 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Semantic Segmentation by Self-Supervised Source Domain Projection and Multi-Level Contrastive Learning
Mar 03, 2023



Deep networks trained on the source domain show degraded performance when tested on unseen target domain data. To enhance the model's generalization ability, most existing domain generalization methods learn domain invariant features by suppressing domain sensitive features. Different from them, we propose a Domain Projection and Contrastive Learning (DPCL) approach for generalized semantic segmentation, which includes two modules: Self-supervised Source Domain Projection (SSDP) and Multi-level Contrastive Learning (MLCL). SSDP aims to reduce domain gap by projecting data to the source domain, while MLCL is a learning scheme to learn discriminative and generalizable features on the projected data. During test time, we first project the target data by SSDP to mitigate domain shift, then generate the segmentation results by the learned segmentation network based on MLCL. At test time, we can update the projected data by minimizing our proposed pixel-to-pixel contrastive loss to obtain better results. Extensive experiments for semantic segmentation demonstrate the favorable generalization capability of our method on benchmark datasets.
EdgeYOLO: An Edge-Real-Time Object Detector
Feb 15, 2023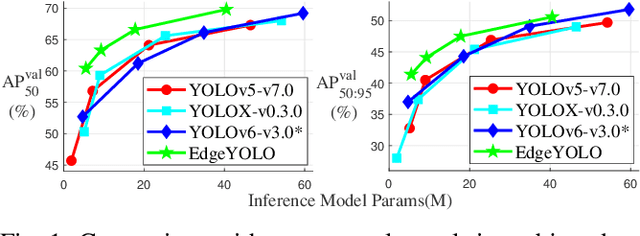
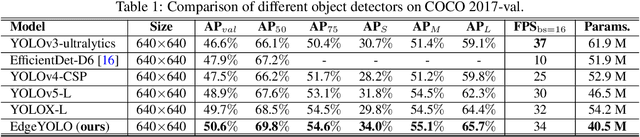

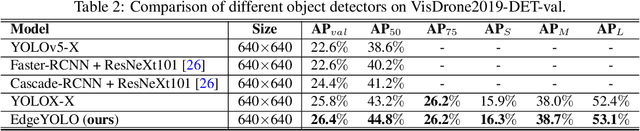
This paper proposes an efficient, low-complexity and anchor-free object detector based on the state-of-the-art YOLO framework, which can be implemented in real time on edge computing platforms. We develop an enhanced data augmentation method to effectively suppress overfitting during training, and design a hybrid random loss function to improve the detection accuracy of small objects. Inspired by FCOS, a lighter and more efficient decoupled head is proposed, and its inference speed can be improved with little loss of precision. Our baseline model can reach the accuracy of 50.6% AP50:95 and 69.8% AP50 in MS COCO2017 dataset, 26.4% AP50:95 and 44.8% AP50 in VisDrone2019-DET dataset, and it meets real-time requirements (FPS>=30) on edge-computing device Nvidia Jetson AGX Xavier. We also designed lighter models with less parameters for edge computing devices with lower computing power, which also show better performances. Our source code, hyper-parameters and model weights are all available at https://github.com/LSH9832/edgeyolo.
Time-attenuating Twin Delayed DDPG Reinforcement Learning for Trajectory Tracking Control of Quadrotors
Feb 13, 2023



Continuous trajectory tracking control of quadrotors is complicated when considering noise from the environment. Due to the difficulty in modeling the environmental dynamics, tracking methodologies based on conventional control theory, such as model predictive control, have limitations on tracking accuracy and response time. We propose a Time-attenuating Twin Delayed DDPG, a model-free algorithm that is robust to noise, to better handle the trajectory tracking task. A deep reinforcement learning framework is constructed, where a time decay strategy is designed to avoid trapping into local optima. The experimental results show that the tracking error is significantly small, and the operation time is one-tenth of that of a traditional algorithm. The OpenAI Mujoco tool is used to verify the proposed algorithm, and the simulation results show that, the proposed method can significantly improve the training efficiency and effectively improve the accuracy and convergence stability.
Dynamic Grained Encoder for Vision Transformers
Jan 10, 2023Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
Towards Generalized Open Information Extraction
Nov 29, 2022



