 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiawei Han
Inf-VAE: A Variational Autoencoder Framework to Integrate Homophily and Influence in Diffusion Prediction
Jan 01, 2020

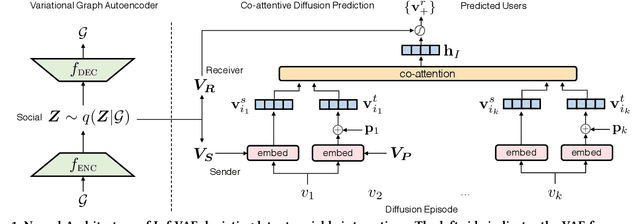
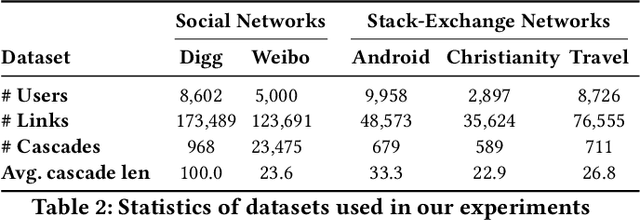
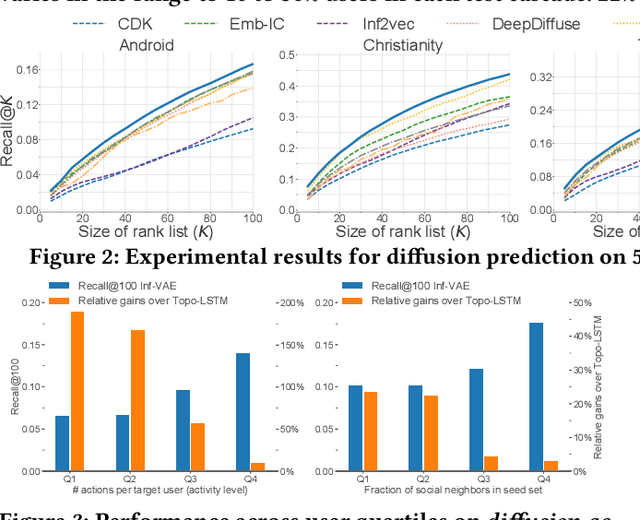
Recent years have witnessed tremendous interest in understanding and predicting information spread on social media platforms such as Twitter, Facebook, etc. Existing diffusion prediction methods primarily exploit the sequential order of influenced users by projecting diffusion cascades onto their local social neighborhoods. However, this fails to capture global social structures that do not explicitly manifest in any of the cascades, resulting in poor performance for inactive users with limited historical activities. In this paper, we present a novel variational autoencoder framework (Inf-VAE) to jointly embed homophily and influence through proximity-preserving social and position-encoded temporal latent variables. To model social homophily, Inf-VAE utilizes powerful graph neural network architectures to learn social variables that selectively exploit the social connections of users. Given a sequence of seed user activations, Inf-VAE uses a novel expressive co-attentive fusion network that jointly attends over their social and temporal variables to predict the set of all influenced users. Our experimental results on multiple real-world social network datasets, including Digg, Weibo, and Stack-Exchanges demonstrate significant gains (22% MAP@10) for Inf-VAE over state-of-the-art diffusion prediction models; we achieve massive gains for users with sparse activities, and users who lack direct social neighbors in seed sets.
