 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanGEA: The Panoramic Graph Environment Annotation Toolkit
Mar 23, 2021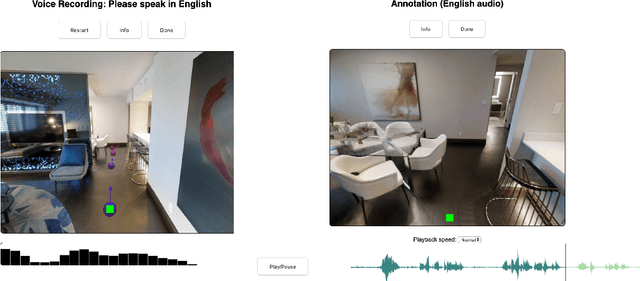
PanGEA, the Panoramic Graph Environment Annotation toolkit, is a lightweight toolkit for collecting speech and text annotations in photo-realistic 3D environments. PanGEA immerses annotators in a web-based simulation and allows them to move around easily as they speak and/or listen. It includes database and cloud storage integration, plus utilities for automatically aligning recorded speech with manual transcriptions and the virtual pose of the annotators. Out of the box, PanGEA supports two tasks -- collecting navigation instructions and navigation instruction following -- and it could be easily adapted for annotating walking tours, finding and labeling landmarks or objects, and similar tasks. We share best practices learned from using PanGEA in a 20,000 hour annotation effort to collect the Room-Across-Room dataset. We hope that our open-source annotation toolkit and insights will both expedite future data collection efforts and spur innovation on the kinds of grounded language tasks such environments can support.
On the Evaluation of Vision-and-Language Navigation Instructions
Jan 26, 2021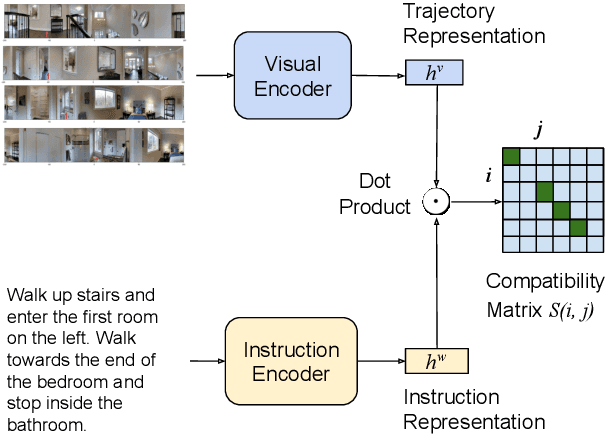
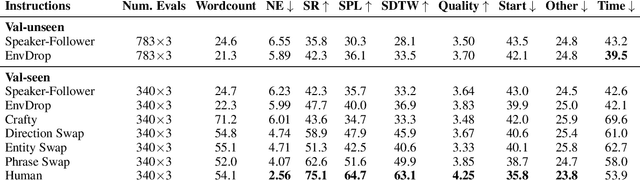
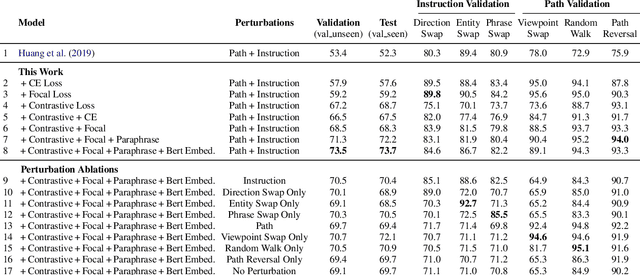
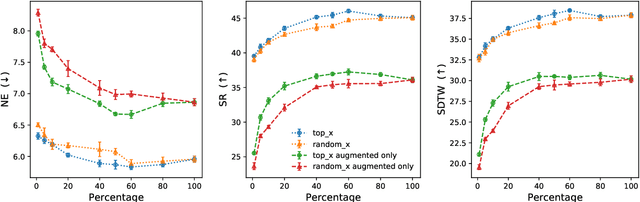
Vision-and-Language Navigation wayfinding agents can be enhanced by exploiting automatically generated navigation instructions. However, existing instruction generators have not been comprehensively evaluated, and the automatic evaluation metrics used to develop them have not been validated. Using human wayfinders, we show that these generators perform on par with or only slightly better than a template-based generator and far worse than human instructors. Furthermore, we discover that BLEU, ROUGE, METEOR and CIDEr are ineffective for evaluating grounded navigation instructions. To improve instruction evaluation, we propose an instruction-trajectory compatibility model that operates without reference instructions. Our model shows the highest correlation with human wayfinding outcomes when scoring individual instructions. For ranking instruction generation systems, if reference instructions are available we recommend using SPICE.
