 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Forcing: Towards Stable One-Step Autoregressive Video Generation
May 22, 2026Recent advances have substantially improved real-time interactive video generation in the autoregressive regime. However, most existing few-step autoregressive video generation methods, often distilled from a corresponding many-step teacher, default to a 4-step sampling configuration, which still incurs considerable latency during deployment and suffers from severe quality degradation when the number of sampling steps is further reduced, particularly in the one-step setting. Trajectory-style consistency distillation methods often produce videos with weak dynamics, while DMD-based approaches, such as Self-Forcing, tend to yield blurry frames. To address this challenge, we propose One-Forcing, a simple yet effective approach which augments the DMD objective with an auxiliary GAN loss for high-quality and efficient one-step video generation. Experiments on VBench show that One-Forcing achieves a total score of 83.76, establishing state-of-the-art performance among one-step causal video generation methods and remaining competitive with strong many-step approaches. We further demonstrate that one-step framewise autoregressive generation can be achieved stably with merely one-third of the training cost of the chunkwise model, a setting that prior methods have failed to achieve successfully.
All Vehicles Can Lie: Efficient Adversarial Defense in Fully Untrusted-Vehicle Collaborative Perception via Pseudo-Random Bayesian Inference
Mar 09, 2026Collaborative perception (CP) enables multiple vehicles to augment their individual perception capacities through the exchange of feature-level sensory data. However, this fusion mechanism is inherently vulnerable to adversarial attacks, especially in fully untrusted-vehicle environments. Existing defense approaches often assume a trusted ego vehicle as a reference or incorporate additional binary classifiers. These assumptions limit their practicality in real-world deployments due to the questionable trustworthiness of ego vehicles, the requirement for real-time detection, and the need for generalizability across diverse scenarios. To address these challenges, we propose a novel Pseudo-Random Bayesian Inference (PRBI) framework, a first efficient defense method tailored for fully untrusted-vehicle CP. PRBI detects adversarial behavior by leveraging temporal perceptual discrepancies, using the reliable perception from the preceding frame as a dynamic reference. Additionally, it employs a pseudo-random grouping strategy that requires only two verifications per frame, while applying Bayesian inference to estimate both the number and identities of malicious vehicles. Theoretical analysis has proven the convergence and stability of the proposed PRBI framework. Extensive experiments show that PRBI requires only 2.5 verifications per frame on average, outperforming existing methods significantly, and restores detection precision to between 79.4% and 86.9% of pre-attack levels.
Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents
Jan 05, 2026Large language model (LLM) agents face fundamental limitations in long-horizon reasoning due to finite context windows, making effective memory management critical. Existing methods typically handle long-term memory (LTM) and short-term memory (STM) as separate components, relying on heuristics or auxiliary controllers, which limits adaptability and end-to-end optimization. In this paper, we propose Agentic Memory (AgeMem), a unified framework that integrates LTM and STM management directly into the agent's policy. AgeMem exposes memory operations as tool-based actions, enabling the LLM agent to autonomously decide what and when to store, retrieve, update, summarize, or discard information. To train such unified behaviors, we propose a three-stage progressive reinforcement learning strategy and design a step-wise GRPO to address sparse and discontinuous rewards induced by memory operations. Experiments on five long-horizon benchmarks demonstrate that AgeMem consistently outperforms strong memory-augmented baselines across multiple LLM backbones, achieving improved task performance, higher-quality long-term memory, and more efficient context usage.