Unsupervised Attributed Multiplex Network Embedding
Nov 15, 2019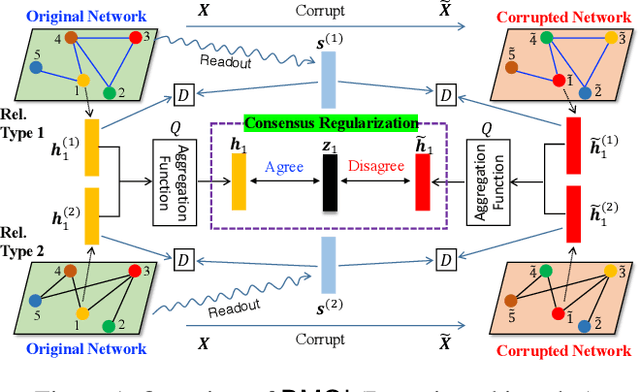
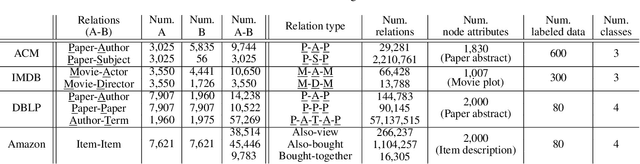
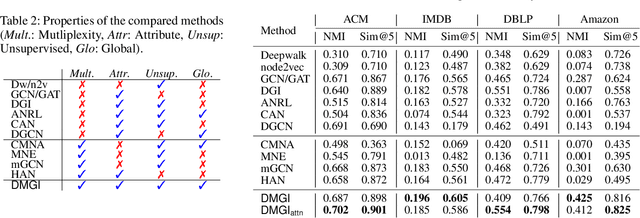
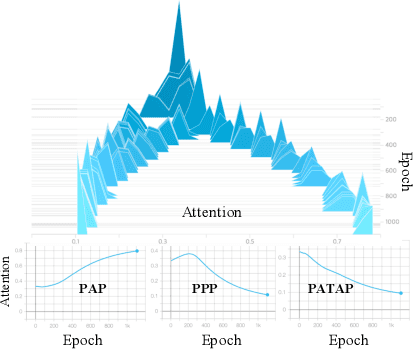
Nodes in a multiplex network are connected by multiple types of relations. However, most existing network embedding methods assume that only a single type of relation exists between nodes. Even for those that consider the multiplexity of a network, they overlook node attributes, resort to node labels for training, and fail to model the global properties of a graph. We present a simple yet effective unsupervised network embedding method for attributed multiplex network called DMGI, inspired by Deep Graph Infomax (DGI) that maximizes the mutual information between local patches of a graph, and the global representation of the entire graph. We devise a systematic way to jointly integrate the node embeddings from multiple graphs by introducing 1) the consensus regularization framework that minimizes the disagreements among the relation-type specific node embeddings, and 2) the universal discriminator that discriminates true samples regardless of the relation types. We also show that the attention mechanism infers the importance of each relation type, and thus can be useful for filtering unnecessary relation types as a preprocessing step. Extensive experiments on various downstream tasks demonstrate that DMGI outperforms the state-of-the-art methods, even though DMGI is fully unsupervised.
Mining News Events from Comparable News Corpora: A Multi-Attribute Proximity Network Modeling Approach
Nov 14, 2019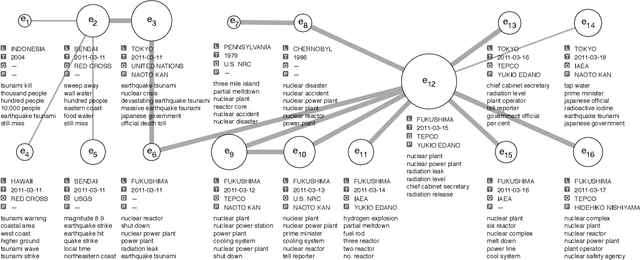
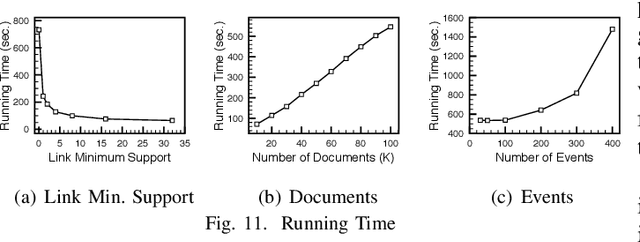
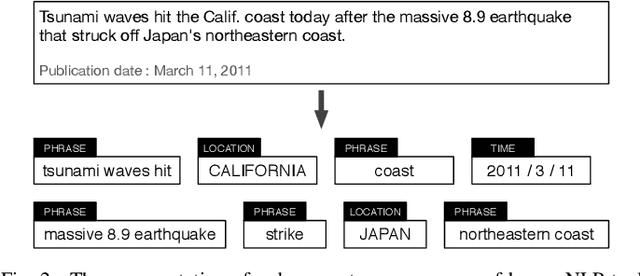
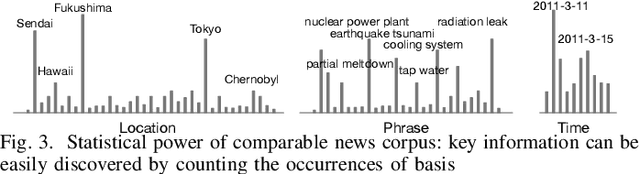
We present ProxiModel, a novel event mining framework for extracting high-quality structured event knowledge from large, redundant, and noisy news data sources. The proposed model differentiates itself from other approaches by modeling both the event correlation within each individual document as well as across the corpus. To facilitate this, we introduce the concept of a proximity-network, a novel space-efficient data structure to facilitate scalable event mining. This proximity network captures the corpus-level co-occurence statistics for candidate event descriptors, event attributes, as well as their connections. We probabilistically model the proximity network as a generative process with sparsity-inducing regularization. This allows us to efficiently and effectively extract high-quality and interpretable news events. Experiments on three different news corpora demonstrate that the proposed method is effective and robust at generating high-quality event descriptors and attributes. We briefly detail many interesting applications from our proposed framework such as news summarization, event tracking and multi-dimensional analysis on news. Finally, we explore a case study on visualizing the events for a Japan Tsunami news corpus and demonstrate ProxiModel's ability to automatically summarize emerging news events.
