 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Online Gradient is Optimum for Dynamic Regret
Oct 23, 2018In online learning, the dynamic regret metric chooses the reference (optimal) solution that may change over time, while the typical (static) regret metric assumes the reference solution to be constant over the whole time horizon. The dynamic regret metric is particularly interesting for applications such as online recommendation (since the customers' preference always evolves over time). While the online gradient method has been shown to be optimal for the static regret metric, the optimal algorithm for the dynamic regret remains unknown. In this paper, we show that proximal online gradient (a general version of online gradient) is optimum to the dynamic regret by showing that the proved lower bound matches the upper bound that slightly improves existing upper bound.
Distributed Learning over Unreliable Networks
Oct 17, 2018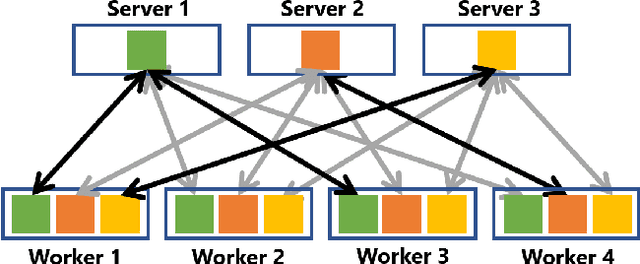
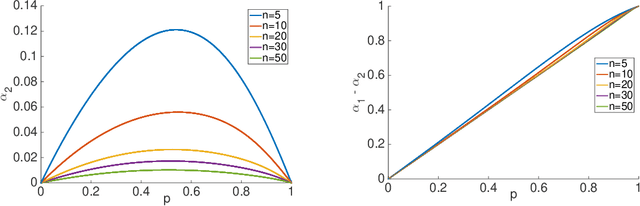
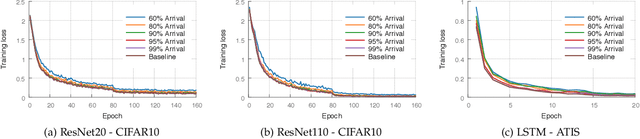
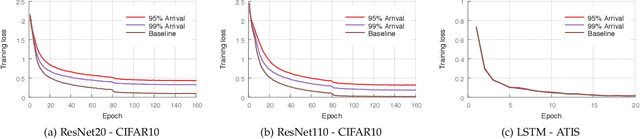
Most of today's distributed machine learning systems assume {\em reliable networks}: whenever two machines exchange information (e.g., gradients or models), the network should guarantee the delivery of the message. At the same time, recent work exhibits the impressive tolerance of machine learning algorithms to errors or noise arising from relaxed communication or synchronization. In this paper, we connect these two trends, and consider the following question: {\em Can we design machine learning systems that are tolerant to network unreliability during training?} With this motivation, we focus on a theoretical problem of independent interest---given a standard distributed parameter server architecture, if every communication between the worker and the server has a non-zero probability $p$ of being dropped, does there exist an algorithm that still converges, and at what speed? In the context of prior art, this problem can be phrased as {\em distributed learning over random topologies}. The technical contribution of this paper is a novel theoretical analysis proving that distributed learning over random topologies can achieve comparable convergence rate to centralized or distributed learning over reliable networks. Further, we prove that the influence of the packet drop rate diminishes with the growth of the number of \textcolor{black}{parameter servers}. We map this theoretical result onto a real-world scenario, training deep neural networks over an unreliable network layer, and conduct network simulation to validate the system improvement by allowing the networks to be unreliable.
