 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical and Reproducible Symbolic Music Generation by Large Language Models with Structural Embeddings
Jul 29, 2024



Music generation introduces challenging complexities to large language models. Symbolic structures of music often include vertical harmonization as well as horizontal counterpoint, urging various adaptations and enhancements for large-scale Transformers. However, existing works share three major drawbacks: 1) their tokenization requires domain-specific annotations, such as bars and beats, that are typically missing in raw MIDI data; 2) the pure impact of enhancing token embedding methods is hardly examined without domain-specific annotations; and 3) existing works to overcome the aforementioned drawbacks, such as MuseNet, lack reproducibility. To tackle such limitations, we develop a MIDI-based music generation framework inspired by MuseNet, empirically studying two structural embeddings that do not rely on domain-specific annotations. We provide various metrics and insights that can guide suitable encoding to deploy. We also verify that multiple embedding configurations can selectively boost certain musical aspects. By providing open-source implementations via HuggingFace, our findings shed light on leveraging large language models toward practical and reproducible music generation.
Sketching the Expression: Flexible Rendering of Expressive Piano Performance with Self-Supervised Learning
Aug 31, 2022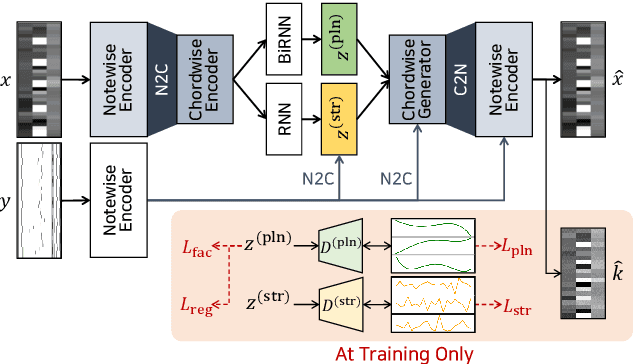
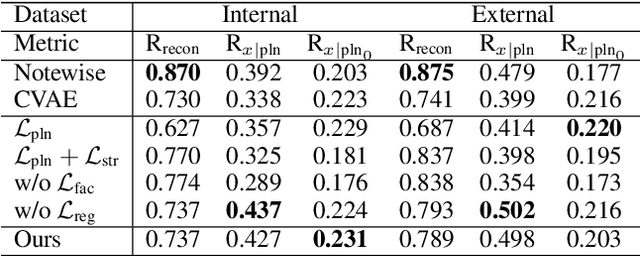
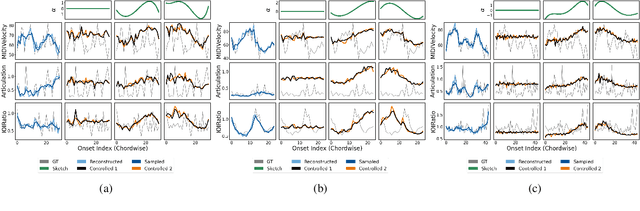
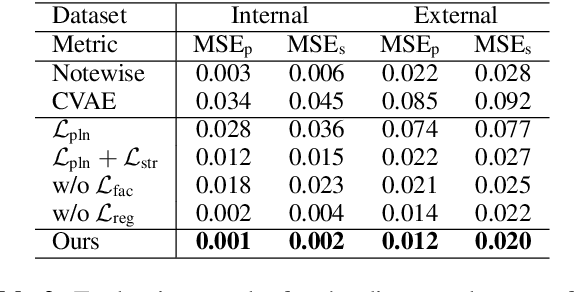
We propose a system for rendering a symbolic piano performance with flexible musical expression. It is necessary to actively control musical expression for creating a new music performance that conveys various emotions or nuances. However, previous approaches were limited to following the composer's guidelines of musical expression or dealing with only a part of the musical attributes. We aim to disentangle the entire musical expression and structural attribute of piano performance using a conditional VAE framework. It stochastically generates expressive parameters from latent representations and given note structures. In addition, we employ self-supervised approaches that force the latent variables to represent target attributes. Finally, we leverage a two-step encoder and decoder that learn hierarchical dependency to enhance the naturalness of the output. Experimental results show that our system can stably generate performance parameters relevant to the given musical scores, learn disentangled representations, and control musical attributes independently of each other.
