 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Speed FHD Full-Color Video Computer-Generated Holography
Aug 27, 2025Computer-generated holography (CGH) is a promising technology for next-generation displays. However, generating high-speed, high-quality holographic video requires both high frame rate display and efficient computation, but is constrained by two key limitations: ($i$) Learning-based models often produce over-smoothed phases with narrow angular spectra, causing severe color crosstalk in high frame rate full-color displays such as depth-division multiplexing and thus resulting in a trade-off between frame rate and color fidelity. ($ii$) Existing frame-by-frame optimization methods typically optimize frames independently, neglecting spatial-temporal correlations between consecutive frames and leading to computationally inefficient solutions. To overcome these challenges, in this paper, we propose a novel high-speed full-color video CGH generation scheme. First, we introduce Spectrum-Guided Depth Division Multiplexing (SGDDM), which optimizes phase distributions via frequency modulation, enabling high-fidelity full-color display at high frame rates. Second, we present HoloMamba, a lightweight asymmetric Mamba-Unet architecture that explicitly models spatial-temporal correlations across video sequences to enhance reconstruction quality and computational efficiency. Extensive simulated and real-world experiments demonstrate that SGDDM achieves high-fidelity full-color display without compromise in frame rate, while HoloMamba generates FHD (1080p) full-color holographic video at over 260 FPS, more than 2.6$\times$ faster than the prior state-of-the-art Divide-Conquer-and-Merge Strategy.
Solving Euler equations with Multiple Discontinuities via Separation-Transfer Physics-Informed Neural Networks
May 26, 2025Despite the remarkable progress of physics-informed neural networks (PINNs) in scientific computing, they continue to face challenges when solving hydrodynamic problems with multiple discontinuities. In this work, we propose Separation-Transfer Physics Informed Neural Networks (ST-PINNs) to address such problems. By sequentially resolving discontinuities from strong to weak and leveraging transfer learning during training, ST-PINNs significantly reduce the problem complexity and enhance solution accuracy. To the best of our knowledge, this is the first study to apply a PINNs-based approach to the two-dimensional unsteady planar shock refraction problem, offering new insights into the application of PINNs to complex shock-interface interactions. Numerical experiments demonstrate that ST-PINNs more accurately capture sharp discontinuities and substantially reduce solution errors in hydrodynamic problems involving multiple discontinuities.
Adversarial Purification by Consistency-aware Latent Space Optimization on Data Manifolds
Dec 11, 2024



Deep neural networks (DNNs) are vulnerable to adversarial samples crafted by adding imperceptible perturbations to clean data, potentially leading to incorrect and dangerous predictions. Adversarial purification has been an effective means to improve DNNs robustness by removing these perturbations before feeding the data into the model. However, it faces significant challenges in preserving key structural and semantic information of data, as the imperceptible nature of adversarial perturbations makes it hard to avoid over-correcting, which can destroy important information and degrade model performance. In this paper, we break away from traditional adversarial purification methods by focusing on the clean data manifold. To this end, we reveal that samples generated by a well-trained generative model are close to clean ones but far from adversarial ones. Leveraging this insight, we propose Consistency Model-based Adversarial Purification (CMAP), which optimizes vectors within the latent space of a pre-trained consistency model to generate samples for restoring clean data. Specifically, 1) we propose a \textit{Perceptual consistency restoration} mechanism by minimizing the discrepancy between generated samples and input samples in both pixel and perceptual spaces. 2) To maintain the optimized latent vectors within the valid data manifold, we introduce a \textit{Latent distribution consistency constraint} strategy to align generated samples with the clean data distribution. 3) We also apply a \textit{Latent vector consistency prediction} scheme via an ensemble approach to enhance prediction reliability. CMAP fundamentally addresses adversarial perturbations at their source, providing a robust purification. Extensive experiments on CIFAR-10 and ImageNet-100 show that our CMAP significantly enhances robustness against strong adversarial attacks while preserving high natural accuracy.