Open Information Extraction (OpenIE) facilitates the open-domain discovery of textual facts. However, the prevailing solutions evaluate OpenIE models on in-domain test sets aside from the training corpus, which certainly violates the initial task principle of domain-independence. In this paper, we propose to advance OpenIE towards a more realistic scenario: generalizing over unseen target domains with different data distributions from the source training domains, termed Generalized OpenIE. For this purpose, we first introduce GLOBE, a large-scale human-annotated multi-domain OpenIE benchmark, to examine the robustness of recent OpenIE models to domain shifts, and the relative performance degradation of up to 70% implies the challenges of generalized OpenIE. Then, we propose DragonIE, which explores a minimalist graph expression of textual fact: directed acyclic graph, to improve the OpenIE generalization. Extensive experiments demonstrate that DragonIE beats the previous methods in both in-domain and out-of-domain settings by as much as 6.0% in F1 score absolutely, but there is still ample room for improvement.
Semi-Supervised Lifelong Language Learning
Nov 23, 2022



Lifelong learning aims to accumulate knowledge and alleviate catastrophic forgetting when learning tasks sequentially. However, existing lifelong language learning methods only focus on the supervised learning setting. Unlabeled data, which can be easily accessed in real-world scenarios, are underexplored. In this paper, we explore a novel setting, semi-supervised lifelong language learning (SSLL), where a model learns sequentially arriving language tasks with both labeled and unlabeled data. We propose an unlabeled data enhanced lifelong learner to explore SSLL. Specially, we dedicate task-specific modules to alleviate catastrophic forgetting and design two modules to exploit unlabeled data: (1) a virtual supervision enhanced task solver is constructed on a teacher-student framework to mine the underlying knowledge from unlabeled data; and (2) a backward augmented learner is built to encourage knowledge transfer from newly arrived unlabeled data to previous tasks. Experimental results on various language tasks demonstrate our model's effectiveness and superiority over competitive baselines under the new setting SSLL.
CGoDial: A Large-Scale Benchmark for Chinese Goal-oriented Dialog Evaluation
Nov 21, 2022Practical dialog systems need to deal with various knowledge sources, noisy user expressions, and the shortage of annotated data. To better solve the above problems, we propose CGoDial, new challenging and comprehensive Chinese benchmark for multi-domain Goal-oriented Dialog evaluation. It contains 96,763 dialog sessions and 574,949 dialog turns totally, covering three datasets with different knowledge sources: 1) a slot-based dialog (SBD) dataset with table-formed knowledge, 2) a flow-based dialog (FBD) dataset with tree-formed knowledge, and a retrieval-based dialog (RBD) dataset with candidate-formed knowledge. To bridge the gap between academic benchmarks and spoken dialog scenarios, we either collect data from real conversations or add spoken features to existing datasets via crowd-sourcing. The proposed experimental settings include the combinations of training with either the entire training set or a few-shot training set, and testing with either the standard test set or a hard test subset, which can assess model capabilities in terms of general prediction, fast adaptability and reliable robustness.
Estimating Soft Labels for Out-of-Domain Intent Detection