Revisit Batch Normalization: New Understanding from an Optimization View and a Refinement via Composition Optimization
Oct 15, 2018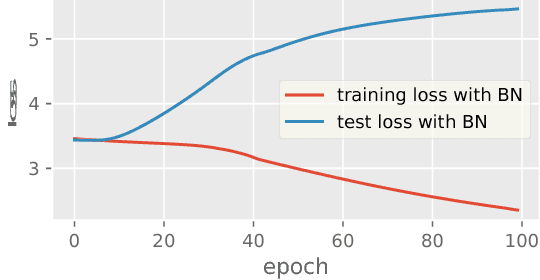
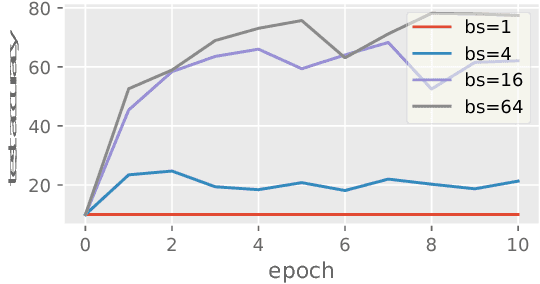
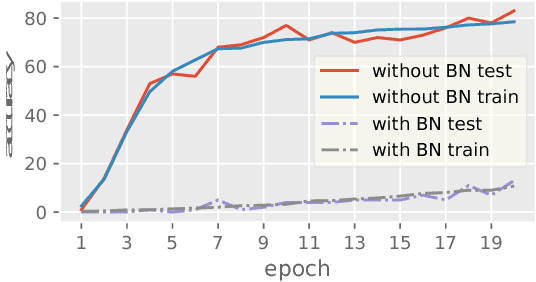
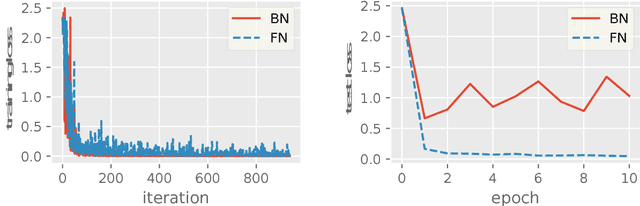
Batch Normalization (BN) has been used extensively in deep learning to achieve faster training process and better resulting models. However, whether BN works strongly depends on how the batches are constructed during training and it may not converge to a desired solution if the statistics on a batch are not close to the statistics over the whole dataset. In this paper, we try to understand BN from an optimization perspective by formulating the optimization problem which motivates BN. We show when BN works and when BN does not work by analyzing the optimization problem. We then propose a refinement of BN based on compositional optimization techniques called Full Normalization (FN) to alleviate the issues of BN when the batches are not constructed ideally. We provide convergence analysis for FN and empirically study its effectiveness to refine BN.
Fully Implicit Online Learning
Oct 14, 2018
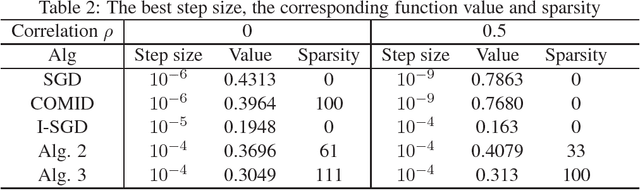
Regularized online learning is widely used in machine learning applications. In this paper we analyze a class of regularized online algorithms without linearizing the loss function or the regularizer, which we call \emph{fully implicit online learning} (FIOL). We show that the FIOL algorithm admits a better regret than the linearization approximate algorithm if each iteration in FIOL can be solved exactly. Then we show that by exploring the structure of a large class of loss functions and regularizers, the computational complexity of FIOL in each iteration is comparable to its linearized part, even if no closed-form solution exists. Experiments validate the proposed approaches.
Parametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space
Oct 10, 2018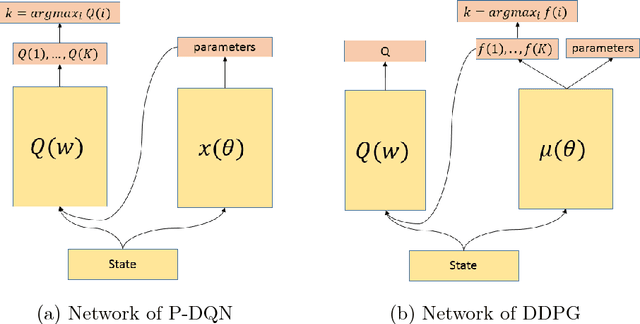
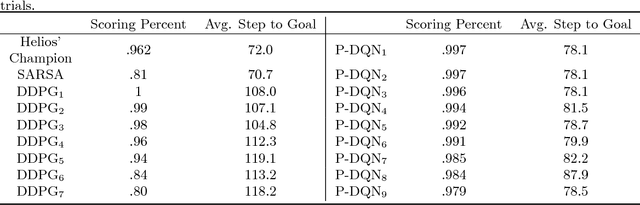
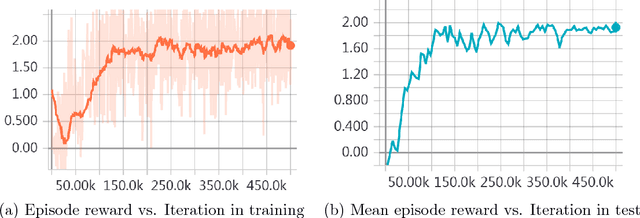

Most existing deep reinforcement learning (DRL) frameworks consider either discrete action space or continuous action space solely. Motivated by applications in computer games, we consider the scenario with discrete-continuous hybrid action space. To handle hybrid action space, previous works either approximate the hybrid space by discretization, or relax it into a continuous set. In this paper, we propose a parametrized deep Q-network (P- DQN) framework for the hybrid action space without approximation or relaxation. Our algorithm combines the spirits of both DQN (dealing with discrete action space) and DDPG (dealing with continuous action space) by seamlessly integrating them. Empirical results on a simulation example, scoring a goal in simulated RoboCup soccer and the solo mode in game King of Glory (KOG) validate the efficiency and effectiveness of our method.