Robust Table Integration in Data Lakes
Nov 30, 2024In this paper, we investigate the challenge of integrating tables from data lakes, focusing on three core tasks: 1) pairwise integrability judgment, which determines whether a tuple pair in a table is integrable, accounting for any occurrences of semantic equivalence or typographical errors; 2) integrable set discovery, which aims to identify all integrable sets in a table based on pairwise integrability judgments established in the first task; 3) multi-tuple conflict resolution, which resolves conflicts among multiple tuples during integration. We train a binary classifier to address the task of pairwise integrability judgment. Given the scarcity of labeled data, we propose a self-supervised adversarial contrastive learning algorithm to perform classification, which incorporates data augmentation methods and adversarial examples to autonomously generate new training data. Upon the output of pairwise integrability judgment, each integrable set is considered as a community, a densely connected sub-graph where nodes and edges correspond to tuples in the table and their pairwise integrability, respectively. We proceed to investigate various community detection algorithms to address the integrable set discovery objective. Moving forward to tackle multi-tuple conflict resolution, we introduce an novel in-context learning methodology. This approach capitalizes on the knowledge embedded within pretrained large language models to effectively resolve conflicts that arise when integrating multiple tuples. Notably, our method minimizes the need for annotated data. Since no suitable test collections are available for our tasks, we develop our own benchmarks using two real-word dataset repositories: Real and Join. We conduct extensive experiments on these benchmarks to validate the robustness and applicability of our methodologies in the context of integrating tables within data lakes.
Robust 3D Semantic Occupancy Prediction with Calibration-free Spatial Transformation
Nov 19, 2024



3D semantic occupancy prediction, which seeks to provide accurate and comprehensive representations of environment scenes, is important to autonomous driving systems. For autonomous cars equipped with multi-camera and LiDAR, it is critical to aggregate multi-sensor information into a unified 3D space for accurate and robust predictions. Recent methods are mainly built on the 2D-to-3D transformation that relies on sensor calibration to project the 2D image information into the 3D space. These methods, however, suffer from two major limitations: First, they rely on accurate sensor calibration and are sensitive to the calibration noise, which limits their application in real complex environments. Second, the spatial transformation layers are computationally expensive and limit their running on an autonomous vehicle. In this work, we attempt to exploit a Robust and Efficient 3D semantic Occupancy (REO) prediction scheme. To this end, we propose a calibration-free spatial transformation based on vanilla attention to implicitly model the spatial correspondence. In this way, we robustly project the 2D features to a predefined BEV plane without using sensor calibration as input. Then, we introduce 2D and 3D auxiliary training tasks to enhance the discrimination power of 2D backbones on spatial, semantic, and texture features. Last, we propose a query-based prediction scheme to efficiently generate large-scale fine-grained occupancy predictions. By fusing point clouds that provide complementary spatial information, our REO surpasses the existing methods by a large margin on three benchmarks, including OpenOccupancy, Occ3D-nuScenes, and SemanticKITTI Scene Completion. For instance, our REO achieves 19.8$\times$ speedup compared to Co-Occ, with 1.1 improvements in geometry IoU on OpenOccupancy. Our code will be available at https://github.com/ICEORY/REO.
M2EF-NNs: Multimodal Multi-instance Evidence Fusion Neural Networks for Cancer Survival Prediction
Aug 08, 2024Accurate cancer survival prediction is crucial for assisting clinical doctors in formulating treatment plans. Multimodal data, including histopathological images and genomic data, offer complementary and comprehensive information that can greatly enhance the accuracy of this task. However, the current methods, despite yielding promising results, suffer from two notable limitations: they do not effectively utilize global context and disregard modal uncertainty. In this study, we put forward a neural network model called M2EF-NNs, which leverages multimodal and multi-instance evidence fusion techniques for accurate cancer survival prediction. Specifically, to capture global information in the images, we use a pre-trained Vision Transformer (ViT) model to obtain patch feature embeddings of histopathological images. Then, we introduce a multimodal attention module that uses genomic embeddings as queries and learns the co-attention mapping between genomic and histopathological images to achieve an early interaction fusion of multimodal information and better capture their correlations. Subsequently, we are the first to apply the Dempster-Shafer evidence theory (DST) to cancer survival prediction. We parameterize the distribution of class probabilities using the processed multimodal features and introduce subjective logic to estimate the uncertainty associated with different modalities. By combining with the Dempster-Shafer theory, we can dynamically adjust the weights of class probabilities after multimodal fusion to achieve trusted survival prediction. Finally, Experimental validation on the TCGA datasets confirms the significant improvements achieved by our proposed method in cancer survival prediction and enhances the reliability of the model.