Spherical Text Embedding
Nov 04, 2019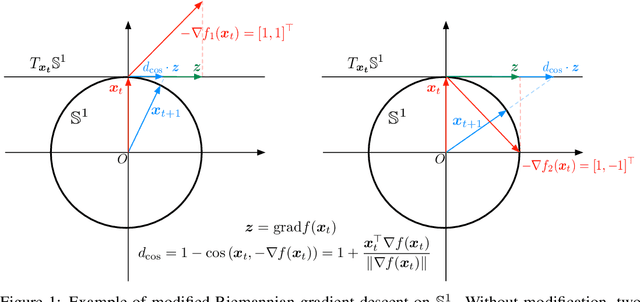
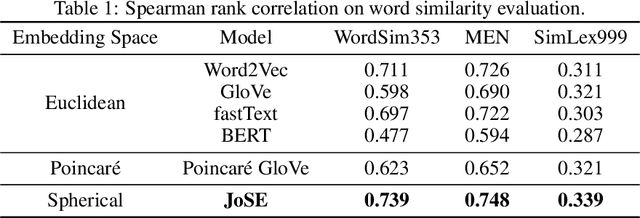
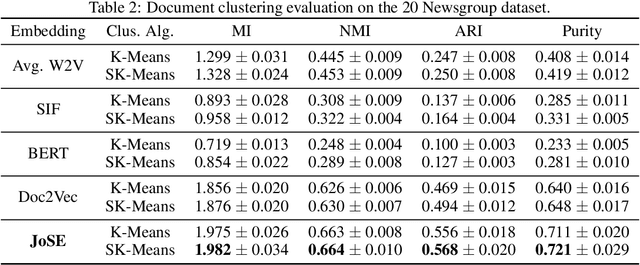
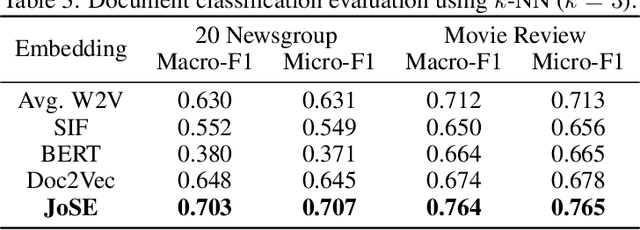
Unsupervised text embedding has shown great power in a wide range of NLP tasks. While text embeddings are typically learned in the Euclidean space, directional similarity is often more effective in tasks such as word similarity and document clustering, which creates a gap between the training stage and usage stage of text embedding. To close this gap, we propose a spherical generative model based on which unsupervised word and paragraph embeddings are jointly learned. To learn text embeddings in the spherical space, we develop an efficient optimization algorithm with convergence guarantee based on Riemannian optimization. Our model enjoys high efficiency and achieves state-of-the-art performances on various text embedding tasks including word similarity and document clustering.