Communication Compression for Decentralized Training
Sep 27, 2018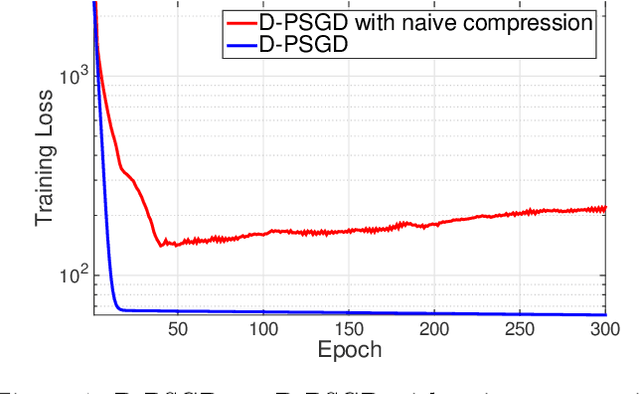
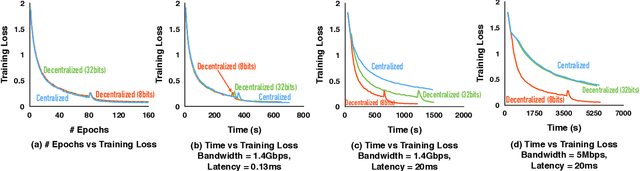
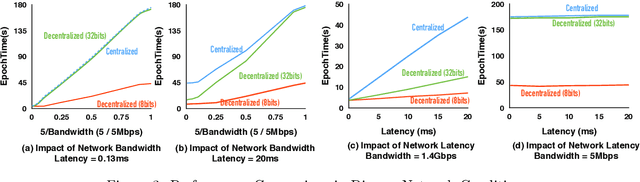
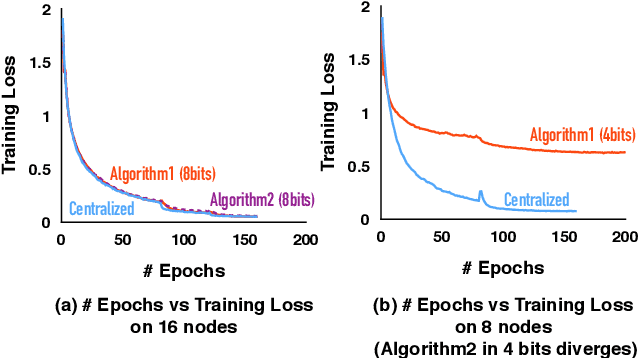
Optimizing distributed learning systems is an art of balancing between computation and communication. There have been two lines of research that try to deal with slower networks: {\em communication compression} for low bandwidth networks, and {\em decentralization} for high latency networks. In this paper, We explore a natural question: {\em can the combination of both techniques lead to a system that is robust to both bandwidth and latency?} Although the system implication of such combination is trivial, the underlying theoretical principle and algorithm design is challenging: unlike centralized algorithms, simply compressing exchanged information, even in an unbiased stochastic way, within the decentralized network would accumulate the error and fail to converge. In this paper, we develop a framework of compressed, decentralized training and propose two different strategies, which we call {\em extrapolation compression} and {\em difference compression}. We analyze both algorithms and prove both converge at the rate of $O(1/\sqrt{nT})$ where $n$ is the number of workers and $T$ is the number of iterations, matching the convergence rate for full precision, centralized training. We validate our algorithms and find that our proposed algorithm outperforms the best of merely decentralized and merely quantized algorithm significantly for networks with {\em both} high latency and low bandwidth.