Deep 3D-CNN for Depression Diagnosis with Facial Video Recording of Self-Rating Depression Scale Questionnaire
Jul 22, 2021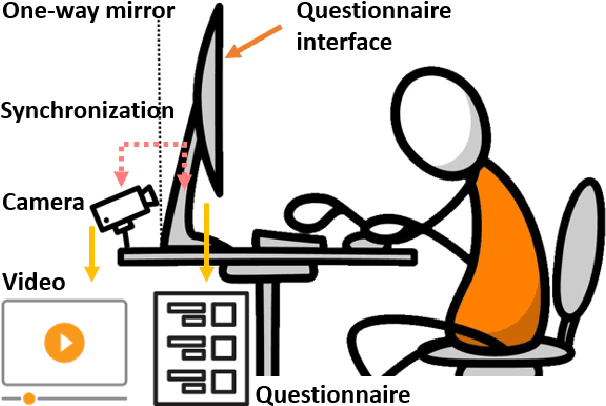
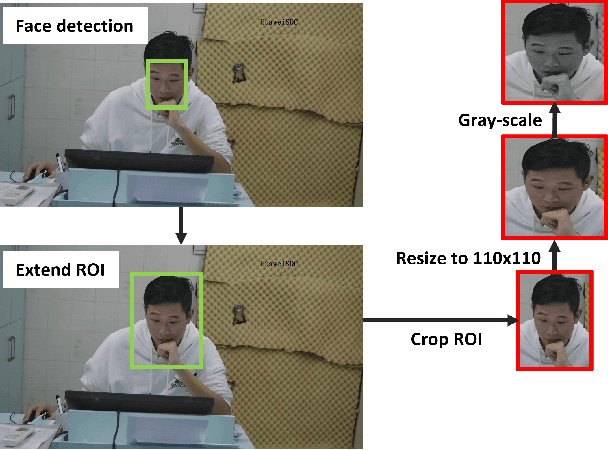
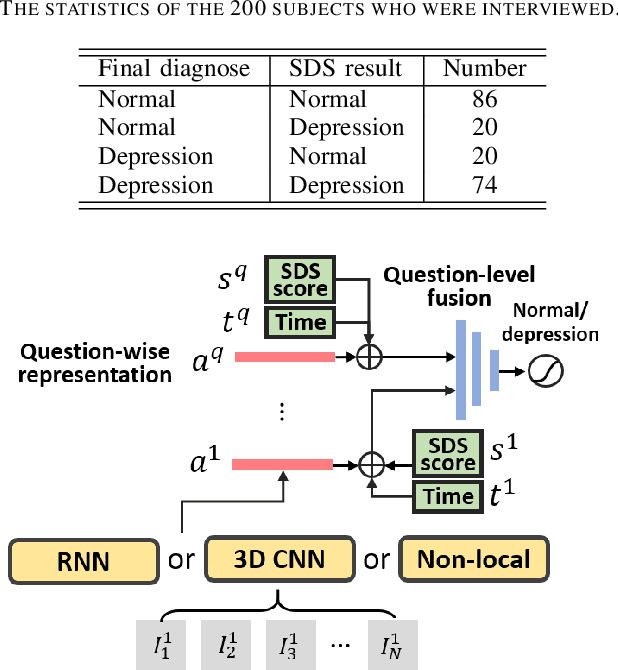
The Self-Rating Depression Scale (SDS) questionnaire is commonly utilized for effective depression preliminary screening. The uncontrolled self-administered measure, on the other hand, maybe readily influenced by insouciant or dishonest responses, yielding different findings from the clinician-administered diagnostic. Facial expression (FE) and behaviors are important in clinician-administered assessments, but they are underappreciated in self-administered evaluations. We use a new dataset of 200 participants to demonstrate the validity of self-rating questionnaires and their accompanying question-by-question video recordings in this study. We offer an end-to-end system to handle the face video recording that is conditioned on the questionnaire answers and the responding time to automatically interpret sadness from the SDS assessment and the associated video. We modified a 3D-CNN for temporal feature extraction and compared various state-of-the-art temporal modeling techniques. The superior performance of our system shows the validity of combining facial video recording with the SDS score for more accurate self-diagnose.