Relation Learning on Social Networks with Multi-Modal Graph Edge Variational Autoencoders
Nov 04, 2019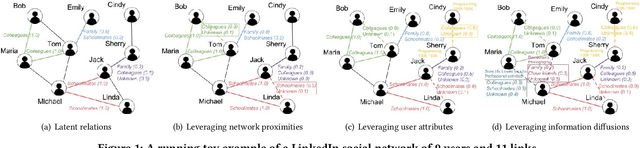
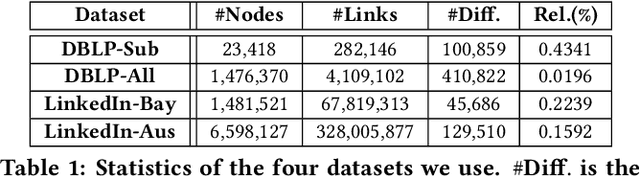
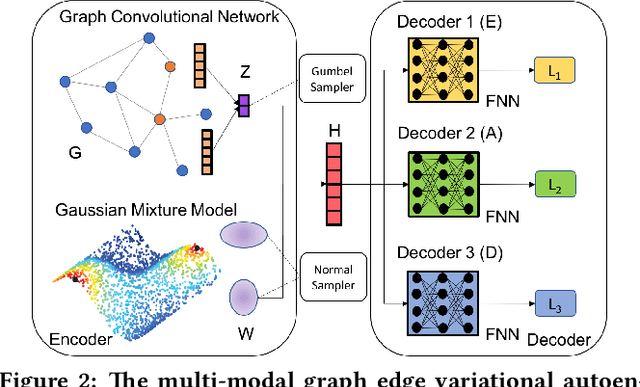
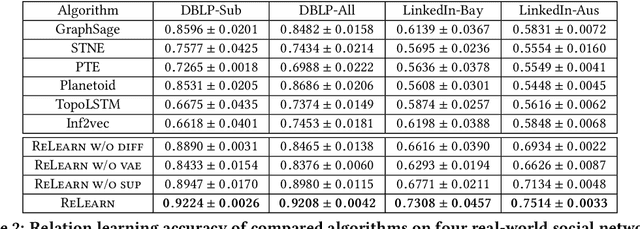
While node semantics have been extensively explored in social networks, little research attention has been paid to profile edge semantics, i.e., social relations. Ideal edge semantics should not only show that two users are connected, but also why they know each other and what they share in common. However, relations in social networks are often hard to profile, due to noisy multi-modal signals and limited user-generated ground-truth labels. In this work, we aim to develop a unified and principled framework that can profile user relations as edge semantics in social networks by integrating multi-modal signals in the presence of noisy and incomplete data. Our framework is also flexible towards limited or missing supervision. Specifically, we assume a latent distribution of multiple relations underlying each user link, and learn them with multi-modal graph edge variational autoencoders. We encode the network data with a graph convolutional network, and decode arbitrary signals with multiple reconstruction networks. Extensive experiments and case studies on two public DBLP author networks and two internal LinkedIn member networks demonstrate the superior effectiveness and efficiency of our proposed model.