Marginal Policy Gradients: A Unified Family of Estimators for Bounded Action Spaces with Applications
Sep 27, 2018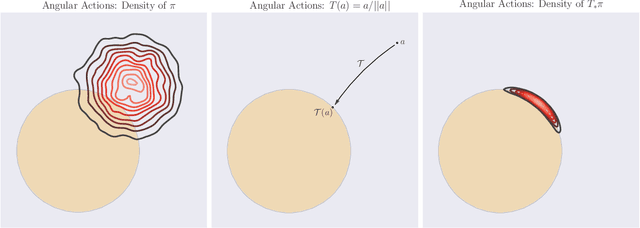
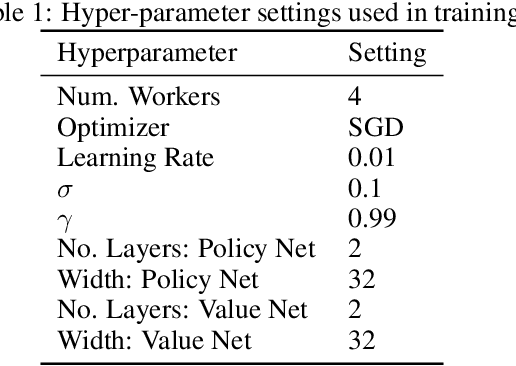
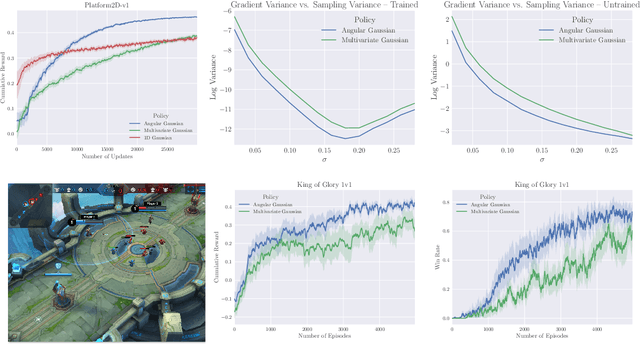
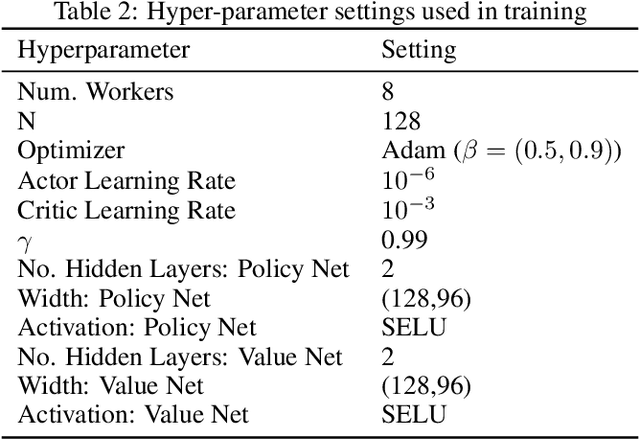
Many complex domains, such as robotics control and real-time strategy (RTS) games, require an agent to learn a continuous control. In the former, an agent learns a policy over $\mathbb{R}^d$ and in the latter, over a discrete set of actions each of which is parametrized by a continuous parameter. Such problems are naturally solved using policy based reinforcement learning (RL) methods, but unfortunately these often suffer from high variance leading to instability and slow convergence. Unnecessary variance is introduced whenever policies over bounded action spaces are modeled using distributions with unbounded support by applying a transformation $T$ to the sampled action before execution in the environment. Recently, the variance reduced clipped action policy gradient (CAPG) was introduced for actions in bounded intervals, but to date no variance reduced methods exist when the action is a direction, something often seen in RTS games. To this end we introduce the angular policy gradient (APG), a stochastic policy gradient method for directional control. With the marginal policy gradients family of estimators we present a unified analysis of the variance reduction properties of APG and CAPG; our results provide a stronger guarantee than existing analyses for CAPG. Experimental results on a popular RTS game and a navigation task show that the APG estimator offers a substantial improvement over the standard policy gradient.