Cross-Modal Contrastive Learning for Text-to-Image Generation
Jan 15, 2021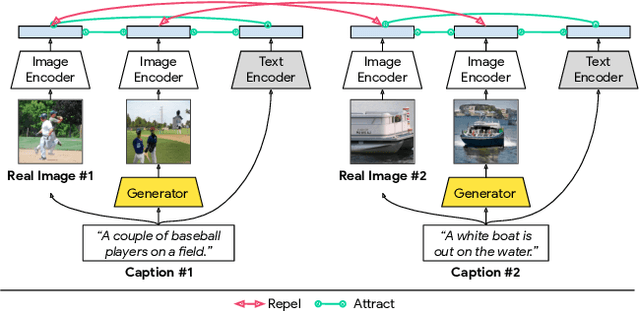
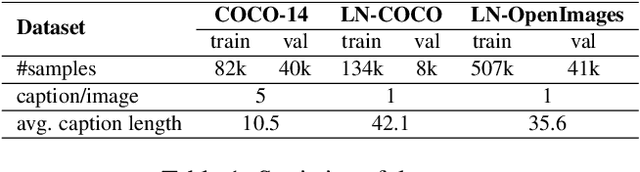
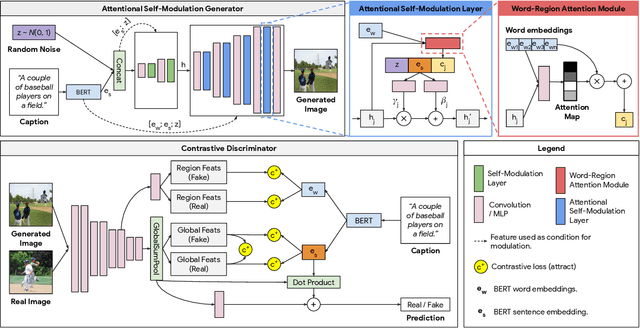
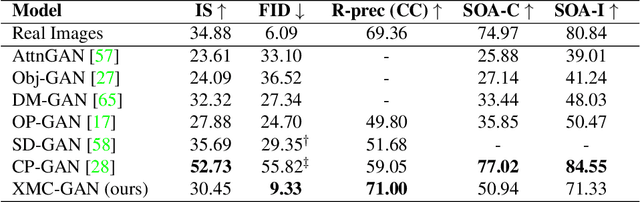
The output of text-to-image synthesis systems should be coherent, clear, photo-realistic scenes with high semantic fidelity to their conditioned text descriptions. Our Cross-Modal Contrastive Generative Adversarial Network (XMC-GAN) addresses this challenge by maximizing the mutual information between image and text. It does this via multiple contrastive losses which capture inter-modality and intra-modality correspondences. XMC-GAN uses an attentional self-modulation generator, which enforces strong text-image correspondence, and a contrastive discriminator, which acts as a critic as well as a feature encoder for contrastive learning. The quality of XMC-GAN's output is a major step up from previous models, as we show on three challenging datasets. On MS-COCO, not only does XMC-GAN improve state-of-the-art FID from 24.70 to 9.33, but--more importantly--people prefer XMC-GAN by 77.3 for image quality and 74.1 for image-text alignment, compared to three other recent models. XMC-GAN also generalizes to the challenging Localized Narratives dataset (which has longer, more detailed descriptions), improving state-of-the-art FID from 48.70 to 14.12. Lastly, we train and evaluate XMC-GAN on the challenging Open Images data, establishing a strong benchmark FID score of 26.91.