FUSE: Multi-Faceted Set Expansion by Coherent Clustering of Skip-grams
Oct 22, 2019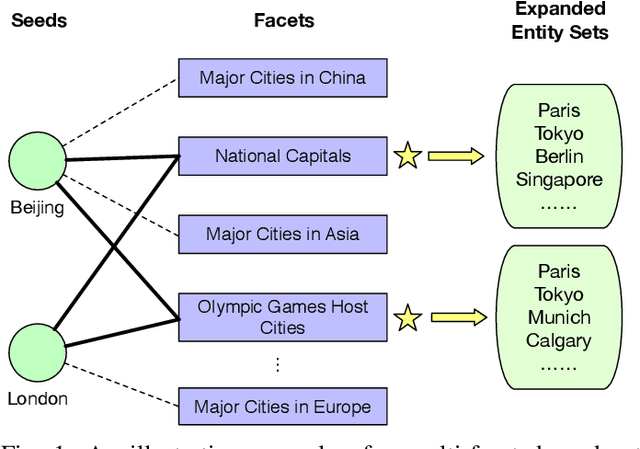
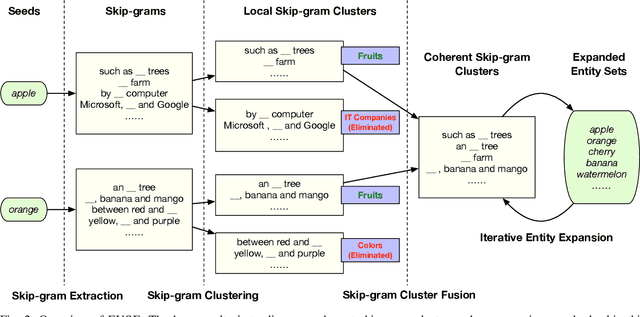
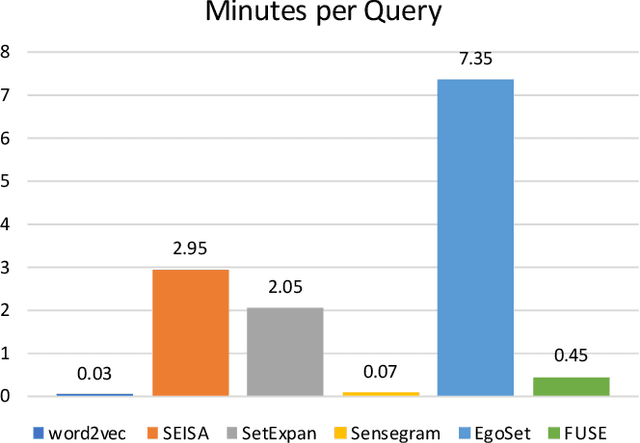
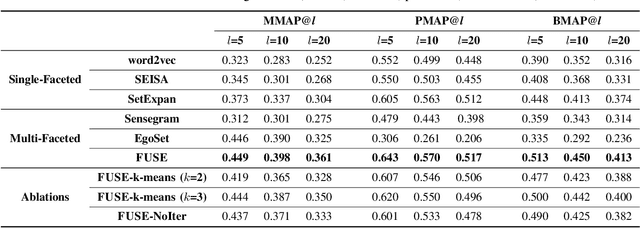
Set expansion aims to expand a small set of seed entities into a complete set of relevant entities. Most existing approaches assume the input seed set is unambiguous and completely ignore the multi-faceted semantics of seed entities. As a result, given the seed set {"Canon", "Sony", "Nikon"}, previous methods return one mixed set of entities that are either Camera Brands or Japanese Companies. In this paper, we study the task of multi-faceted set expansion, which aims to capture all semantic facets in the seed set and return multiple sets of entities, one for each semantic facet. We propose an unsupervised framework, FUSE, which consists of three major components: (1) facet discovery module: identifies all semantic facets of each seed entity by extracting and clustering its skip-grams, and (2) facet fusion module: discovers shared semantic facets of the entire seed set by an optimization formulation, and (3) entity expansion module: expands each semantic facet by utilizing an iterative algorithm robust to skip-gram noise. Extensive experiments demonstrate that our algorithm, FUSE, can accurately identify multiple semantic facets of the seed set and generate quality entities for each facet.