Interpreting Depression From Question-wise Long-term Video Recording of SDS Evaluation
Jun 25, 2021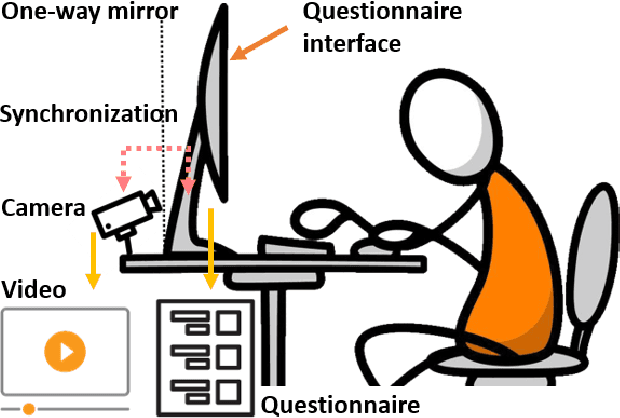

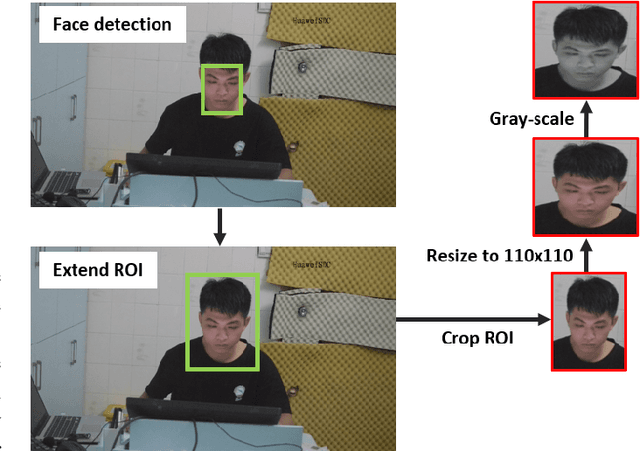
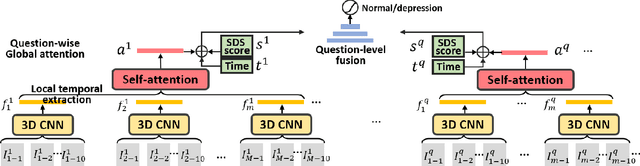
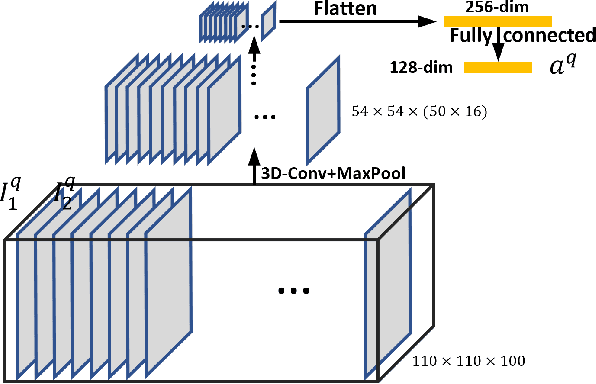
Self-Rating Depression Scale (SDS) questionnaire has frequently been used for efficient depression preliminary screening. However, the uncontrollable self-administered measure can be easily affected by insouciantly or deceptively answering, and producing the different results with the clinician-administered Hamilton Depression Rating Scale (HDRS) and the final diagnosis. Clinically, facial expression (FE) and actions play a vital role in clinician-administered evaluation, while FE and action are underexplored for self-administered evaluations. In this work, we collect a novel dataset of 200 subjects to evidence the validity of self-rating questionnaires with their corresponding question-wise video recording. To automatically interpret depression from the SDS evaluation and the paired video, we propose an end-to-end hierarchical framework for the long-term variable-length video, which is also conditioned on the questionnaire results and the answering time. Specifically, we resort to a hierarchical model which utilizes a 3D CNN for local temporal pattern exploration and a redundancy-aware self-attention (RAS) scheme for question-wise global feature aggregation. Targeting for the redundant long-term FE video processing, our RAS is able to effectively exploit the correlations of each video clip within a question set to emphasize the discriminative information and eliminate the redundancy based on feature pair-wise affinity. Then, the question-wise video feature is concatenated with the questionnaire scores for final depression detection. Our thorough evaluations also show the validity of fusing SDS evaluation and its video recording, and the superiority of our framework to the conventional state-of-the-art temporal modeling methods.