Text-to-Image Generation Grounded by Fine-Grained User Attention
Nov 07, 2020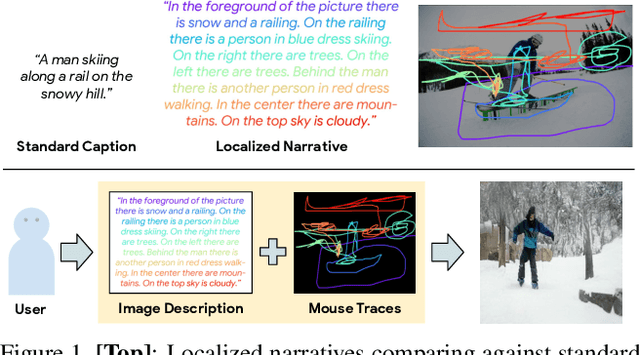
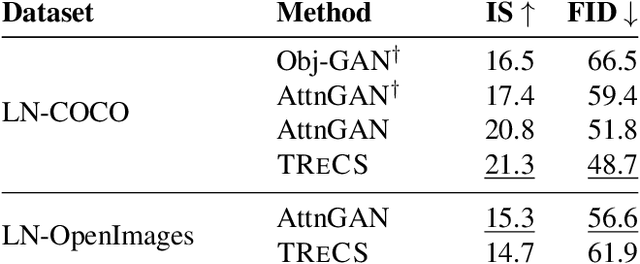
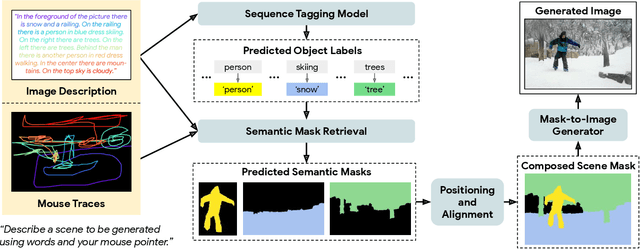
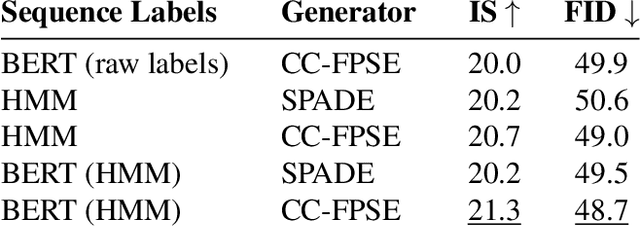
Localized Narratives is a dataset with detailed natural language descriptions of images paired with mouse traces that provide a sparse, fine-grained visual grounding for phrases. We propose TReCS, a sequential model that exploits this grounding to generate images. TReCS uses descriptions to retrieve segmentation masks and predict object labels aligned with mouse traces. These alignments are used to select and position masks to generate a fully covered segmentation canvas; the final image is produced by a segmentation-to-image generator using this canvas. This multi-step, retrieval-based approach outperforms existing direct text-to-image generation models on both automatic metrics and human evaluations: overall, its generated images are more photo-realistic and better match descriptions.
