 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpostor: An Agent-Curated Benchmark for Realistic AIGC Manipulation Localization
Jun 03, 2026Recent advances in generative image editing have improved the realism and controllability of localized image manipulation, raising new challenges for image manipulation detection and localization (IMDL). However, existing IMDL benchmarks still have limitations in visual realism, manipulation diversity, and generator coverage, making it difficult to reflect recent trends in image manipulation. To address these limitations, we introduce Impostor, a high-quality AI-edited image manipulation localization dataset containing 100K manipulated images. Impostor is constructed by CraftAgent, a closed-loop agent framework that integrates scene perception, editing planning, manipulation execution, quality validation, and iterative reflection to automatically generate diverse and visually realistic manipulated images. Moreover, Impostor contains images generated by seven recent AIGC models across three manipulation types and includes multiple manipulated regions, providing a more comprehensive benchmark for AIGC-based IMDL. Furthermore, we propose PhaseAware-Net (PANet), a semantic-forensic framework that introduces local phase modeling and semantic-forensic consistency learning to better localize semantically plausible yet forensically disrupted manipulated regions. Extensive experiments show that Impostor poses significant challenges to existing large vision-language models (LVLMs) and specialized IMDL methods, while PANet achieves superior performance on Impostor and multiple public benchmarks.
EagleVision: Object-level Attribute Multimodal LLM for Remote Sensing
Mar 30, 2025Recent advances in multimodal large language models (MLLMs) have demonstrated impressive results in various visual tasks. However, in remote sensing (RS), high resolution and small proportion of objects pose challenges to existing MLLMs, which struggle with object-centric tasks, particularly in precise localization and fine-grained attribute description for each object. These RS MLLMs have not yet surpassed classical visual perception models, as they only provide coarse image understanding, leading to limited gains in real-world scenarios. To address this gap, we establish EagleVision, an MLLM tailored for remote sensing that excels in object detection and attribute comprehension. Equipped with the Attribute Disentangle module, EagleVision learns disentanglement vision tokens to express distinct attributes. To support object-level visual-language alignment, we construct EVAttrs-95K, the first large-scale object attribute understanding dataset in RS for instruction tuning, along with a novel evaluation benchmark, EVBench. EagleVision achieves state-of-the-art performance on both fine-grained object detection and object attribute understanding tasks, highlighting the mutual promotion between detection and understanding capabilities in MLLMs. The code, model, data, and demo will be available at https://github.com/XiangTodayEatsWhat/EagleVision.
Multi-Camera Calibration Free BEV Representation for 3D Object Detection
Oct 31, 2022



In advanced paradigms of autonomous driving, learning Bird's Eye View (BEV) representation from surrounding views is crucial for multi-task framework. However, existing methods based on depth estimation or camera-driven attention are not stable to obtain transformation under noisy camera parameters, mainly with two challenges, accurate depth prediction and calibration. In this work, we present a completely Multi-Camera Calibration Free Transformer (CFT) for robust BEV representation, which focuses on exploring implicit mapping, not relied on camera intrinsics and extrinsics. To guide better feature learning from image views to BEV, CFT mines potential 3D information in BEV via our designed position-aware enhancement (PA). Instead of camera-driven point-wise or global transformation, for interaction within more effective region and lower computation cost, we propose a view-aware attention which also reduces redundant computation and promotes converge. CFT achieves 49.7% NDS on the nuScenes detection task leaderboard, which is the first work removing camera parameters, comparable to other geometry-guided methods. Without temporal input and other modal information, CFT achieves second highest performance with a smaller image input 1600 * 640. Thanks to view-attention variant, CFT reduces memory and transformer FLOPs for vanilla attention by about 12% and 60%, respectively, with improved NDS by 1.0%. Moreover, its natural robustness to noisy camera parameters makes CFT more competitive.
