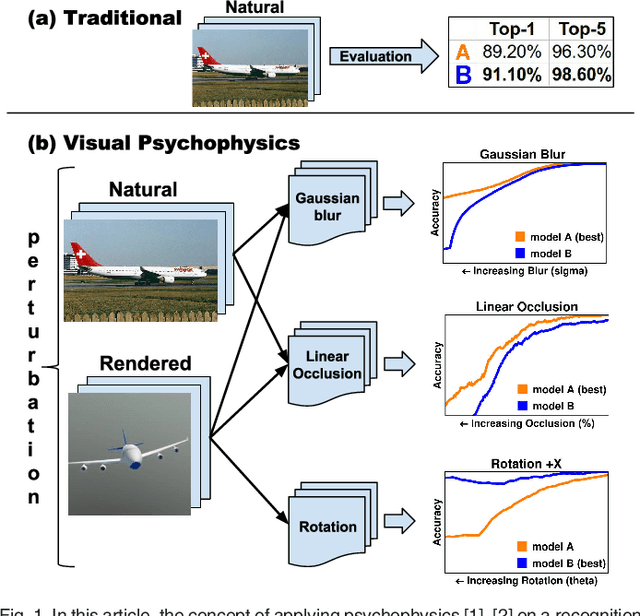
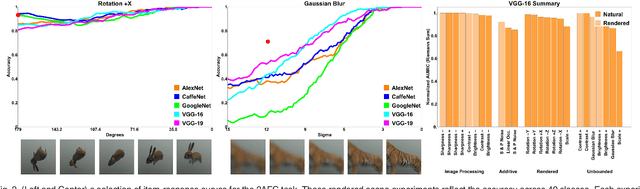
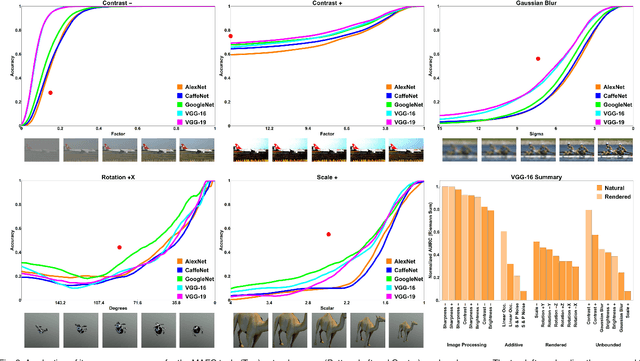
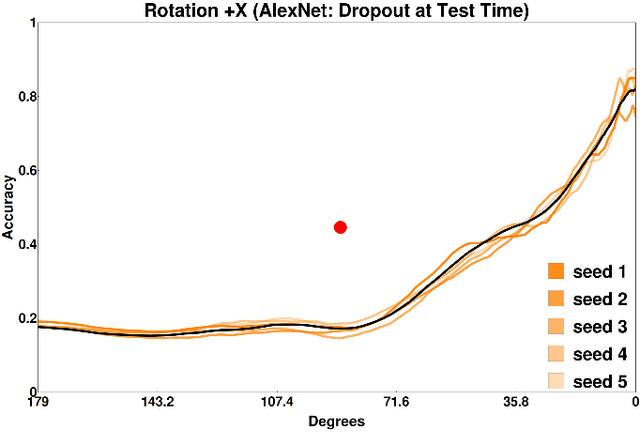
By providing substantial amounts of data and standardized evaluation protocols, datasets in computer vision have helped fuel advances across all areas of visual recognition. But even in light of breakthrough results on recent benchmarks, it is still fair to ask if our recognition algorithms are doing as well as we think they are. The vision sciences at large make use of a very different evaluation regime known as Visual Psychophysics to study visual perception. Psychophysics is the quantitative examination of the relationships between controlled stimuli and the behavioral responses they elicit in experimental test subjects. Instead of using summary statistics to gauge performance, psychophysics directs us to construct item-response curves made up of individual stimulus responses to find perceptual thresholds, thus allowing one to identify the exact point at which a subject can no longer reliably recognize the stimulus class. In this article, we introduce a comprehensive evaluation framework for visual recognition models that is underpinned by this methodology. Over millions of procedurally rendered 3D scenes and 2D images, we compare the performance of well-known convolutional neural networks. Our results bring into question recent claims of human-like performance, and provide a path forward for correcting newly surfaced algorithmic deficiencies.
To Frontalize or Not To Frontalize: Do We Really Need Elaborate Pre-processing To Improve Face Recognition?
Mar 27, 2018

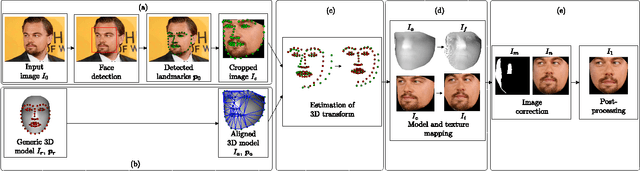
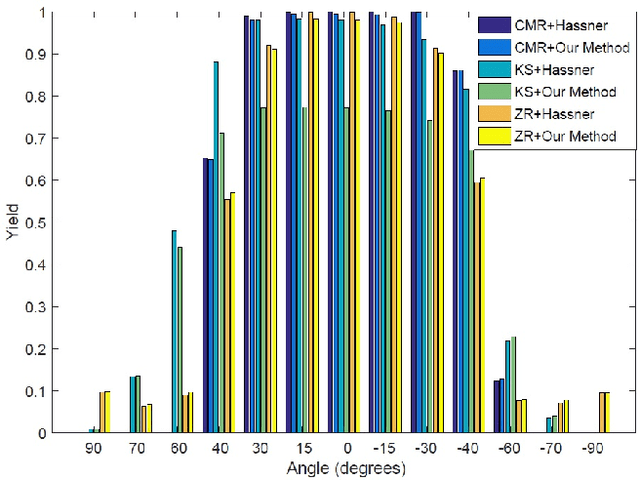
Face recognition performance has improved remarkably in the last decade. Much of this success can be attributed to the development of deep learning techniques such as convolutional neural networks (CNNs). While CNNs have pushed the state-of-the-art forward, their training process requires a large amount of clean and correctly labelled training data. If a CNN is intended to tolerate facial pose, then we face an important question: should this training data be diverse in its pose distribution, or should face images be normalized to a single pose in a pre-processing step? To address this question, we evaluate a number of popular facial landmarking and pose correction algorithms to understand their effect on facial recognition performance. Additionally, we introduce a new, automatic, single-image frontalization scheme that exceeds the performance of current algorithms. CNNs trained using sets of different pre-processing methods are used to extract features from the Point and Shoot Challenge (PaSC) and CMU Multi-PIE datasets. We assert that the subsequent verification and recognition performance serves to quantify the effectiveness of each pose correction scheme.