Chord Generation from Symbolic Melody Using BLSTM Networks
Dec 04, 2017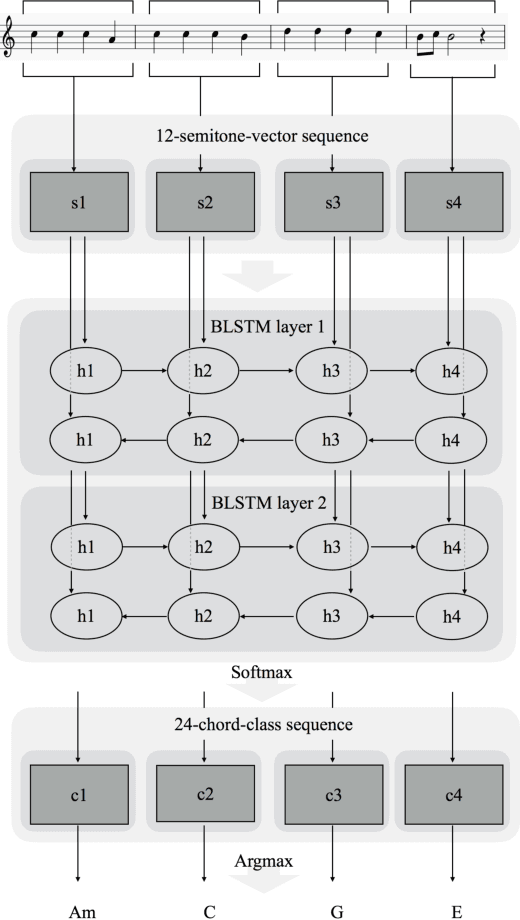
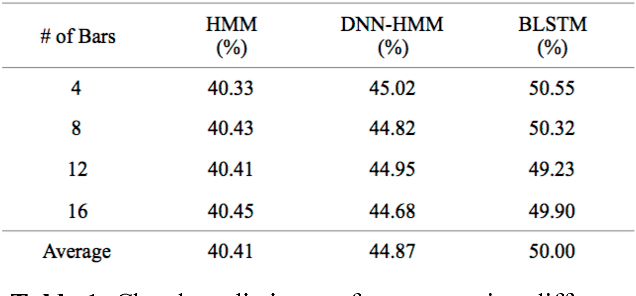
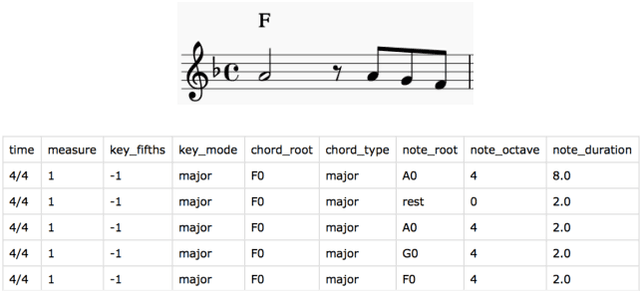
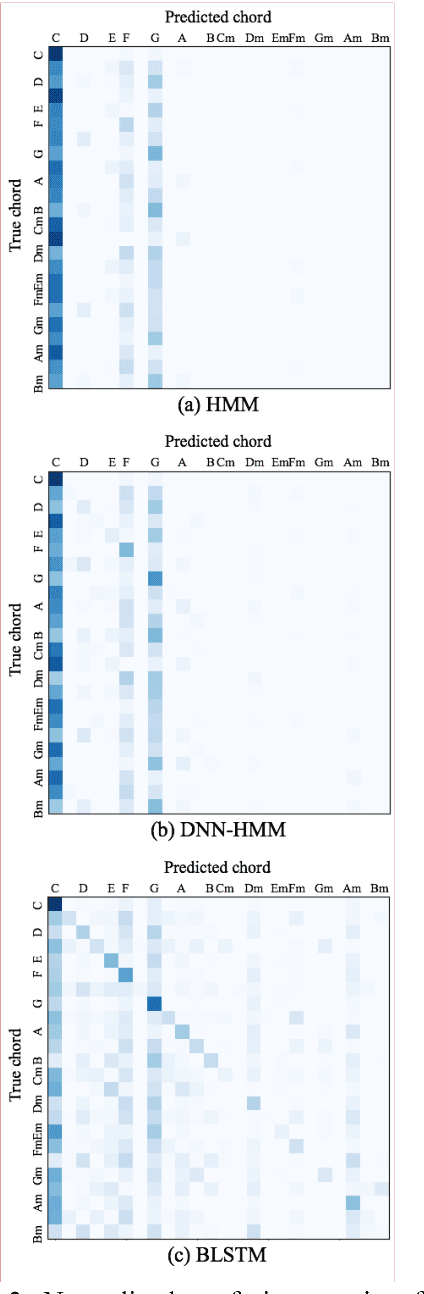
Generating a chord progression from a monophonic melody is a challenging problem because a chord progression requires a series of layered notes played simultaneously. This paper presents a novel method of generating chord sequences from a symbolic melody using bidirectional long short-term memory (BLSTM) networks trained on a lead sheet database. To this end, a group of feature vectors composed of 12 semitones is extracted from the notes in each bar of monophonic melodies. In order to ensure that the data shares uniform key and duration characteristics, the key and the time signatures of the vectors are normalized. The BLSTM networks then learn from the data to incorporate the temporal dependencies to produce a chord progression. Both quantitative and qualitative evaluations are conducted by comparing the proposed method with the conventional HMM and DNN-HMM based approaches. Proposed model achieves 23.8% and 11.4% performance increase from the other models, respectively. User studies further confirm that the chord sequences generated by the proposed method are preferred by listeners.