An Interactive Greedy Approach to Group Sparsity in High Dimensions
Sep 26, 2018
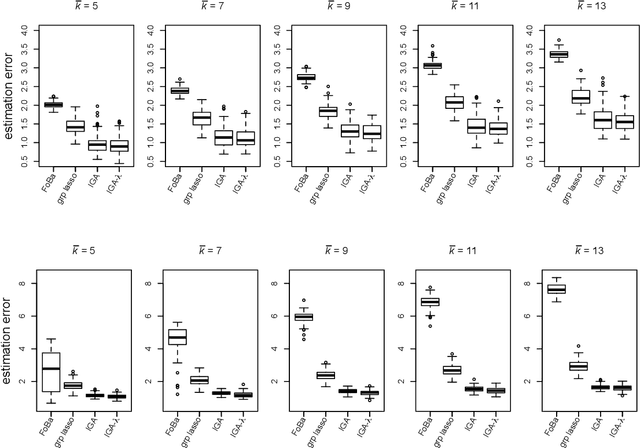
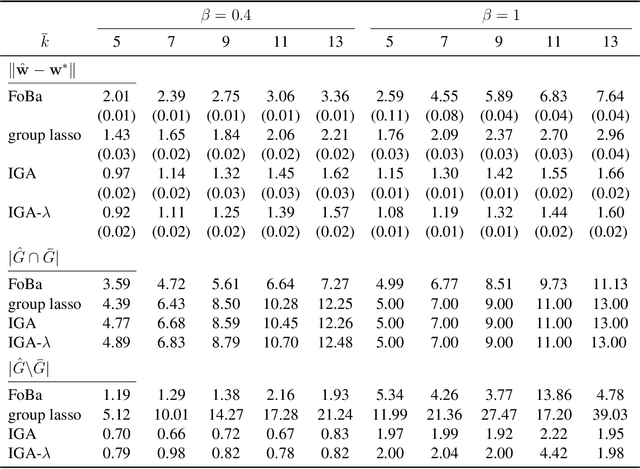
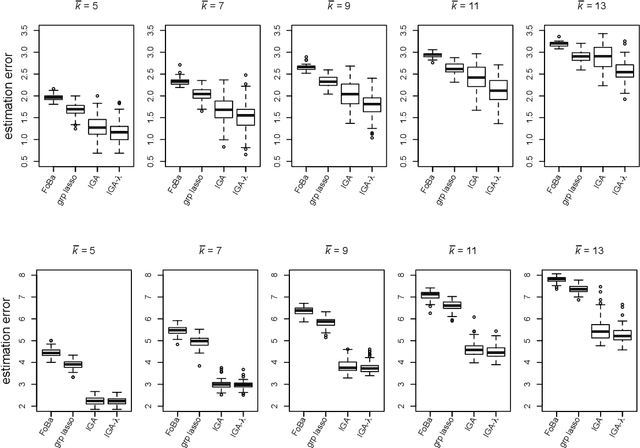
Sparsity learning with known grouping structure has received considerable attention due to wide modern applications in high-dimensional data analysis. Although advantages of using group information have been well-studied by shrinkage-based approaches, benefits of group sparsity have not been well-documented for greedy-type methods, which much limits our understanding and use of this important class of methods. In this paper, generalizing from a popular forward-backward greedy approach, we propose a new interactive greedy algorithm for group sparsity learning and prove that the proposed greedy-type algorithm attains the desired benefits of group sparsity under high dimensional settings. An estimation error bound refining other existing methods and a guarantee for group support recovery are also established simultaneously. In addition, we incorporate a general M-estimation framework and introduce an interactive feature to allow extra algorithm flexibility without compromise in theoretical properties. The promising use of our proposal is demonstrated through numerical evaluations including a real industrial application in human activity recognition at home. Supplementary materials for this article are available online.