Astra: General Interactive World Model with Autoregressive Denoising
Dec 15, 2025



Recent advances in diffusion transformers have empowered video generation models to generate high-quality video clips from texts or images. However, world models with the ability to predict long-horizon futures from past observations and actions remain underexplored, especially for general-purpose scenarios and various forms of actions. To bridge this gap, we introduce Astra, an interactive general world model that generates real-world futures for diverse scenarios (e.g., autonomous driving, robot grasping) with precise action interactions (e.g., camera motion, robot action). We propose an autoregressive denoising architecture and use temporal causal attention to aggregate past observations and support streaming outputs. We use a noise-augmented history memory to avoid over-reliance on past frames to balance responsiveness with temporal coherence. For precise action control, we introduce an action-aware adapter that directly injects action signals into the denoising process. We further develop a mixture of action experts that dynamically route heterogeneous action modalities, enhancing versatility across diverse real-world tasks such as exploration, manipulation, and camera control. Astra achieves interactive, consistent, and general long-term video prediction and supports various forms of interactions. Experiments across multiple datasets demonstrate the improvements of Astra in fidelity, long-range prediction, and action alignment over existing state-of-the-art world models.
EagleVision: Object-level Attribute Multimodal LLM for Remote Sensing
Mar 30, 2025Recent advances in multimodal large language models (MLLMs) have demonstrated impressive results in various visual tasks. However, in remote sensing (RS), high resolution and small proportion of objects pose challenges to existing MLLMs, which struggle with object-centric tasks, particularly in precise localization and fine-grained attribute description for each object. These RS MLLMs have not yet surpassed classical visual perception models, as they only provide coarse image understanding, leading to limited gains in real-world scenarios. To address this gap, we establish EagleVision, an MLLM tailored for remote sensing that excels in object detection and attribute comprehension. Equipped with the Attribute Disentangle module, EagleVision learns disentanglement vision tokens to express distinct attributes. To support object-level visual-language alignment, we construct EVAttrs-95K, the first large-scale object attribute understanding dataset in RS for instruction tuning, along with a novel evaluation benchmark, EVBench. EagleVision achieves state-of-the-art performance on both fine-grained object detection and object attribute understanding tasks, highlighting the mutual promotion between detection and understanding capabilities in MLLMs. The code, model, data, and demo will be available at https://github.com/XiangTodayEatsWhat/EagleVision.
Topology-Aware 3D Gaussian Splatting: Leveraging Persistent Homology for Optimized Structural Integrity
Dec 21, 2024Gaussian Splatting (GS) has emerged as a crucial technique for representing discrete volumetric radiance fields. It leverages unique parametrization to mitigate computational demands in scene optimization. This work introduces Topology-Aware 3D Gaussian Splatting (Topology-GS), which addresses two key limitations in current approaches: compromised pixel-level structural integrity due to incomplete initial geometric coverage, and inadequate feature-level integrity from insufficient topological constraints during optimization. To overcome these limitations, Topology-GS incorporates a novel interpolation strategy, Local Persistent Voronoi Interpolation (LPVI), and a topology-focused regularization term based on persistent barcodes, named PersLoss. LPVI utilizes persistent homology to guide adaptive interpolation, enhancing point coverage in low-curvature areas while preserving topological structure. PersLoss aligns the visual perceptual similarity of rendered images with ground truth by constraining distances between their topological features. Comprehensive experiments on three novel-view synthesis benchmarks demonstrate that Topology-GS outperforms existing methods in terms of PSNR, SSIM, and LPIPS metrics, while maintaining efficient memory usage. This study pioneers the integration of topology with 3D-GS, laying the groundwork for future research in this area.
A Survey on Graph Neural Networks in Intelligent Transportation Systems
Jan 02, 2024



Intelligent Transportation System (ITS) is vital in improving traffic congestion, reducing traffic accidents, optimizing urban planning, etc. However, due to the complexity of the traffic network, traditional machine learning and statistical methods are relegated to the background. With the advent of the artificial intelligence era, many deep learning frameworks have made remarkable progress in various fields and are now considered effective methods in many areas. As a deep learning method, Graph Neural Networks (GNNs) have emerged as a highly competitive method in the ITS field since 2019 due to their strong ability to model graph-related problems. As a result, more and more scholars pay attention to the applications of GNNs in transportation domains, which have shown excellent performance. However, most of the research in this area is still concentrated on traffic forecasting, while other ITS domains, such as autonomous vehicles and urban planning, still require more attention. This paper aims to review the applications of GNNs in six representative and emerging ITS domains: traffic forecasting, autonomous vehicles, traffic signal control, transportation safety, demand prediction, and parking management. We have reviewed extensive graph-related studies from 2018 to 2023, summarized their methods, features, and contributions, and presented them in informative tables or lists. Finally, we have identified the challenges of applying GNNs to ITS and suggested potential future directions.
Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
May 20, 2022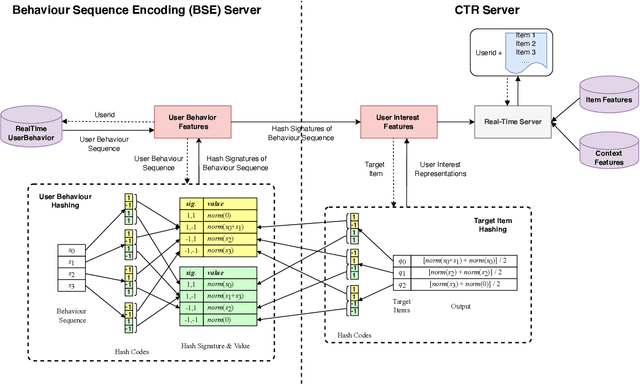

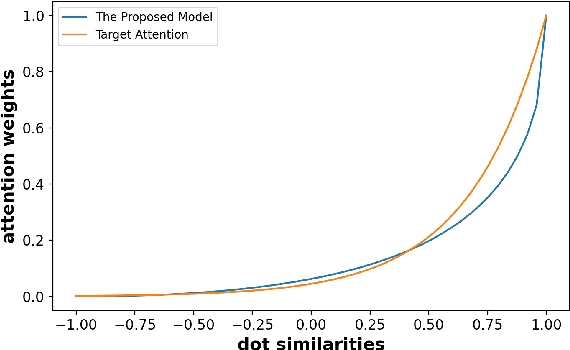
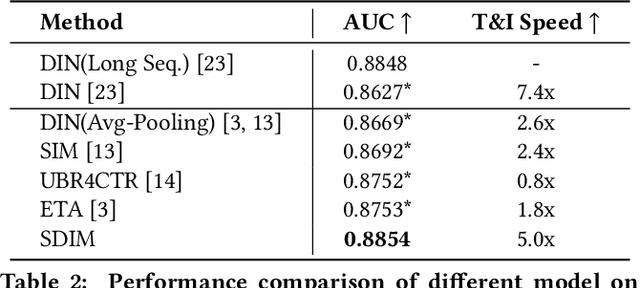
Rich user behavior data has been proven to be of great value for Click-Through Rate (CTR) prediction applications, especially in industrial recommender, search, or advertising systems. However, it's non-trivial for real-world systems to make full use of long-term user behaviors due to the strict requirements of online serving time. Most previous works adopt the retrieval-based strategy, where a small number of user behaviors are retrieved first for subsequent attention. However, the retrieval-based methods are sub-optimal and would cause more or less information losses, and it's difficult to balance the effectiveness and efficiency of the retrieval algorithm. In this paper, we propose \textbf{SDIM} (\textbf{S}ampling-based \textbf{D}eep \textbf{I}nterest \textbf{M}odeling), a simple yet effective sampling-based end-to-end approach for modeling long-term user behaviors. We sample from multiple hash functions to generate hash signatures of the candidate item and each item in the user behavior sequence, and obtain the user interest by directly gathering behavior items associated with the candidate item with the same hash signature. We show theoretically and experimentally that the proposed method performs on par with standard attention-based models on modeling long-term user behaviors, while being sizable times faster. We also introduce the deployment of SDIM in our system. Specifically, we decouple the behavior sequence hashing, which is the most time-consuming part, from the CTR model by designing a separate module named BSE (behavior Sequence Encoding). BSE is latency-free for the CTR server, enabling us to model extremely long user behaviors. Both offline and online experiments are conducted to demonstrate the effectiveness of SDIM. SDIM now has been deployed online in the search system of Meituan APP.