HiExpan: Task-Guided Taxonomy Construction by Hierarchical Tree Expansion
Oct 17, 2019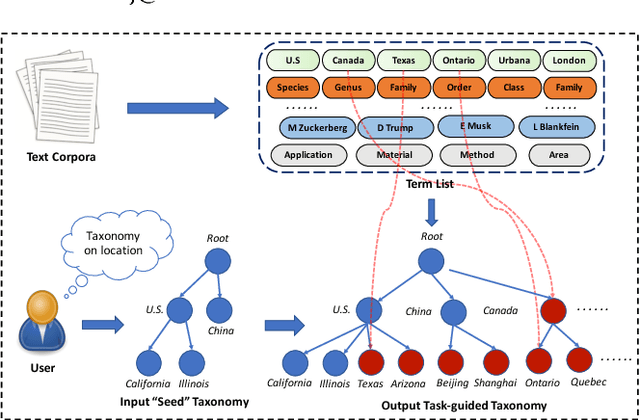
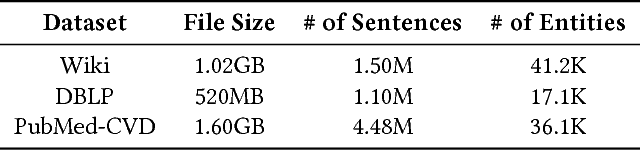
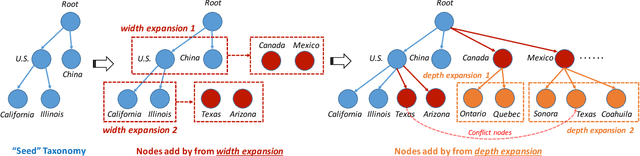
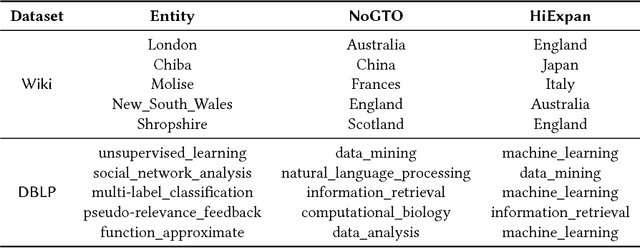
Taxonomies are of great value to many knowledge-rich applications. As the manual taxonomy curation costs enormous human effects, automatic taxonomy construction is in great demand. However, most existing automatic taxonomy construction methods can only build hypernymy taxonomies wherein each edge is limited to expressing the "is-a" relation. Such a restriction limits their applicability to more diverse real-world tasks where the parent-child may carry different relations. In this paper, we aim to construct a task-guided taxonomy from a domain-specific corpus and allow users to input a "seed" taxonomy, serving as the task guidance. We propose an expansion-based taxonomy construction framework, namely HiExpan, which automatically generates key term list from the corpus and iteratively grows the seed taxonomy. Specifically, HiExpan views all children under each taxonomy node forming a coherent set and builds the taxonomy by recursively expanding all these sets. Furthermore, HiExpan incorporates a weakly-supervised relation extraction module to extract the initial children of a newly-expanded node and adjusts the taxonomy tree by optimizing its global structure. Our experiments on three real datasets from different domains demonstrate the effectiveness of HiExpan for building task-guided taxonomies.
SetExpan: Corpus-Based Set Expansion via Context Feature Selection and Rank Ensemble
Oct 17, 2019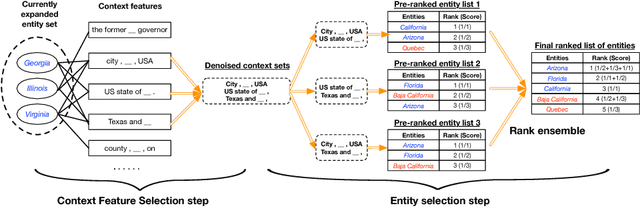
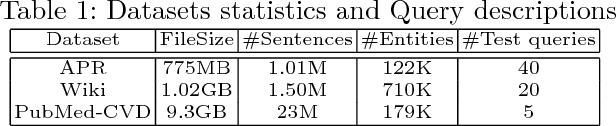
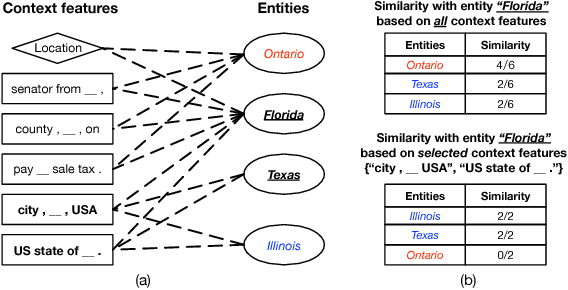
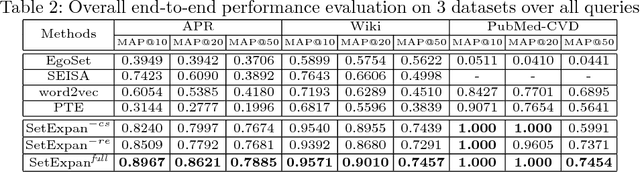
Corpus-based set expansion (i.e., finding the "complete" set of entities belonging to the same semantic class, based on a given corpus and a tiny set of seeds) is a critical task in knowledge discovery. It may facilitate numerous downstream applications, such as information extraction, taxonomy induction, question answering, and web search. To discover new entities in an expanded set, previous approaches either make one-time entity ranking based on distributional similarity, or resort to iterative pattern-based bootstrapping. The core challenge for these methods is how to deal with noisy context features derived from free-text corpora, which may lead to entity intrusion and semantic drifting. In this study, we propose a novel framework, SetExpan, which tackles this problem, with two techniques: (1) a context feature selection method that selects clean context features for calculating entity-entity distributional similarity, and (2) a ranking-based unsupervised ensemble method for expanding entity set based on denoised context features. Experiments on three datasets show that SetExpan is robust and outperforms previous state-of-the-art methods in terms of mean average precision.