Spatial Object Recommendation with Hints: When Spatial Granularity Matters
Jan 08, 2021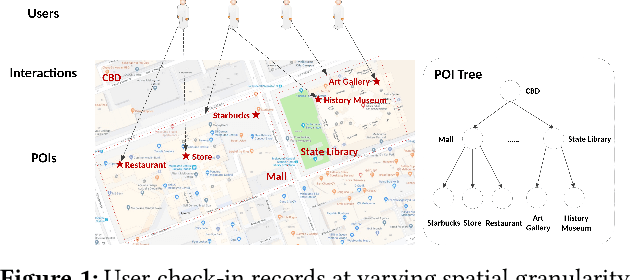

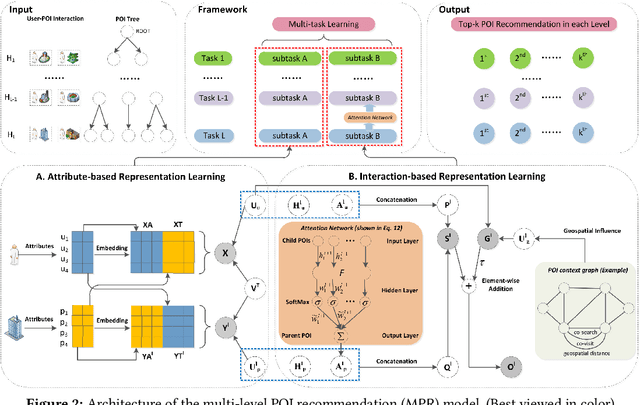
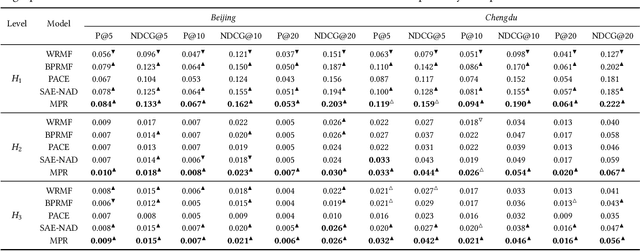
Existing spatial object recommendation algorithms generally treat objects identically when ranking them. However, spatial objects often cover different levels of spatial granularity and thereby are heterogeneous. For example, one user may prefer to be recommended a region (say Manhattan), while another user might prefer a venue (say a restaurant). Even for the same user, preferences can change at different stages of data exploration. In this paper, we study how to support top-k spatial object recommendations at varying levels of spatial granularity, enabling spatial objects at varying granularity, such as a city, suburb, or building, as a Point of Interest (POI). To solve this problem, we propose the use of a POI tree, which captures spatial containment relationships between POIs. We design a novel multi-task learning model called MPR (short for Multi-level POI Recommendation), where each task aims to return the top-k POIs at a certain spatial granularity level. Each task consists of two subtasks: (i) attribute-based representation learning; (ii) interaction-based representation learning. The first subtask learns the feature representations for both users and POIs, capturing attributes directly from their profiles. The second subtask incorporates user-POI interactions into the model. Additionally, MPR can provide insights into why certain recommendations are being made to a user based on three types of hints: user-aspect, POI-aspect, and interaction-aspect. We empirically validate our approach using two real-life datasets, and show promising performance improvements over several state-of-the-art methods.