Nov 10, 2022Out-of-Domain (OOD) intent detection is important for practical dialog systems. To alleviate the issue of lacking OOD training samples, some works propose synthesizing pseudo OOD samples and directly assigning one-hot OOD labels to these pseudo samples. However, these one-hot labels introduce noises to the training process because some hard pseudo OOD samples may coincide with In-Domain (IND) intents. In this paper, we propose an adaptive soft pseudo labeling (ASoul) method that can estimate soft labels for pseudo OOD samples when training OOD detectors. Semantic connections between pseudo OOD samples and IND intents are captured using an embedding graph. A co-training framework is further introduced to produce resulting soft labels following the smoothness assumption, i.e., close samples are likely to have similar labels. Extensive experiments on three benchmark datasets show that ASoul consistently improves the OOD detection performance and outperforms various competitive baselines.
Prompt Conditioned VAE: Enhancing Generative Replay for Lifelong Learning in Task-Oriented Dialogue
Oct 14, 2022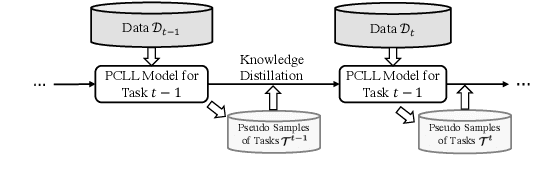
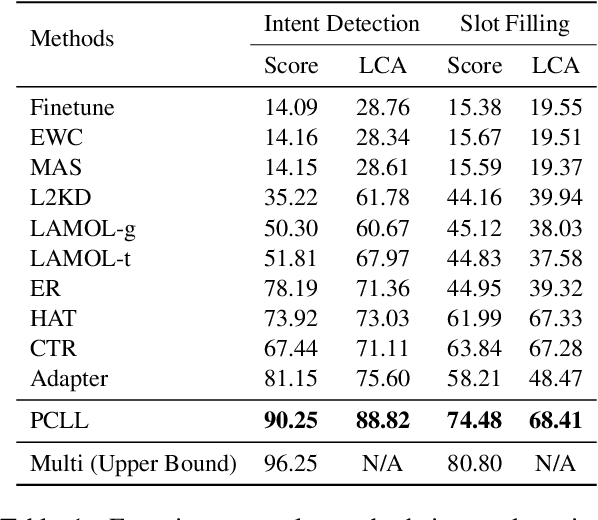
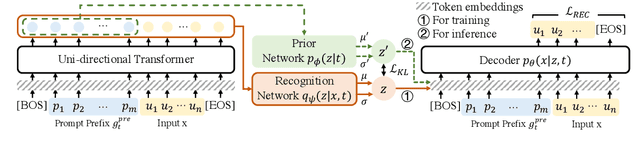
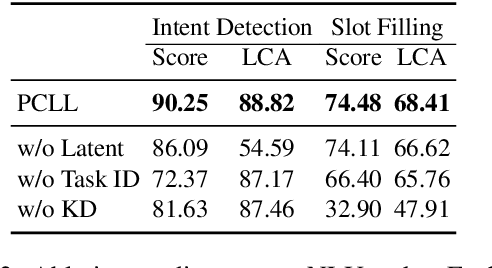
Lifelong learning (LL) is vital for advanced task-oriented dialogue (ToD) systems. To address the catastrophic forgetting issue of LL, generative replay methods are widely employed to consolidate past knowledge with generated pseudo samples. However, most existing generative replay methods use only a single task-specific token to control their models. This scheme is usually not strong enough to constrain the generative model due to insufficient information involved. In this paper, we propose a novel method, prompt conditioned VAE for lifelong learning (PCLL), to enhance generative replay by incorporating tasks' statistics. PCLL captures task-specific distributions with a conditional variational autoencoder, conditioned on natural language prompts to guide the pseudo-sample generation. Moreover, it leverages a distillation process to further consolidate past knowledge by alleviating the noise in pseudo samples. Experiments on natural language understanding tasks of ToD systems demonstrate that PCLL significantly outperforms competitive baselines in building LL models.
Stacking Ensemble Learning in Deep Domain Adaptation for Ophthalmic Image Classification
Sep 27, 2022Domain adaptation is an attractive approach given the availability of a large amount of labeled data with similar properties but different domains. It is effective in image classification tasks where obtaining sufficient label data is challenging. We propose a novel method, named SELDA, for stacking ensemble learning via extending three domain adaptation methods for effectively solving real-world problems. The major assumption is that when base domain adaptation models are combined, we can obtain a more accurate and robust model by exploiting the ability of each of the base models. We extend Maximum Mean Discrepancy (MMD), Low-rank coding, and Correlation Alignment (CORAL) to compute the adaptation loss in three base models. Also, we utilize a two-fully connected layer network as a meta-model to stack the output predictions of these three well-performing domain adaptation models to obtain high accuracy in ophthalmic image classification tasks. The experimental results using Age-Related Eye Disease Study (AREDS) benchmark ophthalmic dataset demonstrate the effectiveness of the proposed model.