HiGitClass: Keyword-Driven Hierarchical Classification of GitHub Repositories
Oct 16, 2019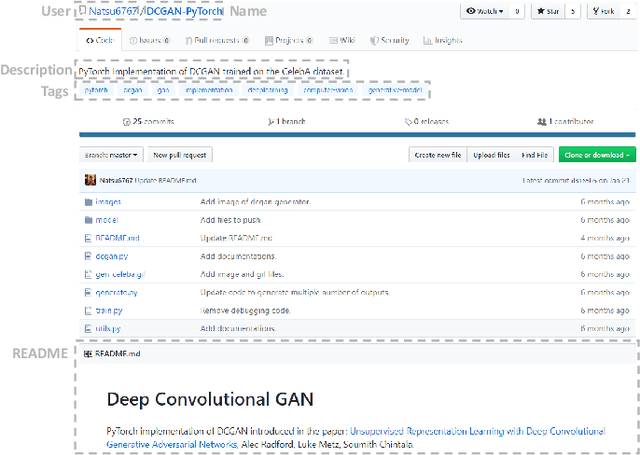
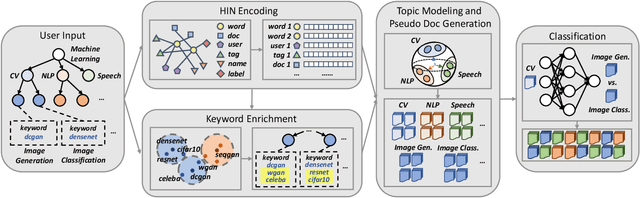
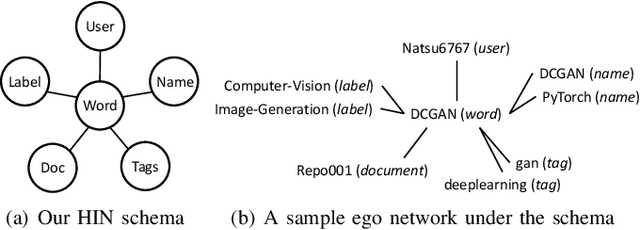
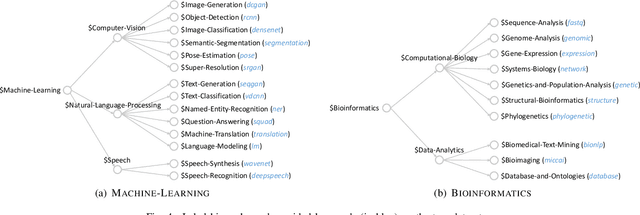
GitHub has become an important platform for code sharing and scientific exchange. With the massive number of repositories available, there is a pressing need for topic-based search. Even though the topic label functionality has been introduced, the majority of GitHub repositories do not have any labels, impeding the utility of search and topic-based analysis. This work targets the automatic repository classification problem as \textit{keyword-driven hierarchical classification}. Specifically, users only need to provide a label hierarchy with keywords to supply as supervision. This setting is flexible, adaptive to the users' needs, accounts for the different granularity of topic labels and requires minimal human effort. We identify three key challenges of this problem, namely (1) the presence of multi-modal signals; (2) supervision scarcity and bias; (3) supervision format mismatch. In recognition of these challenges, we propose the \textsc{HiGitClass} framework, comprising of three modules: heterogeneous information network embedding; keyword enrichment; topic modeling and pseudo document generation. Experimental results on two GitHub repository collections confirm that \textsc{HiGitClass} is superior to existing weakly-supervised and dataless hierarchical classification methods, especially in its ability to integrate both structured and unstructured data for repository classification.