Asynchronous Decentralized Parallel Stochastic Gradient Descent
Sep 25, 2018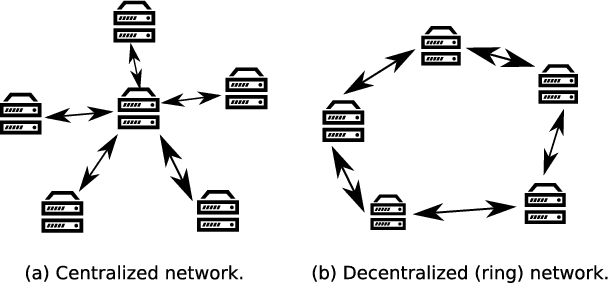
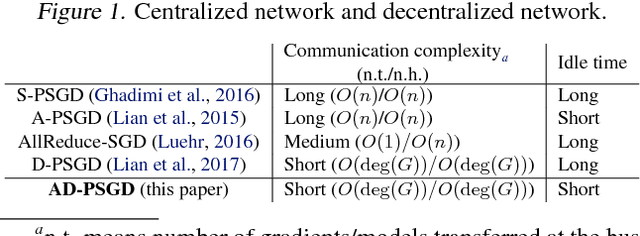
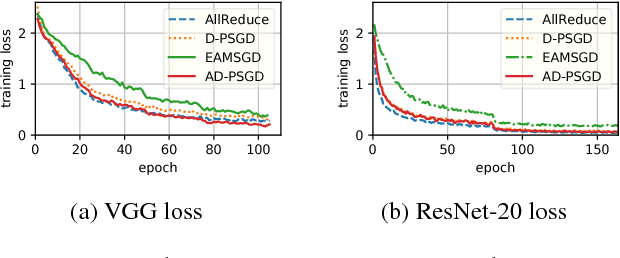
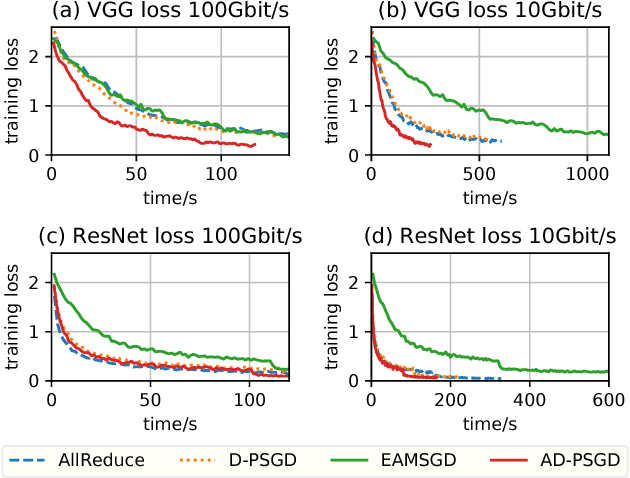
Most commonly used distributed machine learning systems are either synchronous or centralized asynchronous. Synchronous algorithms like AllReduce-SGD perform poorly in a heterogeneous environment, while asynchronous algorithms using a parameter server suffer from 1) communication bottleneck at parameter servers when workers are many, and 2) significantly worse convergence when the traffic to parameter server is congested. Can we design an algorithm that is robust in a heterogeneous environment, while being communication efficient and maintaining the best-possible convergence rate? In this paper, we propose an asynchronous decentralized stochastic gradient decent algorithm (AD-PSGD) satisfying all above expectations. Our theoretical analysis shows AD-PSGD converges at the optimal $O(1/\sqrt{K})$ rate as SGD and has linear speedup w.r.t. number of workers. Empirically, AD-PSGD outperforms the best of decentralized parallel SGD (D-PSGD), asynchronous parallel SGD (A-PSGD), and standard data parallel SGD (AllReduce-SGD), often by orders of magnitude in a heterogeneous environment. When training ResNet-50 on ImageNet with up to 128 GPUs, AD-PSGD converges (w.r.t epochs) similarly to the AllReduce-SGD, but each epoch can be up to 4-8X faster than its synchronous counterparts in a network-sharing HPC environment. To the best of our knowledge, AD-PSGD is the first asynchronous algorithm that achieves a similar epoch-wise convergence rate as AllReduce-SGD, at an over 100-GPU scale.
Stochastically Controlled Stochastic Gradient for the Convex and Non-convex Composition problem
Sep 06, 2018
In this paper, we consider the convex and non-convex composition problem with the structure $\frac{1}{n}\sum\nolimits_{i = 1}^n {{F_i}( {G( x )} )}$, where $G( x )=\frac{1}{n}\sum\nolimits_{j = 1}^n {{G_j}( x )} $ is the inner function, and $F_i(\cdot)$ is the outer function. We explore the variance reduction based method to solve the composition optimization. Due to the fact that when the number of inner function and outer function are large, it is not reasonable to estimate them directly, thus we apply the stochastically controlled stochastic gradient (SCSG) method to estimate the gradient of the composition function and the value of the inner function. The query complexity of our proposed method for the convex and non-convex problem is equal to or better than the current method for the composition problem. Furthermore, we also present the mini-batch version of the proposed method, which has the improved the query complexity with related to the size of the mini-batch.