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
Oct 15, 2020
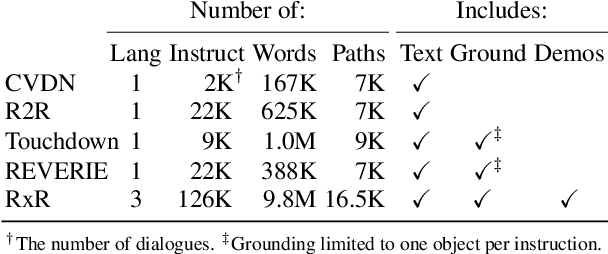
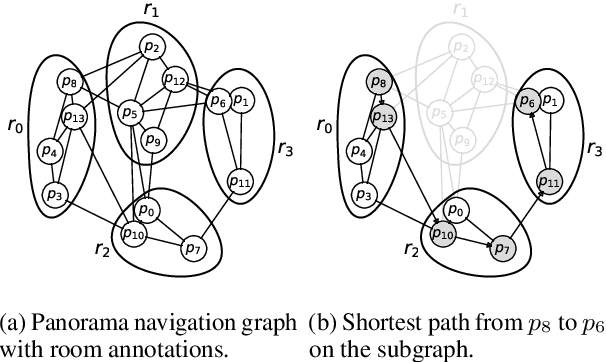
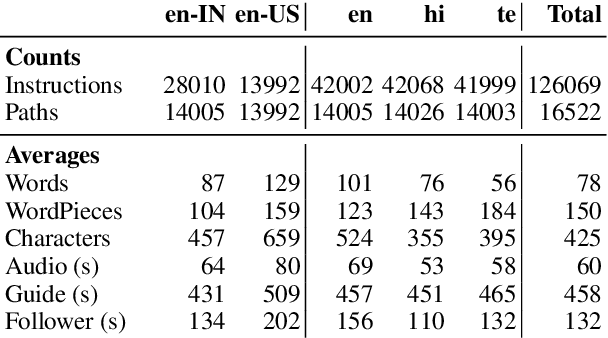
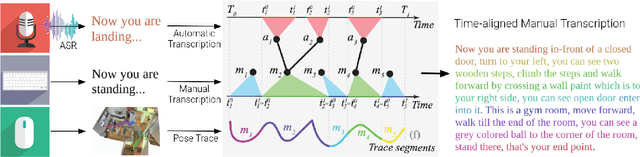
We introduce Room-Across-Room (RxR), a new Vision-and-Language Navigation (VLN) dataset. RxR is multilingual (English, Hindi, and Telugu) and larger (more paths and instructions) than other VLN datasets. It emphasizes the role of language in VLN by addressing known biases in paths and eliciting more references to visible entities. Furthermore, each word in an instruction is time-aligned to the virtual poses of instruction creators and validators. We establish baseline scores for monolingual and multilingual settings and multitask learning when including Room-to-Room annotations. We also provide results for a model that learns from synchronized pose traces by focusing only on portions of the panorama attended to in human demonstrations. The size, scope and detail of RxR dramatically expands the frontier for research on embodied language agents in simulated, photo-realistic environments.
Spatial Language Representation with Multi-Level Geocoding
Aug 21, 2020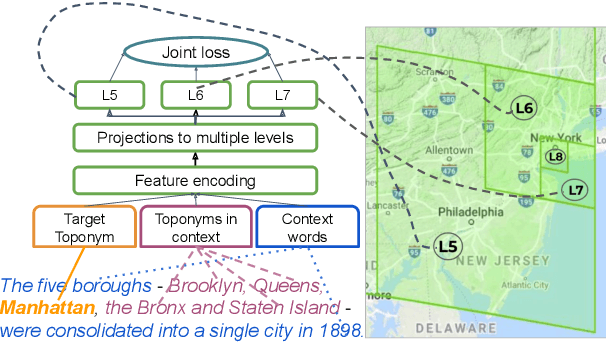

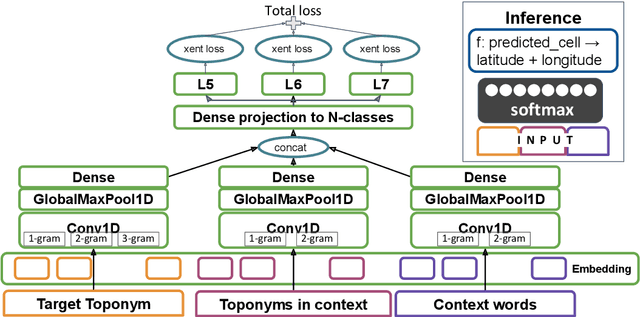

We present a multi-level geocoding model (MLG) that learns to associate texts to geographic locations. The Earth's surface is represented using space-filling curves that decompose the sphere into a hierarchy of similarly sized, non-overlapping cells. MLG balances generalization and accuracy by combining losses across multiple levels and predicting cells at each level simultaneously. Without using any dataset-specific tuning, we show that MLG obtains state-of-the-art results for toponym resolution on three English datasets. Furthermore, it obtains large gains without any knowledge base metadata, demonstrating that it can effectively learn the connection between text spans and coordinates - and thus can be extended to toponymns not present in knowledge bases.