Inference-InfoGAN: Inference Independence via Embedding Orthogonal Basis Expansion
Oct 02, 2021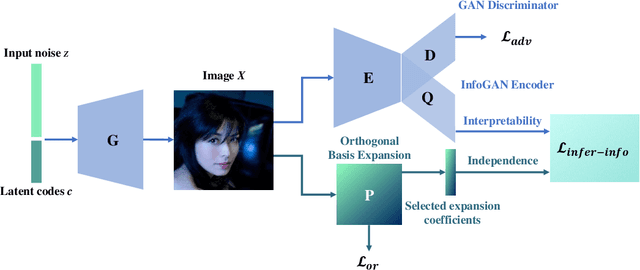
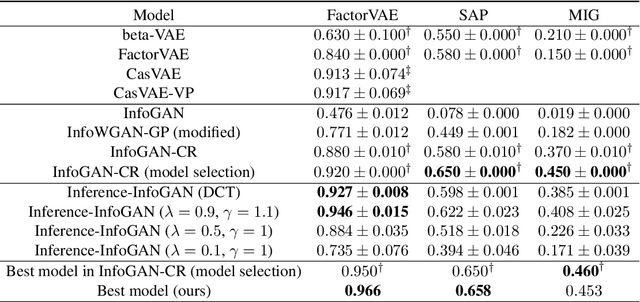
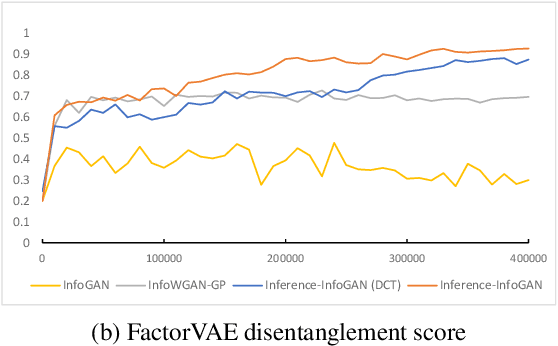
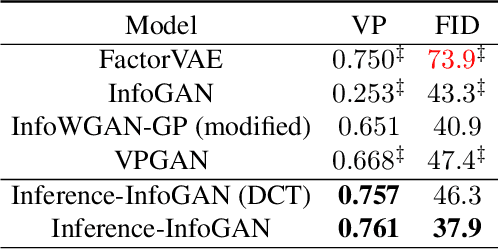
Disentanglement learning aims to construct independent and interpretable latent variables in which generative models are a popular strategy. InfoGAN is a classic method via maximizing Mutual Information (MI) to obtain interpretable latent variables mapped to the target space. However, it did not emphasize independent characteristic. To explicitly infer latent variables with inter-independence, we propose a novel GAN-based disentanglement framework via embedding Orthogonal Basis Expansion (OBE) into InfoGAN network (Inference-InfoGAN) in an unsupervised way. Under the OBE module, one set of orthogonal basis can be adaptively found to expand arbitrary data with independence property. To ensure the target-wise interpretable representation, we add a consistence constraint between the expansion coefficients and latent variables on the base of MI maximization. Additionally, we design an alternating optimization step on the consistence constraint and orthogonal requirement updating, so that the training of Inference-InfoGAN can be more convenient. Finally, experiments validate that our proposed OBE module obtains adaptive orthogonal basis, which can express better independent characteristics than fixed basis expression of Discrete Cosine Transform (DCT). To depict the performance in downstream tasks, we compared with the state-of-the-art GAN-based and even VAE-based approaches on different datasets. Our Inference-InfoGAN achieves higher disentanglement score in terms of FactorVAE, Separated Attribute Predictability (SAP), Mutual Information Gap (MIG) and Variation Predictability (VP) metrics without model fine-tuning. All the experimental results illustrate that our method has inter-independence inference ability because of the OBE module, and provides a good trade-off between it and target-wise interpretability of latent variables via jointing the alternating optimization.