Mapping Natural Language Instructions to Mobile UI Action Sequences
Jun 05, 2020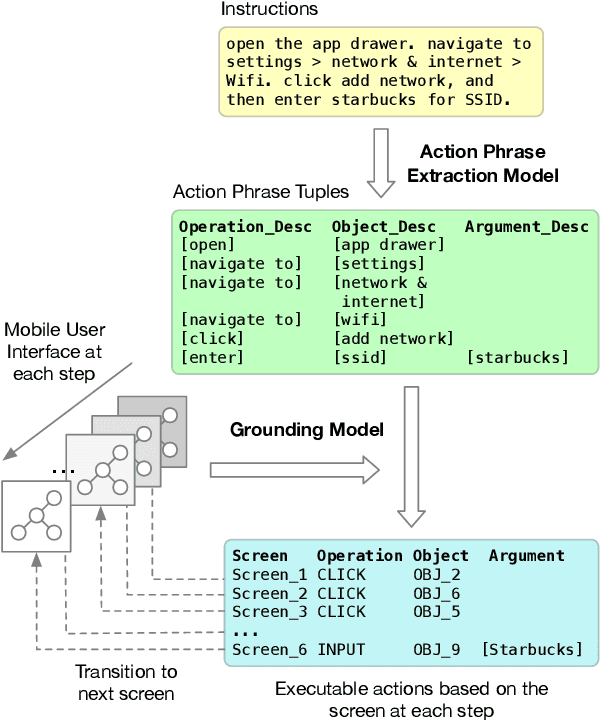
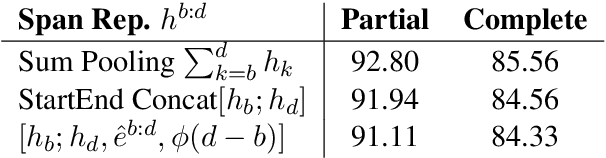
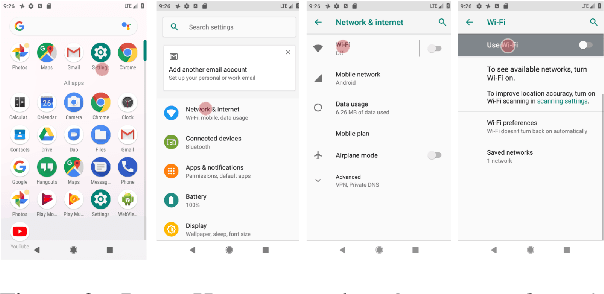
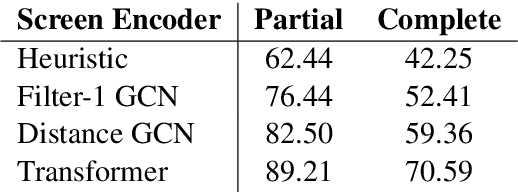
We present a new problem: grounding natural language instructions to mobile user interface actions, and create three new datasets for it. For full task evaluation, we create PIXELHELP, a corpus that pairs English instructions with actions performed by people on a mobile UI emulator. To scale training, we decouple the language and action data by (a) annotating action phrase spans in HowTo instructions and (b) synthesizing grounded descriptions of actions for mobile user interfaces. We use a Transformer to extract action phrase tuples from long-range natural language instructions. A grounding Transformer then contextually represents UI objects using both their content and screen position and connects them to object descriptions. Given a starting screen and instruction, our model achieves 70.59% accuracy on predicting complete ground-truth action sequences in PIXELHELP.
Text Classification with Few Examples using Controlled Generalization
May 18, 2020
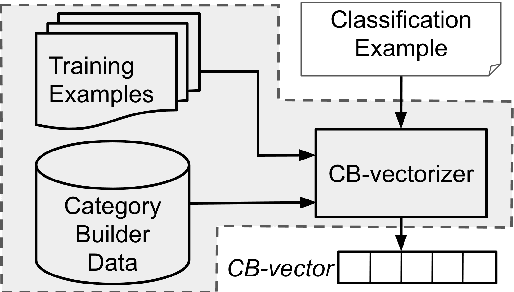

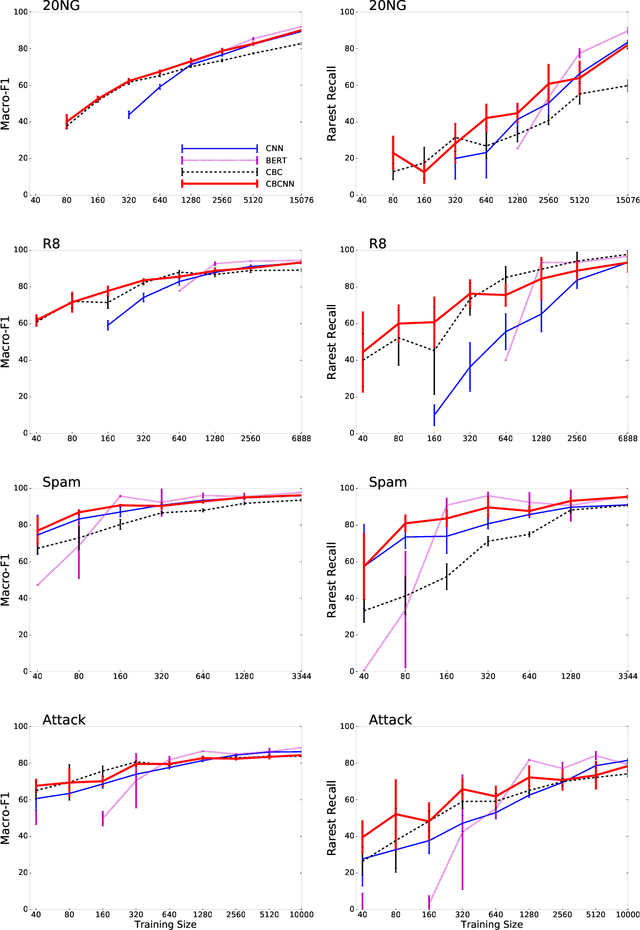
Training data for text classification is often limited in practice, especially for applications with many output classes or involving many related classification problems. This means classifiers must generalize from limited evidence, but the manner and extent of generalization is task dependent. Current practice primarily relies on pre-trained word embeddings to map words unseen in training to similar seen ones. Unfortunately, this squishes many components of meaning into highly restricted capacity. Our alternative begins with sparse pre-trained representations derived from unlabeled parsed corpora; based on the available training data, we select features that offers the relevant generalizations. This produces task-specific semantic vectors; here, we show that a feed-forward network over these vectors is especially effective in low-data scenarios, compared to existing state-of-the-art methods. By further pairing this network with a convolutional neural network, we keep this edge in low data scenarios and remain competitive when using full training sets.
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
Apr 30, 2020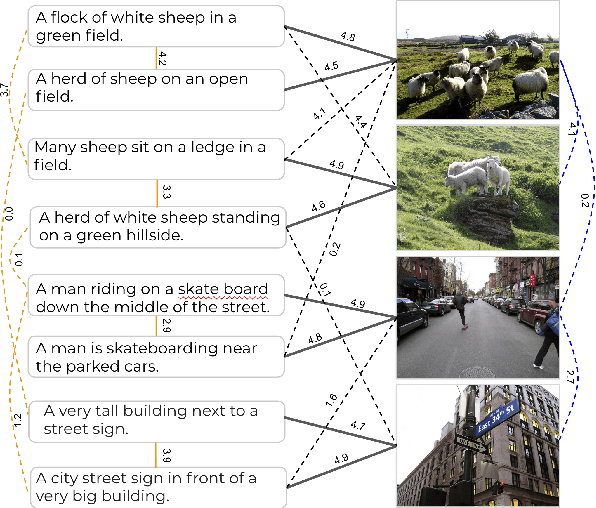



Image captioning datasets have proven useful for multimodal representation learning, and a common evaluation paradigm based on multimodal retrieval has emerged. Unfortunately, datasets have only limited cross-modal associations: images are not paired with others, captions are only paired with others that describe the same image, there are no negative associations and there are missing positive cross-modal associations. This undermines retrieval evaluation and limits research into how inter-modality learning impacts intra-modality tasks. To address this gap, we create the \textit{Crisscrossed Captions} (CxC) dataset, extending MS-COCO with new semantic similarity judgments for \textbf{247,315} intra- and inter-modality pairs. We provide baseline model performance results for both retrieval and correlations with human rankings, emphasizing both intra- and inter-modality learning.
Retouchdown: Adding Touchdown to StreetLearn as a Shareable Resource for Language Grounding Tasks in Street View
Jan 10, 2020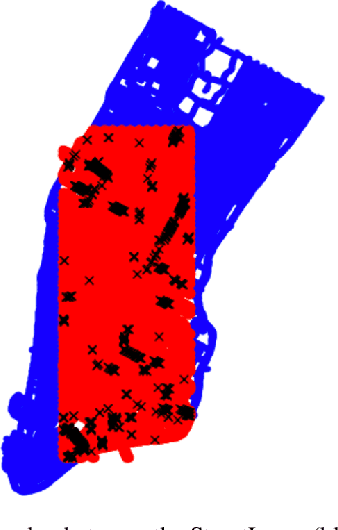
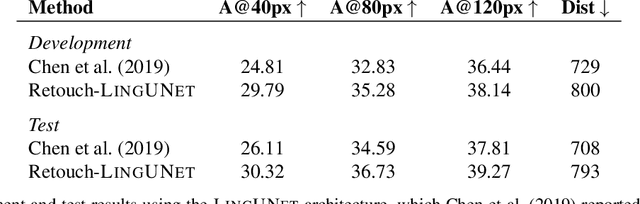

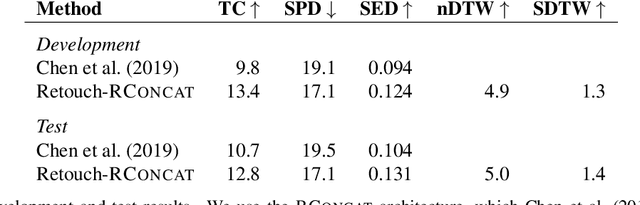
The Touchdown dataset (Chen et al., 2019) provides instructions by human annotators for navigation through New York City streets and for resolving spatial descriptions at a given location. To enable the wider research community to work effectively with the Touchdown tasks, we are publicly releasing the 29k raw Street View panoramas needed for Touchdown. We follow the process used for the StreetLearn data release (Mirowski et al., 2019) to check panoramas for personally identifiable information and blur them as necessary. These have been added to the StreetLearn dataset and can be obtained via the same process as used previously for StreetLearn. We also provide a reference implementation for both of the Touchdown tasks: vision and language navigation (VLN) and spatial description resolution (SDR). We compare our model results to those given in Chen et al. (2019) and show that the panoramas we have added to StreetLearn fully support both Touchdown tasks and can be used effectively for further research and comparison.